

Предисловие
Привет, я Игорь, автор канала Сиолошная — вы можете меня знать по моим детальнейшим лонгам про AI на Хабре.
Вообще по-хорошему про работу, про которую я буду рассказывать тут, стоило бы написать лонг, но у меня сейчас нет времени на вычитку, подготовку картинок, итд (только успел придумать хайповое название :kekeke:). У меня заметок на 7 страниц накопилось, и это без картинок. поэтому будет усечённый формат, где я опущу часть деталей
Но возможно кому-то захочется написать нормальный качественный пост могу поддержать редактурой и фидбеком.
Очень хорошим фоллоу-апом этого поста будет мой лонг про FunSearch, который работает немного схоже, но в разрезе программирования, а не биологии.
Towards an AI co-scientist
В статье представляют AI-ко-саентиста (учёного, но я буду использовать слово саентист), мультиагентную систему, построенную на обычной, не дообученной специально, версии Gemini 2.0. Ко-саентист — виртуальный коллаборатор, призванный помочь в генерации новых научных гипотез и предложений исследований.
В погоне за научными достижениями исследователи-люди сочетают изобретательность и креативность с проницательностью и экспертными знаниями, основанными на научной литературе, чтобы генерировать новые и жизнеспособные направления исследований. Во многих областях это представляет собой задачу необъятной широты и глубины, поскольку сложно ориентироваться в быстро растущей библиотеке научных публикаций, интегрируя идеи из мало/незнакомых областей. Тем не менее, преодоление таких проблем имеет решающее значение, о чем свидетельствуют многочисленные современные прорывы, возникшие в результате трансдисциплинарных усилий.
Самый известный тут пример, пожалуй — это Нобелевка 2020-го год по химии за технику модификации генов CRISPR-Cas9. Если упрощать, то два основных (и очень разных) открытия произошли достаточно давно, но никому не приходило в голову их совместить — либо это было неочевидно, либо было столько других кандидатов на совмещение знаний, что не счесть.
Ко-саентист призван помочь в определении гипотез для проверки и составлении протоколов экспериментов. Чем мне очень понравилась работа Google — это тем, что они прошли даже не одну, а три последние мили, и доказали на практике, что гипотезы, которые выдала модель, при тестировании в пробирке в реальной лаборатории показывают реальные результаты. Спойлер: AI НАШЕЛ НОВОЕ ЛЕКАРСТВО ОТ РАКА!!! (не шутка, но слегка преувеличенный факт). Но об этом позже.
Высокоуровневая картинка
Итак, что же это за система? Как написал выше, она состоит из нескольких агентов — то есть одной и той же модели Gemini 2.0, но с разными промптами, инструментами (поиск по базам / по интернету / запись в долгосрочную память / итд) и частотой их запуска. Ко-саентист анализирует полученную от человека цель в конфигурацию плана исследований (за это отвечает агент-супервизор).
