

Когда в начале ноября я взялся за перевод и редактирование лучшей книги про обучение LLM, я еще не знал, какое наслаждение испытаю в процессе. Скажу честно, последний раз такой кайф от технической литературы я ловил, когда читал "Дедлайн" Тома Демарко и "Программист-прагматика" Ханта и Томаса.

На первый взгляд SMOL Playbook от HuggingFace, которым мы обязаны почти всем в AI-опенсорсе - это эссе размером в 2️⃣0️⃣0️⃣➕ страниц о том, как обучать большие модели. Но для меня это - изысканный десерт весом в полтонны, которым никак не можешь наесться. Слой за слоем я читал и находил все новые и новые инсайты, многие из которых подтверждали мои предположения и опыт, но бОльшая часть была ошеломляюще новой.
*Например, мне стал понятен успех Kimi, инженеры которой просто внимательнее других отнеслись к оптимизации. *
Все это перемежалось тонким юмором и совершенно неожиданной честностью. А еще там внутри оказалось столько незнакомых терминов, сокращений и отсылок, что я решил: лучший способ разобраться - это перевести.
И вот что я понял...
Обычно истории про большие модели звучат как саги о том, как собрать своего Оптимуса Прайма. Но авторы Smol сходу завляют: а может, вам вообще не нужно обучать собственную модель?💁🏻 И вообще, давайте засучим рукава и посмотрим, как обстоят дела в машинном цехе. А там нас ждут вместо успешного успеха ночные падения серверов, странные всплески лосса и тот самый "незаметный баг в тензорном параллелизме", который портит месяцы работы. Полированный научный PDF обычно заканчивается на "...и тогда наша модель стала новым стандартом". Но этот текст постоянно напоминаем о том, что гигантомания в большим моделях - это зло.
Всякая индустрия любит флаги, но AI-рынок особенно. У всех больших ребят должна быть своя обученная модель, свои бенчмарки, и, желательно, свой xGPT.
Playbook предлагает вместо флага компас
ПОЧЕМУ ▶️ ЧТО ▶️ КАК
... и задает крайне неловкий вопрос
"Зачем вам вообще тренировать модель, когда каждый день появляются Qwen, Gemma, DeepSeek, Llama и ещё десяток имён, которые вчера никто не знал, а сегодня они уже новая надежда и убийца OpenAI"?
И сразу идет абзац, который не могу не процитировать:
"Кто-то (если повезёт) получает доступ к кластеру GPU, возможно, через исследовательский грант или через свободные мощности компании, и ход мыслей примерно такой: «У нас есть 100 H100 на три месяца. Давайте обучим модель!» Размер модели выбирается произвольно, датасет собирается из всего, что доступно. Обучение начинается. И спустя шесть месяцев, исчерпав вычислительный бюджет и моральный дух команды, полученная модель остаётся неиспользованной, потому что никто так и не спросил почему..."
Следом - совершенно неожиданный и лично для меня возвращающий веру в людей поворот: в мире, помешанном на оптимизации, авторы предлагают чаще задавать себе вопросы:
💠 Где проходит граница знания, которую вы хотите сдвинуть?
💠 Что такого в вашей реальности, чего не вытянуть ни промптами, ни тонкой пост-тренировкой на уже существующей модели?
💠 Если вы играете в открытую экосистему - какой конкретный пробел вы собираетесь закрыть?
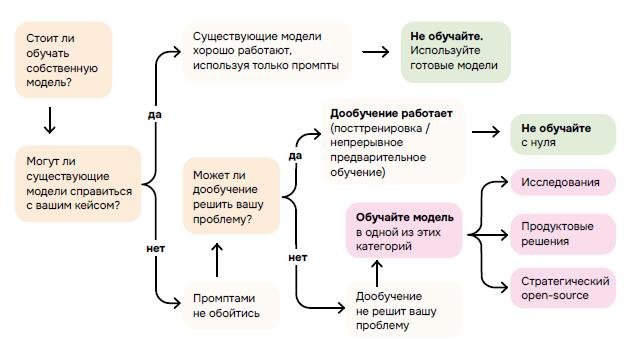
И хотя в книге множество графиков и технических подробностей, ответы на эти вопросы, на мой взгляд, лежат, скорее, в области психотерапии - про нашу способность выдерживать фрустрацию. Потому что это очень стремно - честно сказать: "мне не нужен собственный претрейн" и при этом не чувствовать, что я отстал от всего мира.
Абляции
Что мне еще понравилось - это глава про это неприлично звучащее слово. В то время как в презентациях большие игроки любят говорить о "нашей уникальной архитектуре", авторы начинают с аккуратного 1B-прокси, на котором за 1,5 дня прогоняют по 45B токенов и смотрят, что происходит. А происходит, как правило, что-то странное, например, то, что кажущееся "самое качественное" подмножество данных внезапно ухудшает модель, как в кейсе с arXiv.
Использование всей мудрости цивилизации приводит к тому, что небольшая модель начинает писать тяжёлым академическим языком и при этом теряет хватку в обычном тексте.
Когда я какое-то время назад зарылся в абляция, то был уверен, что это основной механизм подтверждение гипотез. Но у авторов это способ убедиться, что мы не обманываем сами себя. Если на малом масштабе что-то ухудшает обучение, это почти наверняка не спасёт ситуацию на большом. И даже если улучшает - вообще не факт, что не придётся проверять заново.
SMOL, на мой взгляд, задает новую этику инженерной работы: вместо культивации гениальных идей - суровая дисциплина🧙♂️ "не менять всё и сразу" и "не влюбляться в архитектурные фишки, если за них нет стабильных метрик".
Для меня было сюрпризом, что почти все - от Qwen до DeepSeek - живут на одной и той же трансформерной основе, а различия - в аккуратной настройке деталей. В какой-то момент Playbook делает почти кощунственное признание: если вы просто возьмёте хорошую baseline-архитектуру и грамотно обучите её на приличном миксе данных, вы уже будете в "клубе". Никакой магии, только скучная последовательность правильных шагов🧑🏻💻
Неудобная правда
Самая человеческая часть текста - там, где начинается 🏃♂️"марафон обучения". В прологе любого ML-пейпера эта часть обычно скрыта: мы видим только красивые кривые и финальную таблицу. Здесь же нам показывают непривлекательную правду:
- как пропускная способность внезапно падает из-за того, что файловая система решает, какие данные держать "горячими", а какие выгрузить
- как dataloader растит гигантский индекс и роняет производительность просто потому, что никто не думал, что кто-то захочет столько шагов подряд
- как приходится вводить запасной узел в резервацию, чтобы не тратить по 1,5-2 часа на перекачку 24-терабайтного датасета.
В какой-то момент вмешивается ещё один тихий злодей😈 - тензорный параллелизм. Модель, казалось бы, тренируется, лосс падает, оценки растут, но медленнее, чем должны. И только сравнение с 1.7B-версией без TP позволяет заметить, что что-то "едва-едва заметно не так". Оказывается, сиды инициализации были одинаковыми на разных TP-рангах, и это достаточно, чтобы испортить весь праздник.
В этой истории есть важный культурный слой: авторы не экономят на признании собственных ошибок. Это не привычный "мы всё сделали идеально", а "мы наступили на кучу грабель, вот карта мест, где валяются самые болезненные". Такой стиль в технических текстах редок - и именно поэтому ценен. И даже когда часть про претрейн пройдена, можно было бы ожидать что-то про "вот наши метрики, вот наши победы". Но текст разворачивается дальше, в сторону пост-тренинга - туда, где модель перестаёт быть просто предсказателем следующего токена и становится чем-то, напоминающим ассистента.
Авторы честно признают: почти любой пайплайн начинается с SFT - скучной, дешёвой и надёжной супервизии. Никакого романтизма RLHF, никакой магии GRPO, пока модель не научилась хотя бы просто внятно разговаривать. Дальше - слой за слоем: предпочтения, DPO и его многочисленные родственники, осторожные эксперименты с RL. И снова - не как "мы придумали идеальный рецепт", а как "вот что у нас сработало, вот где мы переобучились, вот где модель начала "хакать" награду, вместо того чтобы решать задачи".

