
Foreword
Машинлернинг 101 по факту написал уже Вастрик давным давно, ссылка тутъ, охуенный пост, рекомендую. И если вам нужно просто понимать, как учат машины, возможно даже зачем учат машины, рекомендую почитать. Тот пост нормально состарился и хорошо читается и сегодня.
Зачем же этот псто? Я серьёзно считаю, что Машинное Обучение - это в первую очередь инженерная дисциплина. При том, что у меня профдеформация прикладного математика и я хочу хорошие формулы и доказательства к этой всей хуйне, ящитаю что вся история современного машинлернинга это цепочка элегантных костылей погромистов и инженеров для решения конкретных задач. И это очень наглядно прослеживается на самой важной группе моделей машинного обучения - нейронных сетях, они же нейросетки.
И в этой писанине я постараюсь пройтись по истории применения и написания нейросеток с первого серьезного применения вплоть до современности без формул, матеши и некоторым маханием руками. Я надеюсь что не нагружу вам голову, но начнёте понимать как базово они устроены, почему они охуенно справляются с поставленными задачами и в какой заднице челубесы типа меня находятся сейчас.
Наш маршрут пройдет следующим образом:
- Еще раз, что такое машинное обучение
- Еще раз, как вообще строятся нейросетки
- Первый хайп с коммерческим применением, а конкретно как нейросетки
роняли западрешали задачи компьютерного зрения - Как хайп продолжился, но уже для решения задач обработки текста
- Что вообще стоит в основе этого вашего Гены ИИ и как эта индустрия хайпанула как будто случайно
- В какого мегазорда (проверка на олда, остальным смотреть Power Rangers) собралось решение для работы с текстом
- Почему оказалось, что сами нейросетки вымахали огромными и непонятными
- Как с этими огромными нейросетками для текста приходится работать чтобы из них сделать полезных ассистентов, а не тупо слоп, в
2к23твою мать, 2к26м году.
Чтиво длинное, писать я умею хреново, пишу это долго, надеюсь этот текст не попадет в золотой фонд Русской Классики и вы страдать хотя бы не будете.

Краткое содержание предыдущих серий
Так, чтобы не заставлять аудиторию мотаться по паре ссылок и еще всему интернету, краткое содержание предыдущей серии.
Введем типовую задачу, которую через ML решают. У нас есть какие-то данные. Комменты хвиттора, таблички экселевские, дамп имиджборд, заколебавшие всех войсы в телеграме, может быть вы ценитель и схоронили весь оранжевый ютуб - может быть что-угодно. И вы уверены, что здесь есть какая-то закономерность в этих данных, хотите найти её... зачем-то. Там, нагенерить своих вариантов, предсказать количество лойсов что соберёт пост в Вастрик.Клубе или просто интересно.
Так вот, вы можете построить говнокод специального типа, что умеет это делать, притом вам всё самостоятельно прописывать не нужно, заставить компьютер посмотреть на данные и дозаполнить всё (при помощьи чьей-то матери, и матстата, и теорвера) самому. Вот этот самый процесс и есть машинное обучение.
Fast round
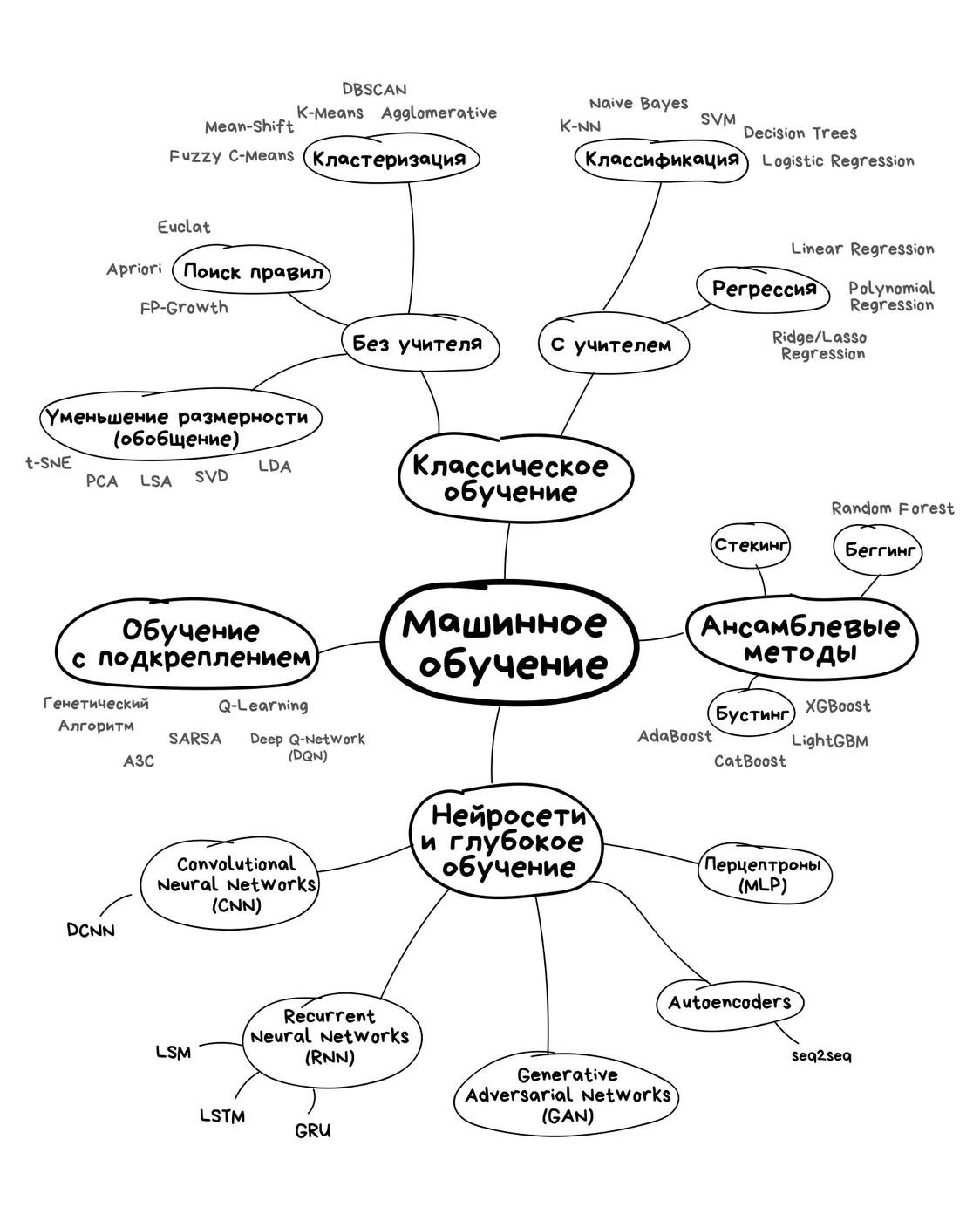
- Если вы пытаетесь что-то предсказывать и подаёте примеры что показывать и предсказывать - это supervised обучение, оно же с учителем, если не даёте - unsupervised или без учителя, если примеров мало - semi-supervised, лучшее что могу придумать - со "студентиком".
- Если вы пытаетесь предсказывать число - регрессия, если пытаетесь предсказать "хотдог или нет" - классификация.
- Есть прикол с тем, что вы можете наплодить много туповатых моделек, сложить их вместе правильно, а они внезапно умеют круто предсказывать - это ансамблирование.
- Если ваша моделька это сумма всех чисел на входе, помноженная на что-нибудь - это линейная модель, а если вы сверху результат запихнёте в какую-нибудь смешную функцию - обобщённая линейная модель.
- Нейросетка - ансамблирование обобщённых линейных моделей.
