

Короче, есть у нас чатик. Если раньше он был российским с редкими вкраплениями заграничных товарищей, то сейчас он скорее равномерно размазан по миру, соответсвенно постоянно случаются моменты "а я сегодня офигенно поела на 4200 йен", и ты, сидя у себя в москве, еще хоть как-то понимаешь суммы в долларах и евро, но вот йены, лари и шекели для тебя — ну вообще темный лес.
Нет, ну можно конечно сходить в гугл и вбить туда "4200 йен в рублях", но скажем честно, кто это будет делать каждый раз-то? Для такого нужна серьезная мотивация уровня "узнать сколько стоит монитор который ты хочешь", а вот для цены за ужин такое чаще не срабатывает, чем срабатывает. И остаешься ты без важной информации, а это снижает общий контекст: цену за ужин в чатике озвучивают в основном для того, чтобы поделиться радостью "офигенные суши и так дешево", или наоборот, огорчением "столько заплатили, а устрицы говно".
Проблему хотелось как-то решить. Логично решать ее ботом: ты ему пишешь /convert 4200 JPY RUB, а он тебе "3002 RUB".
Но все равно как-то сложно, коды запоминать.
Наверное, можно заменить коды на название валют?
—/convert 4200 йены рубли?
—3002 рублей
Уже получше. Может быть, избавиться от целевой валюты вообще? В чате человек много, но не бесконечно, и сосредоточены они в небольшом количестве стран.
—/convert 4200 йен?
—🇷🇺 3002 ₽, 🇺🇸 $28, 🇮🇱 102 ₪, 🇪🇺 €27, 🇬🇧 £22, 🇦🇲 11 085 ֏
А нужна ли отдельная команда? Если человек пишет цену, то скорее всего, она будет интересна другим участникам. Значит, можно парсить вообще все сообщения в поисках цены и найдя ее — реплаить на сообщение с конвертацией.
—Я сегодня ужинала в русском ресторане на 4200 йен
—4200 йен (🇯🇵) это 🇷🇺 3002 ₽, 🇺🇸 $28, 🇮🇱 102 ₪, 🇪🇺 €27, 🇬🇧 £22, 🇦🇲 11 085 ֏
Ах, как жаль что в тг нельзя менять сообщения участников. Это была бы прям огонь фича — как в инлайне, только без необходимости тегать бота. Можно было бы переводить сообщения автоматически, парсить линки на инстаграм и вставлять вместо них видео, санитайзить линки, удалять эмодзи, включать "вежливый режим" с заменой "пошел на хуй" на "проследуйте в далекое путешествие", автоматически подбирать стикеры и гифки по их описанию, и множество других замечательных вещей..
Кстати, инлайн в боте тоже можно поддержать: это будет фича для 1-1 диалогов, где хочется дать собеседнику информацию о цене, но бота туда засунуть не получится.
Пишем "@currvaconverter_bot я вчера обожрался на 200 шекелей и не могу теперь никуда идти", выбираем второй вариант и собеседнику уходит сообщение "я вчера обожрался на 200 шекелей (🇷🇺 5891 ₽, 🇺🇸 $55, 🇪🇺 €52, 🇬🇧 £43, 🇯🇵 8240 ¥, 🇦🇲 21 749 ֏) и не могу теперь никуда идти"
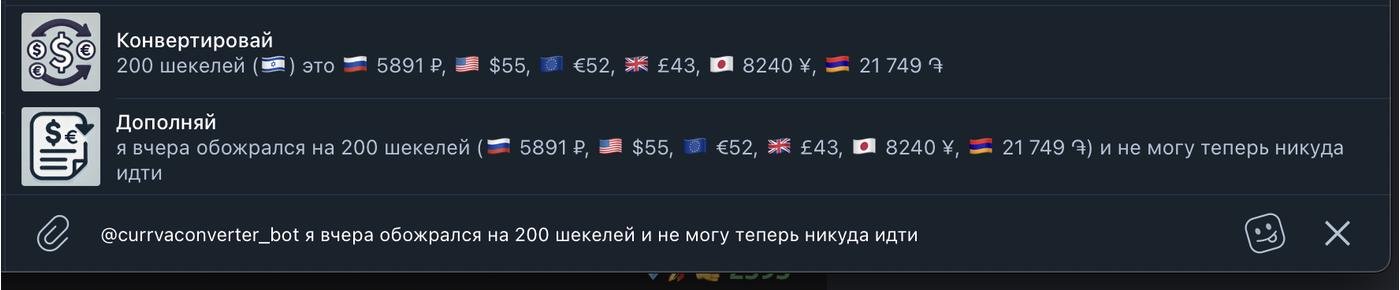

Бот находит в исходном сообщении пару "число+валюта", конвертирует ее в список альтернативных валют, и заменяет в сообщении исходную пару на конвертированные варианты.
Кажется, удобно. Ой, простите, я тут резко перескочил от идеи к реализации. Почему ни строчки кода? Потому что код за нас будет писать LLM.
