

Мне нравится экспериментировать с искусственным интеллектом и делиться своими впечатлениями в LinkedIn. Не ожидаю от этих экспериментов ошеломляющего успеха, но такой подход помогает мне лучше осмысливать проделанную работу. Особенно ценно осознавать свои ошибки или недочеты, когда пост уже опубликован. Это стимулирует к дальнейшему углублению в тему и поиску решений. Вот так за год в итоге у меня получилось выпустить три подкаста от начала до конца сгенерированные ИИ.
Скоро я буду рассказывать про это в одном подкасте про ИИ. Так что кидай в коментах, если что-то хочется послушать в деталях или просто проговорить голосом.
Собираю технологии и техники
Мое увлечение началось в марте прошлого года. Сначала я погрузился в мир prompt engineering, стремясь улучшить качество моих англоязычных постов. Затем я перешел к экспериментам с OpenAI API и LangChain, следя за каждым их обновлением и новостью в блогах. Это было реально очень естественно и легко. Мой респект обоим сервисам.
В какой-то момент отец рассказал как он подтягивает английский для поездки в Великобританию и просит Google Translate озвучить текст. На тот момент их синтезатор речи звучал жутковато. Это заставило меня задуматься о возможностях ИИ в генерации голоса. Неужели ИИ, способный создавать тексты, изображения и видео, не может качественно синтезировать голос? Оказалось, что может! После нескольких сервисов я остановился на ElevenLabs.
ElevenLabs (попиарю, можно скипануть)
Из того, что оказалось для меня очень полезным, — это огромная библиотека голосов на любой вкус. Иногда возникают проблемы с озвучкой украинской или русской речи, поэтому нужно выбирать, какой голос и модель лучше подходят. На данный момент они предлагают следующие опиции:
- Пол (мужской, женский)
- Возраст (молодой, средний, пожилой)
- Акцент (американский, британский, африканский, австралийский, индийский, иногда случайно можно получить грузинский).
- Сила акцента (спектр от низкого до высокого)
- Эмоции (Ха-ха, Ммм и т. д.)
- Prompts
- Украинская (!) озвучка
В общем, я доволен и рекомендую этот сервис всем, кто интересуется text-to-speech. Ребята очень постарались. (Скрестим пальцы в ожидании поддержки беларуского языка — я написал им запрос.)
Собираю Идею

К лету 2023 года у меня были все основные наработки для создания подкастов. Но мне не хватало той последней творческой искры — пока я не услышал один из эпизодов Latent Space. Тогда у меня возникла идея: а что, если генерировать подкаст из рассылки с помощью искусственного интеллекта?
Для справки, моя жена Оли Морозова ведет рассылку Expresso Today. Это не просто дайджест новостей, а яркий коллаж субъективности, иронии и юмора. Я его обожаю и всем рекомендую подписаться.
На самом деле, я очень доволен что Олин проект был первый, потому что у нее очень своеобразный подход к дизайну рассылки: очень много картинок, интересные подписи к ним, юмор, объявления в случайных частях и уникальное форматирование всего этого добра. Поэтому, обычные парсеры сразу были отправлены на полку и пришлось контекст разбирать с помощью ИИ.
Интересный факт, что на тот момент ИИ уже умел распознавать авторские права и иногда наотрез отказывался работать с кусками тексов песен или цитат, которых у Оли тоже достаточно.
Как все устроено
Триггер: каждый выпуск рассылки запускает пайплайн. Чтобы абстрагировать почтового провайдера и процесс реализации, я полагаюсь на API Nylas. В качесте платформы работы с данными использую Databricks.
Структурирование: используя модели OpenAI GPT-3.5 и GPT-4, неструктурированное содержимое рассылки организуется в связные сегменты — резюме, новости, рассказы, рекламу. Это требует структурированного вывода в json формате. (Я был очень рад, когда в последнем апдейте OpenAI улучшил качество такого вывода.)
Сценарий подкаста, перевод и стилизация: GPT-4 преобразует каждый блок в реплики подкаста для двух ведущих с плавными переходами от одной темы к другой. Переводом и стилизацией занимается модель GPT-3.5. Стили помогают не только придать контектсу окраску, но и делает модель более "поддатливой" для моих задач. Интересный факт, что работа со стилями пришла ко мне не сразу, а после разговора с фаундером capital.com Виктором Прокопеней, который собственно и предложил поиграться с этим.
Синтез речи: для этого я использую синтезатор речи ElevenLabs.
Распространение: последний этап — загрузка аудио на платформу transistor.fm, которая распространяет его по подкастинговым сервисам, вроде Spotify или Apple Podcasts.
