
TL;DR
Привет, Олимпийский! Меня зовут Филипп, я работаю дата-шрушером и довольно много преподаю вещи, связанные с DS. Меня от этого качает. При этом у меня экономическое образование.
Когда я заканчивал бакалавриат, хайп вокруг DS (Data Sciense) только набирал обороты. Рынок впервые почувствовал жёсткий дефицит кадров. ФКН ВШЭ ещё не выпустил свой первый поток. Сбербанк только-только начал расчехлять свой кошелёк и нанимать всех, у кого есть нормальная квалификация. А ODS (Open Data Science) был прекрасным садом.
В ВУЗе никакого DS у меня не было. Была хорошая математическая база. Остальное ботал сам. По мотивам своей жизни я тогда написал для студентов младших курсов большой гайд про то "Как стать дата-шрушером?" Что читать, куда смотреть и тп.
Довольно давно хотел обновить этот гайд, потому что в голове накопилось много мыслей по этому поводу. До последнего не очень хотел заливать его в клуб, тк мне казалось, что моя целевая аудитория — студенты.
Недавно прочитал тут историю про вкатку в DS. Тогда Остапа понесло. Я переписал гайд, чтобы он стал более универсальным и теперь показываю его миру.
Почему я называю специалиста по данным дата-шрушером? Попробуйте покопаться в грязных данных, и вы сразу же всё поймёте.

Для кого этот пост
Для меня. Хочу потешить своё ЧСВ. Опять. Этот пост для тех, кто хочет быть дата-шрушером, но не очень понимает, что ему делать. Я попытался накидать схему DS-мира и наметить различные тропинки, ко которым в него можно попасть.
Выбирайте ту тропинку, которая вам лучше подходит. Понятное дело, что все случаи в одном посте описать сложно. Если вам не нравится никакая из тропинок, расскажите нам о своей в комментариях.
Также стоит оговориться, что я пишу этот пост из своего Московского информационного пузыря. Из-за этого в нём может быть некоторое смещение.
Компетентен ли автор
Автор абсолютно некомпетентен. Ни в чём. Но в интернете работает как минимум два закона. Первый из них — Закон Каннингема:
Лучший способ найти правильный ответ в интернете — не задать вопрос, а разместить заведомо неправильный ответ.
Второй из них — Закон Годвина:
По мере разрастания дискуссии, вероятность сравнения, упоминающего нацизм или Гитлера, стремится к единице.
Всё, что я пишу — в корне неверно. Но, я очень жду, что в комментариях вскроется правда. С каким из двух законов будет связана эта правда, пока непонятно.
Часть I: шрушерские координаты
Давайте начнём со следующей мысли: вакансии в DS бывают очень разными. Очень часто под одним и тем же названием скрываются кардинально разные вещи. Сложно понять, что конкретно ты будешь делать, не пообщавшись с работодателем.
Есть места, в которых "аналитик" сидит в экселе. Есть места, в которых "аналитик" пишет продакшн-код. Есть места, в которых "ML-инженер" строит базу данных и следит за ней. Есть места, в которых "ML-инженер" пишет высоконагруженные системы на каком-нибудь низкоуровневом языке с мапами да редьюсами.
Одним словом — разнообразие. В этом разнообразии довольно сложно сориентироваться. Поэтому давайте первым делом попытаемся классифицировать всех дата-шрушеров в двух осях: место, куда я пришёл работать и навыки, которыми я обладаю. Дальше будет легче понять, кем я примерно хочу быть и как мне туда попасть.
1. Дата-шрушер в одной картинке
На самом деле дата шрушер — это Змей Горыныч. Тело этого Горыныча — это анализ данных. Головы змея — это математика, программирование + технические навыки и здравый смысл. Тело не может существовать без голов.

Технические навыки можно выделить в четвёртую голову. Под математикой подразумевается то, насколько глубоко вы можете заботать ML в плане его математической составляющей. Под здравым смыслом подразумевается глубокое понимание продукта, мира, предметной области и вообще.
Ниже мы будем обсуждать каждую из голов по очереди. Сначала я буду описывать зачем эта голова нужна анализу данных и какие компетенции в неё входят. Потом будет список курсов и ссылок. Вкачиваем разные головы с разной силой — получаем разных специалистов. Каждое сочетание востребовано на рынке и имеет право на жизнь.
Если вы вкачиваете все три головы, вы становитесь универсальным чуваком, которому по плечу любые нестандартные задачи. Именно таких ребят стараются готовить Вышкинский ФКН, Сколтех, ШАД и тп.
Например, есть беспилотник. Надо научить его ездить без участия человека. Как? Да хрен его знает. Нанимаем кучу трёхголовых чуваков, и они решают эту инженерную задачу.
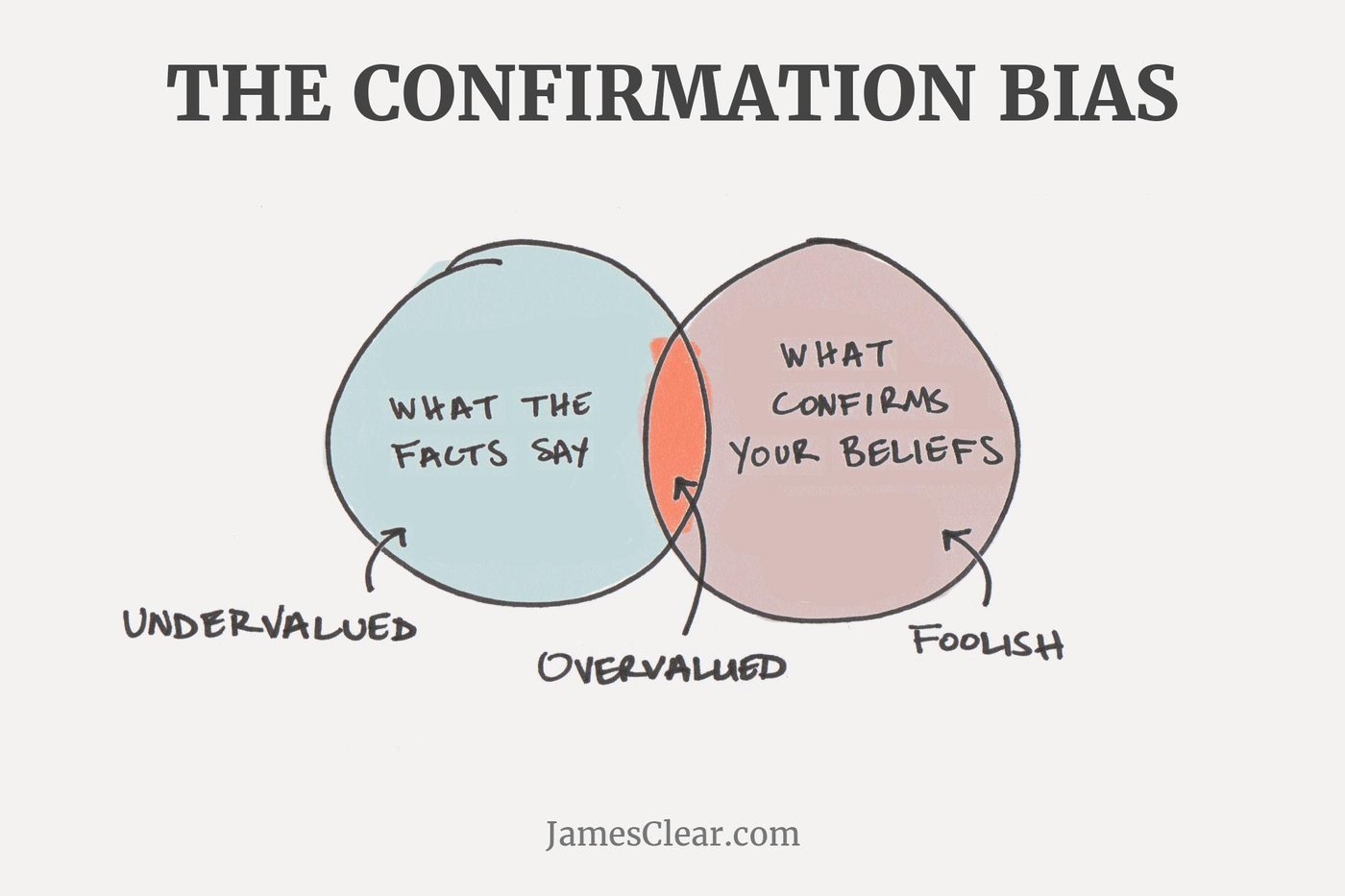
2. Какими бывают компании
То, что вы будете делать на работе зависит не только от ваших навыков, но и ещё от конкретной компании и её задач. Все компании можно разбить на пять типов. Классификация довольно спорная и скорее всего вызовет много вопросиков. Она строится вокруг работы с данными.
Ключевые моменты: наличие хорошей инфраструктуры и ML-алгоритмов, работающих в режиме реального времени. Если они есть, считаем компанию "технологической".
Технологическая компания бережно работает с данными. Для этого есть инфраструктура. На ней выстроен ML (Machine Learning), который работает в режиме реального времени. Обычно у такой компании более-менее единый технологический стек. Из-за этого работать комфортно. ML продукты делаются давно, есть богатый опыт. На бюрократию уходит минимум времени. Многие подобные компании возникли вместе с интернетом и изначально выстраивали все свои процессы вокруг потока данных.
