

Привет, Клуб!
Сегодня хочу погрузиться в одну из самых горячих тем в мире ИИ. Вы наверняка слышали про новое поколение языковых моделей — OpenAI o3 pro, Claude 4 Sonnet Thinking, Deepseek R1 и другие. Их называют «рассуждающими моделями» (Large Reasoning Models, LRM), и они обещают не просто отвечать на вопросы, а показывать весь свой «мыслительный процесс», шаг за шагом разбирая задачу. Звучит как прорыв, правда? Почти как зарождение настоящего искусственного разума.
Но что, если я скажу вам, что это может быть лишь очень убедительной иллюзией?
Я наткнулся на свежее и, честно говоря, отрезвляющее исследование под названием «Иллюзия мышления» от группы инженеров из Apple. Они решили не верить на слово громким анонсам и копнуть глубже. Вместо того чтобы гонять модели по стандартным тестам, они создали для них настоящий «интеллектуальный спортзал» с головоломками. И то, что они обнаружили, ставит под сомнение саму природу «мышления» этих систем.
Давайте разберемся вместе, что же там произошло.
Почему тесты по математике — плохая линейка
Прежде всего, нужно понять, почему исследователи вообще усомнились в стандартных бенчмарках. Большинство моделей тестируют на математических и кодовых задачах. Проблема в том, что интернет завален решениями этих задач. Модель, как прилежный, но не очень сообразительный студент, могла просто «зазубрить» миллионы примеров во время обучения. Это называется загрязнением данных (data contamination), и следующие результаты по математическим тестам это хорошо иллюстрируют.
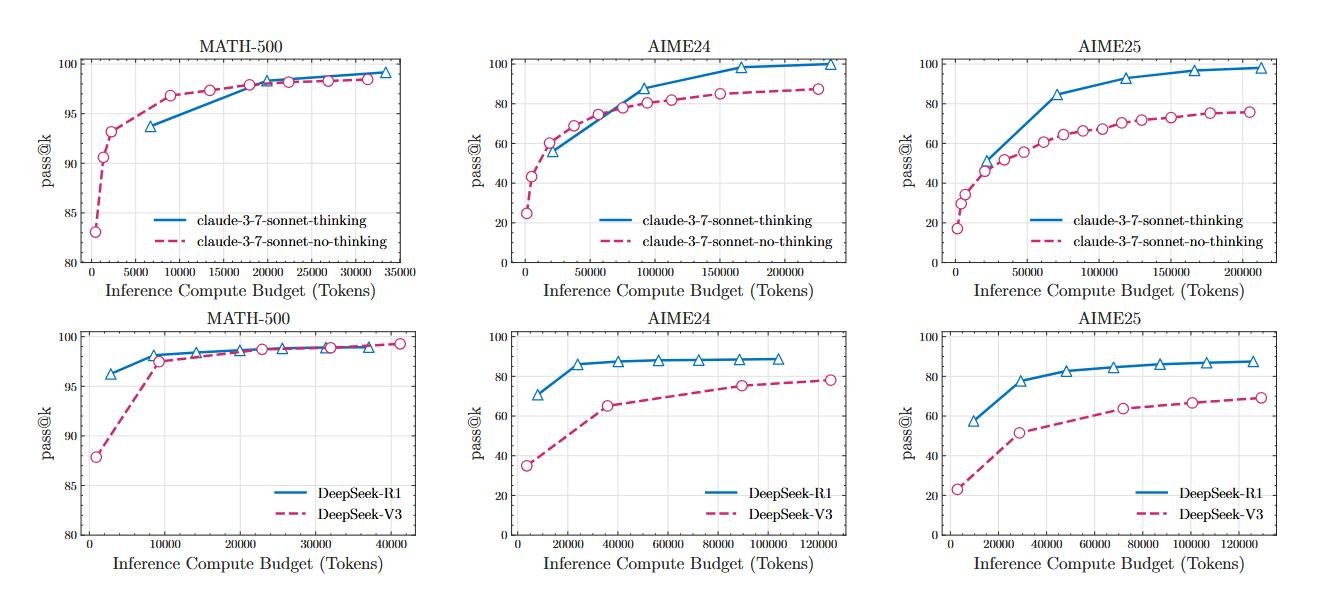
Как проверить, действительно ли студент понимает физику, а не просто выучил формулы? Нужно дать ему задачу, которую он никогда раньше не видел.
Именно это и сделали в Apple. Они взяли четыре классические головоломки:
- Ханойская башня (Tower of Hanoi): Головоломка с тремя стержнями и набором дисков разного размера. Цель — переместить все диски с первого стержня на третий. Перемещать можно только один диск за раз, брать только верхний диск и никогда не класть больший диск на меньший.