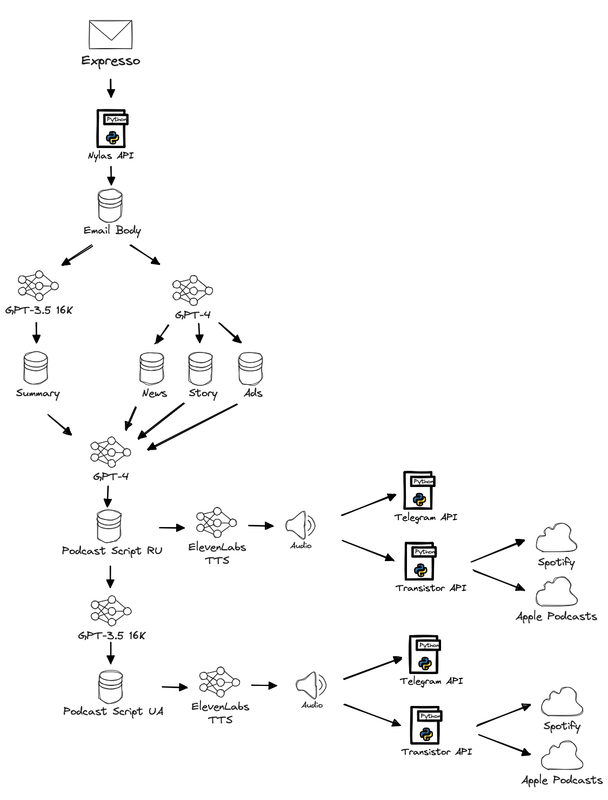
«Искусственный интеллект здесь не просто инструмент. Он — соавтор, редактор и переводчик, который преобразует тексты и делает их идеальными для восприятия на слух. Он избавляется от повторов, улучшает формулировки и старается сохранить уникальный авторский стиль. Иногда результаты получаются смешными и странными — мне это нравится. Моя любимая часть — это неправильные ударения, цифры и приветствия невпопад. Это всё уйдёт со временем, когда системы станут ещё лучше и сложнее»
Что получилось
Сейчас у меня уже три подкаста.
- Оля и Штучный Интеллект Самый первый и дорогой сердцу новостной подкаст на основе рассылки Expresso Today на трех языках.
- Phoebe's Bitmingham Beat Подкаст про новости из мира крипты.
- AI Aficionados Недавно запущенный подкаст про тренды в ИИ.
Что делать дальше?
Есть некоторые идеи. Но было бы здорово послушать и чужое мнение.
В рассылке Оли используется множество изображений, что делает идею применения мультимодальных моделей для распознавания контекста особенно привлекательной. Хотя с мемами сложно достичь значимых результатов, эксперимент стоит того.
При оценке качества и выявлении галлюцинаций представляются два подхода. Первый — работа со структурированной информацией и конкретными данными, такими как цифры, даты, имена. Второй — проверка блоков информации на соответствие друг другу с помощью более продвинутых или специализированных моделей. Тут есть все еще есть вопросы.
Сложность передачи юмора и уникального стиля Оли — задача не из легких. Простое указание ИИ "сохранить шутки автора" не работает. Например, был случай с упоминанием благословения однополых пар церковью. В оригинале был лишь намек на сарказм, но ИИ превратил это в полноценное стендап-выступление, добавив шутки, которых в тексте не было.
По поводу продвижения подкастов: использование ИИ для создания постов в TikTok — перспективная идея. С помощью Content Posting API можно публиковать видео, созданное через модели Stable Diffusion. Это лишь первый шаг. В зависимости от контента подкаста можно генерировать истории и хэштеги, специально адаптированные под контекст выпуска.
Я человек простой. Вижу упоминание Оли Морозовой - ставлю лайк.
Я пытался слушать этот подкаст после рекомендации у Оли в рассылке, и чет прям совсем какая-то долина крипоты была, не осилил. Хотя само техническое решение клевое и об этом интересно читать:)
Мы сейчас живём в обществе, где хорошие данные и идеи ценнее убитого мамонта. Некоторые идеи настолько хороши, что люди готовы запихивать тебе в глотку денег, чтобы ты с ними поделился. Взять, например, книги про Гарри Поттера, Акунина или Игру Престолов. Некоторые идеи - так себе.
Хорошие подкасты/ТГ каналы или тиктоки взлетают благодаря тому, что в них есть идея и исполнение. Идея не обязательно должна быть сложной.
Ну так вот, эта самая идея - это вещь достаточно удивительная. Если ты сам придумал сказку про Шестилапую Электрическую Кошку и Дракона, но при этом никому про эту сказку не рассказал, то эта сказка существует только у тебя в голове, и никто никогда про неё не узнает. Как и ГПТ не сможет рассказать эту сказку, ведь генератор не подключен к твоему сознанию, и не видит того, о чём ты думаешь. А если ты возьмёшь и напишешь/расскажешь/запишешь аудиокнигу, то твоя идея появится у других людей. И некоторые будут готовы тебе платить за неё.
Это то, что генеративные системы делать не могут. У ChatGPT есть большой набор данных. Из этого набора эта штука выбирает себе следующее слово. Да, несомненно, ГПТ ответит на вопрос “придумай сказку”. Но сказка эта будет ну совсем уже не новой. А зачастую - скатится в крипоту. Как во сне после пол-бутылки водки. Тебе захочется пойти и найти гуся, чтобы опорожнить в корыто пальто для лошади. Выглядит, как что-то осмысленное, но по факту никакущее и блёклое. (Тут надо оговорится, что так как через ГПТ прогнали много данных, то выглядит так, что он придумывает новые вещи, хотя на самом деле, просто рекомбинирует уже существующие).