Зрелая компания недавно поняла ценность данных. Она построила основной костяк инфраструктуры для работы с ними. Теперь на её базе выстраиваются регулярные ML-пайплайны. Идёт централизованная борьба с велосипедными решениями. Несколько технологий могут жить рядом и из-за этого всем может быть жутко неудобно. Рано или поздно такие ребята станут "технологическими". Надо только достроить инфраструктуру и накопить ML продуктов.
Дикий запад. Это либо стартап, либо компания, которая поняла ценность данных, но ещё нефига не построила. В ней нет инфраструктуры, многое надо делать с нуля. Внутри происходит полный хаос. ML находится на уровне одноразовых скриптов. Ничего риал-таймового нет. Часто DS параллельно начинают строить несколько отделов. Каждый делает это по-своему, на своём технологическом стеке и своих коробочных решениях. Всё это приходится дружить между собой. Много времени может уходить на борьбу с бессмысленной бюрократией.
Древние компании пока не поняли, что им нужно уметь обрабатывать много данных с помощью ML. При этом в штате у компании есть какие-то аналитики. Чаще всего они всё делают в excel либо какой-нибудь кнопочной системе вроде SPSS. Компания в любой момент может превратиться в "Дикий Запад", а excel-аналитики неожиданно могут превратиться в дата-шрушеров. Компании, которым DS не нужен, мы сюда не относим.
Коробочные компании решили не держать у себя разработку, а покупать для каждой проблемы коробочное решение. У компании есть штат аналитиков, которые поддерживают работу коробок. Если есть новая проблема, для неё находят новое коробочное решение и внедряют.
Иногда компании создают у себя RnD-отделы с полноценными учёными. Они, а также все исследовательские позиции, находятся за рамками этой классификации.
Совмещаем знание о том, какими бывают компаниии с знанием о том, какие навыки нужны дата-шрушеру и получаем политические шрушерские координаты.
3. Что происходит на рынке
У любой технологии есть два этапа существования. Сначала какие-то умные чуваки её изобретают. После начинается её внедрение. Именно так происходило в случае электричества. Несколько учёных сделали открытие, а потом огромное количество инженеров и предпринимателей стали искать способы, чтобы внедрить его в окружающую нас жизнь.
То же самое сейчас происходит с разными "умными" продуктами на основе ML. Несколько учёных уже сделали достаточно, чтобы запустился этап внедрения. Теперь надо где-то откопать армию компетентных дата-шрушеров, чтобы внедрить ML в окружающую нас жизнь. Более того, наука не собирается останавливаться и продолжает каждый год нас радовать чем-нибудь новеньким, что тоже можно куда-нибудь внедрить. Уважаемые учёные говорят, что это только начало.
Открытия есть, армии нет. На рынке труда возникает огромный дефицит. Например, на российском рынке лет 5-6 назад Сбер превратился из Древнего в Дикий Запад и залил весь рынок баблом. Сберовские зарплаты стали мемом. При этом спрос на людей в рамках него всё также не удовлетворён.
При этом компаний, которых интересуют данные, становится всё больше и больше. Подтягиваются телеком, ритейлеры, другие банки. Подтягиваются даже промышленные компании вроде Северстали.
Судя по всему, в ближайшие десять лет этот дефицит никуда не уйдёт. Недавно вышел прогноз про потребности американского рынка труда в десятилетней перспективе. Его можно рассматривать как прокси для мирового рынка.
Главный месседж из него в том, что массовое применение технологий машинного обучения не только уничтожает массу рабочих мест с рутинными задачами, но и создаёт миллионы новых. Чтобы заполнить все эти вакансии не хватит никаких новых выпускников. Нам понадобится очень массовая переподготовка людей в области технических знаний.
Ещё относительно будущего, полезно держать в голове мысль из свежего отчёта Deloitte, MLOps Industrialized AI. Про него недавно писал у себя Кантор:
Отчет Deloitte иллюстрирует одну из популярных идей в современном ML: в будущем вызов будет не в построении моделей, а в их внедрении и масштабировании на весь бизнес. В среднем 28% проектов в Data Science проваливаются на фазе production, 47% даже не выходят из фазы RnD, а внедрение модели в прод часто требует нескольких календарных месяцев.
Инфраструктура для деплоя — это дико важно. Всем будут нужны инструменты для воспроизводимых исследований в ML, выкатки моделей в прод и мониторинга их работы.
Есть расхожее мнение, что 80% времени дата-шрушер тратит на подготовку данных, а оставшиеся 20% на обучение моделей. В случае, если речь идёт про рисёрч, это правда. Когда дело касается прода, 80% времени уходит на продумывание и строительство полноценного воспроизводимого пайплайна. С поставкой данных, краудсорсом, метриками, мониторингами и запусками по крону. Но это лично моё наблюдение, оно не претендует на истину в последней инстанции.
О грандмастерах Kaggle все забывают. О тех, кто пришёл на Дикий Запад и смог выстроить все процессы, слагают легенды.
4. Шрушерские координаты
У нас есть 2 пакета травы, 75 таблеток мескалина дефицит на рынке, шрушерские координаты и какой-то запас ресурсов: свободное время, мозги, деньги. Попробуем выстроить несколько рабочих стратегий по вкатыванию.

Сценарий 1: Таааак, ебать
Есть спрос? Будет и предложение. Многие люди вступают в слак ODS, а потом делают вот так:

Свежий дата-шрушер готов. Можно ли найти так работу? Почти наверное. Например, на Диком Западе. Стоит ли так делать? Зависит от того кто вы.
- Если вы студент — ни в коем случае не смейте так делать. У вас до жопы свободного времени и вы можете досконально всё заботать и напилить кучу проектов для того, чтобы набраться опыта.
- Если вы взрослый, у вас минимум свободного времени и надо зарабатывать где-то деньги, можно попробовать.
Набираете минимум навыков и врываетесь на Дикий Запад. Дальше учитесь в процессе. Дикий Запад может устраивать для своих сотрудников всякие переподготовки. Когда я стажировался в Диком Сбере, я своими глазами видел, как чуваки, которые до этого работали в кнопочной системе, приходят на работу и ботают на ней питон.
Всегда держите в голове, что ваша квалификация очень низка. Не обманывайте себя. Вам нужно успевать за развитием компании и стать зрелым вместе с ней. Самое главное — не остановиться в развитии.
Своему начальнику и коллегам вы можете пытаться показывать, что вы круче, чем есть на самом деле. Главное при этом не лажать. Это нормально. Тут мы говорим про честность с самим собой.
Если вы вдруг почувствуете, что в своей компании вы самый умный, меняйте работу на такую, где вы снова окажетесь самым тупым. Чувствовать себя самым тупым — прекрасно. Всегда есть коллеги, на которых можно ориентироваться и карабкаться вслед за ними, наверх, за квалификацией. Не стесняйтесь быть тупым. Я у себя на работе самый тупой, а мои коллеги очень классные. Это подталкивает к развитию.

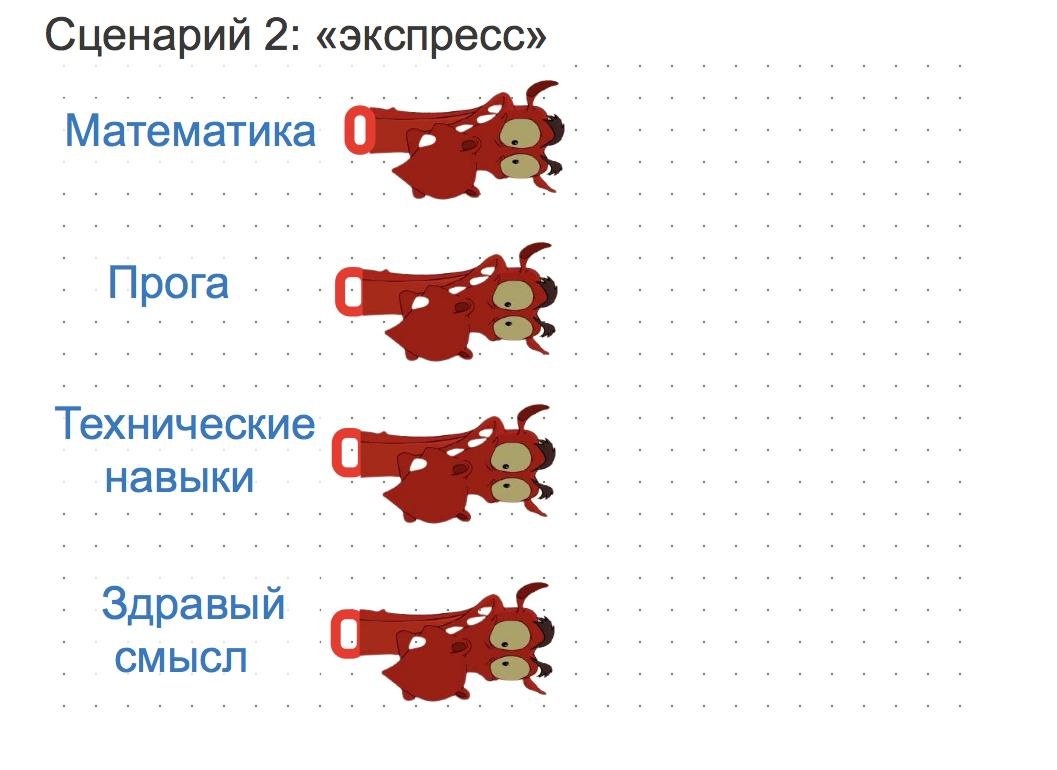
Сценарий 2: экспресс-курс
Этот сценарий более систематичен. От первого он отличается тем, что вы набираете побольше компетенций перед тем, как вломиться в DS-мир. Именно по такому сценарию обычно строятся все курсы переподготовки для взрослых. Обычно сначала рассказывают базовые навыки из математики вроде взятия производных и тервера, а затем анализ данных.
