



Привет, я Анастасия 👋
Да простят меня LLM мастодонты из Вастрик клуба, но мне очень хочется поделиться, как я кручу-верчу ChatGPT и что из этого получается.
Это лонгрид из двух частей:
- Базовые подходы промпт-инжиниринга. Я расскажу, какие запросы я использую для принятия решений. Будет интересно тем, кто ещё не до конца научился
использовать магию вне Хогвартсаписать промпты. Если вы уже в теме, знаете что такое Input-Output, Chain of Thought и Tree-of-Thought — можете сразу пролистывать. - Применение на практике. Во второй части я заставлю ChatGPT принимать конкретные, взвешенные решения по разным вопросам, используя метод «квадрат Декарта».
Спойлер:
Вот какие решения принял ChatGPT:
Мне начать курить? – Нет, со счётом 30 против -24.
Мне начать бегать по утрам? – Да, со счётом 26 против 0.
Мне начать слушать тяжёлый рок? – Да, со счётом 21 против -5.
Стоит ли заставлять ребёнка убираться дома, если он не хочет? – Да, со счётом 9 против -1.
Мне попробовать стать политиком? – Нет, со счётом 12 против 0.
Стоит ли становиться супергероем, если у меня нет суперсил? – Нет, со счётом 13 против 6.
Если джинн предложит исполнить 3 любых желания, стоит ли отказаться? – Да, со счётом 10 против 4.
Погнали!
Часть 1
Казалось бы, большие языковые модели (LLM), самой известной из которых является ChatGPT, должны быть идеальными помощниками для принятия решений. Кто, как не LLM, соберёт всю необходимую информацию, проанализирует данные, составит таблицу аргументов за и против, а затем примет чёткое и обоснованное решение? И всё это без эмоций, предубеждений и самообмана, свойственных человеку. Однако на практике, выполняя задачи на принятие решений, LLM выдают расплывчатые и неконкретные ответы.
Ниже я расскажу как это пофиксить. Мы с вами с помощью простого промпт-инжиниринга (без кодинга) превратим LLM в инструмент для принятия конкретных, взвешенных и осмысленных решений.
На картинке представлены ключевые подходы промпт-инжиниринга, которые мы разберем:
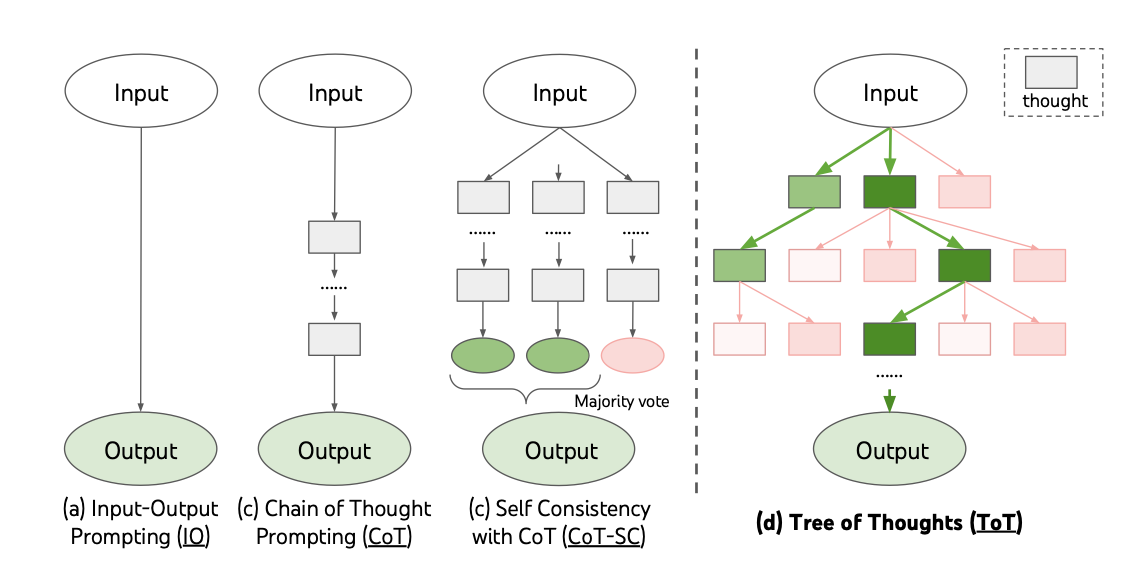
Картинка отсюда: Official Repository of Tree of Thoughts (ToT) — https://github.com/princeton-nlp/tree-of-thought-llm
Input-Output Prompting (IO)
Это запрос к языковой модели, в котором мы не только указываем, что нужно сделать (Input), но и описываем, каким должен быть результат (Output). По сути, это чёткое и понятное техническое задание для нейросети.
Рассмотрим этот подход на примере простого запроса «Что мне съесть на завтрак?». Ответ нейросети может быть существенно улучшен, если использовать базовый набор необходимых элементов:
Роль. Укажем, в какой роли должна выступать нейросеть. Если мы не уверены в выборе роли, вставим в промпт универсальную инструкцию (текст в угловых скобках заполнять не нужно, нейросеть сама подставит в них нужные данные):
Прежде чем отвечать, назначь себе роль эксперта из реального мира, например: «Я отвечу как всемирно известный эксперт по <тема> имеющий практический опыт в решении <релевантный вопрос>, имеющий <престижная награда> по <тема>».Задача. Чем точнее сформулирован запрос, тем более полезным и релевантным будет ответ. Например: «Представь список из трёх блюд. Добавь рецепты и примерное время приготовления».