Интересно, что здесь снова всплывает базовый мотив Компаса из первой части: прежде чем думать, как вы будете делать RL, спросите себя, зачем он вам. Нужен ли вам вообще RL, если у вас нет ни проверяемых версий задач, ни устойчивой reward-модели, ни команды, готовой неделями возиться с нестабильностью обучения?
Финал
Если попробовать в одном предложении описать дух Smol Training Playbook, он звучал бы так: "меньше показной храбрости, больше профессиональной скромности". Вместо "мы героически выдержали месяц обучения" - "мы три раза перезапускали прогон, потому что сами напортачили, и вот что мы из этого поняли" - и все в таком духе. В каком-то смысле этот текст - не только руководство по построению LLM, но и манифест взросления индустрии. Мир, в котором стало нормально не тренировать свою модель, если она не нужна. Как 70 лет назад, на заре компьютерной индустрии, когда инженерная честность важнее пресс-релиза. Где каждую новую архитектурную фишку сначала пропускают через маленькую, скучную абляцию, прежде чем выделить под неё сотни H100.
И, возможно, самая здоровая версия будущего ИИ не там, где каждая компания стремится к своему монолитному мозгу, а там, где великое ремесло - построить работающую, аккуратную, честную систему из уже существующих кирпичей. А собственную модель всё-таки тренировать. Но только тогда, когда после всех неприятных вопросов к себе и к миру Компас всё ещё указывает в ту же сторону.
Поскольку оригинальный вебный текст дичайше тормозит из-за своего объема даже на моем игровом ноуте, я сделал не лонгрид, а PDF.
Полный материал на русском можно скачать по ссылке https://t.me/aivkube/573
Отдельная благодарность:
💗Transmonkey.ai за черновой перевод (без него я бы ковырялся пару месяцев)
💙Маше Кондратьевой за дизайн и верстку (а еще она делает бесподобные деревянные игрушки - посмотрите в ее инстаграме (https://www.instagram.com/reflection.of.sun))
💚Мое любимой жене Наташе за безграничное терпение и поддержку во время бессонных ночей
в первой ссылке двоеточие пропущено после https