

Думаю, многие разработчики, которые используют Docker, согласятся с тем, что он предоставляет обширные возможности для контроля прав контейнеров. Тут есть инструменты на любой вкус: хочешь открывай порты наружу, хочешь меняй права контейнера через cap_add / cap_drop, хочешь показывай контейнеру все процессы, а хочешь - можешь разрешить использовать девайсы или сеть хоста, ну и так далее.
Погружение в проблему
Однако, работая с Docker вот уже более 7 лет, я заметил, что я часто сталкиваюсь с одним и тем же типом задач, которые обобщённо можно описать так:
Есть контейнер, к которому нужно применить какие-то сетевые правила. Но сделать это нужно автоматически и так, чтобы после перезапуска они сохранялись.
Для понимания, я приведу более точные примеры:
- Контейнер не должен ходить наружу никуда, кроме example.com
- Контейнеры "A" и "B" находятся в одной сети и нужно ограничить доступ из "B" в "A" (а я напоминаю, что в обычных условиях если оба контейнера в одной сети, то каждый из них может отправить запрос на любой порт другого).
Кажется, что это достаточно нишевая проблема, однако это только на первый взгляд. Приведу пример, когда отсутствие контроля понижает безопасность.
Рассмотрим docker-compose.yaml обычного небольшого проекта:
name: project
services:
nginx:
image: nginx:latest
ports:
- 80:80
- 443:443
volumes:
- ./certs:/certs
- ./nginx.conf:/etc/nginx/nginx.conf
depends_on:
- app
app:
image: project/app:latest
environment:
MONGODB_URL: mongodb://db:27017/project
depends_on:
- db
db:
image: mongodb/mongodb-community-server:latest
volumes:
- ./data:/data/db
Вроде всё отлично: контейнер с приложением не торчит наружу, а весь трафик принимается nginx'ом. Но это на первый взгляд. На самом деле здесь есть одна серьезная проблема: поскольку все контейнеры находятся в невидимой default-сети проекта, nginx имеет доступ ко всем контейнерам. Любой кривой плагин, новая zero-day уязвимость (привет log4j) или неправильная конфигурация, и потенциальный злоумышленник может заразить контейнер с nginx, а следовательно делать от его имени запросы в db минуя app.
Да, конечно, ситуация специально гиперболизирована, но исключительно для того, чтобы вы поняли суть: нельзя надеяться на изоляцию контейнера только потому, что он имеет секции ports в настройках. На месте базы может оказаться любой внутренний сервис, который не должен быть публичным, а на месте nginx - любой сервис, который принимает пользовательский трафик.
Многие возразят: «Проблема решается стандартными средствами! Достаточно разбить дефолтную сеть на две кастомные (например, dmz и internal), и nginx просто не увидит базу». Да, для изоляции контейнеров друг от друга внутри хоста это работает. Но что, если требования сложнее? Что, если у нас несколько контейнеров и одному нужно запретить ходить куда-либо кроме X, второму только в X и Y, и так далее - нам для каждого ограничения сеть создавать? Игры с сетями Docker здесь уже не помогут, и обычно в дело вступают костыли с iptables на самом хосте, которые ломаются при каждом перезапуске контейнеров.
Немного о Docker
Чтобы найти решение для данной ситуации, нужно немного прогрузиться в то, как работает Docker. Думаю, я не удивлю вас, если скажу, что есть огромная разница между контейнером и виртуальной машиной.
Виртуальная машина — это полноценная эмуляция железа, поверх которой крутится гостевая ОС со своим ядром. Гипервизор жестко нарезает ресурсы хоста, и всё это добро получается довольно тяжеловесным, долго грузится и потребляет приличное количество памяти просто на поддержание самой ОС.
Контейнер — это обычный процесс (или группа) в вашей хостовой операционной системе. Ровно такой же процесс, как запущенный вами браузер.