Многие базовые специализации на курсере ровно так и устроены. Проходите какую-нибудь из списка ниже, пилите пару своих проектов, пытаетесь прособеседоваться на позицию джуна.
Ради всего святого, не надо сразу ломиться на платные курсы переподготовки. Но об этом мы поговорим ниже.
Сценарий 3: доскональный aka студенческий
У вас нет денег, зато до жопы свободного времени.
Если вы студент младших курсов, делайте акцент на математике и проге. Не бегите впереди паровоза. До нейронок добежать ещё успеете. У вас есть куча времени, чтобы досконально разобраться в математике. Поверьте на слово, это очень полезно. Пока ботаете, можете смотреть на вступительный в ШАД и тайно грезить о нём.
Если вы со старших курсов и плохо помните математику, замутите себе по ней экспресс-курс. Без доказательств, с пониманием основных концепций и решением задач. Научитесь базовой проге, а дальше погружайтесь в курсы по анализу данных. Все пробелы залатаете по мере их возникновения. Никто не мешает вам после курса по ML откатиться назад и пройти линал.
В зрелую или технологическую компанию получится вкатиться только при доскональных знаниях и опыте. Поэтому попробуйте не только ботать, но и делать какие-нибудь pet-проекты. Заливайте их на github, закидывайте в CV. Профит. Ещё подумайте о поступлении в нормальную магистратуру, связанную с анализом данных.
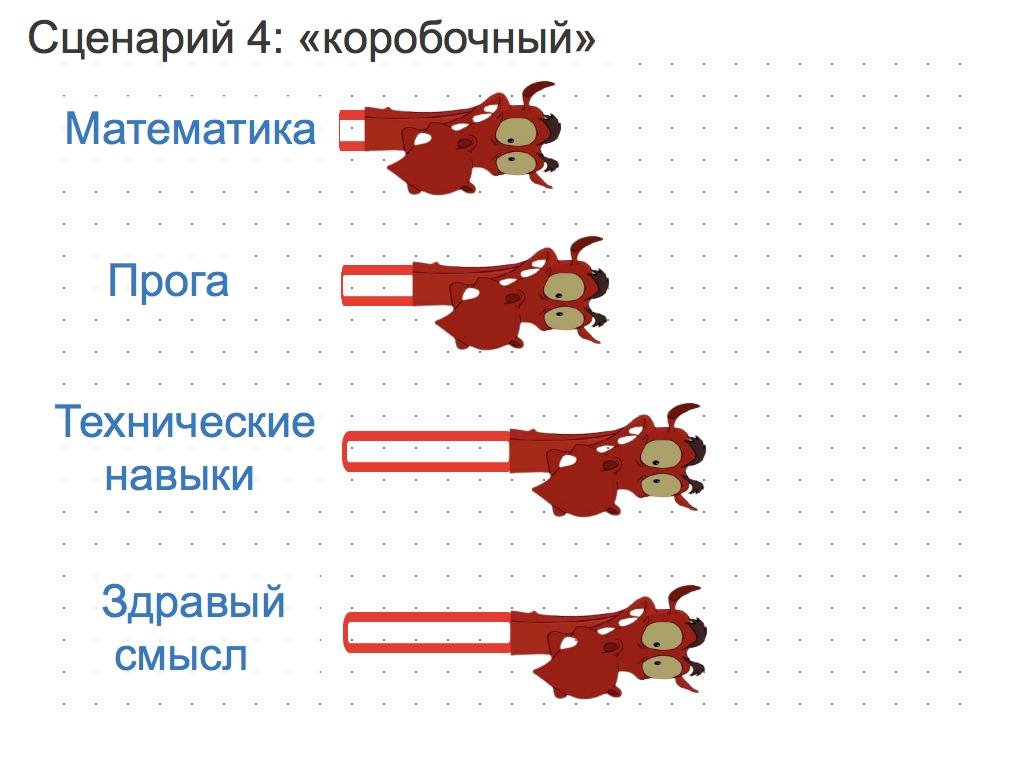
Сценарий 4: коробочный
Берём коробочную компанию. Смотрим какими коробками она пользуется для того, чтобы строить свой бизнес. Ботаем то, как устроены эти кнопочные штуки. Устраиваемся в такую компанию на работу. Мы оказались в мире данных.
Оглядываемся по сторонам, находим задачи, связанные с DS, к которым никто не может подступиться. Забираем себе. Ботаем нужные разделы DS, пытаемся их решить. Растём в навыках, меняем работу на более хард-скиловую. Ну либо становимся главой отдела и начинаем менять коробочный мир, наступая при этом на все возможные грабли.
Под техническими навыками на картинке подразумевается умение быстро разбираться в коробках, дашах, а также SQL.
Сценарий 5: продуктовый аналитик
Обычно такой чувак делает аналитику на уровне продукта. Нужно уметь обсчитывать АБ-тесты, строить дашборды, томно думать о продукте и рожать хорошие метрики.
Вкачиваем матстат. Хорошо разбираемся в проверке гипотез и всяких pvalue. Ботаем базовый SQL. Скорее всего, придётся писать много запросов. ML ботаем по минимуму. Алгоритмы не нужны, на питоне учимся писать одноразовые скрипты. Они могут быть сколь угодно ужасными. Главное, что работают. Дашборды придётся строить в каком-нибудь коробочном софте, на них пока забиваем. Разберёмся на работе.
Пробуем залететь на позицию. Компанию из спектра выбираем в зависимости от того, насколько досконально всё заботали. В технологических компаниях продуктовые аналитики часто находятся ближе к ML-аналитикам.
Здравый смысл на картинке выкручен на максималки, так как хороший продуктовый аналитик должен шарить за продукт и свою предметную область.
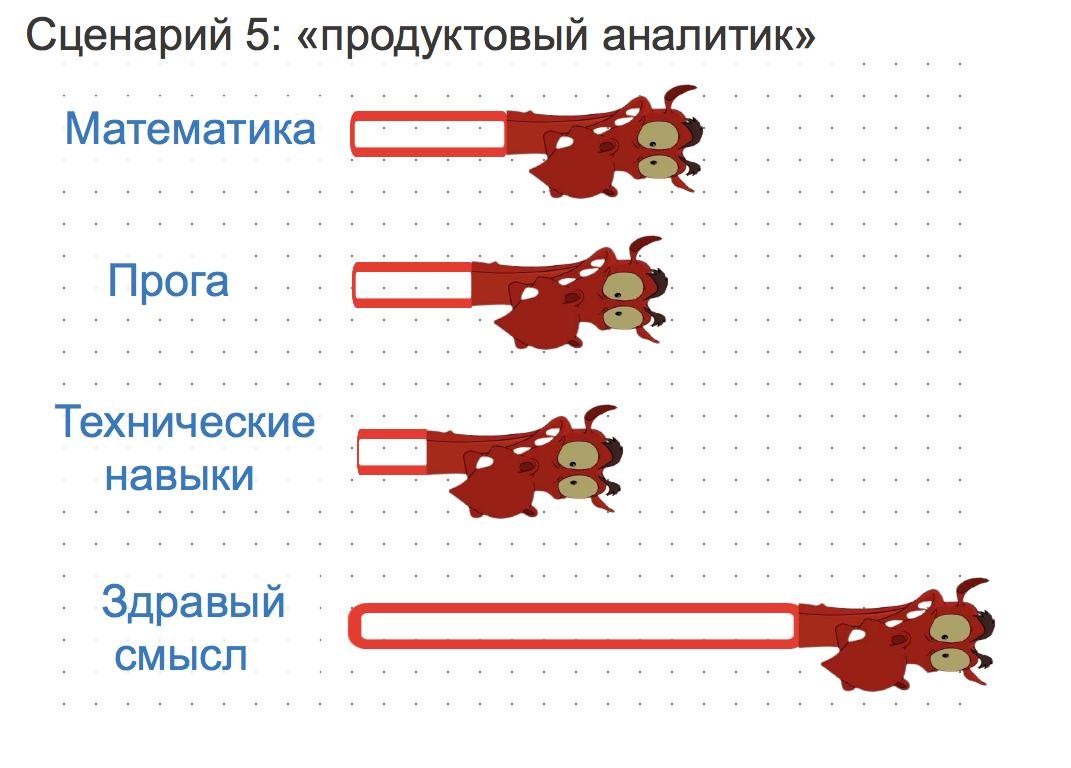
Сценарий 6: ML-аналитик
Нужно уметь хорошо работать с данными, придётся писать тонны одноразовых скриптов для рисёрча. Нужно шарить в ML и уметь переводить на его язык продуктовые задачи.