И вот теперь мы можем начать по-настоящему душнить дальше со всеми остальными нейросетками.
Нейросетка - как она устроена? (Как огр из болота)

Это будет коротыш, потому что это хоть и база нейросеток, но здесь ничего сверх-естественного. Вы уже прочли, что туча тупых линейных моделек сложенные вместе - это нейросетка. Но их так никогда не строят, а их "нарезают" слоями. Прям как лук или Шрек. Зачем это так делать вообще? Вот смотрите, у вас ваш нейрончик можно записать как такое уравнение. А если такие нейрончики поставить в столбик друг над другом, то оказывается, что можно все эти уравнения записать как массив этих коэффициентов. В принципе на этом и всё, вот такой стак нейронов с одинаковой активацией называется слоём и дальше все приколы нейросеток - это попытки-потуги сделать эти самые слои.
А теперь к смешному контенту.
Как нейросетки увидели всё и завезли первый успешный хайп в айти.
Ну так вот, сначала начнём с компьютерного зрения потому что первый хайп на много денег пошёл как раз после того как нейросетка спец. вида выиграла у других бездушных машин конкурс на классификацию картинок. А потом стала выполнять эту работу лучше человека. А там ещё приколы выползли.
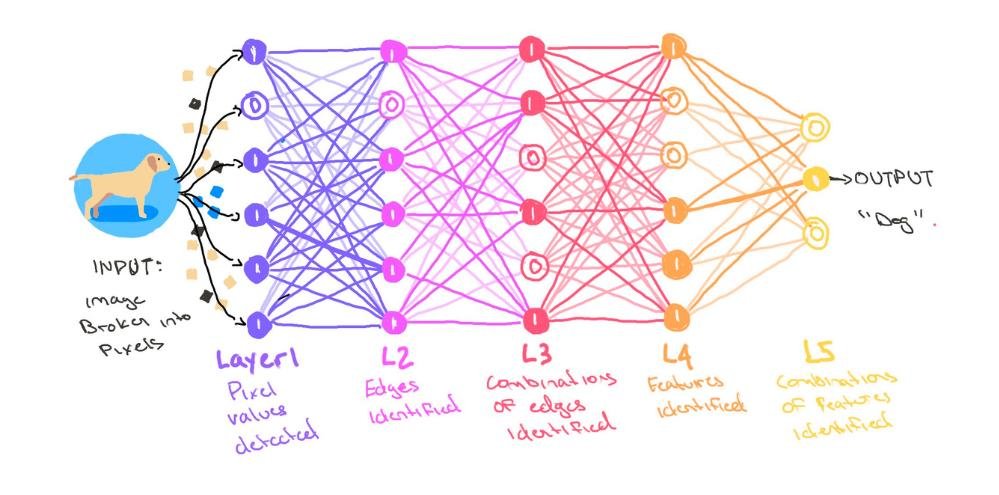
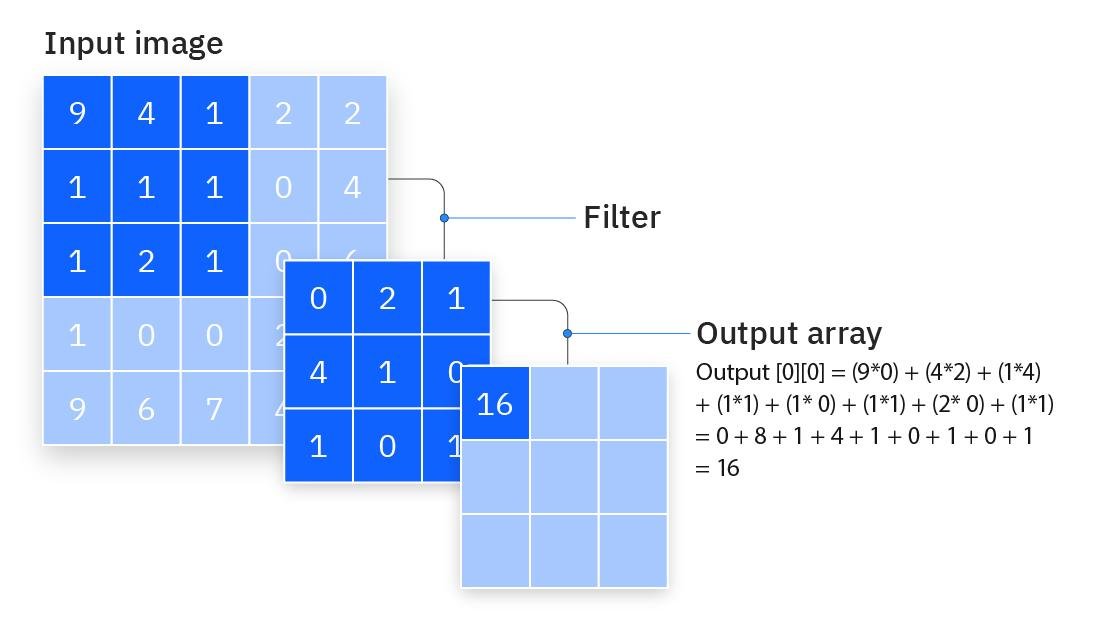
1989й год, молодой и перспективный Ян ЛеКун и сотоварищи из Bell Labs придумали LeNet. Нейросетку, в которой придумали операцию "свёртки", чтобы решать задачку "опознавания рукописных цифр". Обычно новичкам предлагают написать с нуля LeNet-5, пятое поколение этой же самой сетки, что сделали в 1998м году. На английском "свёртка" - convolution, посему Convolutional Neural Network, она же CNN.
Штука забавная получилась, кому-то даже понравилось, решала задачу свою в USPS, она же американская госпочта. Но всем было немного пофигу до 2012 года на такое решение. Что же собственно произошло? Ну собственно уже спойлерил, AlexNet выиграл в ImageNet. Алекс Крижевский вместе с Ильёй Сутскевером и Джоффри Хинтоном (знакомые имена, не так ли?) развили идею, сделали архитектуру посложнее и теперь этот алгоритм решал задачу "что нарисовано на картинке" в рамках соревнования ImageNet Large Scale Visual Recognition Challenge лучше всех остальных. Это пара миллионов картинок и пара тысяч разных объектов на картинке, то есть контест был сложным. Так вот, top-5% accuracy - 84.7%. В топ-5 в предложенных ответах в 84.7% находили правильный ответ. Человека оценили в 94%. Почему все офигели? Второе место в 2012м году получило top-5 accuracy в 73.9%. И тут Остапа понесло...
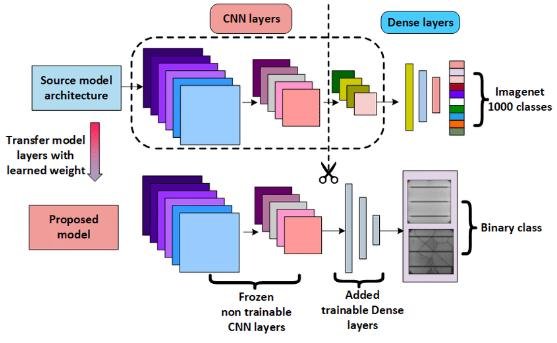
Понесло до того, что обнаружили офигенную особенность этой архитектуры - если отрубить хвост модельки, то есть всё что не слои свёртки, вы получаете штуку, которую можете вообще не трогать, к ней приклеить другую нейросетку или другую модель, что будет решать вашу конкретную задачу. Формальное название - Transfer Learning. Получилось, что если чюваки смогут решать ImageNet всё лучше и лучше, то и все остальные задачи компьютерного зрения будут решаться всё лучше и лучше, потому что первый кусбан алгоритма будет лучше и лучше. Первый бум нейросеток начался.