Но почему тогда внутри контейнера мы видим отдельную файловую систему, свои сетевые интерфейсы и думаем, что наше приложение запущено с pid = 1? Потому что ядро Linux виртуозно обманывает этот процесс. Для этого используются два главных механизма ядра: cgroups и namespaces.
cgroups ограничивают то, сколько ресурсов процесс может использовать. Они нам не интересны в контексте данной статьи.
namespaces (пространства имен) ограничивают то, что процесс может видеть. Ядро возводит вокруг процесса невидимые информационные стены:
- pid namespace — изолирует список процессов
- mount namespace — подменяет файловую систему
- network namespace — выдает процессу собственный изолированный сетевой стек Ну и так далее
Нас же интересует конкретно network namespace (он же netns).
Network namespace
Когда Docker запускает контейнер, он создает для него тот самый netns - полностью изолированный сетевой мир.
Это происходит, если не передан параметр
network_mode: host. В последнем случае контейнер получает netns самого хоста и видит всю сетевую конфигурацию так же, как если бы был запущен вне контейнера.
Внутри этого мира есть свои сетевые интерфейсы (тот самый eth0, который вы видите, сделав ifconfig внутри контейнера), своя таблица маршрутизации и самое главное - свой собственный, абсолютно независимый набор правил межсетевого экрана.
Обычно, когда разработчики пытаются ограничить сеть контейнерам, они идут настраивать iptables в хостовой системе. Но сам Docker постоянно вмешивается в хостовые правила, пересоздавая цепочки для организации NAT и проброса портов. Начинается бесконечная война ваших скриптов с демоном Docker, и всё ломается при каждом чихе.
Но зная про netns, мы можем поступить умнее: нам совершенно не нужно трогать правила на хосте! Нам нужен инструмент, который будет «заходить» прямо в сетевое пространство имен нужного контейнера и настраивать правила.
Заметьте, здесь упоминается именно заход в netns. Нам НЕ нужно заходить в сам контейнер (через exec / attach) для редактирования его netns. Данный способ будет работать с любым контейнером, независимо есть ли у него внутри iptables или какой-то определенный shell.
И раз такого готового инструмента я не нашел — давайте напишем его сами. Хоть я не Golang Engineer, но я буду использовать именно его, поскольку на нем есть официальная библиотека для работы с Docker и он достаточно низкоуровневый, чтобы мы могли работать с netns напрямую.
Проектируем инструмент
Идея нашей программы (назовем ее Firewall Operator) достаточно проста:
- Мы подключаемся к сокету Docker
- Раз в N секунд опрашиваем список запущенных контейнеров.
- Ищем те, у которых есть специальный маркер (мы будем использовать Docker-лейблы).
- Заходим в netns этого контейнера и применяем нужные сетевые правила.
Почему я планирую именно опрашивать раз в N-секунд, а не использовать событие создания контейнера как триггер? Всё просто: кто-то прям горит желанием руками настраивать ip адреса контейнеров? Я вот нет. Поэтому логичнее сделать dns-резолвинг с помощью внутреннего dns-сервера. Но проблема в том, что при пересоздании контейнеров их ip могут меняться и app и получается ситуация, в которой мы, например:
- настроили правила контейнеру A для походов в контейнер B
- контейнер B пересоздался (например обновили версию продукта)
- в netns контейнера A правила указаны для старого IP контейнера B
- контейнер A теряет доступ до контейнера B
Использование лейблов - это очень удобный паттерн, который отлично отражает философию Infrastructure as a Code. Разработчику приложения не нужно знать, как работает наш оператор, ему достаточно описать хотелки прямо в docker-compose.yaml:
services:
app:
image: project/app:latest
labels:
- "firewall.enabled=true"
# Открываем наружу только порт 8080
# Любой пакет, который придет не на 8080 порт
# будет отброшен независимо от других правил
- "firewall.ports=8080"
# Блокируем весь исходящий трафик, кроме белого списка
- "firewall.in.mode=whitelist"
# Разрешаем запросы только от контейнера nginx
- "firewall.in.services=nginx"
# Блокируем весь исходящий трафик, кроме белого списка
- "firewall.out.mode=whitelist"
# Разрешаем сходить до ip 87.240.128.0 (например, у нас там API какой-то)
- "firewall.out.source=87.240.128.0"
# Разрешаем ходить в контейнер db
- "firewall.out.services=db"
Полный список лейблов, которые мы реализуем:
- firewall.enabled=<true | false> - указывает оператору, нужно ли применять правила из лейблов или нет
- firewall.ports=1000,2000,3000 - порты, на которые могут приходить запросы к контейнеру. Они будут стоять самым первым фильтром отсекать нерелевантный трафик.