ML-аналитик обычно учит разные модельки и раскатывает их совместно с разработкой. Из-за того, что ему не хватает скиллов разработчика, зависит от разработки и её ресурсов.
Сильнее прокачиваем вещи, связанные с ML. Меньше качаем вещи, связанные с алгоритмами. Рано или поздно на работе вы почувствуете зависимость от разработки и тогда, скорее всего, начнёте более сильно вкачивать прогу.
Снова компанию из спектра выбираем в зависимости от того, насколько досконально всё заботали.
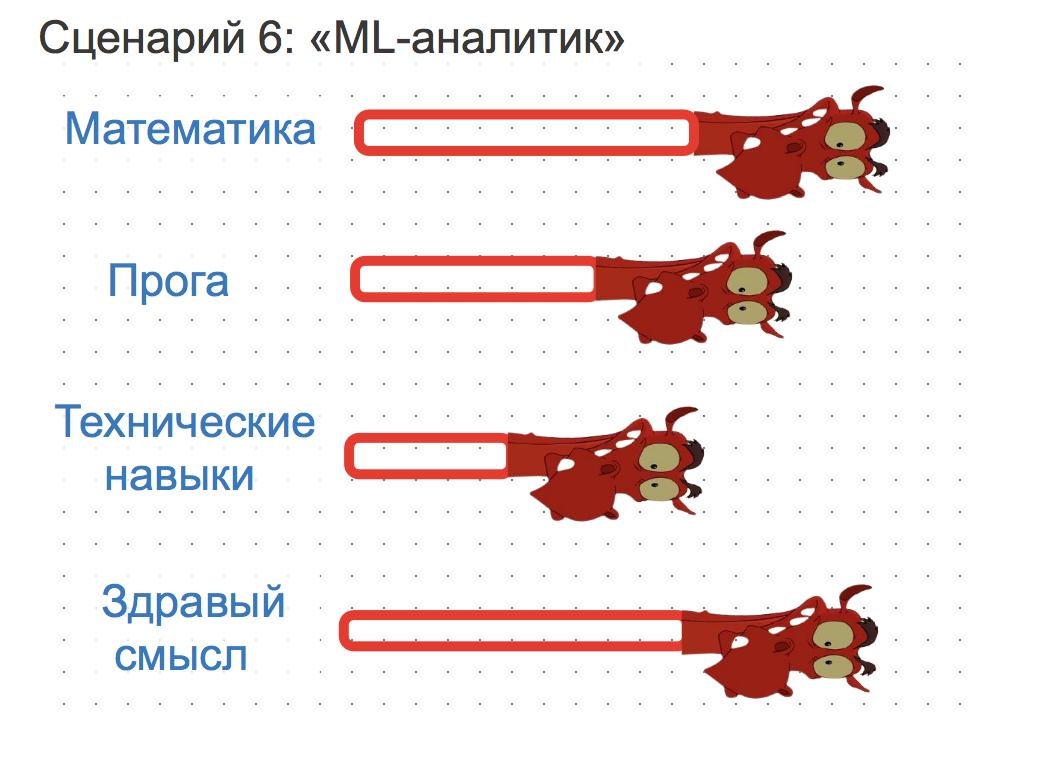
Сценарий 7: ML-разработчик
Этот путь скорее подходит для разработчиков. Разработчик может довольно легко вкатиться в ML через написание инфраструктуры. Ну а дальше ботаем матешу с ML и статистикой на перевес и вкатываемся.
Нужно будет писать много продового кода. Придётся сделать так, чтобы ML-алгоритмы работали внутри высоконагруженных сервисов.
Под здравым смыслом на картиночке подразумевается именно здравый смысл. Знание предметной области тоже нужно, но на мой взгляд не так сильно.
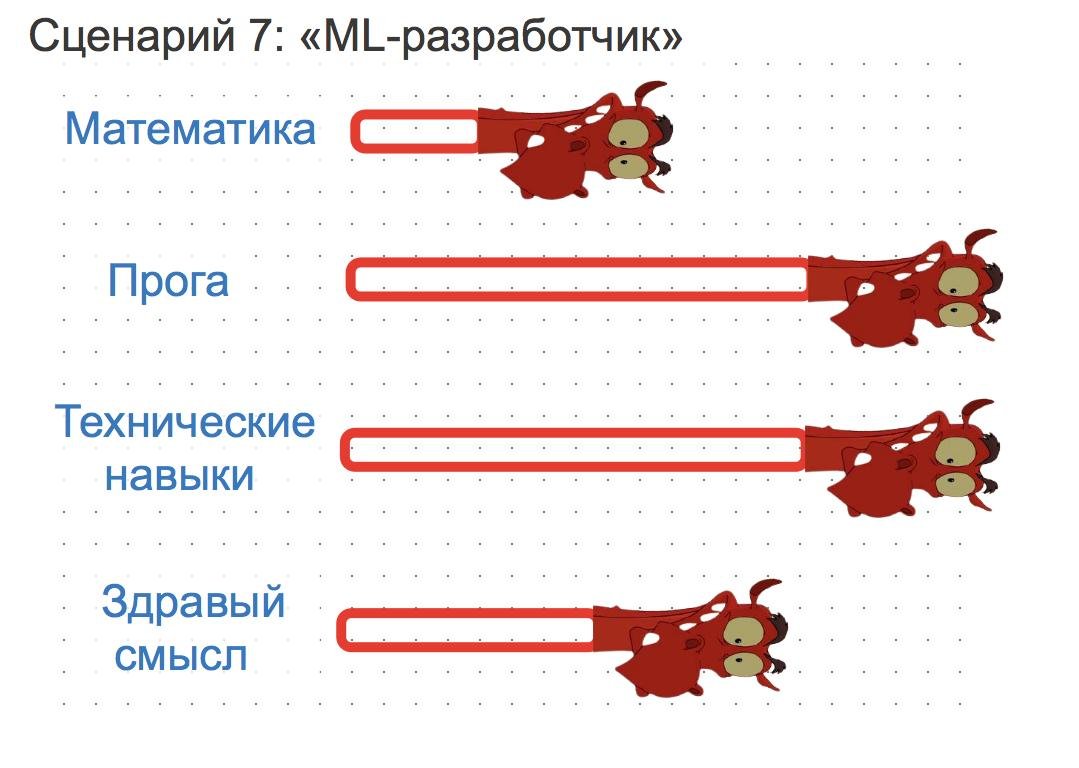
Сценарий 8: Data-инженер
Вам не очень нравится вся эта математика и алгоритмы, но вы обожаете перекладывать json-ы с места на место? Для вас придуман путь дата-инженера.
Придётся собирать и обрабатывать данные, проектировать хранилища и работать с инфраструктурой. Никакого ML, но тоже безумно весело. Под техническими навыками на картинке имеется в виду всё, что связано с выстраиванием нормальной инфраструктуры.
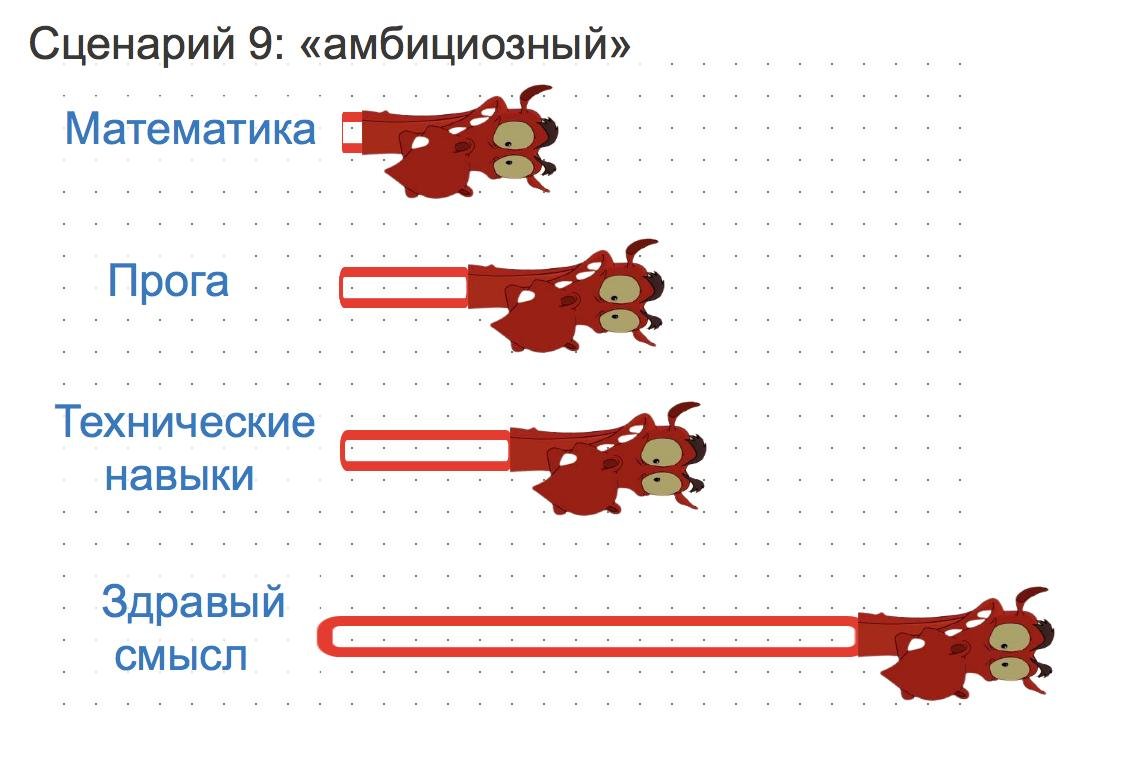
Сценарий 9: амбициозный
Вы работаете аналитиком в компании, которая вошла в стадию Дикого Запада. Поздравляю, у вас есть уникальный шанс выстроить все DS-процессы с нуля. Это довольно амбициозная задача с горизонтом в несколько лет. Чтобы решить её, придётся упороться.