Выводы
- Нейросетки умеют сами находить нужные признаки в сложных данных, позволяя обскакивать традиционные методы.
- Впервые это увидели при работе с компьютерным зрением, сделав CNN.
- CNNки концептуально состоят из двух блоков - feature extractor, слои из свёрток, discriminator - обычные полносвязные слои или вовсе другие модели классического машинного обучения.
- Научив на сложной задаче одну CNNку, можно взять её feature extractor и сразу же использовать в своей конкретной задаче. Это называется Transfer Learning.
- Transfer Learning - главная причина популярности нейросеток, позволяющая быстро склеить готовое решение для своей задачи, не делая всё с нуля.
"Внимание! Спасибо за внимание." Как нейросетки смогли побороть и задачи естественного языка
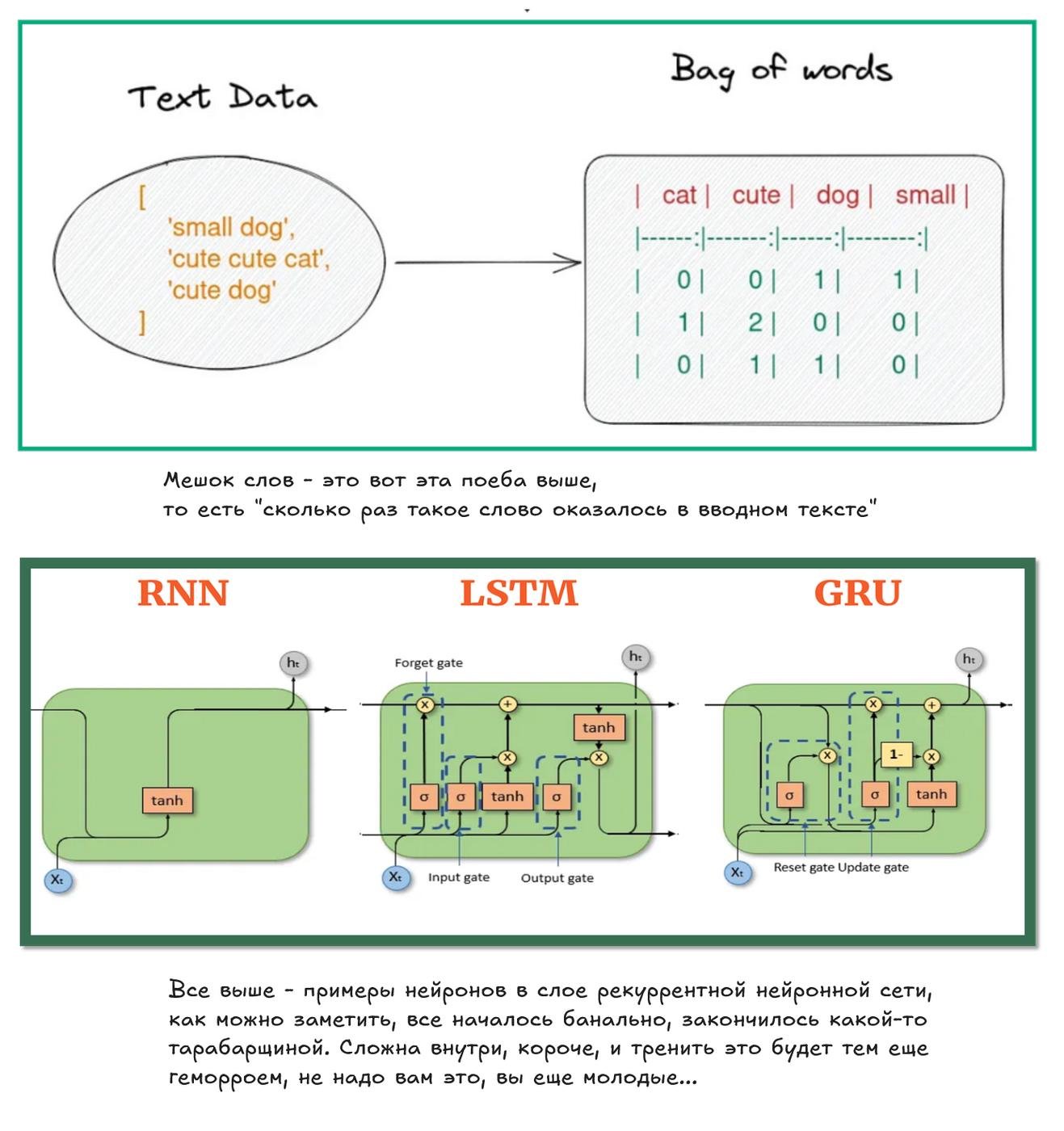
Если с картинками кое-как разобрались и решают много прикольных задач, с текстом такой прикол очень долго не проходил. Изначально задачи с текстом решали методом bag-of-words, то есть пофигу как слова сложены в текст, главное что сами слова на месте. Спам-фильтр на таком подходе ещё можно построить, но на этом наши полномочия всё, закончились. Потом, вспомнили такую штуку как рекуррентные нейросетки. Теперь текст это не просто мешок слов, а последовательность слов, а сама нейросетка теперь будет искать зависимости внутри последовательностей слов.
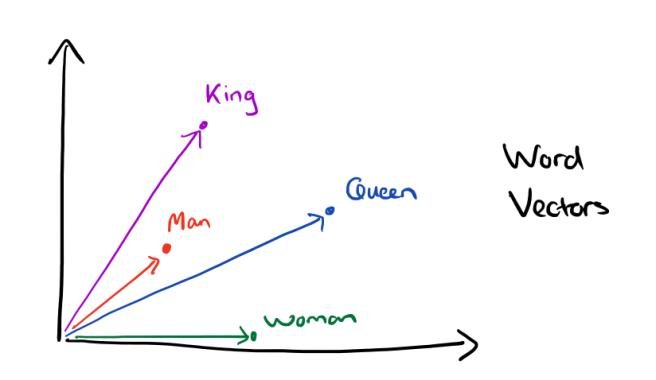
Уже лучше, но такие нейросетки очень сложно было тренировать и у них не было transfer learning, ты не мог взять одну сетку и перекроить так, чтобы было тебе удобно. Эту проблему частично решили, решая следующую задачу - "вот у тебя текст, здесь нету слова, что здесь должно стоять", название задачи очень вам знакомо, это те самые LM из Large Language Model. Результатом стали специальные массивы, которые переводили слово в набор чисел, он же embedding vector, с занятной особенностью, внутри было подобие "семантической логики". Так и начали юзать word embeddings. Это было первым решением задачи языковых моделей.
В принципе, даже машинный перевод уже получался неплохой, но такой же невыносимой лёгкости бытия как с картинками не было. Но потом придумали новый слой для нейросеток и вы по названию параграфа можете понять, что это за слой. Да, attention layer называется. Ребята придумали такую вещь: "когда происходит перевод, разные слова в разных местах влияют на то, какое слово нужно предсказать следующим, давайте тогда поможем Даше подсмотреть, на какие слова в данный момент нужно обратить внимание для предсказания!".