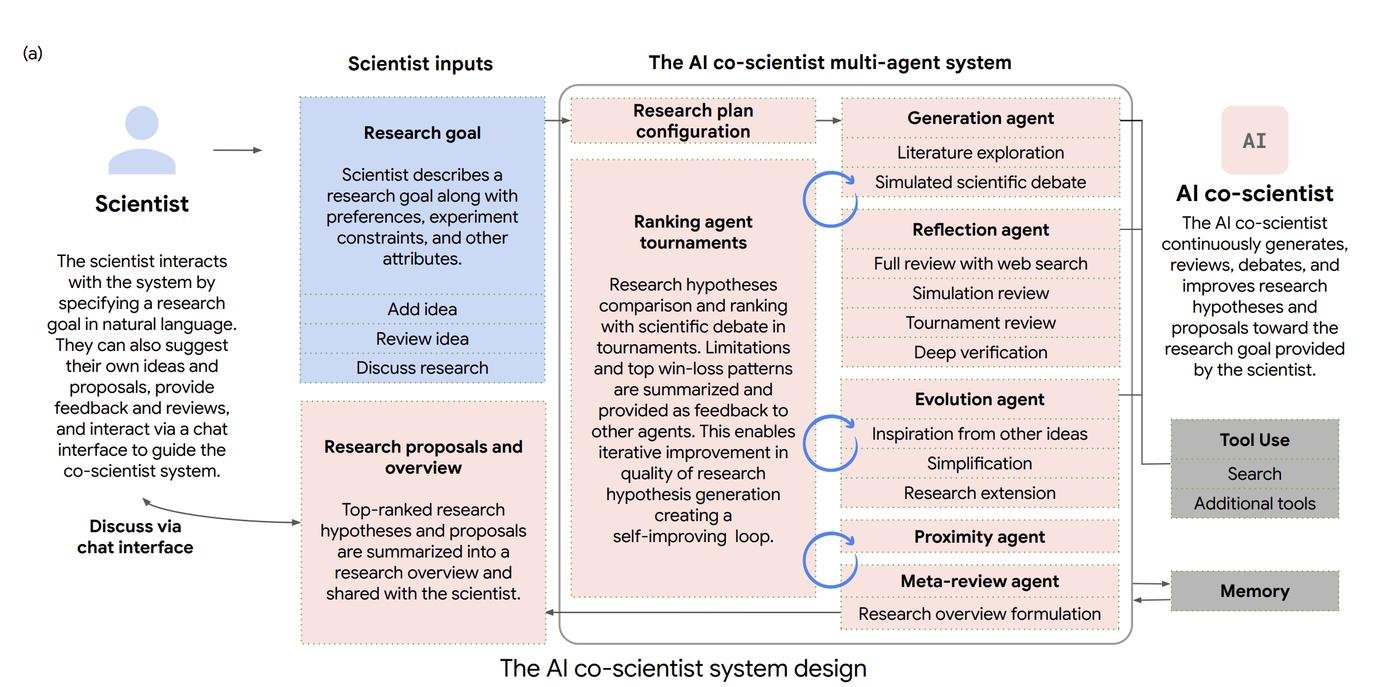
Агент-супервизор назначает специализированных агентов в очередь и выделяет им вычислительные ресурсы. Такая конструкция позволяет системе гибко масштабировать вычисления и итеративно улучшать свои научные рассуждения в направлении указанной цели исследования. Например, в самом начале имеет смысл дать больший вес (ресурсов агенту) просто генерации рандомных гипотез, а на более поздних стадиях важно получать критику, применять её и адаптировать уже существующие гипотезы, внося уточнения и правки.
Дальше существует ещё 6 агентов: Генерирующий, Рефлексирующий, Ранжирующий, Эволюционирующий, Группирующий и Мета-оценщик. Про них вкратце, а потом про самый важный
Генерирующий агент:
— Агент инициирует процесс исследования, генерируя начальные области фокусировки, итеративно расширяя их и генерируя набор начальных гипотез и предложений, которые касаются целей исследования
— Ему доступен поиск по интернету и базе статей, однако на данный момент она содержит лишь публичные данные; статьи из платных журналов сюда не включены, что накладывает ограничения, зато предоставляет зону роста на будущее
— Во время генерации агент может симулировать дебаты между экспертами, добавляя «Критика» в процесс генерации (просто другой промпт для LLM)
Рефлексирующий:
— оценивает существующие экспериментальные данные за или против конрктеной гипотезы и строго проверяет новизну, правильность и качество полученных результатов.
— делает он это в три этапа: 1) Начальное ревью (LLM просто сама даёт оценки по новизне, правильности и качеству ) 2) полное ревью (то же самое, но теперь с поиском по всем статьям) 3) Глубокое верифицирующее ревью, в ходе которого гипотеза раскладывается на независимые низкоуровневые предположения, которые оцениваются по отдельности, опять же, через поиск по литературе
— Также в Рефлексирующего подаётся результат работы Ранжирующего агента (об этом ниже), что позволяет выявлять часто повторяющиеся проблемы и зоны улучшения гипотез (чтобы не делать одни и те же ошибки снова и снова)
Ранжирующий:
— это самое интересное, мне кажется, вся изюминка системы тут
— Ранжирующий выбирает пары гипотез и проводит между ними полноценные дебаты (LLM + промпт «твоя задача защитить или атаковать вот эту позицию»), а затем оценивает победителя
— по результатам большого количества попарных «сражений» строится рейтинг на основе системы Эло (как в шахматах).