Вам надо быстрее всех других уметь разгребать тонны говна и понимать какие технологии нужны, а какие нет. Глубоко в них разбираться не обязательно. Нужно найти людей, которые будут разбираться глубоко, и построить команду.
Чем выше ваша "сеньорность", тем больше должна быть ваша ответственность. Нужно понимать насколько какая штука полезна для бизнеса. Нужно уметь общаться с заказчиками, выслушивать их проблему, предлагать варианты решений без математики, а дальше переводить это всё на язык команды.
Довольно часто продвинутые DS-специалисты уходят на Дикий Запад из технологических компаний, чтобы строить новое с нуля.
Понятное дело, что с плохой квалификацией вы не сможете возглавить этот процесс, но вы вполне можете возглавить какой-то отдельный кусок трансформации, в котором вы лучше всего шарите. Короче, будет драйвово.
Сценарий N
Я уверен, что в коментах вы сможете придумать ещё десяток интересных сценариев.
Ещё раз, ещё раз. Вкачиваем разные головы дракона — получаем разных специалистов. Самое важное — понять чем конкретно вы хотите заниматься, к чему у вас есть склонность, а дальше уже отращивать головы. Чтобы понять, насколько ты вкачан, можно попытаться посмотреть на конкретные навыки, которые требуются на каждом из уровней.
Ещё тут стоит сказать, что если вы хотите успешно проходить собеседования, на них нужно ходить. Никогда не рано попробовать. Это скорректирует ваш курс и поможет немного перестроить образование под недостающие навыки.
Когда кинул паре своих DS-друзей статейку на ревью, они мне прислали выступление Алексея Натёкина на похожую тематику. У него тоже есть похожие картиночки, но не с головами, а треугольниками.
Часть II: драконьи головы
Как было сказано выше, у анализа данных три головы. Ни в коем случае не стройте программу своего развития как: сначала я выучу всю возможную математику, потом научусь прогать, а потом уже нейронки ботать буду. Вам нужно набрать из каждого пласта минимальное количество навыков, а дальше развивать все головы параллельно. Иначе вы застопоритесь.
Однопоточность — зло. Распараллеливание — благо.
Конечно же, заботать математику и прогу — это не самое простое занятие. Нужно будет пробить языковой барьер. Для этого надо нарешать много задач. Если вы это сделаете, вы выйдете в своём понимании на новый уровень. Ещё иногда информация доходит до мозга с лагом. Когда я после гуманитарной школы начал учить матан, я понял материал первого семестра только во втором семестре.
Иногда идёшь по лестнице за вкусняшкой и неожиданно к тебе приходит понимание чего-нибудь, что ты ботал пару месяцев назад, но недопонял до конца. Обожаю такие флешбеки.
Ещё тут стоит сказать, что бывают люди, которые хотят подготовиться вообще ко всему. Например, когда они видят в описании вакансии SQL, они думают, что значит его надо заботать до дыр. Ничего подобного. Если говорить о штуках вроде SQL, обычно достаточно базовых навыков. Всё необходимое ты навёрстываешь в ходе работы (конечно же, если ты не Data-SQL-инженер).
Подготовка ко всему — очень опасное занятие из-за того, что оно не заканчивается никогда. Если вам кажется, что у вас в голове есть костяк из необходимых знаний, попробуйте прособеседоваться. Даже если вы провалитесь, после общения с HR, вы будете понимать, какие навыки надо подтянуть. Поверьте, обычно это не синтаксис SQL.
1. Образование за деньги
В один прекрасный день вы проснулись в своей постели и решили научиться чему-нибудь полезному. Вы оглянулись по сторонам и увидели кучу программ, которые обещают превратить вас в супер-специалиста. Соцсети кишат рекламой подобных контор. Вроде бы у чуваков крутой лендинг и офигенные отзывы. Вы записываетесь на курс от такой конторы, начинаете проходить его. И тут неожиданно оказывается, что он состоит из туториалов, скопированных с хабра. Даже токсичные коменты скопировали. Деньги улетели впустую.
Вокруг дата-сайнса огромный хайп. Разводы, обещающие вам после их курсов 300кк/сек, растут как грибы. Образование стало бизнесом. К сожалению, забота о качестве образования для многих бизнесов - не самое первое дело. Распознать контору, которая решила подзаработать на вас шекелей, помогают базовые навыки. Их можно добыть бесплатно.

Более того, кто сказал, что вам понравится становиться дата-шрушером или разработчиком или ещё кем бы то ни было? Мало ли, в середине процесса к вам придёт осознание, что лучше быть кем-то другим. Ну либо резко окажется, что нет свободного времени, а казалось, что оно будет. А вы уже заплатили за какой-то курс. Неприятно. Ошибаться при обучении и поиске себя хочется бесплатно.
Конечно же, с платным курсом иногда может повезти, но это скорее исключение. Глобально я могу придумать только два оправдания потратить на дополнительное образование деньги:
а) У вас есть нормальная работа, но при этом мало свободного времени.
Хочется, чтобы все компетенции были завёрнуты в красивую коробочку. Хочется, чтобы был человек, который будет отвечать на тупые вопросы и всё разжёвывать. Да и вообще заплатить комфортнее. Потраченные деньги мотивируют ботать. А когда покупаешь абонимент в тренажёрку на полгода, начинаешь в неё ходить.
Такая мотивация вполне понятна. Но перед тем, как тратить свои кровные, наберите базовые навыки бесплатно. Это позволит вам отфильтровать развод. Например, если вы собрались учиться прогать на питоне, пройдите хотя бы pythontutor. После вы сможете более здраво оценить, что за набор тем вам предлагает платный курс. Более того, хорошие конторы обычно выкладывают полностью в открытый доступ первые курсы в своих специализациях. Вы можете бесплатно пройти их, позалипать в тренажёре для кода, а потом решить — релевантны ли вам вообще навыки с этой специализации.
Тут самое главное не утонуть в лени, разжёвывании и комфортных лекциях. Если вы хотите получить новый навык — надо рвать жопу. Чаще всего взрослым делать это влом даже при сильной мотивации.
Я вёл подобные курсы переподготовки. Работать со взрослыми было странновато. Жопу хочет рвать дай бог один из 20. Остальные максимально пасивны. Даже вопросы не задают, когда ничего не поняли. Даже когда вытягиваешь их силой. А потом в конце семестра кто-нибудь спрашивает как установить tensorflow или pytorch. Фу такими быть. Никогда так не делайте. Выходите из зоны комфорта и спрашивайте.
Обычно когда рассказываешь те же вещи студентам, от вопросов ломаются столы в аудиториях. Ещё во взрослых головах есть какая-то предвзятая чушь, что учиться в одной аудитории со студентами — стыдно. Они этого стесняются. Не стесняйтесь, в течение жизни вы ещё не раз окажитесь в учебной аудитории. Уж слишком быстро меняется мир.
Также обратите внимание на то, что есть бесплатные линейки курсов, завёрнутые в красивую коробочку. И их тоже ничто не мешает вам пробовать.
б) Курс учит продвинутым штукам, его делает DS-селеба с безупречной репутацией.
В мире довольно мало курсов, которые учат продвинутым штукам. Если речь про тот же DS, то бывают курсы, где тебе даётся инфраструктура и надо учить и деплоить модели. Сервера стоят денег. Более того, такой продвинутый курс, скорее всего, делает какой-нибудь именитый чувак, к которому в сообществе есть доверие. Подписываясь под ним, он рискует своей многолетней репутацией.
Если вы уверены, что эти продвинутые штуки вам релевантны — на такой курс тоже можно идти. Главное — не забить в середине процесса и не идти на самую первую итерацию. В неё неожиданно всплывёт до жопы косяков во всяких тестирующих системах для домашек.
Если вы студент, вам не подходит ни одна из этих категорий. Потому что у студентов нет денег. Но зато дофига свободного времени. Именем себя самого, я запрещаю всем студентам, покупать курсы где бы то ни было. Лучше купите пивка. Шлифаните под него бесплатные курсы из гайда, а потом деплойте на какой-нибудь классной стажировке. Время играет на вас. Осталось только порвать жопу.
Ниже мы сконцентрируемся на бесплатном либо условно бесплатном. Часто будет встречаться coursera.org и другие подобные сервисы. Обычно курсы на них распространяются по двум моделям. Либо это полностью бесплатный курс, где просят денег за сертификат о прохождении. Либо это курс с бесплатным контентом (видео, код, презентации), но платной проверкой домашек. Но мы то знаем про Lorem Ipsum и неэтичные лайфхаки.