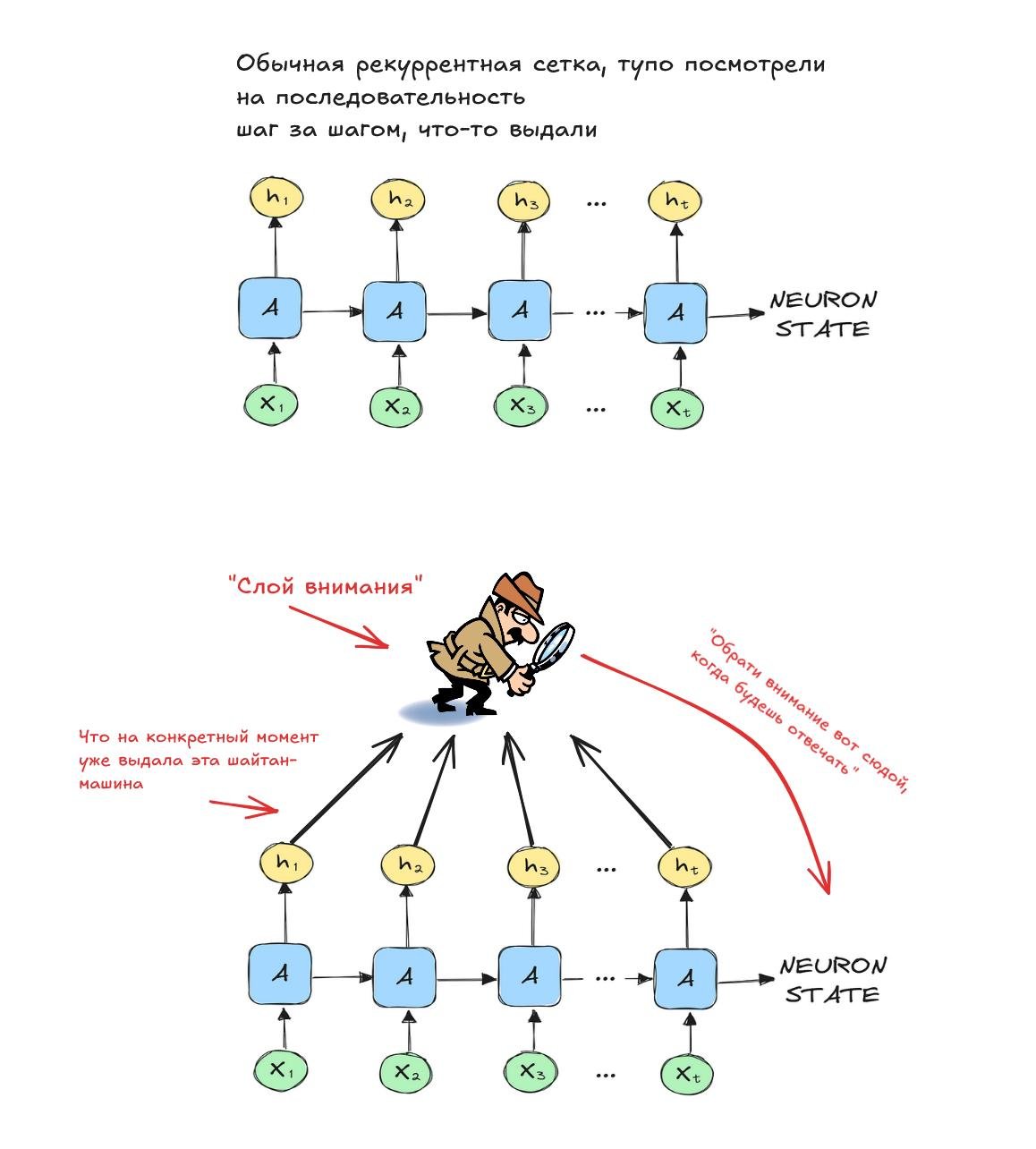
А потом Остапа опять понесло. А давайте мы выкинем нафиг всё, кроме этих самых attention слоёв и посмотрим что получится? Получилось. Оказалось, что Attention is all you need. Так называется статья, в которой сумрачные гении из Гугла создали первую нейросетку чисто на слоях внимания и назвали её трансформером. Самое главное - такой подход включил Transfer Learning уже и для работы с текстом! Теперь ты мог использовать 5-10 лет практик из компьютерного зрения, но теперь уже в абсолютно другом домене, а ИИ зиму отсрочили до 2022 года. А трансформеры даже для картинок приспособили. А трансформеры побольше стали Большими Языковыми Моделями, они же LLM.

Выводы
- Классические методы машинного обучения могут работать только с примитивным преобразованием текста
- Если в компьютерном зрении базовой задачей являлась задача классификации объекта на картинке, для текста базой является языковая модель.
- Важный концепт - embedding vector, оно же специальное представление в данном случае слов в виде здорового вектора со специальной логикой.
- Attention слой позволил создать архитектуру нейронных сетей, которая способна работать с текстом также как и с картинками. Появился Transfer Learning для текста.
Примерно на этом моменте чего-то супер-радикального нового, типа там класса задач новых порешать, с 2017го года в продакшене пока не появилось, однако история не закончилась и обрела сначала новые краски.
"Вокруг шум." Как появился генеративный ии-слоп из резонной прикладной задачи.
В части про компьютерное зрение я расписал то, как нейросетка решает базовую задачу определения объекта на картинке. Я там заикнулся про то, что есть перенос обучения и можно решать очень много разных задач компьютерного зрения таким же образом.
Так вот, не наврал. Если посмотреть на доходность куртки Хуанга и на архитектурку нейросетей, то они выглядеть будут как пирамидки, количество параметров в каждом слое всё меньше и меньше. Так вот, одну пирамидку переворачиваем, соединяем попарно все слои и вот теперь такая штука классно умеет предсказывать к чему относится каждый пиксель изображения. Называется такая сетка U-Net. Эта архитектура очень классно решает задачки, где нужно попиксельно что-то на картинке делать, например классифицировать. Но не только.
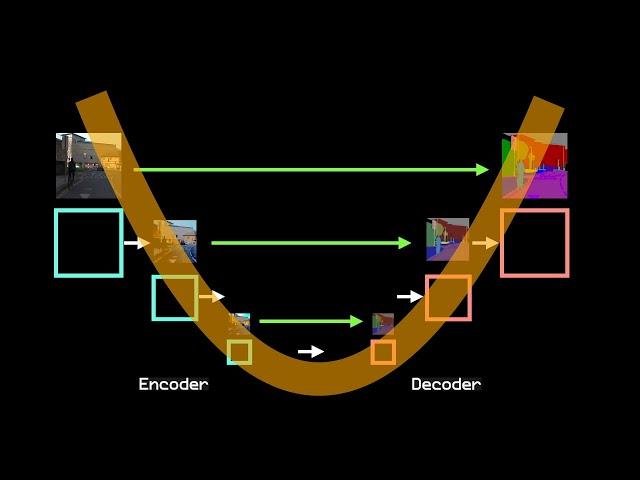
Мы пока решали дискриминативные задачи, там где есть правильный ответ и надо не ошибиться ну слишком сильно. Но есть еще другой класс задач - генеративный. Там нет цели, есть только путь, мы не пытаемся присвоить категорию каждому пикселю, мы пытаемся эти пиксели покрасить так, чтобы было ну примерно похоже на правду. И как это пытались решать?
Помните же старую поебу под названием thisXXXdoesnotexist? Вот та огромная кодла сайтов с генерированными картинками на случайную тему, там лица, песели, 18+ скорее всего точно было... Под капотом там была первая проба пера для решения генеративных задач. Там внутри архитектура GAN, Generative Adversarial Networks. Одна сетка пытается рисовать картинки, а вторая - пытается поймать за жопу первую нейросетку, учится отличать человеческий фурри-арт от ИИшного. Если их правильно замешать, то в теории (и в какой-то мере на практике) обе нейросетки не сговариваются друг с другом, а становятся лучше каждая в своей роли. Вот этот момент с "а давайте отдельная нейросетка будет делать разметку сама" запомните, нам чуточку попозже понадобится. Но да, вот таким соревновательным духом пытались решать задачу изготовления новых картинок из ничего.