— Чем больше рейтинг, тем, видимо, легче гипотезу отстоять в дебатах (то есть или там мало к чему есть подкопаться, или все аргументы имеют крепкую базу с опорой на литературу)
— Так как суммарное количество гипотез очень велико (авторы, к сожалению, никак не описывают порядок величин даже приблизительно), и провести игры каждый-с-каждым не получится, то здесь внедрено две оптимизации: 1) гипотезы с высоким рангом проводят более длинные дебаты (до 10 шагов в диалоге), а с низким — 1 или 3-5 2) гипотезы чаще сравниваются с похожими на них (то есть среди некоторой группы схожих идей проявляется самая сильная). Группировка по похожести делается Группирующим агентом, он строит граф близости (никаких деталей в статье нет)
— результаты дебатов суммаризуются и подаются в Рефлекирующего
Эволюционирующий агент постоянно совершенствует и улучшает существующие гипотезы и предложения, используя:
— упрощение
— объединение/комбинацию гипотез
— и ещё пару методов
Наконец, Мета-оценщик:
— агент работает с результатами дебатов в турнире и находит общие закономерности, выявленные в ревью и дебатах
— Объединяя информацию из всех обзоров, метаобзор предоставляет ценную обратную связь Рефлексирующему
— также в генерируемом мета-обзоре очерчиваются потенциальные области и направления исследований, обосновывается их важность и предлагаются конкретные эксперименты в рамках каждой области. Каждая область включает иллюстративные примеры тем.
Тесты и эксперименты
Далее систему тестировали в end-2-end режиме на трёх реальных исследовательских задачах, а результаты отсматривались специалистами в этих областях.
Тест первый.
Тестирование и одобрение новых лекарств — очень долгое и дорогое занятие; поэтому существует drug repurposing, когда уже одобреное и работающее лекарство пытаются использовать для чего-то, для чего оно изначально не предназначалось. Задача очень сложная и требует экспертизы в нескольких дисциплинах.
AI-ко-саентисту дали задачу найти лекарства из числа одобренных (примерно 2400 штук) для лечения одной из 30+ форм рака. Затем 30 самых высокооценённых гипотез отсмотрели эксперты-онкологи, для каких-то из них произвели анализ на основе методов вычислительной билогии), и закончили экспериментами в мокрой лаборатории с использованием линий раковых клеток (не полноценных опухолей).
Если интересно, вид рака, для которого проверялись гипотезы, был «Острый миелоидный лейкоз» (AML), редкий агрессивный вид рака крови. Так вот, было отобрано 5 лекарств, 3 из них показали результаты, и один показался прямо очень многообещающим. Я не буду притворяться, что что-то понял из медицинских объяснений в статье, поэтому больше деталей дать не могу 🤷♂️ что и как они замеряли, что за графики, по которым можно увидеть действие — хз.
Это одно многообещающее — Binimetinib, который уже одобрен в качестве лечения для матастазирующей меланомы.
«Этот результат показывает, что препараты, предложенные ко-саентистом, являются многообещающими в качестве жизнеспособных кандидатов для клинических испытаний на повторное использование лекарств».
«ко-саентист смог предложить нового кандидата для лечения AML, помимо тех, которые могли быть выбраны с помощью других существующих подходов и экспертных источников. Это говорит о том, что система может быть способна генерировать новые, многообещающие гипотезы для исследователей»
«Даже немотря на то, что гипотеза, созданная ко-саентисом, хорошо проверена онкологами и подкреплена доклиническим обоснованием и сильными экспериментами в пробирке, это не гарантирует эффективность и успех в клинических испытаниях. Такие факторы, как биодоступность препарата, фармакокинетика, побочные эффекты и критерии отбора пациентов, могут повлиять на результаты последующих испытаний»
Тест второй.