Никогда не покупайте на таких платформах сертификаты. Это абсолютно бесполезная фигня. Можно его купить только, если вы хотите задонатить сервису денег на развитие.
Более того, никогда, ни при каких условиях не добавляйте эти сертификаты в резюме. Никакой полезной инфы для работодателя эти сертификаты не дают. Это кринжово. Лучше запихните туда ссылку на свой github с каким-нибудь проектом.

2. Офлайн-школы
ШАД (Школа Анализа Данных) — это место, где готовят драконов с максимально длинными шеями. Есть всякие умники, которые говорят:
Хочешь выучить анализ данных? Поступи в ШАД!
Это неправильный совет. Правильный совет звучит так:
Ты хорошо знаешь математику? У тебя есть уйма свободного времени и ты хочешь выучить анализ данных? Попытайся поступить в ШАД. Возможно, удача будет на твоей стороне.
Поступить в ШАД сложно. Для того, чтобы решить экзамен надо понимать математику. Её недостаточно заботать и уметь применять. Её нужно зашарить так, чтобы в голове была выстроена единая картина мира. Тогда в экзаменационных задачах можно будет разглядеть решения.
Сейчас дело обстоит немного проще. Появился трэк, куда можно поступить без хардкорной математики. Для этого трэка у вас уже должен быть опыт промышленной разработки.
Более того, математику внутри программы никто не отменял. На пары и домашки придётся тратить много времени. Если вы при этом работаете, можно не вывезти. Поэтому с этим надо быть осторожным. Идеально залететь в ШАД на 4 курсе, когда ты уже что-то знаешь и время поботать в спокойствии и тишине у тебя ещё есть.
Я пробовал учиться в ШАД, когда устроился в Яндекс. Меня хватило на год вольнослушания. Часть курсов в течение этого года я завалил из-за нехватки времени. После я забил на системность и просто стал смотреть отдельные курсы, которые меня интересуют без их сдачи. Если бы я смог поступить в ШАД на 4 курсе, я бы очень сильно от него кайфанул, но эта возможность безвозвратно утеряна.
ШАД возник при Яндексе довольно давно. С тех пор прошло много времени и появилось много других компаний, которые стали открывать у себя школы для подготовки кадров. Например, есть OZON MASTERS. В списке преподов и там и там топовые специалисты.
Если у вас есть время залететь в такую магистратуру, она бесплатная и её спонсирует какая-то клёвая компания, попробуйте. Знания будут более системными.
Если команда, которая организует школу вселяет смутные сомнения, учит работать в странной кнопочной системе, да ещё и просит денег — в пекло их.
3. Онлайн-курсы
Онлайн-образование прошло довольно длинный путь от лекций, выложенных в онлайн до когортных подходов. У любого онлайн-курса будут свои проблемы и болячки.
Главная проблема — выживаемость слушателей. Почти никто и никогда не доходит до конца. Вы тоже дойдёте до конца далеко не везде. Даже если начнёте с понедельника.
3.1 Специализации
В интернете висит несколько специализаций по анализу данных. Я бы начал своё погружение в DS именно с них.
Например, есть проверенная временем специализация от МФТИ и Яндекса. Она состоит из 5 курсов. Каждый курс идёт по 4-5 недель. Она начинается с вводных вещей по математике и питону. Дальше идёт анализ данных. Если вы её пройдёте как следует, а не вскользь, то уже будете знать довольно много вещей.
Спецуха классная, но немного устарела. Код на втором питоне. Придётся доставлять вокруг всех принтов скобки. С другой стороны все задания проверены временем, по идее проблем с грейдером быть не должно. Лекции по ML огонь. Все основные методы, кроме нейронок охвачены. Разве что проверки peer-review заданий можно ждать месяцами.
Сейчас ФКН выпускает набор более свежих специализаций. Они более подробные. Есть по анализу данных. Есть по математике. Есть по промышленному ML.
В них везде пререквезитом идёт python. Если с ним туго, то перед тем, как бросаться на эти спецухи, прочитайте раздел про программирование.
Ещё из больших специализаций вроде адекватно выглядят курсы от DataLearn. Но они с вероятностью 99% станут платными и с треском вылетят из этого гайда.
3.2 Математика
Анализ данных невозможен без знания математики. Чем хардскильнее DS, тем лучше он должен понимать, что находится внутри моделей. Даже если вы не собираетесь прогать алгоритм с нуля, полезно знать как он работает. Это помогает видеть недостатки алгоритмов и чётко осознавать в каких кейсах модель не взлетит. Это сильно экономит время. Не все это понимают. А те, кто понял и заботал, во время брейнштормов, когда у всех идеи кончились, только начинают их генерировать.
Матан описывает как устроен мир вокруг нас. Даже больше, матан — это наука о том, как можно забивать на неважное. Любите забивать? Выучите матан и освойте большую силу о-малых.
Тервер говорит, что мы все невежды и помогает невежество замоделировать. Весь анализ данных — это сплошной тервер с разными плотностями, функциями правдоподобия и гипотезами.
Все данные, которые попадают в наши руки — матрицы. Из-за этого все модели машинного обучения утыкаются в линал. Если не понимаете, как, посмотрите видео про путь от матриц к большим данным для самых маленьких.
Обучение модели — это минимизация какого-то функционала, описывающего наши ошибки. Часто эти функционалы очень некрасивые или данных очень много. Это приводит к невозможности найти аналитическое решение. Приходится искать его численно с помощью методов оптимизации.
Короче, забить не получится. Математику надо будет регулярно доботывать и разбираться, как что устроено, если хочется быть настоящим самураем.
Вспоминаем про распараллеливание. Если у вас в ВУЗе были нормальные курсы по математике и вы помните основные концепции, смело двигайтесь к следующему разделу. Если ботаете математику впервые, делайте это в несколько заходов.
- Сначала разберитесь в основных определениях. Что это такое? Нахрена надо? Как объяснить простым языком рандомному прохожему?
- Научитесь решать задачи. Оптимизация, поиск вероятностей, подсчёты и т.п.
- Если душа просит, можно закопаться в доказательства и кайфануть от их красоты.
Именно по такому принципу устроена спецуха математика для анализа данных. Доказательств внутри считай и нет. Если вы заботали эти четыре курса, вы знаете больше, чем надо. Отдельное внимание обратите на курс по линалу. Это лучший курс по линалу из всех, что я видел на русском языке.
Внутри МФТИ-шной спецухи, которую я рекомендовал выше, в первом курсе дают все основные определения. Задачи там не решают, но для первого знакомства это нормально. Во многих курсах по DS, которые будут в перечнях ниже, первыми главами идёт быстрое повторение отдельных разделов математики.
Если хочется больше задач, почитайте mathprofi. Статьи с него могут c лихвой заменить курс семинаров во многих ВУЗах.
Если всё совсем-совсем плохо, посмотрите Саватеева. Его объяснения сложно не понять. У него ещё есть отличная книга. Ещё можно глянуть адаптационный курс по основам математики от Питерского CS-центра.
Стоит ли на этом останавливаться в плане математики? Нет. Эти навыки необходимы, но не достаточны. Полезными могут оказаться совершенно разные области.
Например, теория графов может помочь при моделировании всяких взаимосвязей. Многие вещи в нашей жизни можно изобразить в виде графов. В машинном обучении есть даже отдельные ответвления, занимающиеся графовыми алгоритмами. Одним словом, нет предела совершенству. Если хотите копнуть глубже, можно глянуть курсы из списка ниже. Но, прошу вас, не забывайте, что у Змея Горыныча три головы и нужно прокачивать их все.
- Репозиторий Бориса Демешева с кучей крутых источников мудрости по терверу. Обратите внимание на видосы с семинаров и учебники Черновой по терверу и матстату.
- Вводный курс по терверу от Райгородского, он короткий и дискретный
- Прикольный курс по терверу и асимптотическому анализу от Питерского CS-центра
- Если решили упороться комбинаторикой, от Райгородского среди МФТИ-шных курсов есть несколько разных комбинаторик. У Вышки тоже есть такая страничка с курсами. И у Яндекса. И у любых других университетов.
- Великолепный курс по линалу от MIT, вообще MIT выложил довольно большое количество своих курсов в открытый доступ. Смело можно выбирать среди них себе любой.
- Лучшие лекции, которые я когда-либо слушал по матану - лекции Стаса Шапошникова. Но там совсем-совсем матан. Но очень понятно.
3.3 Программирование
Когда данных много, оптимизацию на бумаге не сделаешь. Придётся научиться программировать.
Под программированием я подразумеваю знание основного синтаксиса и понимание того, как работают циклы, условия, функции и тп. Со временем вы будете изучать разные пакеты с кучей специфичных функций и погружаться в язык более глубоко. А ещё нужно будет подучить алгоритмы и начать разбираться в их сложности.
Чаще всего дата-шрушеры пишут на петухоне питоне. Чем больше задач на программирование вы решите, тем лучше будете писать код.