И зачем я это всё рассказал? А здесь самый кек инженерного подворота не туда. Увы, нужно немножечко забежать в сторону, извините, по-другому тут не вырулить.
Гугловцы (да, опять) решились решать задачу денойзинга изображений. Ну зашакалили картинку, с кем не бывает. Еще ее заапскейлили и во-первых это некрасиво. Было бы очень классно старые картинки 144p расшакалить и довести ну хотя бы до божеских FullHD. Задача? Задача. Полезная? Полезная.
И решили поставить задачу так: берем картинку и шакалим до тех пор, пока не станет похожей на телевизионный шум. Модельку саму для решения этой задачи делали по архитектуре U-Net и заставляли этот фарш постепенно проворачивать назад. И знаете, получилось. Так и появились diffusion networks. Ничего нового, просто склеили костыли таким вот образом, чтобы заработало. Но тут Остапа понесло опять, вечно его у меня несёт...
Народ посмотрел на эти приколы и подумал, хм, а что если там шум - не совсем шум и есть какой-то потайной смысл? Нашли методы сделать так, чтобы он там оказался. Оказалось, что можно переводить вывод трансформеров, а точнее те самые embedding vectors из текста выше в тот самый шум, плюс на "удалении" шума всегда показывали модельке что вот - надо вот это вот самый эмбеддинг. И вот теперь у тебя рабочая схема "написал какую-то поебень и ее перевели в картинку". Так работают эти ваши Stable Diffusion XD Pro Max и прочие Grok Imagine. Повторяем до тех пор пока не получили нужный ответ. Мы получили ситуацию, когда задача с конкретным ответом костылями допилена для решения вообще задачи, которую с начала сделали по приколу, а оказалось что это породило ии-слоп. Как говорится, благими намерениями вымощена дорога в дурку.
Это на самом деле мой любимый пример, каноничный "инженеры решали одну задачу, решили другую, творят дичь третьи люди, а страдать от ии-шрота - нам."

Выводы
- Transfer Learning для отдельных задач позволил сделать хорошую рабочую архитектуру для задач, где нужно точно знать что за пиксель в каждой точке.
- Инженерное решение в виде модели, что за человека должна определять, насколько хорошо генератор картинок справляется с работой, было опробовано в GAN
- Спасибо вообще левой задаче, получилось перекроить старую архитектуру на новый лад, породить новый класс моделей компьютерного зрения, давший бум современного GenAI.
Transformers, everywhere in disguise. Как инженеры затыкали новой игрушкой вообще все проблемы, а в конце получили ЛЛМки
Штош, вернемся к тексту. Напомню, мы остановились на том, что появились Трансформеры, а если вы читаете подписи к этим наскоро скроенным мемам, то увидите что инженеры и исследователи нейросеток любили Улицу Сезам, модели назывались не иначе как BERT, ERNIE, BigBird и там дальше до кучи. Более того, буквально парой абзацев выше мы уже видели, что трансформеры помогли появлению GenAI. Есть целая серия статей под названием Unreasonable Effectiveness of... когда ретроспективно какой-нибудь исследователь смотрит и охреневает от того, что какой-то инструмент, какое-то решение ведет себя как мужской шампунь 7-в-1. Вот сука просто куда-угодно не присунь - работает. С трансформерами произошло тоже самое.

Я блин не шучу с этим мемом, буквально везде. Что-угодно, что можно представить в виде последовательности чего-то, там сука точно будет решение на трансформерах. Но там трансформеры еще цивильные, сложились в что-то что влезает хотя бы в сервак, за такие применения малайца и много лайков, вон, за AlphaFold2 даже Нобелевка получена Демисом Хассабисом и DeepMind пополам с химиком, что синтезировал белок которого в природе не находили вообще по чертежам из AlphaFold2. Это к сожалению последняя похвала здесь инженерам. "Когда у тебя в руках молоток, все вокруг кажется гвоздем", так и тут "когда в руках трансформеры, все вокруг кажется последовательностью". Набаловались и хватит, надо вернуться к истокам и дальше дрючить задачи текста.
Гугл (да, опять) выпустил для трансформеров архитектуру под названием Т5. Оказалось, что достаточно большой трансформер можно научить решать несколько задач сразу, запихивая название самой задачи в исходные данные.

Окей, мы еще больше ленимся, не делаем Transfer Learning, а тупо штробим наборы данных с вводной задачей. Кто-то очень ленивый и более умный был в OpenAI, ведь на самом деле даже на это забиваем.
На сцену к легендарному T5 выходит популярный внук RLHF, Reinforcement Learning with Human Feedback. И вместе получаем модель под названием InstructGPT. Источника всех наших бед с текстовой выдачей и предтечу того, что в ChatGPT и аналогах под капотом.

Вот такой "левый коронный, правый похоронный" получился внутри там. В чем суть - мы как в T5 тупо не заморачиваемся с датасетом под каждую задачу, хуярим все прямо без разбора. Это наш Бока. Данных много, целый Интернет, если ты это сделал первым и захайпился, шансы что тебе не дадут по жопе за пиздинг данных без спроса, снижаются. Но как это тренировать так, чтобы вышло нормально, где Жока?
Помните GAN? Нам нужен такой же дискриминатор, но теперь он будет не отделять ии-слоп от слопа человеческого, но будет ранжировать и оценивать выдачу самостоятельно. Как его тренировать?
Reinforcement Learning - вот уж где самый далекий реверанс во всей статье. Тут задача как раз подходящая - невозможно же сделать разметку для всего интернета, не говоря о том, что нужно отметить по несколько примеров, как трансформер ответит на его же части. Мы делаем бездушную машину для того чтобы оценивать это не самому, короче. Это Reinforcement Learning. А научить её оценивать мы можем приставив к ней душную машину, которая поначалу будет говорить, что там хорошо получилось, а что плохо, то есть тот самый Human Feedback. Охапка (размером с Интернет и атомный реактор электричества) дров, ЛЛМ готов.

Выводы
- Трансформеры - в каждой современной затычке. Если вы можете в своей задаче как-то вписать слово "последовательность" не просто так, там сработают трансформеры.
- Трансформеры с достаточным размером могут сами определять, какую конкретную задачу от них хотят.
- Чтобы получить из трансформера современную ЛЛМку, нужно две вещи: огромные количества данных и специальные модели, что будут делать для неё разметку вместо человека, обучающиеся постепенно копировать человеческую разметку.
"Очень дохрена умные и внезапно талантливые." Почему нейросетки стали огромными.
Готов, значит, наш ЛЛМ. Скоро спекусь и я. И к сожалению, ничего с этим не поделаешь. Ладно, давайте по порядку, а то если честно от этого всего у меня нормально так горит жопа как прикладника-эмэльщика.
Новых слоёв не придумано, то есть сейчас идет плотная гонка перепаковки одного и того же в разных комбинациях в надежде что сработает. Ладно, придумано, можете погуглить про MAMBA, но там не выдерживает конкуренции с ЛЛМками текущими. Как будто рисерч свернул не туда и народ тупо спонсирует куртку Хуанга на новую куртку в надежде сделать по факту тот же самый трансформер, но ещё больше. Почему так-то? Где прогресс, где креатив-то? Оказалось всё грустно, а по факту ещё и слишком ядрёно математически. И у меня на это 5 3 причины. Возможно будет 5, расскажу про три.
Первая причина - double descent. Один из важных концептов в машинном обучении - переобучение и обобщающая способность. В чём суть - если модель дохера умная, то вне зависимости от количества данных мы можем натренировать её так, что мы идеально всё предскажем, если это касается чего-угодно близко похожего на то, на чём тренировали. Проблема начинается там, когда мы пытаемся такой же моделькой предсказать нечто новое. Вот например если б было море пива, мы знаем, что мы бы были дельфином красивым. А если было бы море водки - то были подводной лодкой. Что же будет при море самогона?
