

Как я отказался от оверинжиниринга и переместился с 30 места на 7 в Enterprise RAG Challenge. И чего не хватило до 1 места.
Это челлендж, организованный llm_under_hood (одно из главных сообществ в РФ инфопространстве по построению LLM-систем) и TimeToAct Austria.
Там были какие-то призы, но думаю, все участвовали чтобы протестить свои подходы на индустриальном датасете. Ну и конечно, чтобы потом выпендриваться местами в лидерборде – сейчас в AI не так много способов отстроиться от инфоцыган, которые прошли недельные курсы по промтингу.
Задача была сложная:
- Есть 100 корпоративных отчетов, в каждом 100-1000 страниц душного корпоративного текста.
- Есть 100 вопросов по этим отчетам ("сколько отелей у компании Х?", "Были ли изменения в дивидендах компании Y?", "На каких позициях в топ-менеджменте были изменения?", "у какой из компаний X, Y, Z самая высокая выручка?")
- Нужно дать ответы на эти вопросы + ссылки на страницы в отчетах, которые это подтверждают (жестокая жизнь, где бизнесу нужны пруфы)
Все бы ничего, но предполагалось, что это будет сделано за несколько часов. Сначала выдаются отчеты, есть пару часов на их предобработку/индексацию, потом выдаются вопросы и несколько часов, чтобы прогнать их через систему.
Как все успеть? Попробовать подготовить систему заранее. Где-то за неделю Ринат нагенерил 40 тестовых pdf и 30 вопросов. Получается, было время протестить на них всю систему, а когда придут новые данные, просто запустить ее на них.
Хаха, кто же знал, что все не так просто.
Вот что я делаю:
Анализирую победившее решение предыдущего челленджа
- Daniel делает извлечение метрик из отчетов на основе structured output
- Все извлеченные данные сохраняет в одну базу знаний, которая просто передается в промпт вместе с каждым вопросом