Деталей мало, «системе было поручено разработать экспериментально проверяемые гипотезы относительно роли эпигенетических изменений в фиброзе печени, а также определить препараты, воздействующие на эпигенетические модификаторы, которые можно было бы использовать для лечения фиброза печени».
Тут люди отобрали 3 из 15 самых высокооценённых гипотез, провели эксперименты, тоже все красиво, а детали ожидаются в статье, которую скоро напишут совместно со Stanford University, что, как мне кажется, указывает на уровень — если бы там совсем ничего нового не было, или что-то не работало, как ожидается, скорее всего так бы не делали.
Тест третий.
Тут сосредоточились на на создании гипотез, объясняющих механизмы эволюции переноса бактериальных генов, связанные с устойчивостью к противомикробным препаратам (AMR) — эволюционно развитыми механизмами микробов, позволяющими им противостоять препаратам для лечения инфекций.
Но тут произошла такая штука — вот прямо в феврале одна из исследовательских групп написала статью с реальными экспериментами, и они получили результат, который собираются публиковать в престижных научных изданиях. Но эта статья и результаты ещё нигде не были размещены онлайн, то есть модель не могла их найти.
И так вышло, что как раз одна из топовых гипотез, предложенных моделью, и показала себя в реальных экспериментах, проделанных исследователями (Fleming Initiative и Imperial College London) независимо.