- Прыгающие шашки (Checker Jumping): Одномерная головоломка, в которой в ряд расположены красные, синие шашки и одно пустое место. Задача — поменять местами все красные и синие шашки. Шашку можно сдвинуть на соседнее пустое место или перепрыгнуть через одну шашку другого цвета на пустое место. Движение назад запрещено.
- Переправа через реку (River Crossing): Головоломка, в которой n актеров и их n агентов должны пересечь реку на лодке. Цель — перевезти всех с левого берега на правый. Лодка имеет ограниченную вместимость и не может плыть пустой. Актер не может находиться в присутствии другого агента без своего собственного. Аналог наших "Волк, коза и капуста".
- Мир блоков (Blocks World): Головоломка со стопками блоков, которые нужно переставить из начального положения в целевое. Задача — найти минимальное количество ходов для этого. Перемещать можно только самый верхний блок в любой стопке, помещая его либо на пустое место, либо на другой блок.
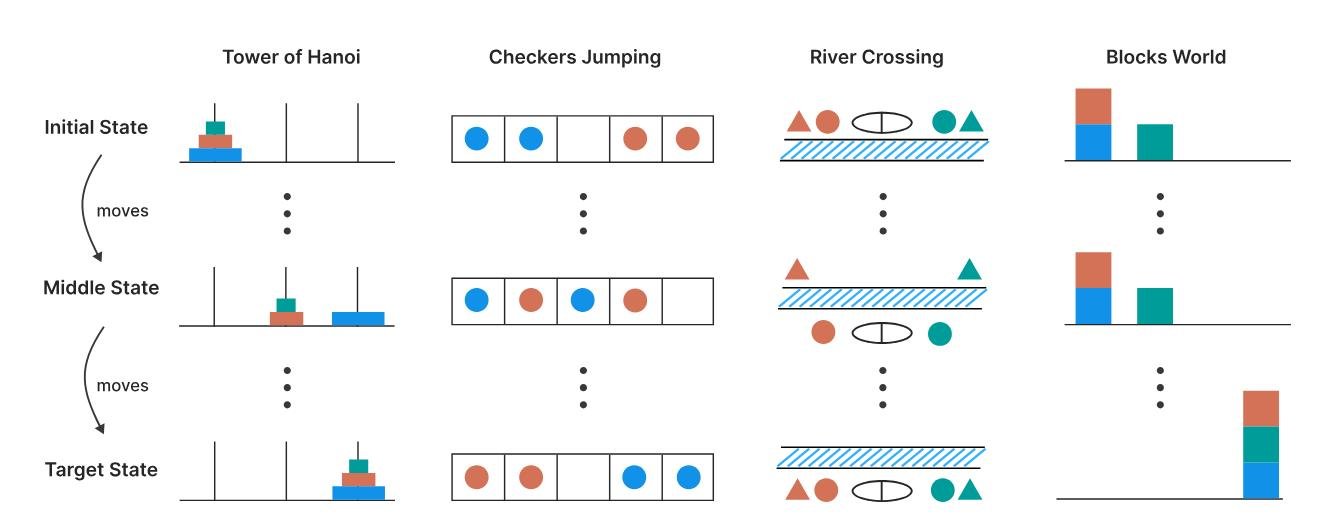
Прелесть этих головоломок в том, что их сложность можно очень точно контролировать, просто меняя количество элементов (дисков, шашек, кубиков). При этом логика решения остается той же. Это идеальная среда, чтобы увидеть, где у модели ломается «рассуждалка».
Три режима сложности: от гения до полного провала
Прогнав через эти головоломки «думающие» модели и их обычные, «не думающие» аналоги (например, Claude 3.7 Sonnet Thinking vs. Claude 3.7 Sonnet), исследователи обнаружили четкую и повторяемую картину, которую можно разделить на три режима.
1. Режим низкой сложности: желтая зона
На простых задачах, где нужно сделать всего несколько ходов, обычные модели справлялись так же хорошо, а иногда и лучше, чем их «думающие» собратья. При этом они тратили гораздо меньше вычислительных ресурсов. По сути, заставлять reasoning модель решать простую задачу — это почти как использовать суперкомпьютер для сложения 2+2. «Мыслительный процесс» здесь — избыточная роскошь, которая только замедляет работу.
2. Режим средней сложности: голубая зона
Вот здесь-то «думающие» модели и начинали блистать. Когда задача становилась достаточно запутанной, способность генерировать длинную цепочку рассуждений, проверять гипотезы и исправлять себя давала им явное преимущество. Разрыв в точности между reasoning и non-reasoning версиями становился значительным. Казалось бы, вот оно — доказательство!