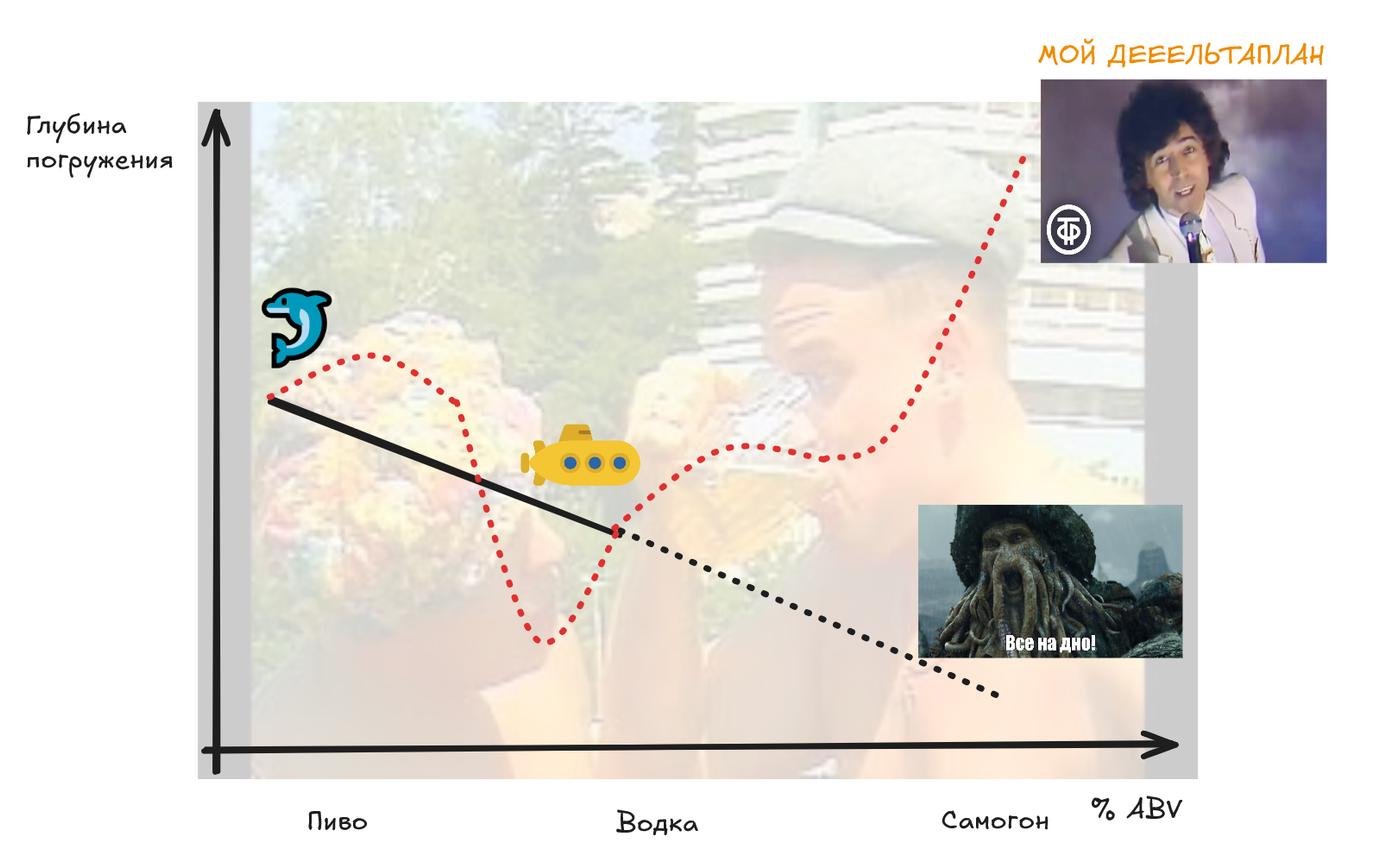
Если вы уже скипаете мои мемасы, там беда в том, что сложная модель предсказывает дичь типа "полетел на дельтаплане", хотя по идее логично должны устремиться на дно.
Мы столкнулись с overfitting, оно же переобучение. Если модель дохера умная, то она придумает очень заковыристые правила по которым будет предсказывать и провалится тогда, когда эти заковырки накинут чуши. Мы же хотим тренировать модельки так, чтобы у нас была возможность одинаково хорошо предсказывать как и то, что было, так и то что будет, это и есть generalization ability, обобщающая способность модели.
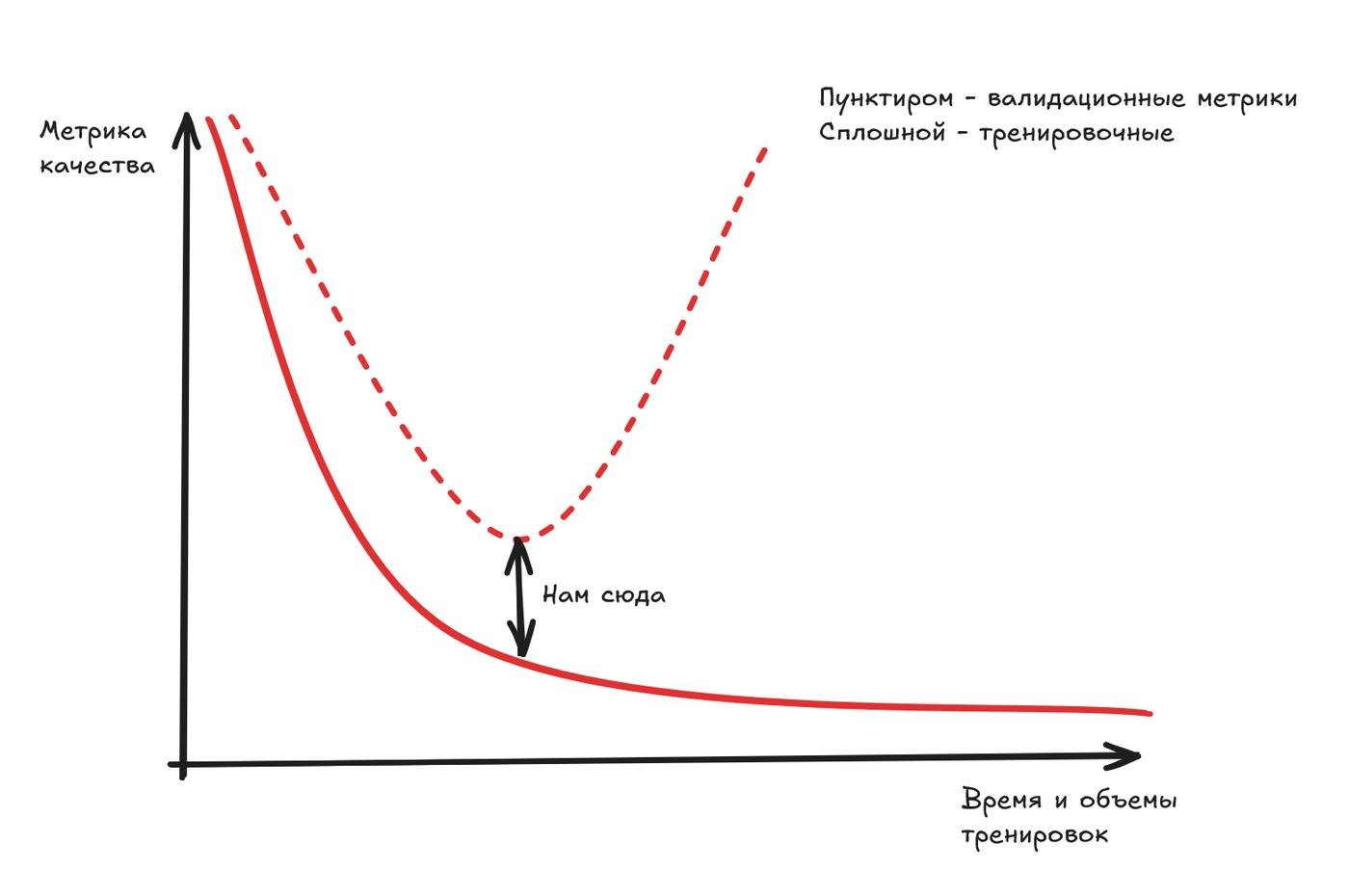
Вы прочитали предыдущий абзац? Так вот забудьте всё, чему вас учили. Оказалось, что если модель ОЧЕНЬ дохера умная, то есть внутри дофигица параметров что нужно тренировать, может происходить вот этот вот бурлеск категории Г:
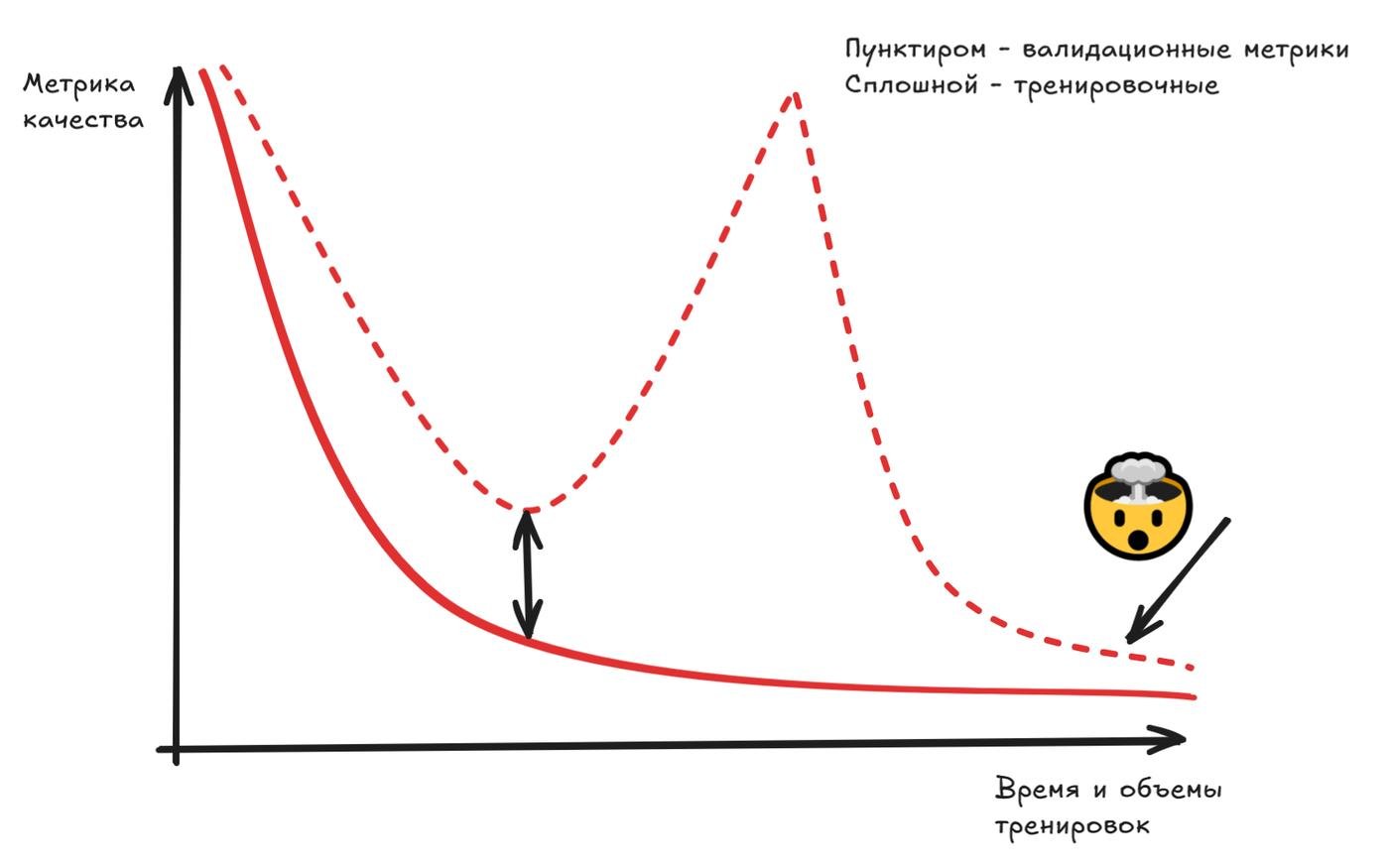
Если модель становится слишком сложной по дизайну, параметров там становится дохера, то каким-то магическим образом она сама может найти выход из переобучения и станет нормальной. Если у тебя валяется без дела биткоин-ферма, то тупо запускай на всё тренировку огромной нейросетки и крути это азино 3 топора пока не повезет. Ну не пиздец ли?
А вот и вторая причина. В 2019м году выходит Bitter Lesson Ричарда Саттона, корифея в машинном обучении. В 2020м, Kaplan Scaling Laws, и этот Каплан не желал петь нам про яхты и парус, это исследователь из OpenAI. Оба утверждают одно и то же - нужно построить зиккурат^W огромный датацентр, притом для качественных скачков в перформансе моделей нужно увеличивать его кратно. Просто если Bitter Lesson приводит к тому, что нейросетка - лучшая модель, потому что та может жрать много-много данных, Scaling Laws - это про то, что если мы хотим качественный скачок качества решений, то нужно взять всю твою бетховен-ферму и умножить количество карточек на 10, чтобы туда влезла соответствующая нейросетка.