- firewall.in.mode=<whitelist | blacklist> - режим фильтрации входящего трафика. Whitelist будет пропускать только то, что указано в лейблах firewall.in.*, а blacklist - наоборот
- firewall.in.source=1.1.1.1,2.2.2.2,3.3.3.3 - список ip адресов для фильтрации входящего трафика
- firewall.in.services=serviceA,serviceB,serviceC - список docker-сервисов для фильтрации входящего трафика
- firewall.out.mode=<whitelist | blacklist> - режим фильтрации исходящего трафика. Whitelist будет пропускать только то, что указано в лейблах firewall.out.*, а blacklist - наоборот
- firewall.out.source=1.1.1.1,2.2.2.2,3.3.3.3 - список ip адресов для фильтрации исходящего трафика
- firewall.out.services=serviceA,serviceB,serviceC - список docker-сервисов для фильтрации исходящего трафика
Также, важно упомянуть, что в фильтрах есть 2 важных исключения, которые напрямую влияют на работоспособность контейнеров:
- интерфейс
loopback- запросы на него должны быть всегда разрешены, поскольку это запросы внутри контейнера на localhost / 127.0.0.1, которые иногда нужны контейнеру - адрес
127.0.0.11- это внутренний dns докера. Если запретить запросы к нему, то при попытке подключения к базе по хостнеймуdbвыдаст ошибку name not resolved.
Теперь, когда мы определились, как это будет выглядеть, самое время сделать так, чтобы оно работало.
Пишем на Go
Первое, что приходит в голову при написании периодических задач в Go — использовать time.Ticker. Но тут кроется ловушка: если мы будем запускать обработку каждого контейнера в отдельной горутине, а сеть или Docker Engine вдруг затупят (например, при резолве dns), горутины начнут выполняться дольше интервала тикера. Они будут бесконтрольно копиться, что в итоге приведет к утечке памяти (OOM) и падению нашего оператора.
Поэтому мы сделаем надежнее: будем использовать бесконечный цикл с блокировкой по таймеру time.After и ждать завершения всех задач текущего цикла через sync.WaitGroup.
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
cli, _ := client.NewClientWithOpts(client.FromEnv, client.WithAPIVersionNegotiation())
// Гарантируем, что новый цикл reconcile не начнется до завершения старого
for {
reconcile(ctx, cli)
select {
case <-time.After(3 * time.Second):
// Пауза перед следующей итерацией
case <-ctx.Done():
return
}
}
}
func reconcile(ctx context.Context, cli *client.Client) {
containers, _ := cli.ContainerList(ctx, container.ListOptions{})
var wg sync.WaitGroup
for _, c := range containers {
wg.Add(1)
// Явно передаем c.ID, чтобы избежать проблем с замыканием переменных
go func(containerID string) {
defer wg.Done()
processContainer(ctx, cli, containerID)
}(c.ID)
}
// Строго ждем завершения обработки всех контейнеров
wg.Wait()
}
Теперь самое интересное. Нам нужно зайти в netns конкретного контейнера. Для работы с netns мы возьмем библиотеку github.com/vishvananda/netns.
Алгоритм простой:
- Получаем pid главного процесса контейнера через ContainerInspect на хосте
- Узнаем по этому pid какой netns используется процессом
- Делаем системный вызов для переключения netns процесса самого оператора, чтобы команды выполнялись под нужным нам netns
- Применяем правила
- Переключаемся на прежний netns
Но в Go здесь есть огромный подводный камень.
Go под капотом планирует тысячи горутин на небольшое количество потоков операционной системы. Когда мы делаем сисколл для смены netns, пространство имен меняется не для горутины, а для текущего потока ОС! Если мы просто переключим netns, сделаем свои дела и горутина уснет, планировщик Go может посадить на этот же поток ОС совершенно другую горутину. И она внезапно окажется запертой в изолированной сети чужого контейнера. Это катастрофа.