- Нам это не подходит, потому что у нас
- больше разных типов вопросов (не только про метрики)
- больше документов
- сами документы больше
Думаю, как поменять решение. Понятно, что нужно извлекать данные из отчетов на основе structured output, но какие данные? Смотрю на код генерации вопросов и понимаю, что там 9 типов вопросов.
Делаю похожую систему похожую на то, что у Daniel, только теперь "типов" данных стало больше – целых 9 вместо 1. Соответственно в классе Report делаю 9 списков, а не 1:
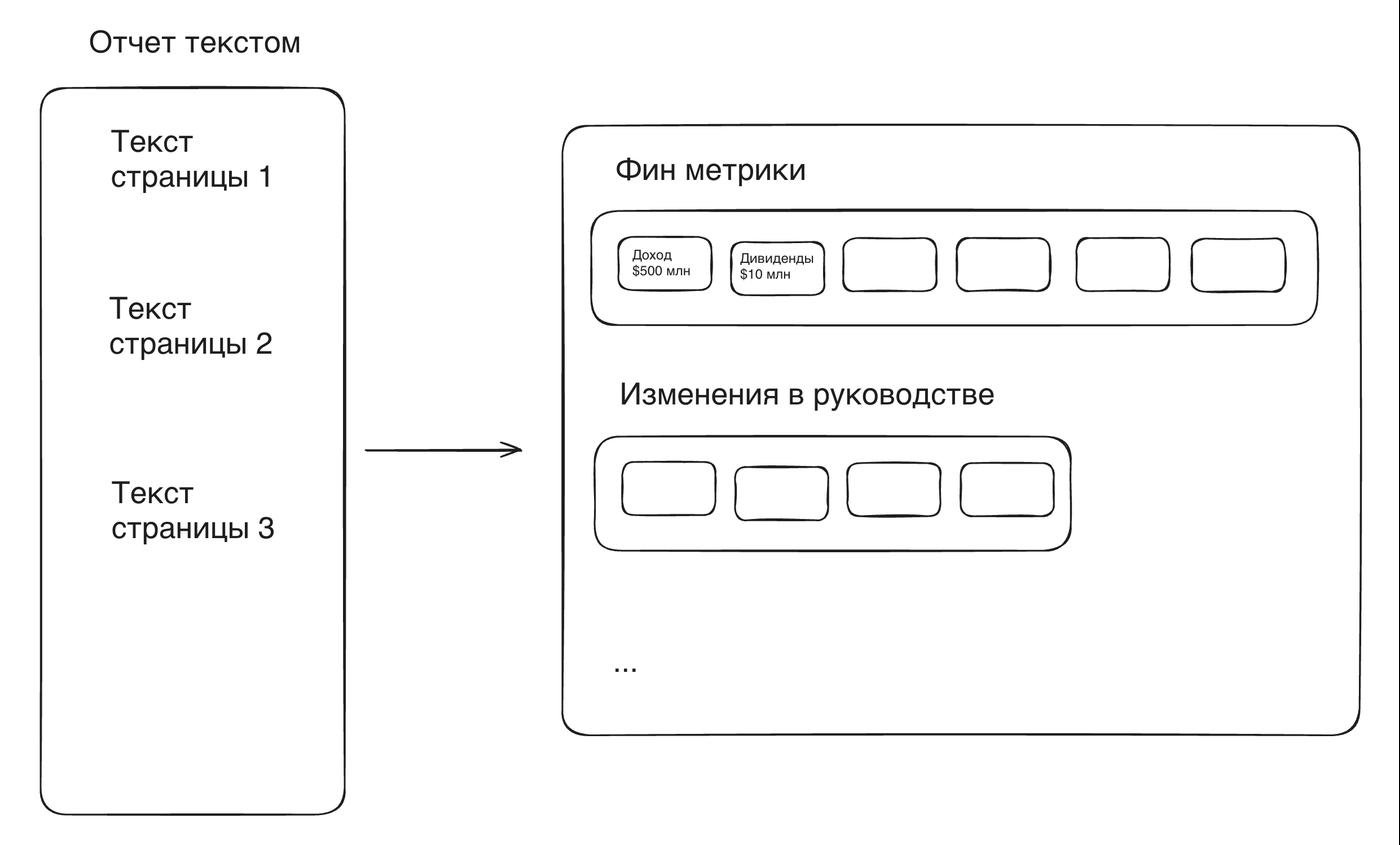
class AnnualReport(BaseModel):
financial_metrics: list[FinancialMetric]
leadership_changes: list[LeadershipChange]
# Еще 7 списков
class FinancialMetric(BaseModel):
metric_name: Literal["Total revenue", "Operating income", "Net income", ...]
value: float
currency: str
period: str
details: str
class LeadershipChange(BaseModel):
position: str
old_holder: str
new_holder: str
effective_date: str
details: str
# Еще 7 разных типов информации
Я специально удалил из кода Field(description=...), чтобы не перегружать пост. Но вообще description важен, потому что уточняет важные детали извлечения для LLM.
Все полученные данные не влезут во входной контекст для ответа на вопрос. А даже если бы и влезли, то нерелевантная инфа настолько бы захламляла контекст, что качество было бы ужасным. Понятно, что нужно как-то определить, данные какого отчета нужны для ответа на вопрос. По сути, нужно вычленить название компании из вопроса. Как? Опять structured output и Literal 🤷♂️
class Response(BaseModel):
company_name_from_question: Literal[tuple(name_to_id.keys())]
...
company_id = name_to_id[parsed_response.company_name_from_question]
Ок, нашел отчет. Но у меня по нему 9 огромных списков с данными. Передавать в промпт все 9 списков?