Начальный уровень: начните с pythontutor - интерактивного учебника на русском языке. Пошло хорошо? Отлично! Решайте задачи в курсе от Густокашина. Идёт очень туго? Посмотрите курс Python как иностранный. Фишка этого курса в том, что его делали люди, которые вкатывались в DS-индустрию из какой-то другой, а не из мира программирования.
Базовые алгоритмы: очень рекомендую прочитать грокаем алгоритмы и теоретический минимум по CS. Из первой вы узнаете про сложности алгоритмов и поймёте как обширен их мир. Из второй вы наберётесь базовой компьютерной грамотности. Обе книги написаны очень простым языком, а ещё они с мемами. Можно учиться и кекать одновременно.
Знаете основной синтаксис? Почитали по диагонали про алгоритмы и сложности? Двигайтесь дальше. Если захочется ещё попрогать и алгоритмов, то сходите по ссылкам ниже.
Решайте задачи: чем больше задач вы нарешаете, тем лучше. Можно искать их на leetcode или codeforces. Подобные алгоритмические задачки иногда спрашивают на собеседованиях.
Продвинутый уровень: довольно неплохо выглядит специализация от МФТИ и мэйла. Хотите офигеть от жизни? Посмотрите лекции от яндексоидов. По алгоритмам есть хорошая специализация от Яндекса и Стенфорда. Самое глубокое погружение в питон можно найти в книге Лутца. Для продвинутых на русском ещё есть ШАДовские лекции по алгоритмам от Макса Бабенко.
Не бойтесь курсов на английском языке. Не бойтесь гуглить на английском языке. Даже если у вас очень плохие навыки в английском, от него никуда не денешься. Сидите с переводчиком. На работе вам придётся иметь дело с англоязычной технической литературой и всякими форумами в интернетах каждый день.
Ещё не надо стесняться гуглить ошибки, которые вам выдаёт код. Чаще всего это будет приводить вас на универсальный форум stackoverflow, на котором собраны ответы на очень многие вопросы. Скорее всего ваша проблема уже возникла у какого-нибудь жителя Индии, он задал вопрос на stackoverflow, ему там помог какой-нибудь житель Бразилии, и всё это произошло на ломаном английском, понять который обычно не составляет особого труда.

3.4 Технические навыки
Среди людей, получавших DS-образование, есть такое понятие, как "пропущенный семестр." В него входят все те навыки, которым научить забыли. Пришлось их получать самостоятельно из гугла: работа с командной строкой, редакторы, системы сборки, контейнеры и тп.
В какой-то момент топовые факультеты поняли, что про инструменты разработки толком ничего не рассказывают и залатали этот пробел. В англоязычном варианте можно посмотреть версию от MIT. В русскоязычном варианте можно посмотреть версию от ФКН. Обе версии чрезвычайно годные, на страничке курса есть куча ссылок на дополнительные материалы. В дополнение к ним я добавлю своих.
Довольно много технических навыков вроде терминала, SQL и Hadoop покрывает спецуха про промышленный ML. Кроме неё про аналогичные штуки можно глянуть курс на степике.
Терминал
Рано или поздно придётся освоить терминал. На степике есть хороший вводный курс. Научат основным командам, немножко прогать на баше, подключаться к серверу и запускать там скрипты.
Ещё можно позависать в каком-нибудь тренажёре. Если есть время и желание попробовать что-то запустить на сервере, щедрый гугл может предоставить вам на несколько месяцев оборудование на 300$ на халяву. Аналогичная акция есть у Яндекса, но денег дадут меньше.
Системы контроля версий
Git — это одна из самых популярных систем контроля версий. Один из самых известных сервисов, основанных на git — github. Весь код, выложенный на github находится в открытом доступе. Корпорации обычно покупают на github себе приватные аккаунты.
Зачем нужен навык по работе с git? Дата-шрушеры часто работают в командах. Приходится обмениваться кодом. Лучше, чтобы была система контроля версий. Мало ли вы что-то удалили или переписали, а потом выяснилось что это неэффективно или вообще неправильно. Нужна возможность откатиться назад. Хранить на компьютере все версии кода довольно затратно, хранить изменения лучше. Git именно это и позволяет делать.
Можно посмотреть интерактивный самоучитель и почитать книгу на русском языке.
Виртуализация
Часто хочется упаковать весь свой код вместе с тем окружением, где он запускается, в контейнер. Чтобы человек сразу же запустил его с нужными версиями библиотек и всем таким. Чтобы без проблем и несовместимостей.
Docker помогает это сделать. Прочтите какой-нибудь базовый гайд. В качестве практики попробуйте залить решение для какого-нибудь соревнования с Kaggle, где требуется сдать его с докером.
SQL
Данные хранят в базах. SQL — это язык запросов, позволяющий с этими базами работать. Базовые запросы из SQL знать не помешает. Для того, чтобы их освоить, можно глянуть курс на степике либо просто посидеть в любом SQL-тренажере. На просторах интернета их выше крыши.
Другое
Дата шрушеру могут понадобиться многие другие технические навыки. Мир меняется довольно быстро. Плюс внутри каждой компании есть какие-то свои инструменты с кучей внутренней документации. Не бойтесь сталкиваться с чем-то новым и читать туториалы. Не бойтесь экспериментировать (если конечно это не прод).
3.5 Здравый смысл
В схемах с навыками была голова, которая отвечает за здравый смысл. К сожалению, нет никаких курсов, которые помогли бы его прокачать. Он приходит сам, вместе с неуловимой штукой, которую все называют "опыт".
Чем лучше вы понимаете продукт, где вы работаете, и чем больше у вас опыта, тем вы круче. Чтобы были опыт и понимание, надо решить много задач. Ещё нужно искренне интересоваться тем, что вы делаете, и тогда чакра точно откроется.
Попробуйте сделать свой личный проект. Придумайте себе задачу. Спарсите данные. Сделайте разметку, если это необходимо. Поднимите халявный сервер, поработайте с ним. Задеплойте модельку с помощью какого-нибудь Flask. Ещё можно оформить итоговый продукт в виде телеграм-бота.
Ещё вам точно не повредит знание предметной области, в которой вы собрались дата-шрушить. Например, если вы идёте в ритейл заниматься прогнозированием цен, разбиритесь в базовой микроэкономике. Поверьте мне, вы не раз услышите на работе про всякие эластичности, товары первой необходимости и тп.
А ещё плохо быть криповым необщительным задротом софт-скиллс никто не отменял. Они существуют. Проявляйте инициативу, доводите дело до конца, берите на себя ответственность.
3.6 Анализ данных
Не прошло и тысячи строк, добрались до тела дракона. Это повод открыть бутылочку чего-нибудь. Ведь ради этого мы все тут и собрались.
Когда выбираешь себе курс по DS, имеет смысл прикидывать, насколько велика внутри каждая из трёх голов дракона. Бывают курсы излишне сильно загруженные математикой. Бывают курсы загруженные прогой. Бывают поверхностные курсы про логику и примеры бизнес-задач.
Машинное обучение
Снова напоминаю про спецуху от МФТИ и спецуху от ВШЭ. Туда смотрите в первую очередь.
Можно попробовать пройти классический курс по машинке от основателя курсеры Andrew Ng. Он на английском. Он объясняет всё слишком дотошно и медленно. Это для вас может быть как плюсом, так и минусом. Ещё один минус в том, что все задания к курсу предлагается делать на мёртвых языках, октаве и матлабе. Тем не менее, на просторах интернета можно найти готовые решения на Python.
Когда вы освоили основной материал, нужно углубиться в него. Для этого я рекомендовал бы пройти курс по машинке от ODS на хабре. В конце каждой статьи есть ссылка на актуальную видео-лекцию, прочитанную в последнюю итерацию курса. Курс от ODS чуть более хардкорный, чем курсеровские спецухи.
В дополнительных материалах в статьях на хабре часто указываются лекции Евгения Соколова. Их тоже имеет смысл почитать. Даже можно найти записи лекций его курса по ML, которые он читает на ФКН. На их канале тоже можно найти уйму полезного.
Кучу крутых вещей можно вычитать в блоге Александра Дьяконова. Он выигрывал соревки на кегле, когда это ещё не было мэйнстримом.
Если хочется очного курса, можно также записаться на Data Mining in Action. Это полугодовой интенсив по машинке от Виктора Кантора и Эмили Драль, знакомых вам из курса МФТИ.
Если вы хотите жёсткой математики и вообще никакой практики, смотрите курс Воронцова. Это примерно треть его ШАДовского курса по ML. Правда в ШАД есть семинары и много практики на питоне, а на курсере нет.
Области тьмы ML
Продвинутые юзеры могут попробовать углубиться в отдельные области ML.
По нейросеткам есть шикарный курс Deep Learning на пальцах от Семёна Козлова. Он рассказывает очень простым языком сложные вещи. Всем очень рекомендую его видосы.
Если хочется книгу, прочитайте глубокое обучение от Николенко. Там будет побольше математики, но и практику не обойдут стороной. Правда код придётся переписывать с первой версии tensorflow на вторую, но это довольно простое упражнение.
На степике по нейросетям можно посмотреть курс от Анатолия Карпова с основами основ. Там же два более свежих курса от Samsung на pytorch: компьютерное зрение и анализ текстов.