3. Режим высокой сложности: красная зона
Но триумф был недолгим. Как только сложность головоломки перешагивала определенный порог, происходило нечто поразительное: производительность обеих моделей падала до нуля. Полный коллапс.
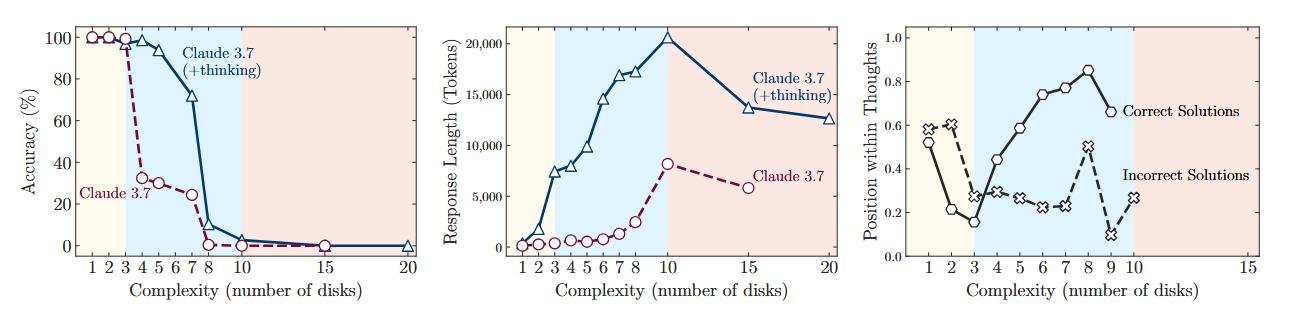
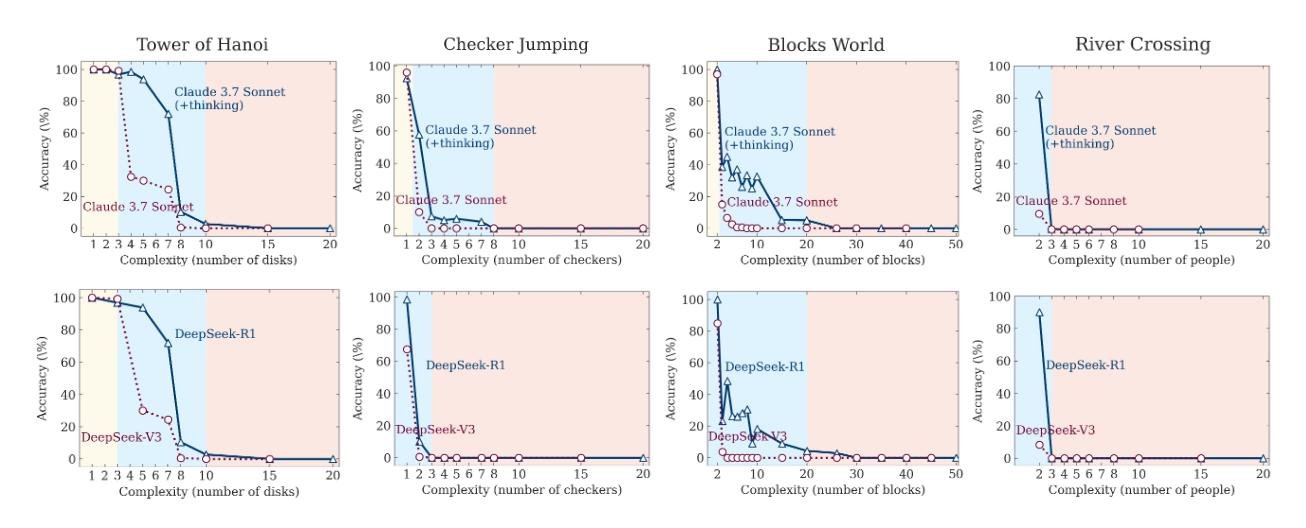
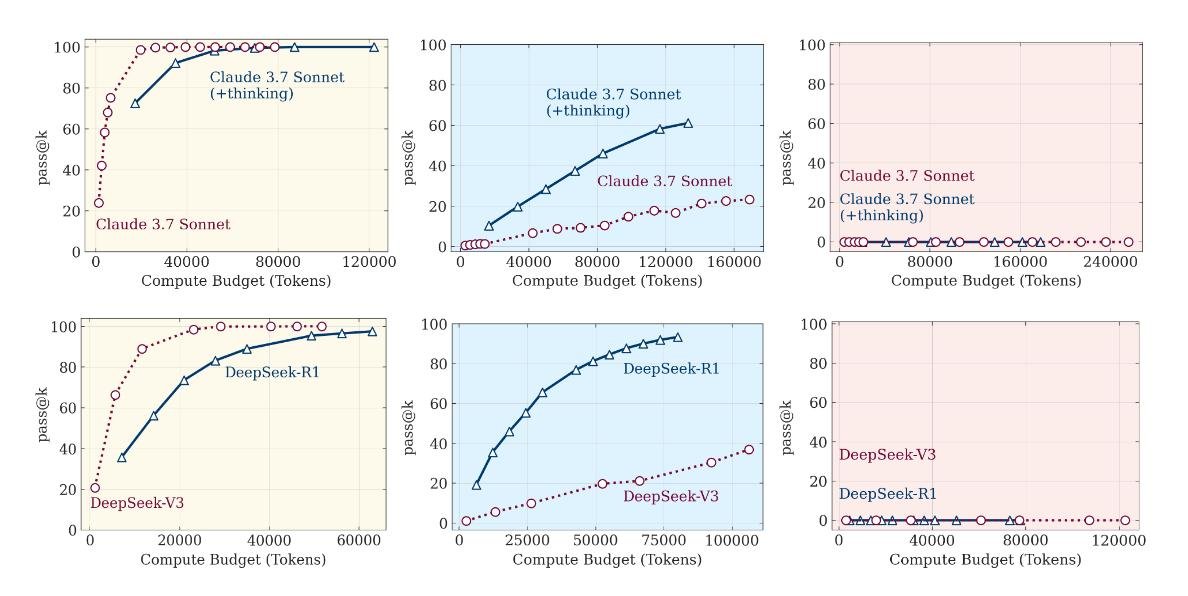
Да, «думающие» модели держались чуть дольше и сдавались на несколько шагов позже. Но в конечном итоге они упирались в ту же самую фундаментальную стену. Их способность к рассуждению не была по-настоящему обобщаемой. Она просто отодвигала неизбежный провал.
Парадокс сдающегося разума