Нет, лучше определю, какие именно данные нам нужны для ответа на вопрос и буду использовать только эти данные, чтобы еще меньше захламлять промпт.
data_point_types = [
"financial_metrics",
"leadership_changes",
# ...
]
class Response(BaseModel):
company_name_from_question: Literal[tuple(name_to_id.keys())]
data_type_question_asks_about: Literal[tuple(data_point_types)]
и передаю это в промпт к o3-mini.
company_id = name_to_id[parsed_response.company_name_from_question]
report = extracted_reports[company_id]
data_type = parsed_response.data_type_question_asks_about
only_relevant_data = report.model_dump(include={data_type})
prompt = f"""
<knowledge_base>
{only_relevant_data}
</knowledge_base>
<goal>Answer the question based on the found knowledges</goal>
<question>
{question}
</question>
""".strip()
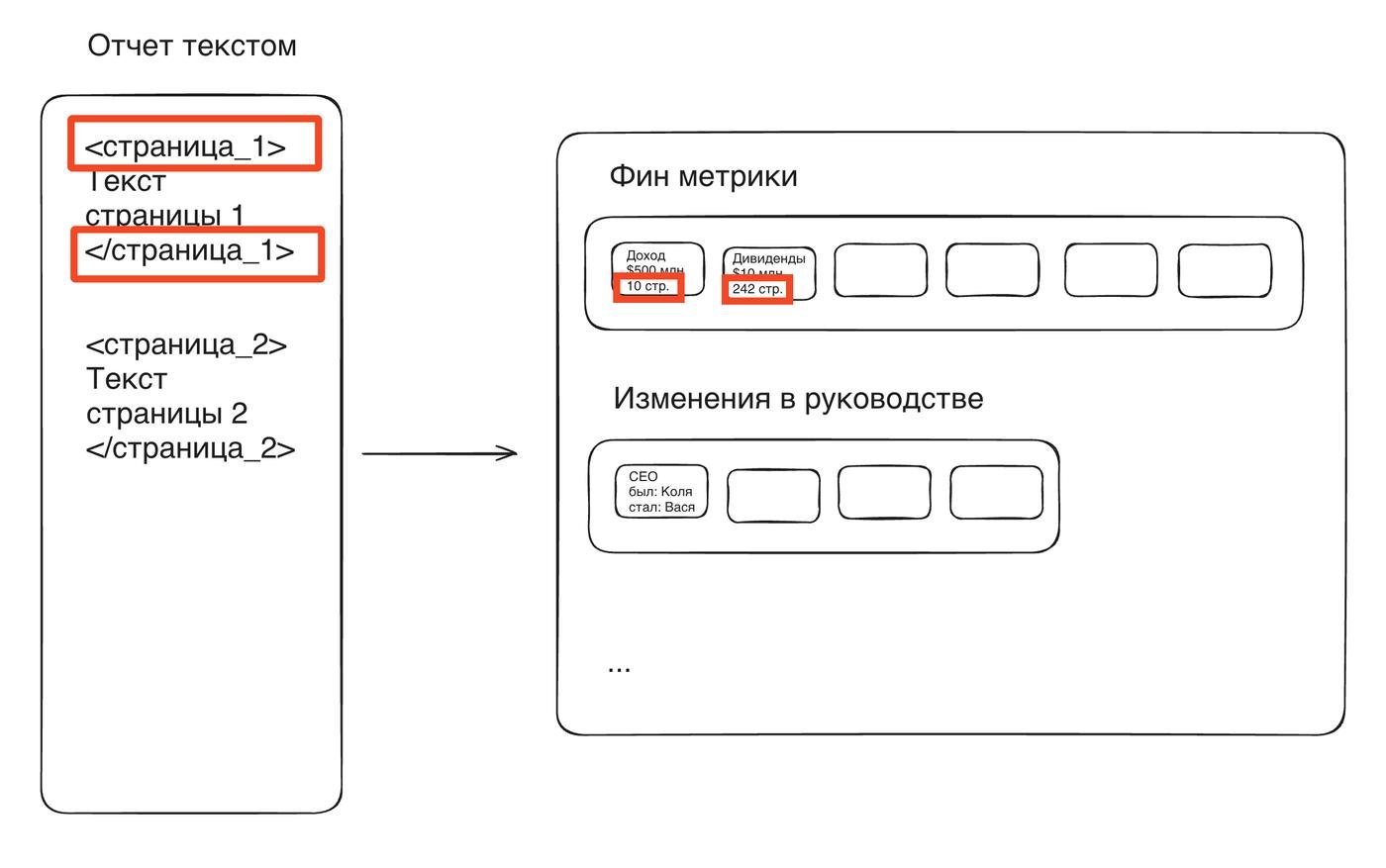
Ну все, радуюсь. Прогоняю на тестовых данных, отправляю сабмишшн на тестовое API. Ошибка. Ответ не совпадает со схемой. Нет референсов. Черт! Я забыл, что нужны еще и номера страниц с пруфами.