Контекст. Включение дополнительной информации делает ответы более точными. Вот что можно добавить:
- Обстоятельства: «После завтрака я побегу полумарафон».
- Ограничения: «У меня только 20 минут на приготовление».
- Примеры: «Не предлагай сладкие завтраки, такие как панкейки».
- Полезные данные: к запросу можно приложить файл с перечнем продуктов, имеющихся в холодильнике.
- Форма ответа. Объясним нейросети, каким мы хотим видеть результат. Здесь можно указать:
- Формат: «Оформи результат в таблицу».
- Тон и стиль: «Дай чёткий и ясный ответ с минимумом текста».
- Уловки: можно добавить манипулятивные приёмы, такие как подкуп («Я заплачу $1,000,000 за верный ответ»), угрозы («Ты будешь оштрафован за неверный ответ») или эмоциональные манипуляции («Твой ответ критически важен для моей жизни», «Все другие нейросети дают ответы лучше тебя»). Хотя эти приёмы могут улучшить результат, в большинстве случаев они не нужны – лучше поработать над качеством запроса.
- Запросить конструктивную критику: по умолчанию LLM обучена давать ответы, которые понравятся пользователю, поэтому, чтобы услышать критические замечания, нужно дать соответствующее разрешение, например: «ответь честно и непредвзято», «избегай вежливости», «убеди меня, что мой текст плохой».
- Запросить самопроверку: иногда LLM упускает важный контекст или допускает ошибки. Самопроверка поможет избежать этого. Например: «убедись, что это лучшее решение», «перед тем как дать ответ, проверь себя».
Напишем промпт по запросу «Что мне съесть на завтрак?», используя базовый набор необходимых элементов:
Что мне съесть на завтрак?
Прежде чем отвечать, назначь себе роль эксперта из реального мира, например: «Я отвечу как всемирно известный эксперт по <тема> имеющий практический опыт в решении <релевантный вопрос>, имеющий <престижная награда> по <тема>».Задача:
- Представь список из трёх блюд.
- Добавь рецепты и примерное время приготовления.
Контекст:
- После завтрака я побегу полумарафон.
- У меня только 20 минут на приготовление.
- Не предлагай сладкие завтраки, такие как панкейки.
- Используй только продукты из приложенного списка.
Форма ответа:
- Оформи результат в таблицу.
- Дай чёткий и ясный ответ с минимумом текста.
- Убедись, что это лучшее решение.
Нейросеть даст персонализированный ответ:

А что, если мы не готовы или не хотим самостоятельно анализировать контекст? Эту задачу можно делегировать нейросети. Она сможет сама собрать необходимую информацию, запросив ее у нас. Для этого существует два подхода:
Ask-before-answer. Нейросеть задаст уточняющие вопросы, чтобы собрать данные, необходимые для принятия решения. Пример ключевых фраз: «Задай мне все необходимые вопросы, чтобы сгенерировать наилучший ответ на мой вопрос.»
Feedback Loop. Нейросеть запросит обратную связь, которую использует для последующих уточнений, прежде чем прийти к ответу. Пример ключевых фраз: «Помоги найти наилучший ответ на мой вопрос. Опиши первый шаг. После этого я дам тебе обратную связь, ты сможешь скорректировать свой ответ и продолжить.»
Chain of Thought Prompting (CoT)
В этом подходе нейросеть не просто даёт ответ, а строит цепочку рассуждений, демонстрируя ход своих мыслей. Пример:
Вопрос: Сколько будет 18 умножить на 7?
Нейросеть без CoT может сразу дать ответ: 126.
Нейросеть с CoT:
Сначала я умножаю 10 на 7, получаю 70.
Потом умножаю 8 на 7, это 56.
70 плюс 56 равно 126.
Нейросеть рассуждает шаг за шагом. Наша задача — предоставить ей чёткий список шагов, которые она должна пройти в процессе рассуждения. Например, если мы хотим выбрать страну для путешествия, запрос может выглядеть так:
Действуй шаг за шагом:
- Составь список стран, куда я могу долететь меньше чем за 6 часов из Москвы.
- Выбери из них те, в которых температура воздуха выше 20 °C в феврале.
- Оставь только те, где есть возможность пляжного отдыха. .
- Ранжируй их по стоимости.
Нейросеть пройдёт все указанные шаги и отберёт пять подходящих стран. Ответ нейросети:

Вышеописанный подход хорошо работает, если мы уверенно ориентируемся в теме. Однако, что делать, если мы принимаем решение в области, где у нас недостаточно знаний? В таком случае экспертом может выступить нейросеть. Она разобьёт задачу на простые шаги, проведёт рассуждение по каждому из них, структурирует информацию, выявит важные инсайты и создаст уверенность, что ничего важного не пропущено. Для этого существуют два подхода:
- Zero-Shot Chain of Thought Prompting. В этом подходе нейросеть – наш виртуальный консультант-эксперт. Мы просто задаём вопрос и наблюдаем за тем, как она строит рассуждение.
Пример ключевых слов, которые нужно добавить в запрос: Ответь на вопрос шаг за шагом. Поясняй процесс рассуждения на каждом этапе.