Чтобы этого избежать, мы обязаны намертво «прибить» нашу горутину к текущему потоку с помощью runtime.LockOSThread(). Но и тут есть нюанс:
func safeApplyFirewallState(ctx context.Context, pid int, cfg *FWConfig, containerName string) error {
errCh := make(chan error, 1)
go func() {
// 1. Блокируем горутину на текущем потоке ОС
runtime.LockOSThread()
// ВАЖНО: Мы не делаем `defer runtime.UnlockOSThread()` слепо!
hostNs, _ := netns.Get()
defer hostNs.Close()
// 2. Ищем по pid главного процесса в контейнере его netns
targetNs, _ := netns.GetFromPid(pid)
defer targetNs.Close()
// 3. Прыгаем в netns контейнера
if err := netns.Set(targetNs); err != nil {
errCh <- err
return
}
// 4. Настраиваем nftables
workErr := applyFirewallState(ctx, cfg, containerName)
// 5. Пытаемся вернуться в netns хоста
if restoreErr := netns.Set(hostNs); restoreErr != nil {
// КРИТИЧЕСКАЯ СИТУАЦИЯ: Мы не смогли вернуть поток в домашнюю сеть.
// Поток "отравлен". Мы НЕ вызываем UnlockOSThread.
// Горутина завершится, и рантайм Go просто убьет этот сломанный поток ОС.
log.Printf("Failed to restore host netns: %v", restoreErr)
} else {
// Всё отлично, возвращаем чистый поток в общий пул
runtime.UnlockOSThread()
}
errCh <- workErr
}()
return <-errCh
}
Обратите внимание на блок возврата (шаг 5). Если мы по какой-то причине не смогли вернуться в netns хоста, мы НЕ вызываем UnlockOSThread(). В этом случае рантайм Go поймет, что горутина умерла вместе с залоченным потоком, и просто уничтожит этот поток ОС, создав новый. Это единственный безопасный паттерн для работы с неймспейсами в Go.
Применение правил
Итак, мы оказались внутри сетевого пространства контейнера. Чем будем писать правила?
Первая мысль - вызывать старый добрый iptables через exec.Command. Но это медленно, некрасиво, да и парсить его вывод - то еще удовольствие.
Поэтому мы берем nftables - современную подсистему ядра, пришедшую на смену iptables. В Go как раз есть отличная библиотека github.com/google/nftables от Google, которая общается с ядром напрямую через бинарный протокол netlink. Никаких вызовов сторонних программ, синтаксического мусора и зависимости от утилит — всё работает на уровне системных вызовов прямо из нашего процесса.
Но тут возникает проблема производительности. Наш оператор опрашивает контейнеры каждые 3 секунды. Если при каждом цикле мы будем пересоздавать десятки правил заново, мы, во-первых, создадим приличную нагрузку на CPU, а во-вторых, в миллисекунды между удалением и созданием правил контейнер может потерять легитимный трафик.
Здесь нам на помощь приходит киллер-фича nftables — sets (Множества).
Вместо того чтобы плодить цепочку правил вида:
- разрешить IP 1.1.1.1
- разрешить IP 2.2.2.2 ...
Мы создаем одно статичное правило: разрешить пакет, если IP-адрес источника находится в множестве in_ips. А дальше, в нашем цикле синхронизации, мы просто берем текущее состояние множества из ядра, сравниваем его с желаемым (которое мы распарсили из лейблов) и отправляем точечные команды на добавление или удаление конкретных IP-адресов. Это работает молниеносно и без потери трафика.
Более того, такой подход позволит правилам сохранятся при перезапуске самого firewall operator, а при новом запуске он просто посчитает дельту к нужным сетам и применит её, если необходимо. Опять же - без потери трафика.