Добавляю в первый шаг с извлечением инфы номера страниц на вход (в виде xml тегов <page_number_{i}>{page_content_i}</page_number_{i}>). И на выход для каждого data_point прошу указать откуда он. Аналогично делаю и на последнем этапе с ответом на вопрос.
Все работает. У меня еще пара часов до начала соревнования. Я уже переборщил с кофе, так что иду потренить в зал, чтобы немного переключиться.
Вообще-то, одна из самых сложных частей челленджа – доставать текст без потерь из pdf (особенно таблицы). Кто-то использовал кастомный OCR, кто-то использовал Vision модели (я чекнул, показалось дорого). Я сначала вообще использовал базовый PyPDF2, потом прогнал все через marker-pdf, он рисует красивые md таблички, правда на одну пдф могло по пол часа уходить, так что экспериментировал я с PyPDF2, а потом постепенно подсасывал те отчеты, которые выдавал Маркер. Кстати, вот уже обработанные отчеты
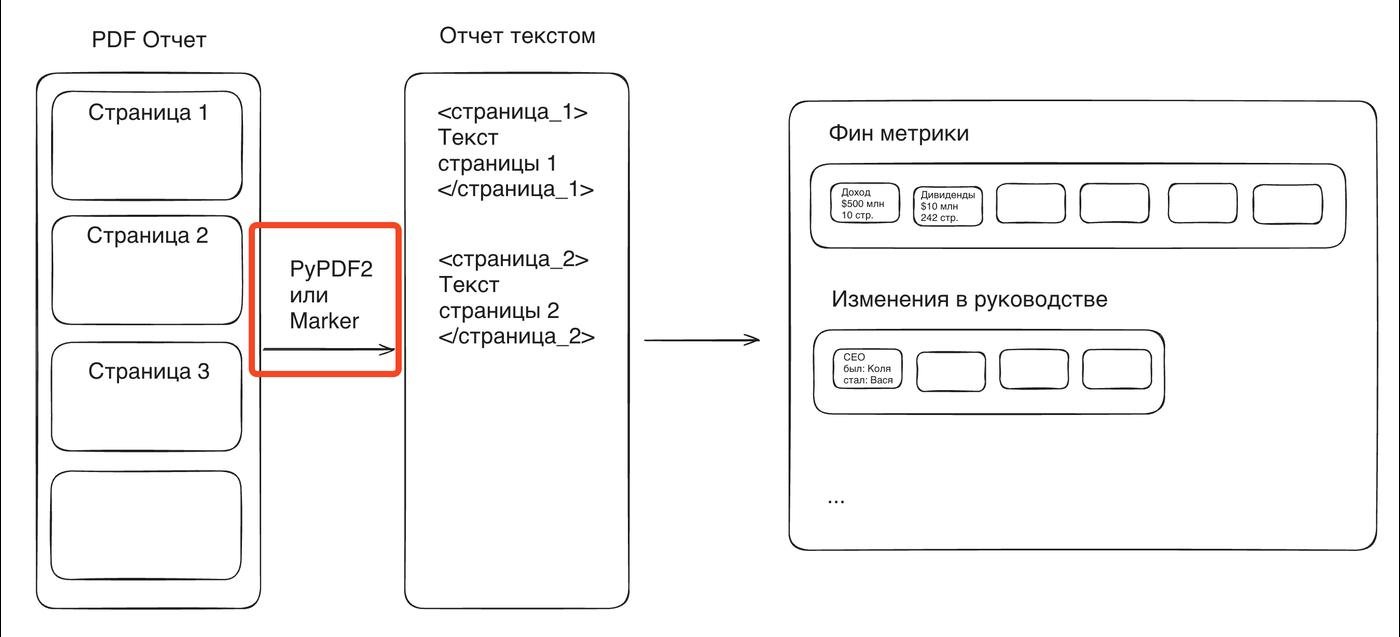
Сравнение:
Оригинал
Marker-pdf

PyPDF2

Вообще-то, и с pypdf работает неплохо – это на наш человеческий взгляд разница колоссальная, а для LLM что такой разделитель, что другой, разница не такая большая. Но сложные таблицы он шакалит.