От МФТИ можно глянуть dlschool. На youtube есть записи лекций и семинаров
Можно посмотреть специализацию от Яндекса и ВШЭ. Она состоит из разных курсов: введение в нейронки, байесовские методы в ML, как побеждать на kaggle, работа с текстами и НЛП, обучение с подкреплением, курс про ML и адронный коллайдер (совсем специфичная вещь). Все курсы на английском.
Многие ШАДовские курсы лежат в открытом доступе. Тут можно найти и NLP и RL и DL. Есть тетрадки с домашками/семинарами, а также видосы с лекциями. По NLP очень рекомендую лекции от Лены Войты.
По временным рядам нормальных курсов на русском нет. Обычно все рассказывают про ARIMA. Есть две недели про ряды от меня в вышкинской спецухе. Есть хорошая статья от Дмитрия Сергеева в курсе от ODS. Ещё можно почитать отличную книгу Хиндмана.
Матстат и эконометрика
Анализ данных пытается ответить на два великих вопроса:
Как устроен мир (как переменная y зависит от переменной x)?
Что будет завтра (как спрогнозировать переменную y)?
В зависимости от того, на какой из двух вопросов мы ищем ответ, мы используем разные методы. Казалось бы, если модель получилась интерпретируемой, значит она будет хорошо прогнозировать. Если модель хорошо прогнозирует, то значит она должна быть интерпретируемой. Оказывается, нет.
Если нас интересует ответ на второй вопрос, то на помощь к нам приходит машинное обучение. При поиске ответа на него, мы почти всегда жертвуем интерпретацией и находим модель, которая хорошо умеет прогнозировать, но не совсем понятно как она устроена внутри.
Если нас интересует ответ на первый вопрос, то на помощь к нам приходят эконометрика, статистика и интерпретируемое машинное обучение. В этом случае мы очень сильно боимся получить неправильную величину эффекта. К сожалению, этой ошибке способствует огромное число факторов. Чтобы избежать ошибок, статистики придумали кучу навороченных статистических процедур с правдоподобием и гипотезами.
Хочется матстата на питоне? Идите в спецуху Вышки. Там тоже три курса. Их делал автор этого поста (реклама подъехала).
Хочется эконометрики, смотрите курс от Бориса Демешева. Правда он на R. Ещё если хочется уметь искать причинно-следственные связи, прочитайте книгу Филиппа Картаева. Это лучший учебник по Эконометрике на русском, который я видел. Особенно прочитайте последние главы про эффект воздействия.
По интерпретируемому ML пока курсов не подвезли, но есть неплохая книга об этом.
Ещё по статистике есть два офигенных курса, которые ставят мозги на место: Improving your statistical inferences и Improving statistical questions.
Заключение
Последнее, что хочется сказать - не забывайте о боевом опыте моделирования. Практика для дата шрушера — важнейшая вещь. Попробуйте Kaggle, но только без фанатизма. В проде модели ради сотых процента не стекают. Сделайте свой собственный проект. Например, телеграм-бота, который парсит что-то полезное и где-то на халявном сервере от гугла обсчитывает ваш личный ML.
Ну или в конце концов, найдите работу! Там будет дофигище практики и экспоненциальный рост в навыках. Реальная работа — это намного круче, чем обучающие курсы. Однако для неё нужен какой-то бэкграунд. Как только набрали его — бегом на собесы. Если конечно вы не студент. Студенты качают все три головы до максималок и идут в ШАД (или нет).
Когда найдёте работу, не забывайте, что в курсах можно найти какие-то новые задачи. Это разнообразит жизнь. На самом деле, довольно приятно пилить по вечерам разные собственные проекты ради интереса. Можно даже публиковать статьи или выступать на митапах.
Поздравляю всех, кто дошёл до конца этого лонгрида. Кидайте ссылки на свои любимые курсы в комментарии. Будем пополнять наши списки :)








поясните, шрушер - это такой локальный прикол автора, или такая калька с английского?
P.S. спасибо за длиннопост - пройдет некоторое время пока смогу откомментить по контенту
Спасибо за материал. Немного по смыслу похоже на Телеграм-канал Мамкин Data Scientist (https://t.me/mommyscience).
А что думаешь про Datacamp и подобное для быстрой проработки навыков (Python, SQL и др.) до «минимального» уровня?
😱 Комментарий удален его автором...
😱 Комментарий удален его автором...
После прочтения осталось чувство что текст может отпугнуть очень многих которые хотят освоиться в профессии, но не свободны во владении математикой. В целом текст очень хорошо описывает реальность, но я бы выкинул все что упоминает мат подготовку.
На просторе СНГ есть странное отношение к математике как к священной корове. Мол, для того чтобы поступить в ШАД, давайте порешаем олимпиадных задачек. И давайте мы будем объяснять материал не через концепции, а сразу навалим тонну формул и пусть студенты сами трахаются с пониманием. Если вам нравится идея получать знания через превозмогание и формулы, то тот же ШАД / курс МФТИ / ВШЭ вам классно зайдет, но этот путь для избранных.
Математика -- всего лишь один из инструментов, и дрочить матан это подвид особой олимпиады на просторах СНГ. В процессе обучения в Германии я столкнулся что здесь материал подается в формате "долгое объяснение концепции" -> "дополнительное объяснение математики для формального оформления". И вы не представляете насколько свободно я выдохнул. Ты сосредоточен на концепции которая движет лекцию и это увлекательно, а математика дается как дополнительный инструмент для выражения своих мыслей, а не как жесткие рамки в которых тебе нужно работать и где тебе надо решить с десяток непонятно кому нужных примеров. Для понимания, сравните англоязычную математическую вики и русскоязычную.
К чему я, на просторах СНГ плохо умеют интересно и адекватно преподавать математику, все рассчитано на полу-перельманов которые от математики в вакууме кайф ловят. Если вы хотите вкатиться в ds/ml/cv смотрите только зарубежные лекции, там математика связанная с предметом преподается иначе, вы и поймете больше, и страха будет меньше. Ставьте акцент на понимании идей. Если вы смогли сдать первый курс матана в любом универе - все будет вам по силам (и дополнительные курсы по математике вам скорее не нужны). Вы справитесь!
Очень много, очень годно! Тебе что, Гитлер этот текст нашептывал, так уж он дьявольки хорош.
Я в итоге вкатился в п5, Продуктовую аналитику, причем когда туда попал, не особо даже понимал, какие есть альтернативы, когда мне на работе понабится ML и пр. Был слегка фрустрирован в начале, о чем хочу написать следующий пост :)
Насчет приведнных ссылок - а ты проходил сам в итоге спецуху от Яндекса и МФТИ? Просто мне ее очень сложно кому-то порекомендовать, она стремительно скатывается в какое-то днище уже на третьем курсе (а первые звончки там - на втором, когда за одну неделю тебя внезапно пытаются научить нейронным сетям). Я кое-как дотошнил до диплома только чтобы понять, что это 6 недель сомнительного проекта по сомнительным устаревшим инструкциям, с мервым форумом и проверкой другими такими же страдальцами.
P.S.
Перешёл по ссылке на курс ШАД и ВШЭ по DL (и NLP, RL). Если я правильно понял, то видео лекций есть к прошлому году, но не к этому.
Может кому-нибудь пригодится:
https://github.com/yandexdataschool/Practical_DL/tree/fall20
Нужен ещё пост про левел-ап тем, кто уже вкатился.
После прочтения лонгрида я понял, что не быть мне дата-шрушером.
Пост крутой! Теперь понятно как начать этим заниматься.
Но остался такой вопрос, какие вообще бывают задачи? Что считается крутыми задачами?
Вообще в контексте того что сейчас очень много либ для всего насколько часто нужно делать что-то самому? Можно подобрать готовую либу или модель которая умеет нужное?
Например я прошел курс от Стенфорда и сам могу написать нейросеть и градиентный спуск, чтобы ее обучать. Но насколько часто это нужно? (я подозреваю что нечасто)
По линейной алгебре мне заходит:
https://www.amazon.fr/No-bullshit-guide-linear-algebra/dp/0992001021
Но это больше как паралельно учебник, автор копает глубоко, но понятно.
а есть какая-нибудь книга (или онлайн материалы) по ML/DL, где
Я так понял, что материалы из поста хороши для новичков, но из-за этого пункт 1 не выполняется, а ведь с формулами удобнее и понятнее (если есть достаточный бэкграунд), и потом подсмотреть проще.
Спасибо за содержательную статью! Появился вопрос - если не указывать пройденные курсы, но и не иметь профильного образования, как пройти хотя бы эйчара?
Пять копеек от меня. В сети есть канал StatQuest где очень многие концепции статистики и машинного обучения разжевываются для tupikh. Очень подойдет для первого ознакомления и с ответом на вопрос "Про что машинное обучение вообще". Материал, к сожалению совершенно не систематизирован, но автор сейчас пишет учебник, который скоро закончит.
https://www.youtube.com/c/joshstarmer
В каких реальных задачах бизнеса помогают дефолтные Scikit-learn, TensorFlow, Keras, PyTorch и прочие инструменты? Вряд ли многим нужно отличать котеек от пёселей или писать очередной распознаватель рукописных цифр.
Feature engineering жив ещё? Гудфеллоу и товарищи обещали, что для глубоких сетей он уже не нужен, дескать, сетка сама всё сделает.