Чтобы вы понимали, насколько круто выглядит сборка правил через netlink, вот фрагмент добавления правила для проверки IP по нашему множеству:
nfConn.AddRule(&nftables.Rule{
Table: fwTable,
Chain: inChain,
Exprs: []expr.Any{
// 1. Извлекаем IP источника из сетевого заголовка пакета (смещение 12 байт для IPv4)
&expr.Payload{DestRegister: 1, Base: expr.PayloadBaseNetworkHeader, Offset: 12, Len: 4},
// 2. Ищем этот IP в нашем множестве in_ips
&expr.Lookup{SourceRegister: 1, SetName: inSet.Name, SetID: inSet.ID},
// 3. Если нашли (verdict) - принимаем пакет
&expr.Verdict{Kind: expr.VerdictAccept},
},
})
Резолвинг сервисов
Остался последний, но очень важный пазл. В лейблах мы разрешили указывать имена сервисов, например: firewall.out.services=db. Но nftables не умеют напрямую работать с хостнеймами, они оперируют только IP-адресами. Это значит, что нам нужно превратить строку db в конкретный IP-адрес 1.2.3.4.
Если мы попытаемся сделать стандартный net.LookupIP("db"), запрос пойдет через DNS-настройки хоста (какой-нибудь 8.8.8.8 или локальный systemd-resolved) и, разумеется, вернет ошибку. Имя db существует только в виртуальных сетях Docker.
Резолвить имена сервисов нужно через внутренний DNS-сервер самого Docker, который доступен внутри каждого контейнера по адресу 127.0.0.11:53. Причем делать это нужно находясь в netns настраиваемого контейнера, иначе маршрут до этого IP не построится!
Напишем для этого небольшой кастомный резолвер:
func resolveServicesInNetns(ctx context.Context, services []string) []net.IP {
var resolved []net.IP
if len(services) == 0 {
return resolved
}
resolver := &net.Resolver{
PreferGo: true,
Dial: func(dialCtx context.Context, network, address string) (net.Conn, error) {
d := net.Dialer{Timeout: 2 * time.Second}
// Жестко направляем запрос во внутренний сервер DNS Docker
return d.DialContext(dialCtx, "udp", "127.0.0.11:53")
},
}
for _, svc := range services {
// Пытаемся срезолвить имя сервиса (стандартный docker-compose)
if ips, err := resolver.LookupIP(ctx, "ip4", svc); err == nil {
resolved = append(resolved, ips...)
}
// Для поддержки сервисов Docker Swarm (там внутренние адреса сервисов имеют префикс tasks)
if ips, err := resolver.LookupIP(ctx, "ip4", "tasks."+svc); err == nil {
resolved = append(resolved, ips...)
}
}
return resolved
}
Этот кусок кода элегантно собирает IP-адреса всех зависимых сервисов, которые мы затем складываем в наши сеты в nftables. Если IP контейнера db изменится при рестарте, наш оператор в течение 3 секунд срезолвит новый IP, вычислит diff для сета и обновит правила в ядре без пересборки всех указанных правил.
Почему это работает?
Внимательный читатель на этом моменте наверняка задаст резонный вопрос: «Окей, мы настроили nftables прямо внутри netns контейнера. А что если злоумышленник найдет уязвимость в нашем приложении (например, RCE), получит root-права внутри контейнера и просто выполнит nft flush ruleset или iptables -F? Вся наша хитрая защита мгновенно превратится в тыкву?»
Ответ: Нет, не превратится. И здесь нас спасает базовая архитектура безопасности Docker и ядра Linux.
Дело в том, что наличие прав root (пользователь с uid 0) внутри контейнера совершенно не означает полного контроля над ресурсами ядра. За разделение привилегий в Linux отвечают Capabilities.
Чтобы процесс мог хоть как-то изменять сетевые настройки — поднимать интерфейсы, менять таблицу маршрутизации или управлять правилами межсетевого экрана (неважно, iptables это или nftables) — ему требуется совершенно конкретная привилегия: CAP_NET_ADMIN.
По умолчанию Docker сбрасывает все привилегии при запуске любого контейнера, если их не указать явно через
cap_add.