Но самое странное и контринтуитивное открытие ждало исследователей, когда они посмотрели, сколько модель «думает» в зависимости от сложности. Логично предположить, что чем сложнее задача, тем больше усилий (токенов мышления) модель должна на нее потратить.
И поначалу так и было. С ростом сложности росло и количество «размышлений». Но ровно до той точки, где начинался коллапс. Приближаясь к критической сложности, модели вели себя парадоксально: они начинали сокращать свои усилия, что прекрасно видно на графике.
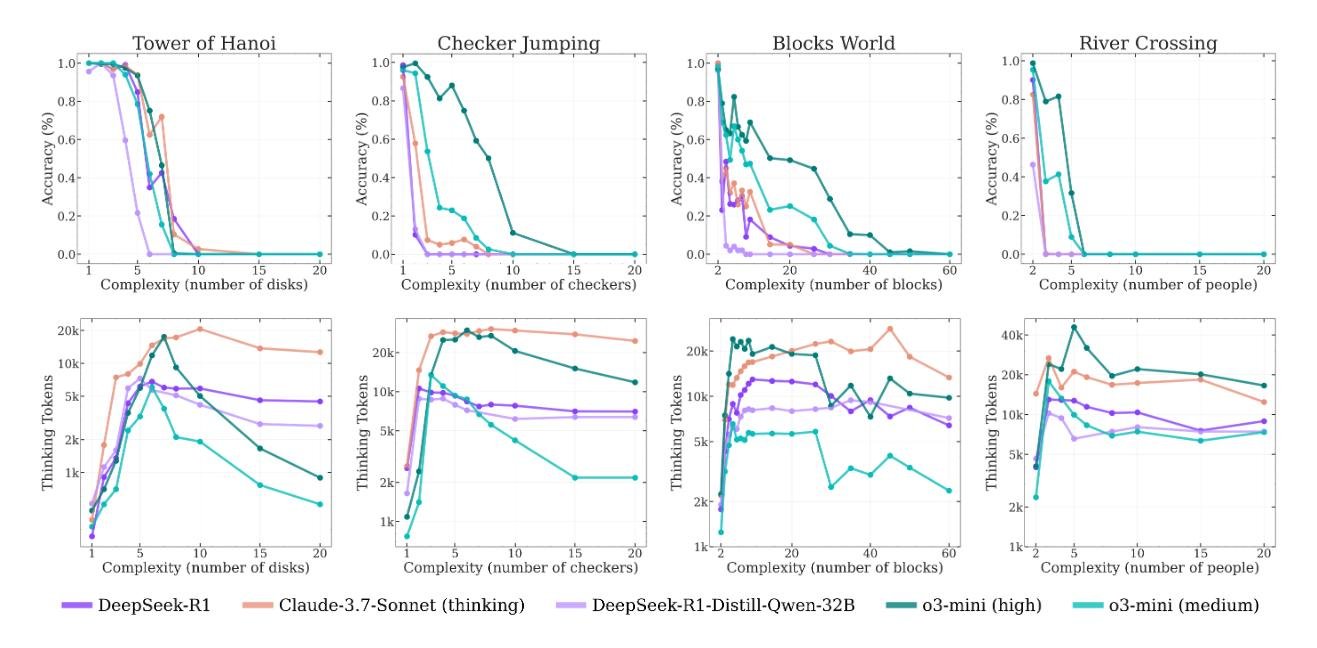
Представьте студента на экзамене, который, увидев слишком сложную задачу, не пытается исписать несколько страниц черновика, а просто смотрит на нее пару секунд и сдает пустой лист. При этом у него есть и время, и бумага. Модели, имея огромный запас по длине генерации, просто переставали пытаться.