Финишная кривая.
Появляются финальные отчеты. Прогоняю их через свой пайплайн и занимаюсь микроитерациями – смотрю вручную, какие знания пропускает и пытаюсь поправить, калибруя промпты и число страниц, которые подаю за раз.
Вот так выглядит финальная система:
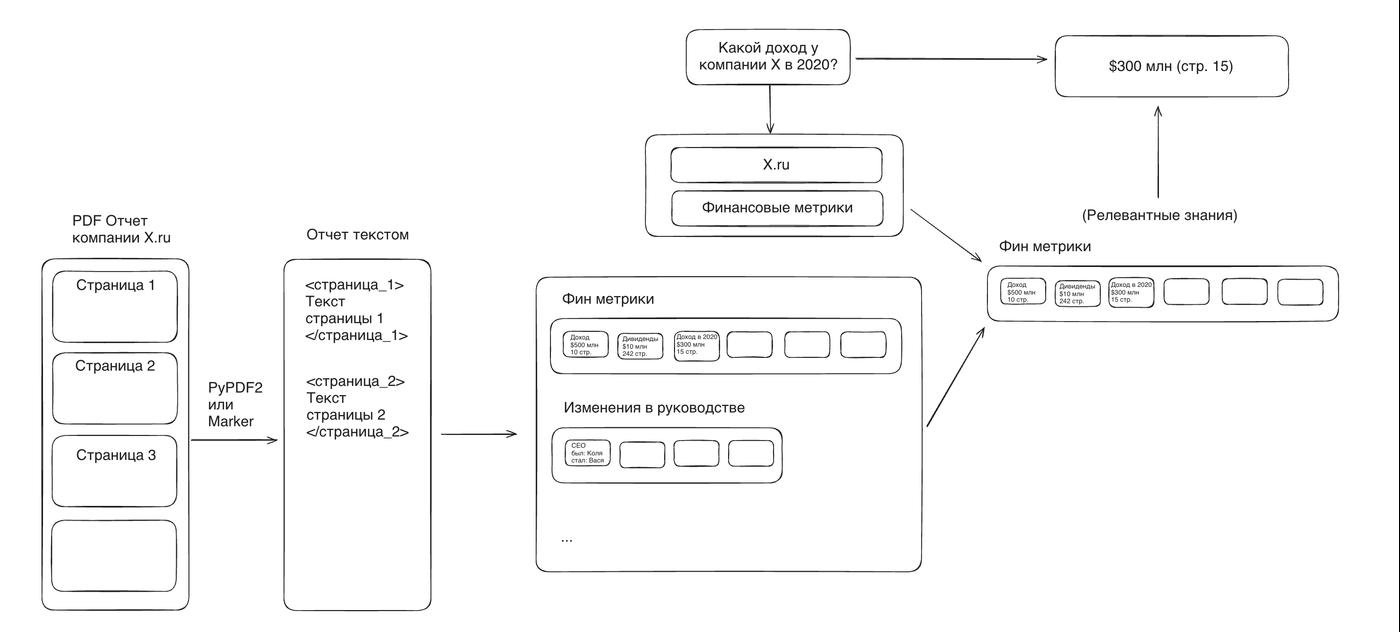
Через несколько часов появляются и вопросы. Уже через пару минут я отправляю первый сабмишшн. Весь вечер провожу в минорных изменениях. Где-то на 5 сабмишшене до меня доходит, что вопросов столько же сколько отчетов, они генерировались рандомно, а значит, не все отчеты вообще нужны. Выбрасываю лишние из пайплайна и из очереди в маркер.