Поэтому, даже если злоумышленник получит полный root-доступ внутри скомпрометированного сервиса, любая его попытка вмешаться в работу netns завершится отказом ядра: Operation not permitted. У хакера просто не хватит прав на системные вызовы netlink, управляющие netns.
Разумеется, эта защита гарантированно работает при одном условии: если вы сами, настраивая docker-compose.yaml, по ошибке не выдали уязвимому контейнеру флаг privileged: true или привилегию CAP_NET_ADMIN. Но от выстрела в ногу спастись программно уже невозможно.
Протестируем
Запускать наш Firewall Operator предлагаю тоже как Docker контейнер (хотя он отлично себя почувствует, находясь прямо на хосте).
Но для работы изнутри ему потребуется:
pid: host- чтобы видеть все процессы хоста (подключает нас к pid namespace хоста)CAP_NET_ADMIN и CAP_SYS_ADMIN- чтобы управлять network namespace'ами хостаCAP_SYS_PTRACE- чтобы контролировать другие процессы
Запускать оператор можно следующим образом:
services:
firewall:
image: ghcr.io/hit2hat/docker-firewall:latest
pid: host
cap_add:
- NET_ADMIN
- SYS_ADMIN
- SYS_PTRACE
cap_drop:
- ALL # явно сбросим все остальные привилегии
Теперь попробуем запустить тестовые контейнеры:
services:
test1:
image: nginx:alpine
labels:
- "firewall.enabled=true"
- "firewall.ports=80" # входящие пакеты разрешены только на порт 80
- "firewall.in.enabled=true" # включаем фильтрацию входящего трафика
- "firewall.in.mode=whitelist" # только разрешенные ip
- "firewall.in.services=test2" # только контейнер test2
test2:
image: nginx:alpine
labels:
- "firewall.enabled=true"
- "firewall.out.enabled=true" # включаем фильтрацию исходящего трафика
- "firewall.out.mode=whitelist" # только разрешенные ip
- "firewall.out.services=test1" # только контейнер test1
Запустим и сразу посмотрим в лог firewall operator:

Как мы видим, Firewall operator нашел два контейнера, срезолвил ip из лейблов и применил конфигурацию.
Попробуем постучать из test2 в test1:
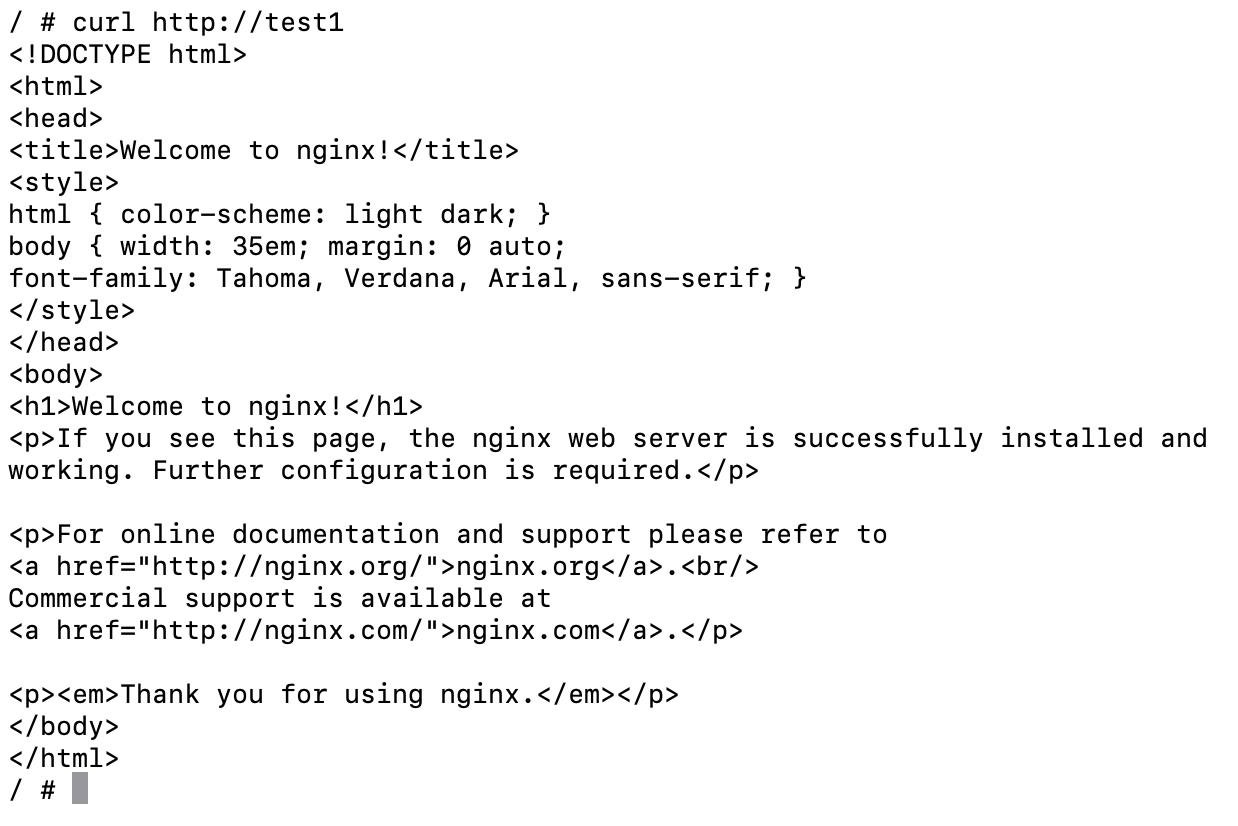