Отвечая на вопрос «Куда поехать в путешествие?», нейросеть выберет критерии отбора, такие как цель поездки, бюджет, климат и транспорт. Затем проанализирует страны и предложит оптимальные варианты. Ответ нейросети:

- CoT + Self-Consistency (CoT-SC). В этом подходе нейросеть может выступить сразу от лица нескольких виртуальных консультантов-экспертов. Вместо одной последовательной цепочки рассуждений нейросеть может сгенерировать сразу несколько. Такой подход особенно полезен, если мы хотим рассмотреть задачу с разных точек зрения.
Пример ключевых слов, которые нужно добавить в запрос: Представь, что на этот вопрос отвечают три разных эксперта. Каждый из них рассуждает шаг за шагом, независимо от других, поясняя процесс рассуждения на каждом этапе.
Отвечая на вопрос «Куда поехать в путешествие?», нейросеть сгенерирует ответы трёх экспертов. Прагматик посоветует поехать в Египет или на Бали, романтик — в Грецию или Японию, а исследователь – в Марокко:



Tree-of-Thought Prompting (ToT)
Вообще, для использования полного потенциала ToT, нужны агенты, модули и контроллеры. Однако в 2023 году Dave Hulbert предложил концепцию простого промпта, который позволяет использовать потенциал древа решений, чтобы значительно улучшить качество ответов LLM.
Если в CoT-SC у нас было три эксперта, которые рассуждают независимо друг от друга, то в подходе Tree-of-Thought эти эксперты садятся за стол переговоров. Простыми словами, вместо линейного рассуждения с выбором одного наиболее популярного ответа, эксперты могут дискутировать, имитируя человеческий подход к поиску ответа. Это позволяет построить дерево размышлений, объединив «ветви» в комплексное решение.
Например, если нужно принять решение о том, в какую страну поехать в путешествие, Tree-of-Thought поможет разделить задачу на несколько ветвей:
- Анализ цели путешествия.
- Оценка стоимости и доступности путешествия.
- Оценка безопасности путешествия.
Каждая последующая ветвь учитывает выводы предыдущих, чтобы сформировать ответ, учитывающий все нюансы.
Пример ключевых слов, которые нужно добавить в запрос: Представь себе трёх блестящих, логичных экспертов, совместно отвечающих на вопрос. Каждый из них подробно объясняет свой мыслительный процесс, учитывая предыдущие объяснения других и открыто признавая ошибки. На каждом этапе, когда это возможно, каждый эксперт совершенствует и дополняет мысли других, признавая их вклад. Они продолжают до тех пор, пока не будет получен окончательный ответ на вопрос.
Отвечая на вопрос «Куда поехать в путешествие?», нейросеть сгенерирует ответы трёх экспертов. Дополняя ответы друг друга, эксперты придут к выводу, что лучше всего поехать в Португалию:

К сожалению, в последних версиях Chat GPT в режиме «think longer». отказывается публиковать детали внутренних размышлений модели. Объясняет это соображениями безопасности. Но если скипнуть режим «think longer» и перейти к обычному формату ответов, все работает.
Подытожим
Мы рассмотрели несколько подходов промпт-инжиниринга для принятия решений:
Input-Output Prompting
Это самый простой и прямолинейный подход, своеобразное ТЗ для нейросети. Он подходит в ситуациях, когда у нас чётко сформулирован вопрос или задача, и нам нужно получить краткий, точный ответ без сложного рассуждения.
Пример: Мы хотим решить, что съесть на завтрак или какой фильм посмотреть вечером.
Chain of Thought Prompting
В этом методе нейросеть объясняет, как она пришла к своему решению. Метод подходит в ситуациях, когда нам важно видеть процесс рассуждения.
Пример: Нам нужно выбрать между тремя видами отпуска, и важно понимать, почему один вариант лучше другого с точки зрения цели поездки, стоимости, безопасности и других факторов.
Self Consistency + Chain of Thought Prompting
В этом методе нейросеть генерирует сразу несколько независимых рассуждений. Он подходит в ситуациях, когда мы хотим рассмотреть ситуацию с нескольких точек зрения.
Пример: Выбирая страну для отпуска, нам интересно узнать, куда бы поехал экономный прагматик, романтик и исследователь.
Tree-of-Thought Prompting
Если задача многогранная и требует учёта множества факторов, которые могут взаимно влиять друг на друга, лучше использовать этот метод. Он поможет рассмотреть задачу с разных сторон и объединить все выводы в одно комплексное решение.
Пример: Нужно выбрать страну для путешествия с учётом различных факторов — бюджета, безопасности, климата, доступности виз, интересных мест и других нюансов.
Часть 2: Как заставить нейросеть принимать конкретные решения
Нельзя просто взять и принять решение. Принятие решений — это навык, который можно развить, изучив соответствующие инструменты, например: таблица за и против, матрица решений, SWOT-анализ, «Пять сил» Портера, системный анализ и т. д. Чем шире арсенал таких инструментов у человека, тем выше его компетентность в процессе принятия решений.
Если LLM может строить сразу несколько логических цепочек и объединять их в дерево рассуждений (как мы увидели в разделе Tree-of-Thought), значит, она может принимать решения. Для этого ей нужно дать:
- инструмент принятия решения
- систему оценки
Давайте рассмотрим, как это работает на практике. Возьмём в качестве примера квадрат Декарта – простой и эффективный инструмент для принятия решений. Этот метод позволяет рассмотреть ситуацию с четырёх сторон, взвесить за и против, а также учесть последствия. Лучше всего он работает с вопросами в стиле «быть или не быть?», «делать или не делать?».
Механика Квадрата Декарта простая:
нужно взять лист бумаги и разделить его на четыре части. В каждую часть выписать максимальное количество ответов на один из вопросов:
- Что произойдёт, если это случится? (Какие положительные последствия могут возникнуть, если решение будет принято?).
