
Чуть ранее я рассказывал про Paper mills, как мы с ними боремся и при чем тут Generative AI. Также был пост в канале "New Yorko Times" про то, что распознавать текст, сгенерированный chatGPT, не так-то просто, и OpenAI тут репортит честные метрики, а не 99% accuracy, как у стартапов. Конечно же, мы тоже долго кумекали, можем ли мы надежно распознавать сгенерированные статьи и даже организовали соревнование при COLING 2022, про которое я тут расскажу (также эту тему есть отдельный пост на английском в одноименном блоге). Оно не то чтобы удалось, и это только подтвердило, что задача непроста.
Соревнование
Мы взяли тексты из сотен отозванных статей журнала “Microprocessors and Microsystems” – про них раньше было исследование, часть статьи про tortured phrases (помните? “image acknowledgement” вдруг вместо “image recognition”, и ”quantum doors” вместо “quantum gates”): где-то в 2021 вдруг число статей на выпуск сильно выросло, а время рецензирования подозрительно сократилось. Также в этих выпусках обнаружили целые россыпи tortured phrases, порой по 30-40 на статью. Чтоб сбалансировать, мы взяли аннотации более ранних статей того же журнала, в которых проблем не было выявлено. Это первые две части датасета – одна из фейков, вторая – из текста, написанного людьми (и тут вы уже чувствуете, что метки не идеальны. Даже в хорошие более ранние статьи “Microprocessors and Microsystems” могло просочиться немного сгенерированного контента, и, наоборот, в стрёмных выпусках после 2021 тоже что-то может быть написано людьми).
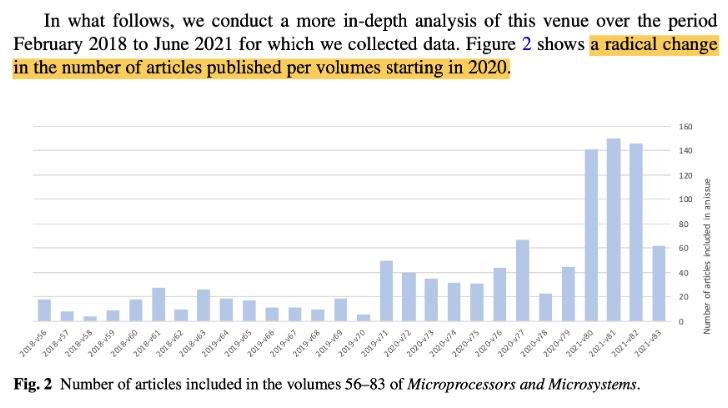
Число статей в выпусках журнала “Microprocessors and Microsystems”
Чтоб не затачиваться только под один домен, я добавил аннотации статей на все темы – от солнечной энергии и прав человека до бедности и урбанизации (это из соседнего проекта по классификации статей по вкладу в Sustainable Development Goals). Далее наш любимый HuggingFace, берем эти аннотации и по-всякому над ними издеваемся: пересказываем с pszemraj/led-large-book-summary, по первой фразе генерируем продолжение с EleutherAI/gpt-neo-125M и GPT-3. Также перефразировали некоторые аннотации с помощью SpinBot (это прям рассадник tortured phrases).
Сделал train/test split с 70% текстов в тесте, думая, выбил ~82% F1 c tf-idf & logreg – да запустил соревнование, думая, что SciBERT добавит 2 процента, как обычно. Сроки поджимали, SciBERT-нубук был на подходе, но надо было уже запускать сореву. Уже даже с логрегом я заметил, что некоторые подвыборки теста классифицируются идеально, например, все пересказанное моделью pszemraj/led-large-book-summary – там шаблоны начала “in this paper authors propose” или “the authors suggest to” выучиваются даже с tf-idf.

Доля верных ответов на валидации, в разбивке по типам данных. Модель – tf-idf & logreg.
В-общем, запустили соревнование, а через несколько дней я понял, что SciBERT выбивает >98% по метрике F1. Фэйл, дальше возня пошла за проценты и доли процента, у победителей в итоге 99.43% на лидерборде (у двух команд скор совпал, но читерства не заметно). Слегка обидно, что создается иллюзия легкости задачи, хотя я уже догадывался, что тут с дата-дрифтами все поломается.
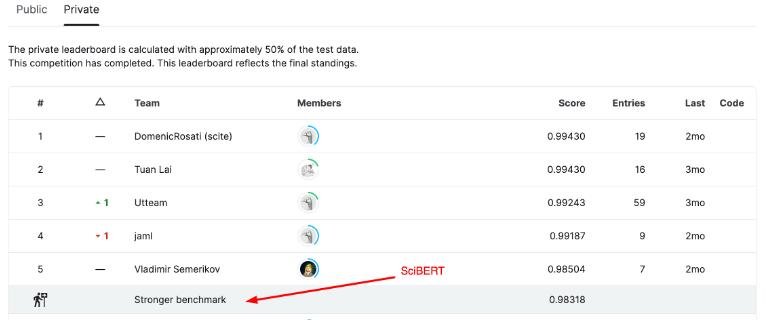
Лидерборд соревнования
Что мы поняли
Самым полезным выхлопом от соревнования оказалась статья одного из победителей Domenic Rosati. То, что я подозревал, Доменик показал на цифрах. Он сгенерировал новый датасет, похожий на мой – с немного другими темами и другими моделями перефразирования/генерации. Ну и все сломалось. Модели, обученные на данных моего соревнования, выбили только 31% на новом датасете (в постановке бинарной классификации – совсем фэйл, хуже рандома). Также он показал, что если мы хотим распознавать текст, сгенерированный новой моделью, скажем, BLOOM, то BLOOM также должен быть и в трейне. То есть обобщения на другие типы моделей нет.
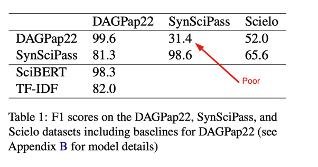
Отсутствие обобщения на новые синтетические датасеты
Недолго сумлеваясь, я позвал Доменика делать новое соревнование – с полными текстами статей вместо аннотаций, token-level классификацией вместо sentence-level и новыми темами и моделями в тесте. Мы пока пролетели с заявками на KDD Cup (там Амазон пришел с кучей призовых, хотя интересный твист плот, если я не прошел потому, что писал заявку не без помощи chatGPT) и NeurIPS (одна рецензия положительная, одна отрицательная #reviewer2, третий ревьюер увидел заготовку соревы на сайте COLING и подумал, что это dual submission – оргфэйл). Так что теперь метим на COLING 2024.
Надо честно признаться, что организация таких соревнований – это развлечение и репутационный бонус (особенно, конечно, если на NeurIPS попадать), но в случае этой задачи в прод далеко не скоро что-либо пойдет, если вообще когда-либо пойдет. Но если все же научиться надежно ловить контент, порожденный более старыми моделями а-ля GPT-2, это уже неплохо, есть попутные бонусы, например, так можно ловить тексты с tortured phrases (возможно потому, что spinbot под капотом использует GPT-2, но это гипотеза).
Про детекторы конкретно GPT-контента и сложности их использования в бою поговорю в следующий раз.
Спасибо! Но я из статьи так и не понял до конца, в чем была проблема. Из конкретики, приводится вот это:
Только ли в этом заключается неудачность датасета?