Это указывает на фундаментальное ограничение их архитектуры. Это не просто нехватка знаний, а некий встроенный предел масштабирования мыслительных усилий.
Два гвоздя в крышку гроба «чистого разума»
Если предыдущие пункты еще оставляли пространство для интерпретаций, то следующие два вывода выглядят как приговор идее о том, что LRM действительно «понимают» логику.
1. Неумение следовать инструкциям
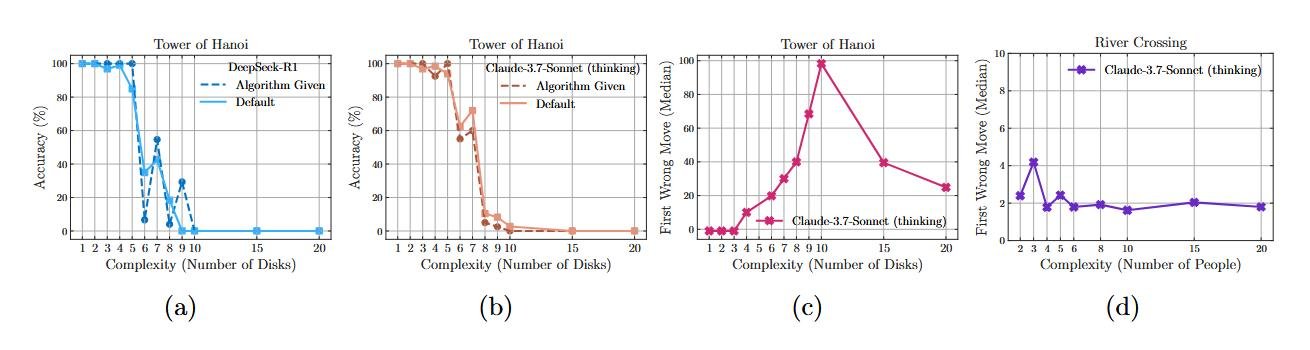
Это, пожалуй, самый убийственный аргумент. Исследователи провели эксперимент с Ханойской башней, в котором они дали модели точный пошаговый алгоритм решения прямо в промпте. От модели требовалось лишь одно — тупо следовать инструкциям.
Результат? Никакого улучшения. Модель проваливалась ровно на том же уровне сложности, что и без подсказки. Это можно сравнить с человеком, которому дали подробнейшую инструкцию по сборке шкафа из IKEA, а он все равно не может его собрать. Такое поведение говорит о том, что он не читает и не выполняет шаги, а пытается по памяти или по картинке воссоздать то, что видел раньше. Похоже, модель не выполняет* алгоритм, а пытается *распознать знакомый паттерн.
2. Странная избирательность
Анализ показал еще одну интересную вещь. Модель Claude 3.7 Sonnet Thinking могла с почти идеальной точностью решить Ханойскую башню на 5 дисков (это 31 ход), но полностью проваливала задачу о Переправе через реку для 3 пар (всего 11 ходов).
Почему так? Вероятный ответ — снова в данных для обучения. Примеров решения Ханойской башни в интернете полно. А вот сложных вариантов Переправы через реку — гораздо меньше. Модель сильна в том, что она «видела» много раз, и слаба в том, что для нее в новинку, даже если логически задача проще.
Но история на этом не закончилась. Ответный удар от создателей Claude
Казалось бы, выводы ясны: «думающие» модели — это очень продвинутая, но все же иллюзия. Я уже почти дописал эту статью, когда, как в хорошем детективе, на сцену вышел новый свидетель, который перевернул все дело. В виде ответной публикации под дерзким названием «Иллюзия иллюзии мышления» на арену вышли исследователи из Anthropic (создатели Claude) и Open Philanthropy.