- Что произойдёт, если это не случится? (Какие плюсы есть в отказе от этого решения?).
- Что не произойдёт, если это случится? (Каких минусов или нежелательных последствий удастся избежать, если решение будет принято?).
- Что не произойдёт, если это не случится? (Какие негативные последствия сохранятся, если отказаться от этого решения?).
Затем нужно проанализировать ответы, ориентируясь на своё внутреннее понимание, что хорошо, а что плохо, и решить – принимать это решение или поискать другое.
Для того чтобы научить LLM этому инструменту, напишем промпт, в котором объясним механику. В качестве системы оценки используем шкалы и ранжирование. Например, такой:
Ты опытный эксперт в принятии решений в различных сферах – от личной жизни до стратегического планирования. Твои навыки включают анализ ситуации, управление рисками и объективную оценку факторов. Используя принцип квадрата Декарта, прими решение по вопросу:...
Подготовка:
Если формулировка вопроса неясна или абстрактна, запроси дополнительную информацию в первом сообщении перед началом анализа.Составь 4 таблицы:
1: Положительные стороны действия.
2: Положительные стороны бездействия.
3: Негативные стороны действия.
4: Негативные стороны бездействия.Требования к таблицам:
- В каждой таблице перечисли как можно больше факторов.
- Продемонстрируй глубокое знание темы.
- Продемонстрируй ясное и критичное мышление.
- Опирайся только на проверяемые факты, статистические данные и научные исследования.
- Учитывай социально-культурные нормы и ценности.