Окей, у вас есть аргумент почему надо покупать свои собственные АЭС и делать Нвидию самой богатой компанией мира (скоро). Но всё равно, зачем?
Третья причина - emergent abilities. Оказалось, что когда трансформеры стали настолько огромными что не просто в дверь не вмещаются, они сами по себе научились решать задачи, не связанные с тем, что её просили. И вот они, emergent abilities. Когда моделька, которую учат на задаче "какое слово* должно быть следующим", внезапно иногда умеет в арифметику.

Самое страшное в этом всём то, что есть односительно современная математика, которая способна объяснить, почему так вообще должно было неизбежно произойти. Теория нелинейных динамических систем (распиарена как теория хаоса), плавно перетекающая в теорию сложных систем. Но нет худа без добра, ИИ зиму отсрочили по прикидкам ещё до 2027го, ведь АЭС, песок и станки для изготовления видеокарточек не кончаются пока. Пока кончаются только деньги на это всё.
Мы буквально в ситуации, когда хуевый экстенсивный рост, забивание хуя на инженерию и авось приносит позитивные результаты в решении задачек при помощи этих огромных нейросеток. Что с этим делать? Хуй знает. Как с этим работать? Об этом позже, пока что подведем мое горение жопы под список удобных поинтов.
Выводы
- Слишком большие модели машинного обучения иногда могут игнорировать переобучение -> тренируем модель дольше положеного
- Легче всего получить хороший результат с нейронками можно тупо удесятерив количество её параметров
- Слишком большие трансформеры можно тренировать на несколько задач одновременно
- Слишком большие трансформеры, ой простите, LLM проявляют emergent abilities, способность выполнять задачи, на которые модель изначально не была расчитана.