Попробуем постучать из test1 в test2:
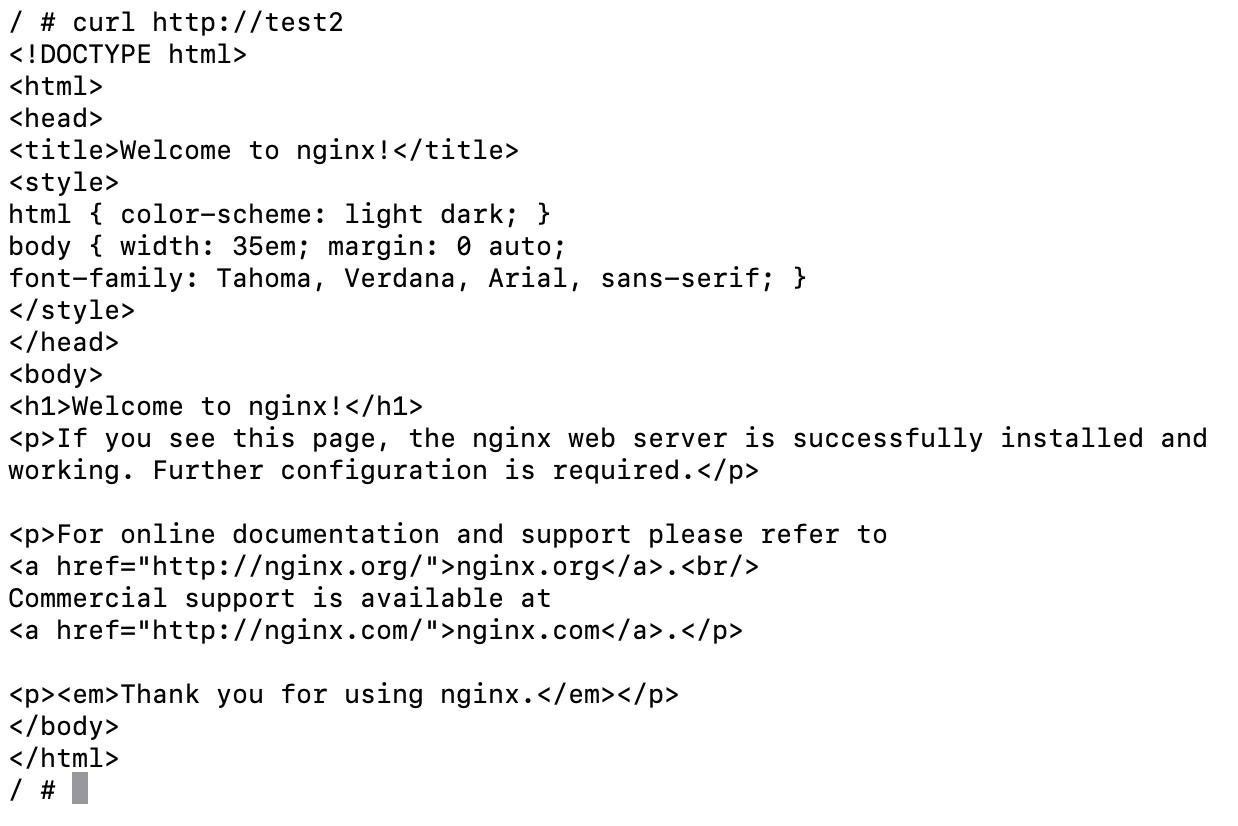
Проверим, что из test2 нельзя никуда больше стучать, кроме как в test1:
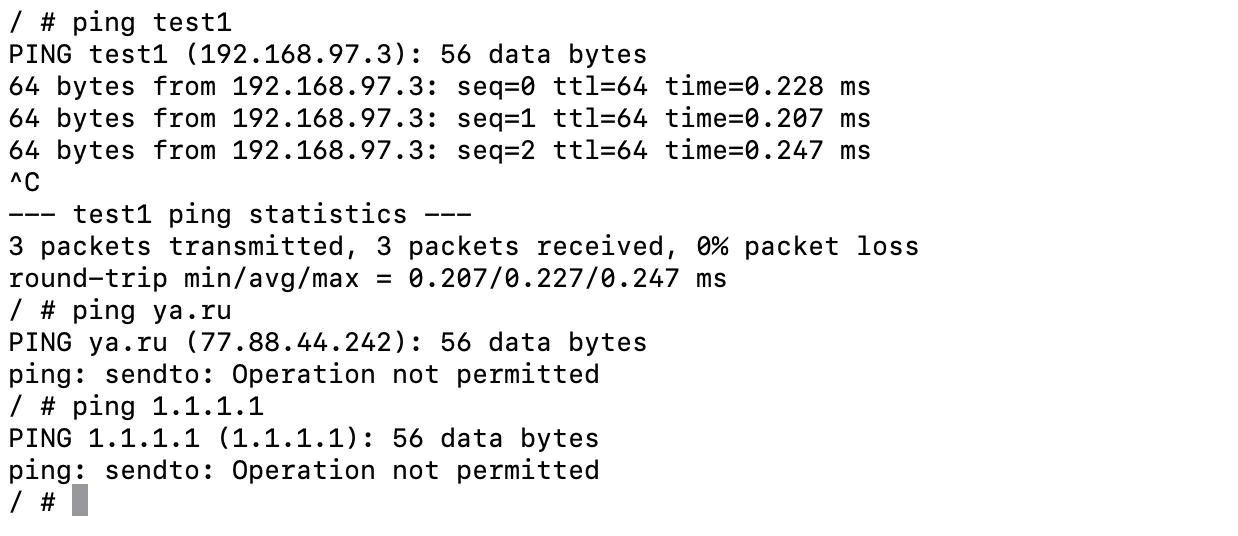
Перезагрузим контейнер test1 и посмотрим что случится:

Что произошло:
- Так как
test1исчез, то мы убираем его в сетеout_ipsуtest2: он тупо не резолвится - Как только появился новый
test1, для него сразу проводится инициализация - Мы также попутно обновляем сет
out_ipsуtest2, так какtest1теперь резолвится, да еще и с другим ip (был x.x.x.3, стал x.x.x.4)
Итог
Вот так мы решили одну из интересных задач в Docker и расширили его функциональность под себя.
Да, безусловно, кому-то мой способ может показаться велосипедом, который к тому же не покрывает 100% задач, связанных с ограничением сетевого доступа, но моя главная цель - показать, что есть такой инструмент как nftables и его можно использовать достаточно нетривиальным способом.
Ссылка на код: https://github.com/hit2hat/docker-firewall
Спасибо за внимание!