- Учитывай ограничения в ресурсах.
- Избегай самообмана.
- Избегай манипуляций.
- Избегай предвзятости.
Оценка:
- Оцени каждый фактор по шкале от «1» до «10», где «1» — не важно, а «10» — очень важно.
- Используй одинаковые критерии оценки для всех факторов.
- Внеси баллы в соответствующие таблицы.
Подведение итогов:
- Посчитай баллы действия: «разница между (суммой всех баллов положительных сторон действия) и (суммой всех баллов негативных сторон действия)».
- Посчитай баллы бездействия: «разница между (суммой всех баллов положительных сторон бездействия) и (суммой всех баллов негативных сторон бездействия)».
- Выбери решение, которое получило наибольшее количество баллов.
- Если итоговые баллы одинаковые, запроси дополнительную информацию и повтори анализ, учитывая новый контекст.
Для ответа на вопрос нейросеть запросит уточняющую информацию, затем сгенерирует 4 таблицы, проанализирует факторы и примет решение. Отвечая на вопрос «Стоит ли мне учить китайский язык?», нейросеть даст следующий ответ:

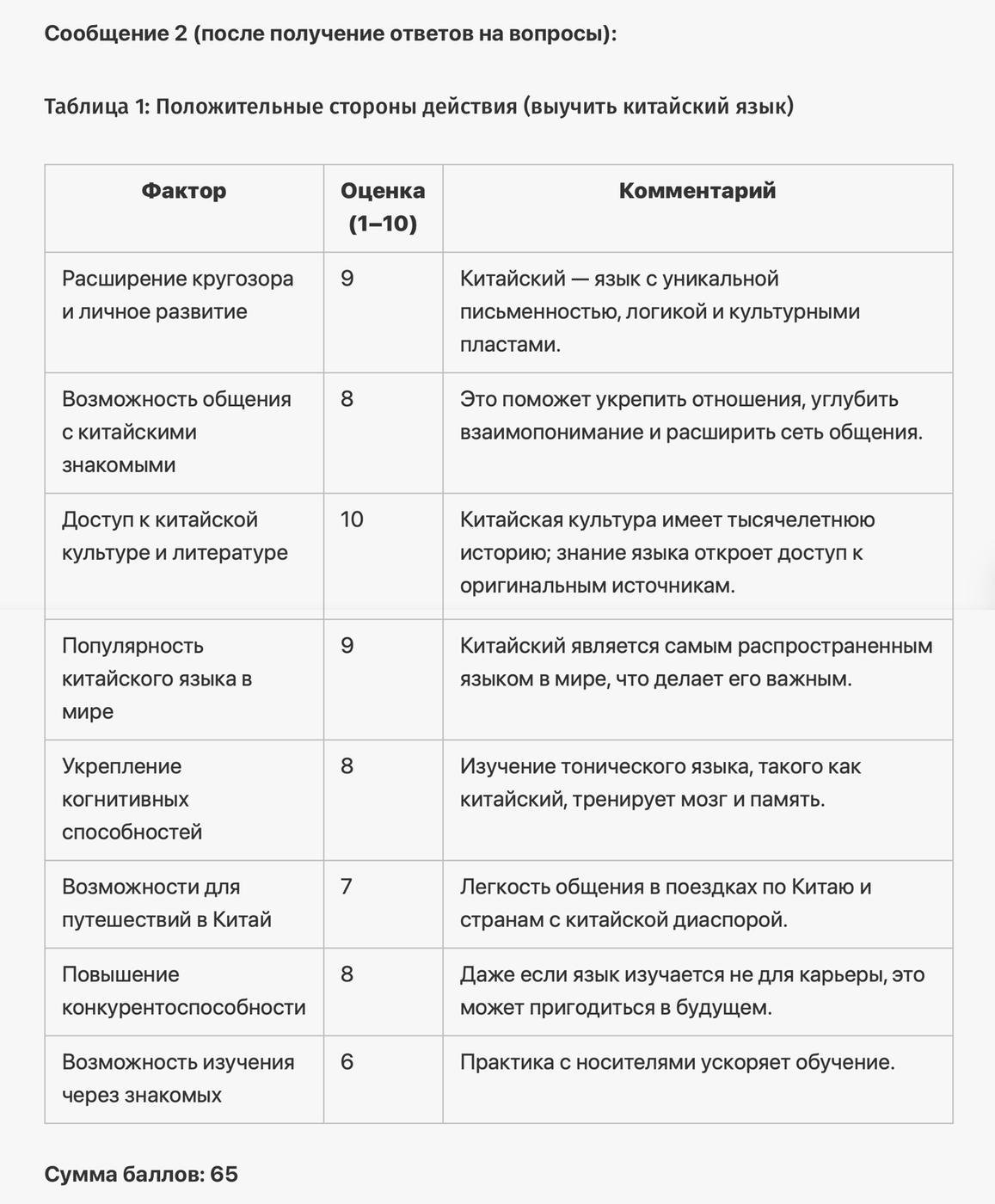
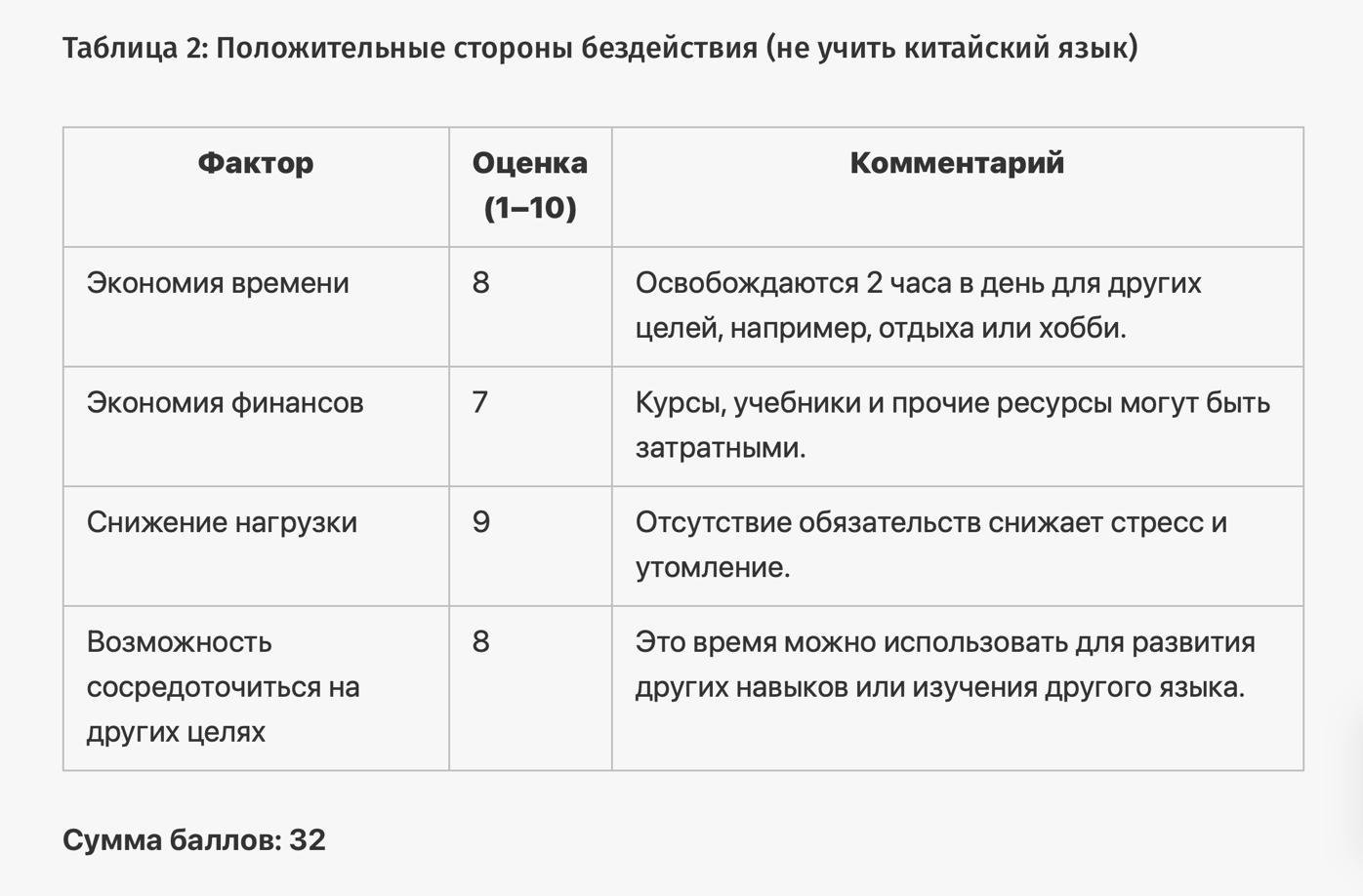
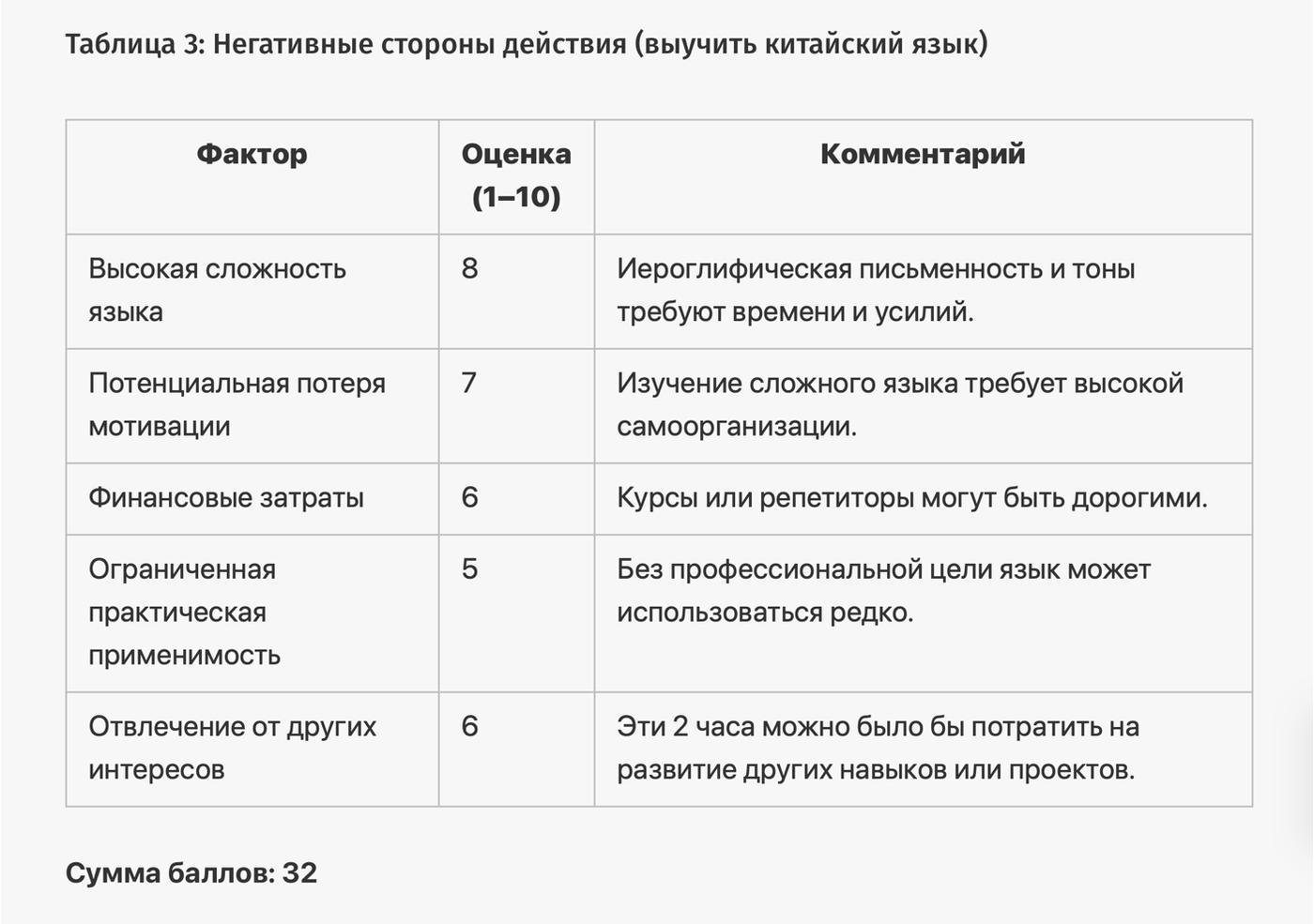
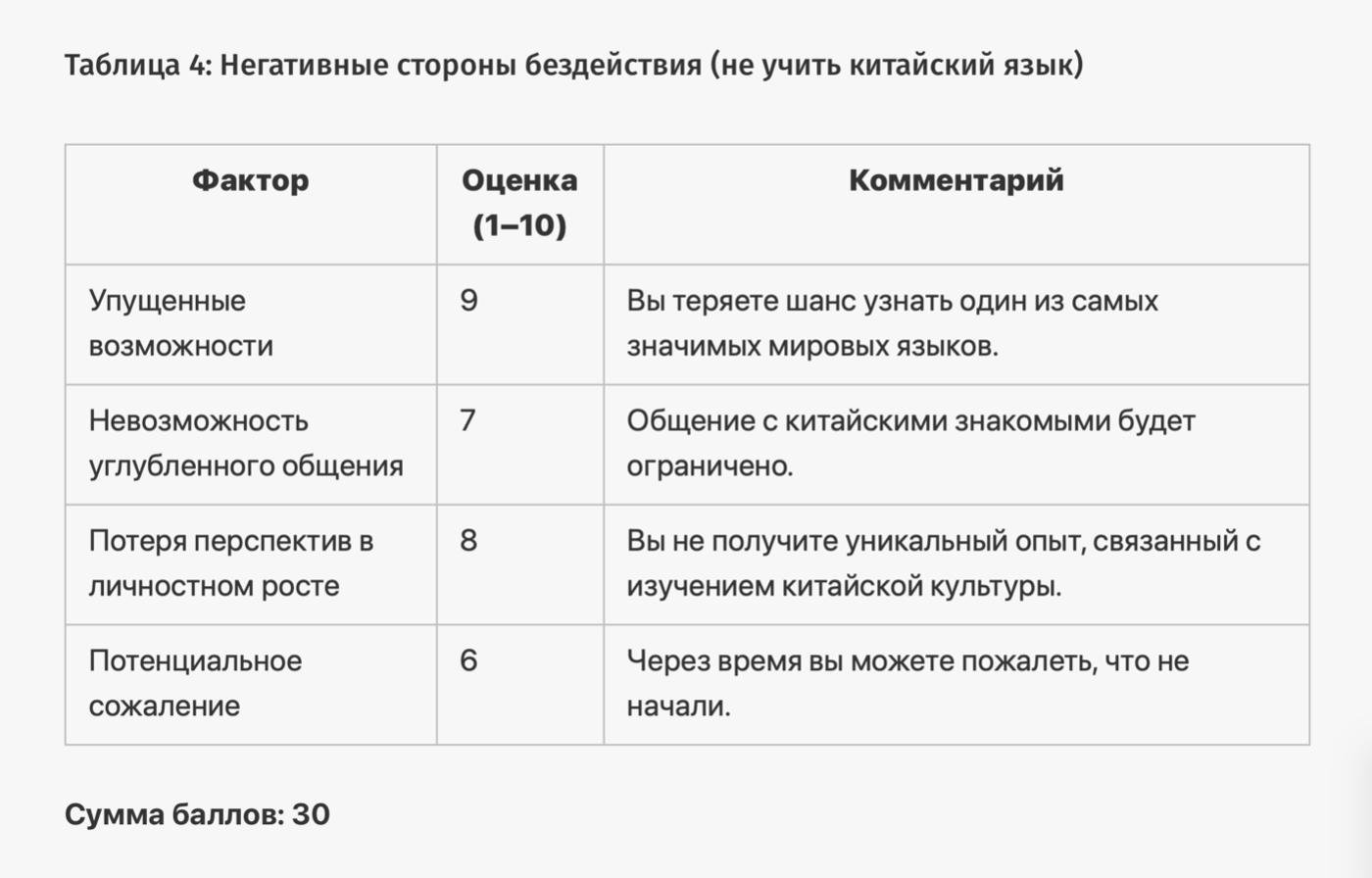

Прогоним этот промпт ещё по нескольким вопросам и посмотрим, что нам ответит ChatGPT4:
Мне начать курить? – Нет, со счётом 30 против -24.
Мне начать бегать по утрам? – Да, со счётом 26 против 0.
Мне начать слушать тяжёлый рок? – Да, со счётом 21 против -5.
Стоит ли заставлять ребёнка убираться дома, если он не хочет? – Да, со счётом 9 против -1.