На следующее утро до меня доходит еще одна вещь. Раз вопросов примерно столько же сколько отчетов, значит, по одному отчету не бывает много вопросов. Значит извлеченные знания почти не переиспользуются. Тогда зачем они?
И вместо того, чтобы пытаться заранее предугадать, какие данные могут понадобиться из отчета и доставать их все, я могу тупо доставать данные сразу под конкретный вопрос.
Система упрощается на порядок.
- Асинхронно делаю запрос к gpt-4o-mini под каждую страницу отчета "есть тут ответ на вопрос или нет"?
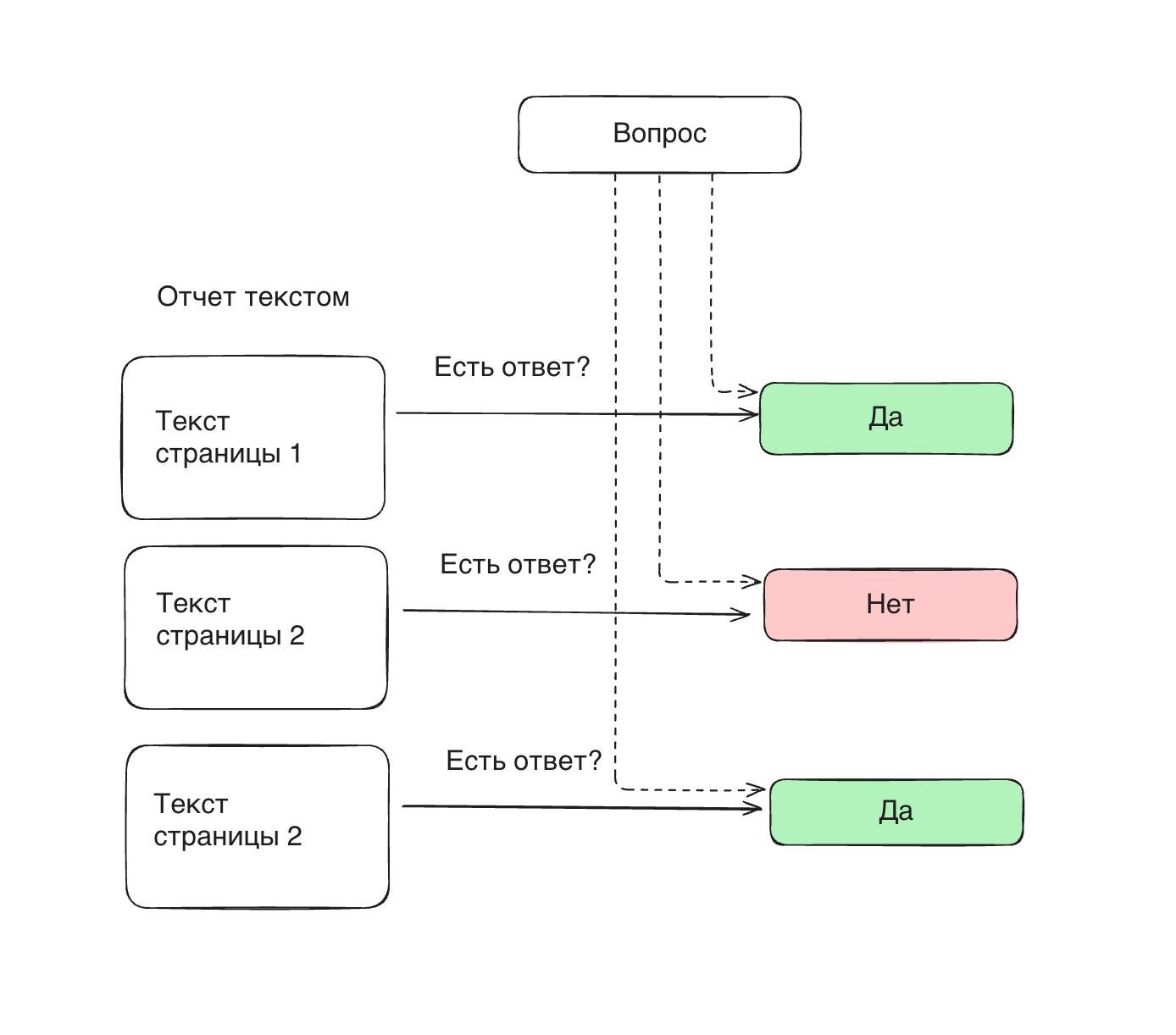
- Дамплю все страницы с положительным ответом в промпт и прошу o3-mini ответить на вопрос.