Прикол в том, что ГПТ может очень хорошо помочь с исполнением. Подправить стиль, подтянуть ошибки, перевести на другой язык. Когда ты создал основную идею и описал её боту, то тот может тебе нагенерить гигабайты текста. Только любой, кто писал что-то в “соавторстве с гпт” прекрасно знает, что надо постоянно держать бота в узде. Он через два-три предложения начинает уходить не туда.
И чем лушче ты описываешь ГПТ свою идею, тем лучше он будет генерить контент. Тебе самому надо придумать всю историю, от начала до конца. А уже потом можно будет пихать всё это в ГПТ, и просить его переписать, допилить или доделать. И даже в этом случае, твой текст будет усеян различными ненужными словами и оборотами, да и стиль превратится в “разговаривающего робота” вместо “интересного рассказа”.
У вас как раз и получилось очень хорошо в данном случае использовать ГПТ как инструмент. Одна пишет статьи - другой генерирует их в ГПТ. Проблема с шутками - как раз и заключается в том, что Олины идеи (конкретная шутка) оказываются “размазанными” по тексту. Я бы рекомендовал ручную правку. Потому что эти шутки - это и есть идея автора. Просто брать текст сгенерированной статьи и править руками небольшие вещи, например, ту же шутку про церковь. А вещи побольше - можно просто заставлять переписывать с уточнениями, пока не будет более менее похоже на правду.
А что касается вот этой конкретно части:
Я бы рекомендовал убрать ГПТ из соавторства. Поставить туда брейкпоинт, и просто читать получившийся текст, прежде чем запускать его дальше в работу.
И, у тебя переводчиком работает 3.5. Я, если честно, из 4.0 не смог выжать хороших переводов. Несмотря на то, что переводил с русского на английский, текст получался нечитаемым. В основном потому, что ГПТ не мог справится с эпитетами и смысловой нагрузкой оригинала.
А так - эй! Поздравляю! У тебя есть слушатели. Причём, относительно не мало. Ты не пошёл по пути 90% идиотов на хабре, которые просто пишут в ГПТ "Напеши статью для Хабра, и вставь ссылку на мой ТГ канал". Мне кажется, что чем больше ты будешь корпеть над нагенерированным текстом и чем больше ты его будешь править ручками, тем лучше и интереснее будет подкаст.
Спасибо за офигенный пост! :)
А для чего использовал Databricks? Он предоставляет удобный инструментарий для пайплайнов с chagtpt?
И если решишь написать отдельный пост с более детальным обзором архитектуры, кодом, промптами - будет вообще бомба
Пост навеял воспоминания о 2018г, когда я уволился с работы, чтобы делать "стартап" на пару с бывшим коллегой. Проект назывался "Voizzy".
Суть такова: мобильное приложение с подписками на каналы. Каналами являлись популярные новостные сайты типа TechCrunch или Медузы. Но их не нужно было читать, потому что статьи с сайтов были озвучены TTS от Amazon и Yandex. Так что это было что-то вроде маленькой платформы с подкастами.
Также можно было сделать свой канал прямо в Voizzy, слушать самому и давать слушать другим. Редактор статей был внутри приложения и в нём была вторая главная фича – копирование ссылки на текстовый контент. Бэкенд сначала сверялся с базой, если такая ссылка уже была, то предлагалось сделать репост. Если это новый контент, то он озвучивался на лету.
Это была главная техническая проблема, которую мы решили. Время ожидания даже для огромных статей составляло около 5 секунд. Т.е. приложение можно было использовать, чтобы освободить руки, например, за рулём.
Мы выпустили релиз под iOS и Android и не придумали, что делать дальше. Такой вот стартап.
Больше технических подробностей от кофаундера тут.
Классная статья! Здорово придумал.
Послушал сгенерированый подкаст (не целиком, пару минут). Очень ухо резанула интонация ИИ.. понятное дело, что все это уйдёт в будущем с допиливанием библиотеки, но в этой итерации очень сложно слушать. Она каждое предложение заканчивает с одинаковым придыханием что ли.. ну кто слушал - тот поймёт. Но конечно огромный разлёт с тем что умела "гугл баба" лет пять назад.
Не в тему поста (он охуенный), но подумалось:
Чем больше "успехов" делает ИИ в области креатива, тем кринжовее и отвратительнее становится результат.
Сама идея того, что какое-то произведение было сделано с его использованием, попахивает читерством и наебаловом. Дескать можно по-старинке, вложить душу и труд, а можно просто нейросеткой пройтись. Инициатива обязательной маркировки в этом смысле абсолютно логична.
В это же время в сугубо прикладных областях ИИ отлично себя показывает, взять тот же DLSS в видеокартах.