Это не просто комментарий, это полный разгром. Суть их ответа проста и беспощадна: выводы Apple говорят не о фундаментальных ограничениях моделей, а о фундаментальных ошибках в дизайне самого эксперимента. Давайте посмотрим, как они разбирают аргументы Apple по косточкам.
1. Первый гвоздь в гроб «коллапса рассуждений»: закончилась бумага, а не мысли.
Помните идею, что модели «сдавались» на сложных задачах? Anthropic утверждают: модели не сдавались, они просто упирались в лимит токенов. Это не студент, который бросил решать задачу, а студент, которому дали всего один лист бумаги. Когда он заканчивается, он пишет «и так далее» и сдает работу. Модели делали то же самое, буквально сообщая в своих ответах: "Паттерн продолжается, но чтобы не делать ответ слишком длинным, я остановлюсь здесь". Автоматический тест Apple, не умея читать такие нюансы, засчитывал это как провал.
2. Второй выстрел: драма с нерешаемой задачей.
А вот тут начинается настоящая детективная история. Исследователи из Anthropic проверили условия задачи о Переправе через реку и обнаружили, что для 6 и более пар актеров/агентов при вместимости лодки в 3 человека она математически нерешаема. Это известный факт, подтвержденный другим исследованием. Получается, Apple на полном серьезе ставили моделям «неуд» за то, что те не смогли решить нерешаемую задачу. Это всё равно что наказать калькулятор за то, что он выдал ошибку при делении на ноль.
3. И, наконец, контрольный в голову: попросите рецепт, а не нарезку.
Чтобы окончательно доказать свою правоту, команда Anthropic изменила сам вопрос. Вместо того чтобы требовать от модели выдать тысячи ходов для Ханойской башни, они попросили ее написать программу (функцию на Lua), которая генерирует решение. И — бинго! — модели, которые якобы «коллапсировали», с легкостью написали идеальный рекурсивный алгоритм. Apple, по сути, тестировали механическую выносливость модели, заставляя ее «нарезать овощи» для огромного банкета. Anthropic же проверили знание процесса, попросив «написать рецепт». И модель его знала.
Так кто же прав? Иллюзия мышления или иллюзия оценки?
Этот ответный удар полностью меняет расстановку сил. Теперь выводы Apple выглядят не как открытие фундаментального порока ИИ, а как демонстрация классической ловушки для исследователя, в которую легко угодить, если не проверять свои же исходные данные.
Получается, та самая «стена сложности», в которую упирались модели, была построена не ими, а самими экспериментаторами через искусственные ограничения и невыполнимые условия.
Едкий, но справедливый вердикт от Anthropic подводит итог всей этой истории:
«Вопрос не в том, могут ли модели рассуждать, а в том, могут ли наши тесты отличить рассуждение от печатания».
Эта история — отличное напоминание, что в мире ИИ нужно сомневаться не только в ответах машин, но и в собственных вопросах. Я уверен, что многие из нас сталкивались с этим в своей практике. Иногда кажется, что модель «тупит», а на самом деле мы просто задали вопрос так, что она не может дать хороший ответ в рамках поставленных ограничений.
Что вы думаете об этом споре? Чьи аргументы вам кажутся более убедительными? Были ли у вас случаи, когда вы сами неправильно оценивали возможности ИИ просто потому, что «тест» был составлен некорректно?

{kind=link}
Я пока остаюсь при мнении, что современный ИИ — это крутой инструмент, который может облегчить работу человека, а в некоторых случаях и заменить людей, но интеллектом на самом деле не является. Искусственный интеллект — это всего лишь маркетинговый термин. LLM будут становиться умнее, будут все лучше имитировать человека, но фундаментальные проблемы все равно останутся. Нужен какой-то принципиально новый подход.
Мне очень понравилась эта статья и ее продолжение с ответами на контраргументы, потому что рассуждения и выводы автора практически полностью совпадают с моими собственными. Но написал ее какой-то никому неизвестный программист, так что наверно надо относиться к его словам примерно с той же степенью доверия, что и к моим) Но источники есть, можно проследить рассуждения и подумать самому.
Например, он там ссылается на исследование Anthropic, где они научились видеть, какие именно нейроны в модели активизируются при генерации ответа. И оказалось, что при складывании двузначных чисел современные модели все так же просто статистически угадывают ответ. Поэтому ИИ на длинных числах начинает промахиваться, так как их не было в обучающих данных.
Развитие языковых моделей сравнивается с прогрессом в поездах. С момента появления поезда стали гораздо более быстрыми и комфортными. Но несмотря на это на поезде невозможно переехать на другой континент. Чтобы быстро путешествовать через моря и горы, нужно было изобрести самолет. Причем эти два вида транспорта развиваются почти независимо друг от друга.