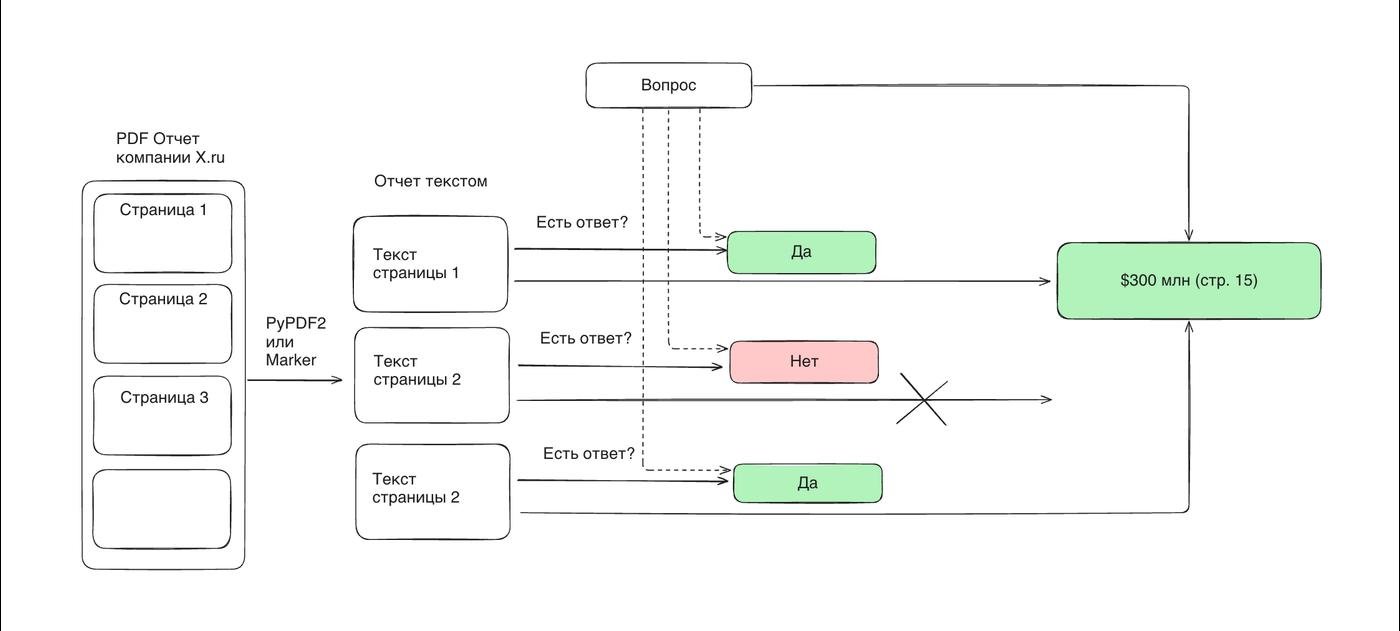
Первое решение получило 89 баллов из 133. Последнее 110. А самое главное, что аналогичное решение поделило 1-е место получив 121.6 баллами.