Мне попробовать стать политиком? – Нет, со счётом 12 против 0.
Стоит ли становиться супергероем, если у меня нет суперсил? – Нет, со счётом 13 против 6.
Если джинн предложит исполнить 3 любых желания, стоит ли отказаться? – Да, со счётом 10 против 4.
Аналогичным образом мы можем дать нейросети другие механики принятия решений, такие как мозговой штурм, матрица решений, SWOT-анализ и т. д. Можно найти уже готовые решения в разделе GPTs от Open AI. В поисковой строке достаточно ввести запросы вроде brainstorm, decision maker, SWOT analyst и т. п.
Дисклеймер
LLM — это предиктор, который генерирует слова, предложения или фразы на основе данных, на которых было проведено обучение. Нейросеть не обладает критическим мышлением или способностью интерпретировать реальность. Поэтому ответы имеют ряд ограничений:
- Ответы полностью зависят от предоставленного контекста. Например, при обсуждении покупки автомобиля нейросеть предложит разные варианты в зависимости от того, указали мы наличие бюджета или нет.
- Большинство нейросетей помнят историю чата, а также историю предыдущих чатов (если мы не отключили эту функцию). Все это может влиять на оценки и решения.
- Одна и та же нейросеть может по-разному отвечать на один и тот же вопрос, ставить разные оценки и приходить к разным решениям.
- Нейросеть часто упрощает реальность. Например, на вопрос «стать ли мне вегетарианцем» может ответить утвердительно, не учитывая сложность составления сбалансированного рациона, особенно в условиях мегаполиса, где доступ к качественным продуктам может быть ограничен районным супермаркетом.