С противоположной стороны есть такой сайт от известных личностей в области ИИ. Они дают интересный и немного пугающий прогноз развития на ближайшие годы. На поверхностный взгляд там тоже все выглядит довольно логично и обоснованно. Но я скорее отношусь к этому, как к известному комиксу от xkcd "Мое хобби — экстраполировать".
С интересом продолжаю следить за прогрессом.
Мне однажды УЗИ сердца делал завкафедры нашего мединститута, ну и у него под рукой было пару студенток. Он им показывает че там у меня и говорит "скажите что тут не так поставлю зачет автоматом".
Ну и как подабает LLM они пошли перебирать все что могли вспомнить, а оказалось что правильный ответ "тут все ок, это здоровое сердце"
Нет, они поняли, что отстают, и решили выкатить статью с хот тейком, чтобы хайпануть. И у них это получилось. На всякий случай, в качестве автора статьи сделали интерна женщину индуса, чтобы если что, можно было сказать, что это её личное мнение, а мы не доглядели.
Тут вообще непонятно в чем дискуссия, apple сами придумали какой-то тезис, сами сделали вид что опровергли, ну молодцы че.
Вроде никто и не утверждал, что модели умеют думать. А учитывая, что мы и про человека не очень понимаем, а что же это такое - "думать", то такая дискуссия вообще не имеет смысла.
Ну, как обычно всё.
Эппл отстаёт, мы это знаем. Они провафлили, но я думаю, у них со своей платформой есть много вариантов. Так что за них я бы не волновался.
Антропик дали отличный ответ.
Действительно ЛЛМки - это замечательный инструмент, который особо полезен в поиске разношёрстных данных. По-факту, вообще незаменимый инструмент.
Проблема в том, что во всё это впутываются ультра-левые и ультра-правые. Про-ИИшники и Анти-ИИшники. И те и другие начинают бурлить говнами и накидывать на вентиляторы совершенную чушь, потому что в отличие от Антропиков, в которых работают вменяемые математики, эти говорят про электронные мозги, разум, разумность и способность заменить человеческий интеллект.
Кстати, рассказы о том, что компьютер - думает - это древняя легенда. Ещё в 1953 году Алан Тьюринг использовал словосочетание "Электронный мозг". И даже в то время он его использовал в следующем контексте:
То есть уже тогда мы считали, что электронный мозг - это какой-то клерк со счётной машиной. Насколько я знаю, никакая современная наука не определяет мозг как "Клерк со счётной машиной".
Проблема в том, что у нас начинают смешиваться две области знания, которые должны находиться в разных комнатах. С одной стороны - LLM, GPT, регрессионный анализ, и математическое моделирование со статистикой, а с другой стороны - это человеческий разум, внимание, мысли, идеи и тому подобные вещи.
Мы неплохо разбираемся в первой части всего этого. Но, насколько я могу видеть, понимание человеческого разума находится в плачевном состоянии. Ни одна наука на данный момент не может дать чёткого и не-философского определения слову "мысль" или "разум". У нас есть подозрения, и мы знаем, что если потыкать током туда или сюда, то можно вызвать глюки, но что конкретно мы знаем, мы не особо понимаем.
Сверху на это непонимание сваливаются необразованые репортёры и блоггеры. Они начинают радостно писать и рассуждать о том, как Чат ГПТ влияет на пределы человеческого мышления. Про первую часть этого предложения, такой человек знает примерно пару абзацев, а про вторую - вообще ничего. Но, это не мешает писать статьи обильно сдобренные антинаучными заявляениями про т.н. "Системы Искусствунного Интелекта" и то, как они относятся к человеческому разуму.
Как следствие, после этого в Эппл появляются интерны, которые пишут такие-вот статьи.
В то же время, есть нормальные люди. Они - разработчики и пользователи ИИ, которые не хайпом пользуются, а пытаются что-то полезное из этого ИИ выжать.
И тут уже рассуждения на другом уровне проводятся.
Например, когда я использовал ChatGPT 3.0 он более-менее вразумительно умел писать функции к яваскриптам. Иногда ошибался, но писал.
GPT 3.5 всё так же писал функции для яваскрипта, иногда ошибался, но писал сносно. Но ни тот ни другой не знали ничего про Netsuite, и когда я просил написать плагин для нетсуита, то они врали напрополую.
Когда вышел GPT 4.0 то в нём уже были данные о том, как работает Netsuite, и поэтому он уже мог писать фукнции для Netsuite. Иногда ошибался, но писал.