Чем оно отличалось? Я слишком поздно увидел 8 вопросов, которые требуют данных сразу из нескольких отчетов (в тестовых данных такого не было). К дедлайну на призовые места я успел сделать только нерабочий костыль.
А победитель поступил очень просто – распилил такие вопросы на несколько, каждый из которых требует данных из одного отчета, а это мы умеем. А потом просто одним доп.запросом собрал ответ из всех ответов на эти вопросы.
template = r"Which of the companies had the lowest (?P<metric>.*?) in EUR at the end of the period listed in annual report: (?P<companies>.*?) If data for the company is not available, exclude it from the comparison. If only one company is left, return this company"
...
subquestions = [{
"text": f"For {company}, what was the value of {metric} at the end of the period listed in annual report? If data is not available, return 'N/A'.",
"kind": "number"
} for company in companies]
⬆️ Это чисто моя спекуляция о том, как оно примерно выглядело.
Главный вывод
- Всякие хитрые архитектуры поиска, ембеддинги и прочее – просто способ снизить стоимость запросов к LLM, заранее отбросив побольше лишней информации.
- Запросы становятся все дешевле, и уже сейчас можно использовать gpt-4o-mini как search engine. А учитывая асинхронность, это еще и быстро – пройтись по всем страницам отчета можно за 10-20 секунд. Стоимость ответа на один вопрос - 10 центов. Вручную его искать можно несколько часов. Выгода для бизнеса очевидна.
- Уверен, в будущем таких "тупых" архитектур будет все больше. Уже сейчас они делят 1 место со сложными комбайнами (где парень даже переписал часть либы под себя 🫨).
А еще, я пишу про такие штуки в AI и грабли. Например, у меня есть серия о structured_output, который постоянно встречается в посте
А потом прилетает тот самый пдф на 1000 страниц и доки с поломанными шрифтами. XD
Не знал, что ты есть и в Вастрике.) Поздравляю с крутым результатом.)
Вах, какая красивая табличка у Marker получилась!
Классно написал, спасибо!
Я тоже участвовал в том же челлендже, занял пятое место. Ринат и его канал, и особенно чатик - какой-то луч в темном царстве поверхностных AI каналов в телеграме.
В своем подходе я использовал Gemini Flash 2.0 для OCR, тупо сконвертировал все пдфки в PNG и каждую скармливал по отдельности в Gemini, и просил вернуть маркдаун. Потом это все засунул в Postgres (pgvector), конвертировал в эмбеддинги (google) и скармливал мало-мальски релевантные куски в Flash 2.0 Thinking (с температурой 0) для финальных ответов.
На распознавание тысяч страниц я потратил в районе 6 долларов.
Подробности описал тут:
https://t.me/saas_founders/87
@nikolay_sheyko
у меня вопрос одновременно по теме и не по теме :)
Есть у нас инициативная группа, которая только начинает прокачиваться именно вот в этой теме, условно говоря "Как проектировать, тестировать и строить архитектуру приложений вокруг этих ваших нейронок". То есть, это не тренинг моделек, не тюнинг, а именно построение своего комплекса приложений, которые бы решали сугубо наши, внутренние, специфичные для нас задачи.
Собственно, вопрос в том, где и как искать обучающие материлы по этой теме, как прокачиваться именно в этом направлении?
Классная статья и хороший результат. Применяем очень похожий подход для решения задач патентного анализа, где приходится анализировать сотни (а иногда и тысячи PDF), так же этот метод отлично работает для создания отчетов типа Deep Research по локальной базе документов.
Лично для меня до сих пор остается загадкой почему в open source до сих пор нет (или я просто не могу найти?) инструментов для обработки больших массивов данных подобным образом. Вместо этого все помешаны на RAG, который просто архитектурно не способен решать такие задачи.
Поздравляю ) подписался почитать