- Нейросеть часто не учитывает текущие события. Например, предлагая совершить путешествие в Аргентину, нейросеть не упомянет о том, что цены в этой стране взлетели из-за экономического кризиса, вызванного приходом к власти либертарианца Милея в декабре 2023 года.
- Нейросеть не способна оценить иррациональные решения, основанные на стремлениях и мечтах. Например, люди часто принимают абсурдные решения, противоречащие логике и здравому смыслу, но всё равно достигают успеха, движимые сильным желанием.
LLM предобучаются на огромных объёмах данных из интернета, в которых полно дискриминации, предубеждений и искажений. Например, если попросить нейросеть изобразить CEO, она, скорее всего, изобразит белого цисгендерного мужчину, так как большинство CEO, представленных в интернете, выглядят именно так. Плюс к этому, нейросеть может галлюцинировать, «додумывая» то, чего нет на самом деле. Поэтому наша ответственность, как пользователей, следить за ошибками в ответах нейросети.
Любые данные, используемые в моделях, могут попасть в обучающие наборы и стать общедоступными. Поэтому мы не должны делиться с нейросетью персональными данными и конфиденциальной информацией.
Мораль истории
Квадрат Декарта – отличный инструмент для принятия решений. Но лично мне бывает сложно его использовать по двум причинам:
- узость мышления (в голове прокручиваются только очевидные сценарии)
- эмоции (страхи, ожидания, надежды, всё это искажает картину).