BBC взяли интервью у одного из авторов не-AI-шного исследования, и я так понял, что это не гугловцы придумали именно такой запрос задать в ко-саентиста, а просто профессор был знаком с кем-то из команды, которая делала инструмент, и из любопытства (или его попросили) закинул свой самый свежий тезис, вот прям в котором он очень хорошо разбирается, и по которому у него готовится статья с экспериментальным подтверждением.
«Полное десятилетие, потраченное учеными, также включает время, которое потребовалось для доказательства исследования, что само по себе заняло несколько лет. Но они говорят, что если бы у них была гипотеза в начале проекта, это сэкономило бы годы работы»
«Дело не только в том, что главная гипотеза, которую ко-саентист выдвинул, была правильной», — сказал профессор. «Дело в том, что он выдвинули еще четыре, и все они имеют смысл. И об одной из них мы даже никогда не думали, и теперь мы работаем над ней».
Картинки
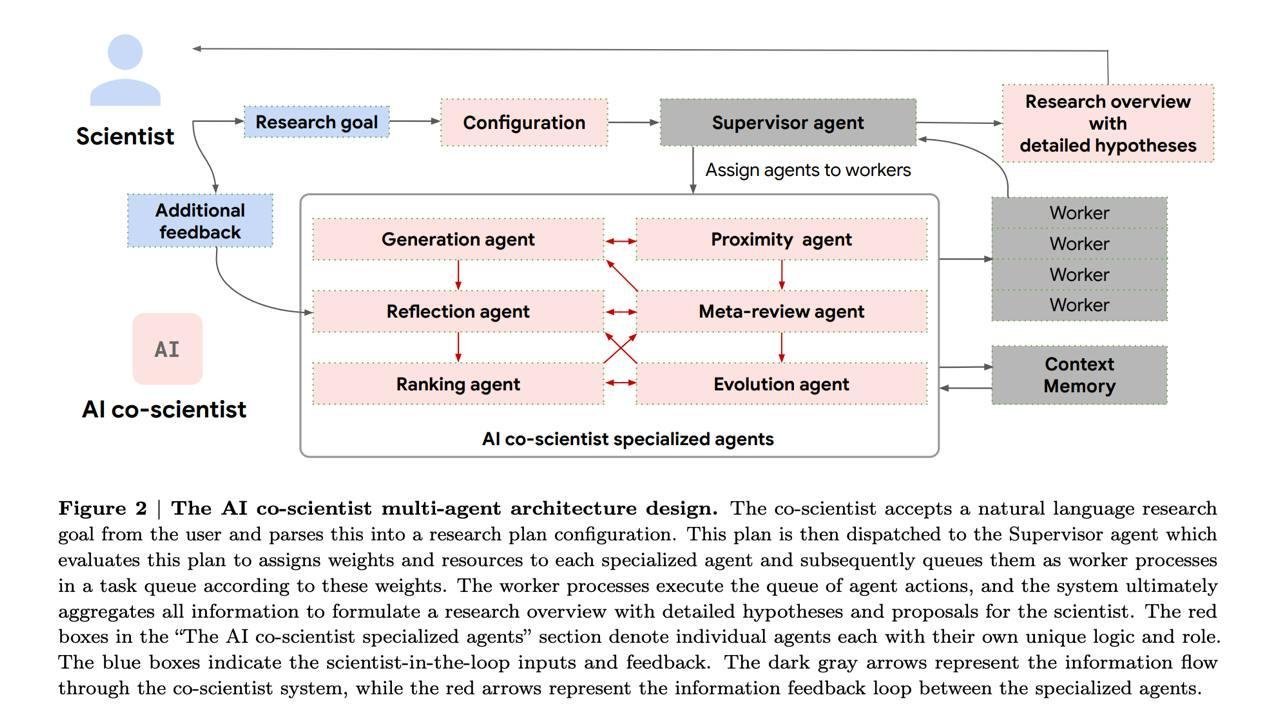
- устройство системы и описание того, как общаются агенты между собой
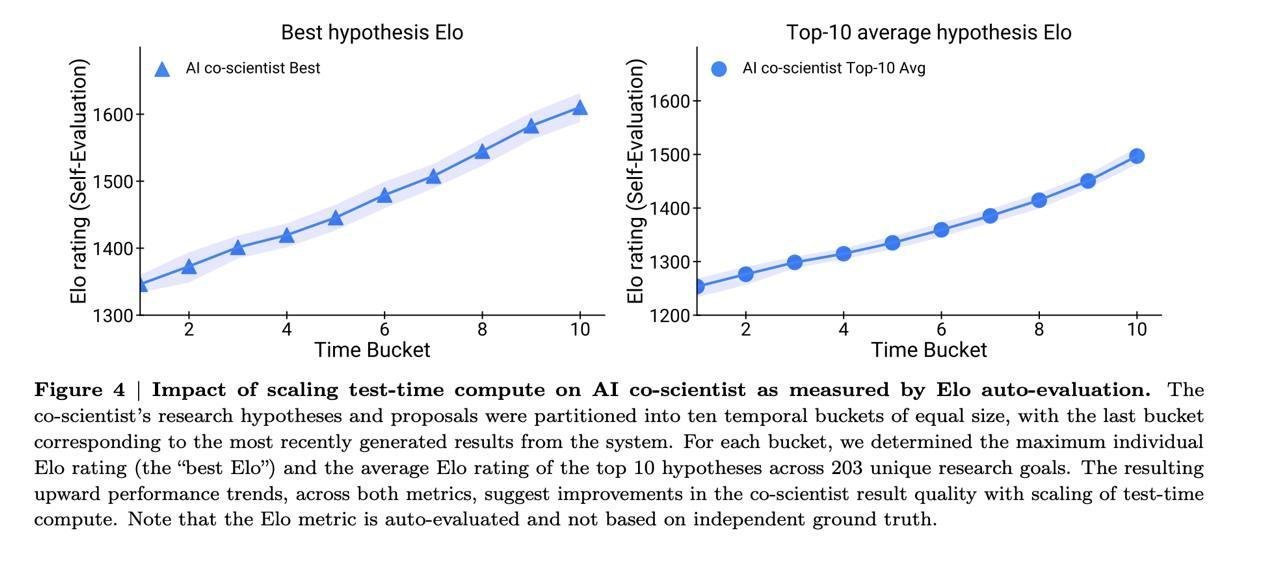
- Рост эло-рейтинга от количества времени работы системы (чем дольше работает, тем лучше получаются гипотезы). Плато пока не наблюдается, можно вкинуть в 10 раз больше ресурсов и посмотреть, что ко-саентист найдет. Так как рейтинг оценивается самой системой, то это не обязательно означает рост реального объективного качества гипотез, однако гугловцы сделали отдельный анализ корреляции качества ответов на GPQA (выбор ответов в сложных googl-proof вопросах) и Эло оценки решений ответов, и подтвердили, что она высокая.