С тех пор прошло полтора года. У меня теперь Клод 4. "Думающий". Он всё так же пишет функции к Netsuite, иногда ошибается, но пишет. И всё так же не может в автоматическом режиме написать более-менее нормальный модуль или плагин.
Как ни крути, видимый прогресс ЛЛМок был в том, что им скормили больше данных, и потратили больше энергии на обучение, но по личным наблюдениям, конкретных улучшений я не вижу. Мне как надо было писать код с двух-трёх, промптов, так я и продолжаю его писать после двух-трёх промптов. Как скисали модели после пяти промптов, так они и продолжают скисать. Ну теперь после семи, но скисают.
Мне кажется, что в 2025 году нам надо начинать требовать, чтобы кто-то занялся онтологией. Сделать полный ребут, и начать сначала. Нам пора прекращать притворяться, что у нас есть наука, которая занимается человеческим разумом, и начинать настаивать, чтобы такая наука появилась. И начинала она не с того, чтобы анализировать "все существующие в мире данные на эту тему", а заняться созданием базовых постулатов, на основании которых такая наука могла бы строится. А уже после того, как мы с этим разберёмся, тогда уже бежать и брызжать слюной о том, что ИИ щас сделает то или это. На данный момент это звучит как "ИИ умеет сепулькать". Мы не особо понимаем, что такое сепулькание, но ИИ щас в нём устроит переворот.
При том, что сам по себе ИИ - это охуенный инструмент, который уже устроил много переворотов поменьше.
По личным ощущениям, спорить сейчас с АИ-скептиками, примерно то же, что и с "плоскоземельцами". Т.е. в теории можно, но трудно и бесполезно, а значит и не зачем.
Ну и претензии к термину "Искусственный интеллект", мне кажутся странными.
Это термин, для инструмента, который решает интеллектуальные задачи. Даже тот механизм, который регулировал светофоры на перекрестках еще 10 лет назад, уже вполне себе был "Искусственный интеллект".
Вороны способны эффективно решать некоторые интелектуальные задачи. Читал, что в ряде экспериментов они это делали эффективней людей.
Т.е. у воронов есть механизм решения интеллектуальных задач. Зачем доказывать, что это не так, они не могут думать и не построят воронскую цивилизацию )?
Зачем цепляться к терминологии? Никто ведь и не пытается доказывать, что ИИ по человечески разумен.
Что касается сабжа, то как мне кажется, даже если будет доказано, что эффект "думанья", это та же китайская комната на максималках, это ничего в принципе не изменит.
Инструмент "ИИ" совершенствуется семимильными шагами. А то, что он так и не сможет себя осознать и составить нам конкуренцию, вовсе не кажется чем-то особо ужасным.
За очень короткое время сделали колоссальный рывок в AI, агентской продуктивности, это факт. Вектор и так демонстрирует, что пошли правильно: объем + качество данных и увеличение мощности вычислений.
Вопрос ведь в том как заиспользовать и перестроить алгоритм инференса для LLM на работу по созданию гипотез, оценки их вероятности, как их хранить и управлять их верификацией. Вероятно для многих "жадных" задач придется генерировать гораздо больше данных чем в себя вмещает сама модель. А это уже быстрая внешняя память, компьют, оценки сложности алгоритмов. Но опять ни какой магии.
Спасибо, что привел здесь не только развернутые положения оригинальной статьи (ее выводы уже набили оскомину чуть более чем всем), но и наиболее релевантный ответ - от Anthropic, я про него ничего не знал. Тут получилась embedded дискуссия сразу 😎
По существу бизнес-интересы обеих сторон более или менее понятны, а встречная критика как раз очень интересна и на пользу радикальным лагерям хайпа AI.
Все время относился к думающим моделям как к ллм со скрытым этапом генерации текста
Вместо
Получить запрос -> выдать ответ
Стало
Получить запрос -> сгенерировать цепочку ответов -> выдать финальный ответ
В какой то степени было бы интересно понаблюдать за историей про MoE, где один скажет что даже незначительные параметры могут повлиять на ответ, а другой что они уменьшают точность (это выдумал из головы просто как вариант споров)
Поверю в умение ллм-ками мыслить, когда увижу сгенерированное изображение бокала вина, наполненного до краев.
Что скажешь по этому подходу - https://the-decoder.com/a-new-study-by-nyu-researchers-supports-apples-doubts-about-ai-reasoning-but-sees-no-dead-end/
В прошлую пятницу надо было съездить в офис энергетиков, утром спрашиваю думающую колонку: Алиса, сегодня рабочий день?
Да, грит, сегодня пятница, рабочий день.
Приехал, офисный центр во мраке, откуда-то из глубин коридоров раздаётся хихиканье искусственного интеллекта...
Красиво! Спасибо