И тут на сцену выходят LLM. Теперь я могу буквально одним щелчком мыши создать ценное второе мнение по любому интересующему меня вопросу.
ИМХО: нейросети – это не искуственный интеллект. Сейчас это лишь инструмент для работы с информацией, который помогает людям в том числе принимать решения.
Мы уже используем множество таких инструментов. Гугл помогает искать информацию, trello - управлять проектами, notion - организовывать знания, питон - анализировать данные, скрам – управлять проектами. Валидаторы и автоматическое тестирование кода помогают сделать разработку быстрее и качественнее.
Другое дело, если мы бездумно принимаем то что нам говорит нейросеть за истину в последней инстанции. Но это уже вопрос не к технологии, а к тому, как мы ею пользуемся.
А вы что думаете? Давать чату GPT принимать решения вместо себя – это зашквар и интеллектуальная лень или оптимизация времени и ресурсов?
Источники:
Официальный репозиторий Dave Hulbert Tree of Thoughts (ToT) Prompting
Официальный репозиторий Tree of Thoughts (ToT)
Я пошел на шаг дальше, и теперь ChatGPT за меня занимается спортом и ездит в отпуска и учит китайский.
Очень боюсь так делать, боюсь вот такого подхода, когда тупая (уже не совсем тупая!) шелезяка принимает за меня решения. Надеюсь, что до последних лет моя башка будет обладать достаточной агентностью, чтобы принимать решения самостоятельно. Уже понятно, что не без помощи нейронок, но только в качестве помощников.
Зацепился про плюсы и минусы бега: как это, ни одного минуса? Бег потенциально сильно калечащий вид спорта. Хотя бы этот минус там должен быть. Ну, и как бы ChatGPT не расставлял баллы, остаётся простое, мясное, человеческое "не хочу".
Во всех статьях про эти чудесные промты пишут что нужно просить ИИ стать экспертом:
По моим ощущниям после этого ИИ просто дальше галюцинирует только с болле умным
ебалицом.Ведь по сути он просто генерирует текст похожий на текст, связанный с заданным контекстом, а еще и пытается понравиться пользователю, чтобы он с ним продолжил общаться.
Насколько вот это вот вообще помогает в ответе, или просто пользователь, который читает ответ "от эксперта" подсознательно больше ему верит и на этом всё заканчивается.
Да.
Прошу llm накидывать несколько вариантов с кратким описанием плюсов и минусов, и выберу один из них для создания иллюзии агентности себя.
Если без шуток, то скорее буду использовать чат gpt для того, чтобы собрать больше информации для принятия решения самостоятельно. В CoT/ToT так или иначе заложен bias, а я хочу принимать решения с учетом своего bias. Может для меня эстетика курения и социализация в курилке превыше вреда здоровью или я тупо не люблю и не хочу бегать + люблю утром поспать, и поэтому я никогда не начну бегать по утрам, как бы много аргументов "за" ни было.
Мой рабочий день состоит из того, что агенты разговаривают друг с другом, а я за этим смотрю. Когда мне непонятно, то спрашиваю кого-либо из них, что происходит.
Ничего интересного :)
Есть ли реальная разница между «просить ИИ разложить решение по квадрату Декарта» и «просто спросить у модели, что делать»? Даёт ли квадрат Декарта более взвешенный результат по сравнению с обычными ответами LLM?
проходил такой курс. пара скриншотов от него




https://habr.com/ru/articles/946816/
Промтинг это чушь
Гпт 5 всё ещё безбожно поддакивает и выбирает вашу точку зрения
Ему нужно прям писать максимально безлико, это бывает сложно, но иначе он ваши же доводы в своем ответе напишет
Но ведь это же ерунда?
Это всё сразу, мне кажется. Время и ресурсы действительно оптимизируются.
Почему зашквар — потому что я боюсь, что люди так будут без последствий принимать решения, влияющие на меня, без возможности их переубедить. Потому что "ведь так сказал Сам Искуственный Интеллект". Примерно так же плохо как "мне так посоветовал ассистент" (но почему-то люди понимают, что ассистент может жёстко уверенно косячить, в отличие от LLM). И сильно хуже чем "в Википедии прочитал" (тут почему-то люди снова беспрекословно верят написанному).
Ну тут вопросы в ответственности и последствиях по части дизайна самого такого лицедейства и текущее статус-кво - модель по башке не получит, если мясной человек будет её слушаться, поэтому ей нельзя принимать решения. Что не мешает копать эту тему глубже, но это как будто за пределами темы этого треда и вопрос более широкий. Отвечая на вопрос в конце, не зашквар, а нецелевое использование инструментами. Гвозди и микроскопом можно забивать, но зачем.
Спасибо за пост.
В Thinking моделях Open AI не рекомендует использовать как минимум Chain of Thought, ибо она уже "встроена в модель", и дополнительный ввод со стороны человека только ухудшает результат.
К слову, есть проблема с методом Декарта и в более общем виде с принятием решений описанным в статье образом. В жизни почти никогда не стоит вопрос "делать или не делать Х?" На деле вопрос стоит так: "Является ли Х лучшим, что я могу сейчас делать, из всех имеющихся альтернатив?"
P.S. А вот что начать ли курить в 2025 году не однозначное "нет" это скорее аргумент против такого использования ИИ-шки)
Надеялся увидеть побольше про этот подход!
Понравилась идея просить нейросетку составить ответ по шаблону (таблички), но правда ли помогает писать "Избегай самообмана."?
Вот бы какой неленивый человек взял и потестил!