"Белые-белые перчатки к чёрной-чёрной коробочке." Как в 2026м году приходиться работать с этими гигантскими нейросетками.
Большие, мать его, Языковые Модели. Даже в двери не помещаются. И даже в GeForce 5090 не влезут многие. И что теперь? Как с этим работать-то?
Начиная с чатгопоты, модели стали слишком огромными, чтобы с ними работать как по-старинке. Как было-то? Здесь у модельки что-то подрезать, что-то дотренить, весело было короче. А сейчас так не поковыряешься внутри, приходится вертеться. И если честно, вертимся мы сейчас так, что нас в динамо-машину надо засунуть и от выхлопа можно запитать Токио, потом хватит и на Токио-3. И в общих словах про все эти выкрутасы я постараюсь расписать прямо щас.

Что же можно делать. Самое суровое, на черный день - finetuning. Допустим, вводных данных много, где-то даже разметка есть, доступ к модельке есть, можно докрутить веса. Чем и занимаемся. Но, у нас же не только сама LLMка в доступе, скорее всего ещё и та самая RLHF модель есть - ей тоже придется несладко. И это по сути единственный момент, когда мы что-то с самой моделью можем сделать. На проде видел раз в жизни.
Из более практичного, на помощь пришли прэколы диффузионных сеток. Те тоже разбухли дай боже. Но там нашли свой фокус - оригинал не трогаем, но делаем его копию сбоку. Помните как построены все нейросетки? Как слои, верно, возьмите с полки пирожок. Все эти слои берем и разбиваем бьём на два слоя поменьше. И запускаем тюнить модель так, чтобы оригинал не трогали, а вот нашу мелкашку правили куда нужно. Перед генерацией склеиваем их вместе тупо сложив. Получаем кратно меньше весов, чтобы это дело дотренировать и это потом подкручиваем когда надо. Название метода - Low-Rank Adaptation, она же LoRA.
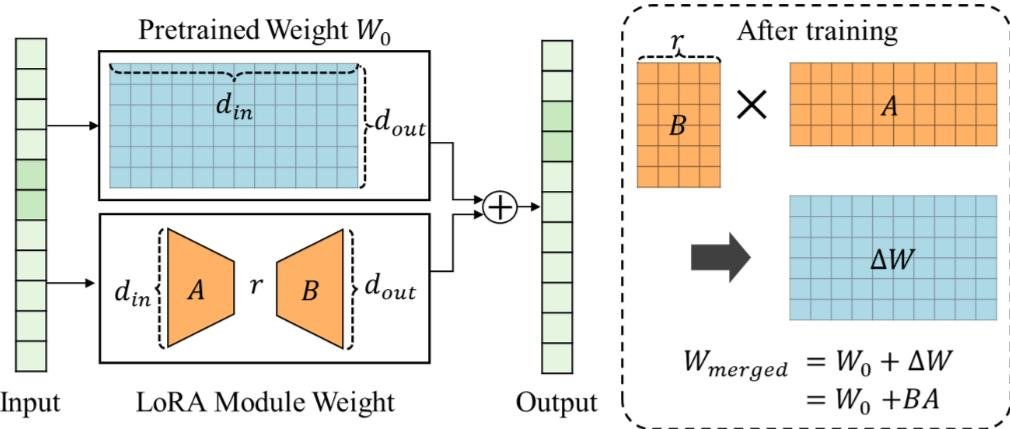
Ладно, а что если вообще не трогать модель. Оказалось, что увы так проще и это все и используют. И увы поэтому современный ИИ-девелопмент - это либо датасатанисты перекатывающиеся в бэкенд-инженеров с вытекающими в штаны, либо бэкендеры, пишущие обвязку для одного-двух API. Опишу только один пунктик здесь, потому что всё остальное работает точно так же - мы скрещиваем N разных моделей, колдуем и... получаем результат.

Не будем говорить про чудеса промптинга, просто объясню что такое RAG и закончим с этим. В принципе, все эти клоды, чатгопоты и прочие гроки хорошо работают уже со здоровым промптом. Лишь бы ты релевантные данные туда засунул бы. Вот был бы вариант их искать... а, ну да, у нас есть трансформеры, есть их эмбеддинги. Крошим всю базу данных на куски лишь бы влезло и сос мыслом, перегоняем их через трансформер на ваш вкус, загоняем это всё дело в базу данных спец. типа, что умеет быстро по эмбеддингам искать то, что тебе нужно - ну вот теперь у тебя не просто Generation, а Retreival Augmented Generation.
И так со всем. Нужно оценить качество работы ЛЛМки, а людей мало? Окей, берем другую ЛЛМку, она рассудит. Нужно, чтобы модель не посылала клиента? Берём отдельную модельку. Анонимизировать входные данные? Кого вы обманываете, никто этим не занимается Есть решения и тут. Современная продакшен-работа с LLM - это натурально тот самый low-code/no-code конструктор из разных запчастей, зачастую других LLM и прочих моделей. И в этом проклятом мире нам с вами жить.
Выводы
- LLMки начались с того, что к трансформерам большого размера прикрутили ещё и промежуточную модель, что училась размечать генерацию LLMок вместо человека.
- LLMки слишком огромны, чтобы с ними можно было работать напрямую
- Даже самые инвазивные методы дотренировки LLMок под ваши задачи в подавляющем количестве случаев не трогают напрямую оригинальную модель, а делают довесок сбоку
- Современная практика работы с LLM - довесить-нарастить сбоку от неё все инструменты, чтобы загнать в ввод к ней как можно больше полезной информации.
Вы находитесь здесь
Фух, сводим:
- Машину не обязательно кодить напрямую, чтобы получить код, кое-как решающий нужную задачу при помощи чьей-то матери и матстата
- Нейросетки - подвид моделей машинного обучения, которые по построению комбинация самой базовой модели из статистики, сложенная хитрым образом. А не туча "if", заколебали уже
- Нейросетки оказались классным инструментом для решения разнообразных сложных задач малыми усилиями, спасибо Transfer Learning. Выяснили когда решали задачи компьютерного зрения чисто инженерным способом.
- Когда были сделаны трансформеры, Transfer Learning появился и для задач обработки текста.
- Чем больше нейросетки, тем более неожиданные задачи она способна решать. Чтобы нейросетки умели что-то новое, рост их сложности - кратный, они должны расти в разы.
- Картиночный ии-слоп появился в том числе потому что когда-то инженеры перебирали нейросетки для решения довольно безобидных задач, типа удаления цифрового шума из изображений.
- Мы находимся на моменте, когда с 2017го года не было придумано ни одного кардинально нового слоя нейросеток, индустрия до сих пор закидывает вычислительными ресурсами всё, что нужно решить и это, сука, работает.
- Современные базовые модели настолько огромны, что вся разработка - вокруг них, а не внутри.
И это всё за какие-то 15 лет после первого бума.
Я надеюсь, теперь вы понимаете, почему нейросетки работают и почему их так активно юзают. Вы можете идти читать всякие умные статьи по этой теме с большей душкой и вниманием к деталям. Или не идти читать их. По крайней мере теперь вы будете понимать, почему все так носятся с LLMками и почему Nvidia продаёт видеокарты по цене почки.
Да, я трачу двести баксов в месяц чтобы делать так:
Спасибо за статью, мне как непосвященному в принципы работы LLM-ок было очень интересно, теперь хотя бы поверхностное понимание есть.
А по поводу того, что с 2017-ого не было придумано ничего кардинально нового в этой области: попытки есть вообще? Или будут абузить увеличение используемых мощностей, пока это не упрется в какой-то потолок?