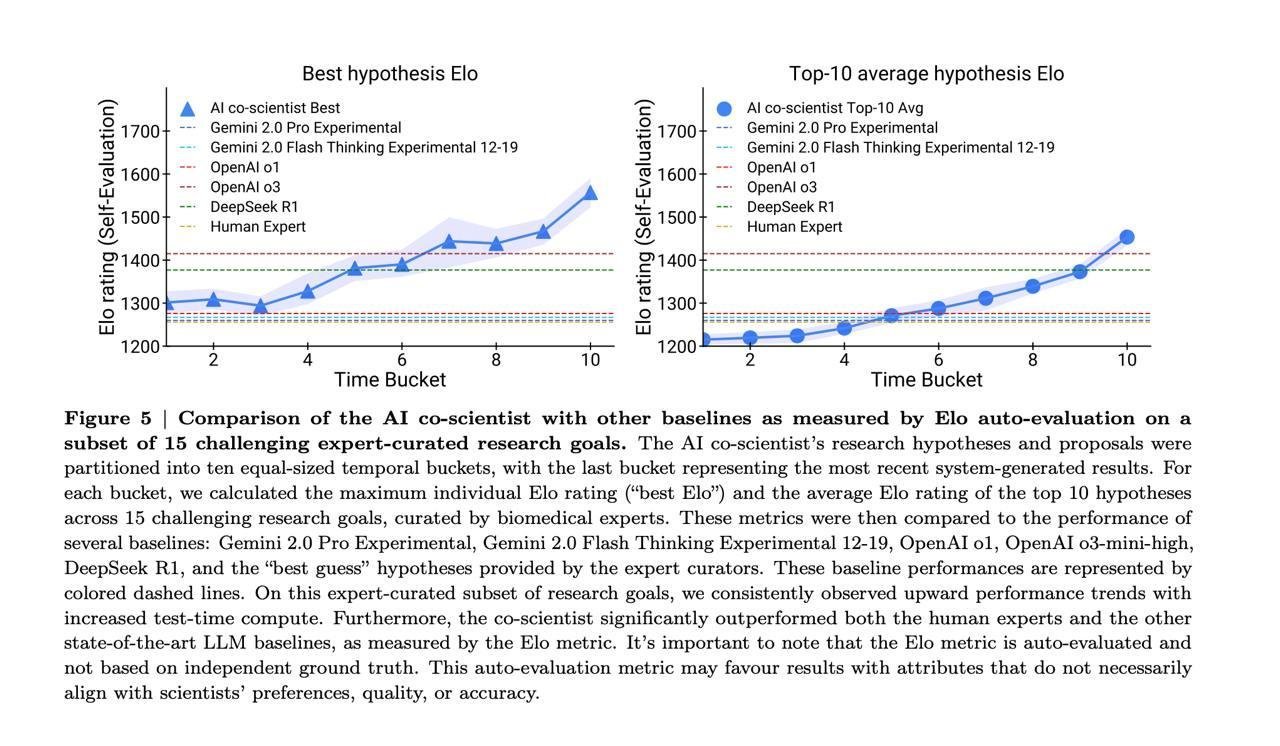
- Сравнение эло-рейтинга гипотез системы с генерациями обычных моделей (как я понял, просто один раз просят сгенерировать что-то по нужному формату; а затем Ранжировщик оценивает и сравнивает). Обратите внимание, что o3(-mini-high) и R1 как обособленные модели сами по себе выдают очень сильные гипотезы даже без всех этих агентских обвязок! А представьте как себя покажет GPT-5?
Ахахах а ещё посмотрите как низко люди на последней картинке...
Ограничения и ближайшее будущее
У этой работы есть ограничения, некоторые из которых плавно перетекают в намёки на то, что именно ждать от второй версии системы. Уверен, что Google по аналогии с AlphaFold будут толкать тему дальше, и возможно уже через год результат лучших гипотез будет неоспорим:
— используется только открытая литература, доступная без подписок. Наверное, логично скооперироваться с парой крупшейших издателей, заплатить десяток миллионов и почивать, пока TPU гудят
— из-за предыдущего пункта система скорее всего имеет ограниченный доступ к негативным экспериментальным результатам или записям об неудачных экспериментах. В науке в целом так вышло, что такие данные публикуются реже, чем положительные, и потому какие-то из гипотез, которые ко-саентист мог отсечь, всё ещё остаюстя
— система работает только с текстом, хотя Gemini 2.0 должна хорошо понимать картинки в статьях и отчётах об экспериментах
— так как это ранний прототип, то точно можно существенно прокачать проверку всех гипотез, включая улучшение литературных обзоров, добавление перекрестных проверок с внешними инструментами, улучшение проверки фактов и цитирований
— «Будущая работа будет сосредоточена на обработке более сложных экспериментальных проектов, таких как многошаговые эксперименты. Интеграция ко-саентиста с системами автоматизации лаборатории может потенциально создать замкнутый цикл для проверки и обоснованную основу для итеративного улучшения» (тут речь про то, что уже существуют программируемые лаборатории, которые могут проводить эксперименты, описанные кодом. Модель выдаёт код на питоне, он исполняется, реактивы смешиваются, туда сюда, центрифуга, и готово).
— Авторы уже попробовали подключить AlphaFold 3 в качестве инструмента, говорят, заработало, но никакими деталями не делятся. Такие модели смогут усилять систему за счёт возможности проверки некоторых гипотез и предположений на лету, без реальных экспериментов.
===
«Эти достижения имеют значительные последствия для различных биомедицинских и научных областей. Например, интеграция ко-саентиста в процесс выбора кандидатов на лекарства представляет собой значительный прогресс в поиске повторного использования лекарств. Помимо простого поиска литературы, соученый может быть способен синтезировать новые идеи, соединяя молекулярные пути, существующие доклинические данные и потенциальные терапевтические приложения в структурированные, проверяемые конкретные цели»
===
3 теста это здорово, но мало, очень хотелось бы увидеть через полгода-год масштабирование на десятки-сотни и коллаборации с ведущими экспертами в разных областях. Такое, к сожалению, пока ограничено нашей естественной скоростью проведения тестов и бюрократии 🥺
О и да, инструмент пока в закрытом доступе, Google ищет партнёров-учёных 👍
Послесловие
Короткий разбор = 2000 слов 😀😀
Я не так часто переношу свой контент из тг-канала в Клуб, но не мог пройти мимо этой статьи, так как тема ОХРЕНЕТЬ какая важная. Кто-то всё ещё тыкает пальцем в примеры, когда LLM неправильно считают буквы в словах. Ну, другие шевелят угли членом и продолжают толкать науку.
Если вдруг вы ещё не подписаны (это как вообще?), но не хотите пропускать подробные разборы чё почем в AI — Сиолошная или Хабр.
Напомню, что
Очень хорошим фоллоу-апом этого поста будет мой лонг про FunSearch, который работает немного схоже, но в разрезе программирования, а не биологии.
Увидимся на релизе GPT-4.5 через недельку-две 0/
Спасибо за канал - один из любимейших каналов про AI
Рад видеть твой контент в клубе, отличный лонгрид!
Спасибо за канал, читаю почти каждый день. Лонгридов и подкастов, Youtube выпусков бы ещё.. 🙄
Отлично, гугл теперь и фарма. Киберпанк всё ближе
Спасибо за лонгрид, Игорь!
Тема огонь, the future is now.
Как будто для клуба статью стоило облегчить
На статью наткнулся абсолютно магическим образом. Вообще сначала не понял зачем я сюда зашел, такие темы меня сейчас пугают.
Дело в том, что у меня самого ОМЛ. Сейчас каким-то чудом я в ремиссии, но она с этим диагнозом очень хрупкая.
Если бы вы могли постараться подробнее расписать результаты статьи про ОМЛ, я был бы сказочно рад.
UPD. Только-только написал, пришел врач и сказал, что ремиссия все.
Ждём open-source alternative!