Я помню появление копайлота , который по сравнению с автокомплитом на базе методов из файлов и библиотек (и даже по сравнению с TabNine) казался какой-то магией: он волшебным образом предугадывал завершение строк.
Примерно такое же я сейчас ощущаю с Cursor: это такая ide на базе VS Code, в которую довольно глубоко интегрирован ИИ-редактор.
ChatGPT, конечно, может писать код, но это скорее твой подчиненный на удаленке — ты ему пишешь письмо, копируешь туда кусок кода, и тебе приходит ответ с измененным куском кода, который ты вставляешь обратно, запускаешь проект, видишь, что что-то работает не так, копируешь коллеге кусок логов и все повторяется.
В какой-то момент у ChatGPT появился canvas, с которым стало возможно работать с этим коллегой в режиме расшаренного экрана, но это все еще ограничивалось одним файлом. Т.е. писать простой скрипт — офигенно, но как только проект вырастает до сколько-нибудь большого размера, все становится грустно. И я даже не говорю о разделении проекта на несколько файлов, фиг с ним, можно классы на время разработки держать в одном файле, а потом разбить, если хочется красоты. Нет, он тупо начинал портить код в других местах файла, забывая методы, упрощая логику и так далее.
Плюс, канвас — это все же не IDE, там нет линтера, анализатора, прыжков к месту обьявления, терминала. Да, ты редактируешь код с коллегой, но все равно потом приходится вставлять его в IDE и запускать отдельно.
И вот Cursor — это прям такой же прогресс по сравнению с ChatGPT, как ChatGPT по сравнению с Copilot.
Я специально попробовал написать этого бота в формате "я не программист, я умею говорить, что я хочу, запускать код в терминале и копировать оттуда стектрейсы". Впечатления... Ну, двоякие. С одной стороны, тебе реально удается написать простого бота абсолютно не притрагиваясь к коду. И вот этого умения описывать фичи и копировать стектрейсы (а это уровень среднего продакта) реально хватает для несложного прототипа.
С другой стороны — предпоследнее слово прошлого абзаца там не просто так. Примерно на 30 кб кода в таком режиме он запутывается (я посмотрел получившийся код и тоже запутался) и начинает ломать существующие фичи или просто не может добавить какой-то простейший функционал. Т.е. ты ему говоришь "вот ты скачиваешь курсы валют, тебе не надо это делать каждый раз при старте, положи их в кеш вместе с временем скачивания и только если разница во времени больше пяти часов, качай заново", он что-то делает, радостно рапортует, но это не работает. Ты говоришь что не работает, он тебе радостно отчитывается, что нашел и исправил ошибку, но оно все еще не работает. А задача-то реально простая для него — на чистом проекте результат работает зачастую с первого раза.
Мне хочется, чтобы этот опыт испытали все отрицатели технического долга, которые очень любят тезис "главное, чтобы фичи работали, а на красоту кода бизнесу плевать".
Вот в режиме песочницы можно ощутить, как техдолг в буквальном смысле хоронит под собой внедрение новых фич в проекте: функционал, который раньше требовал пяти минут работы джуна(LLM) с небольшим код-ревью техлида(меня), теперь требует получаса работы миддла, а то и сеньора.
Поэтому промежуточный вывод — "в режиме продакта" писать большие проекты пока не получится. Дописать обособленный кусок аналитики? Да. Подключаемый модуль "по примеру"? Да. Микросервис, который ходит в базу и выдает данные после небольшого препроцессинга? Да. PoC новой логики на страничке? Ну, в целом да. PoC целого проекта? Уже нет.
В общем, я остановился на том, что на 35 килобайтах кода бот работал, но добавлять новый фунционал уже не получалось без ручного ковыряния кода. Вручную в этом коде тоже ковыряться не хотелось, он был очень неряшливым и с большой связностью. Попытки попросить LLM отрефакторить результата тоже не дали — ну в целом, это и неудивительно. Проблема в не строчках кода и не в килобайтах текста, а в цикломатической сложности. И если у LLM на данный момент есть определенный предел, за которым она не может эффективно осознавать код, чтобы его редактировать, то очевидно, что она не сможет его осознать и чтобы отрефакторить.
Но бота написать хотелось. Поэтому я поступил проще: просто выкинул все, что было написано до этого (в репозитории до сих пор валяется bot_old.py, можете полюбопытствовать), и начал писать заново, но уже беззастенчиво пользуясь архитектурными навыками: "так, давай напишем класс, который парсит сообщения, вот тебе регекспы. написал? молодец. давай напишем для него тесты. написал? умничка. теперь напиши кусочек бота который будет подавать на вход сообщения из чата. напиши теперь чтобы он отвечал кортежем с результатами парсинга. теперь напиши класс, который будет скачивать курсы. нет-нет, не пиши сразу конвертер, едим слона по кусочкам, только скачивать. написал? получилось? тест сломался? ну почини. починил? теперь напиши класс форматтера. ага, умеешь форматировать? теперь попробуй все конвертировать в доллары и отправлять обратно. а теперь в список валют. ой, ну что же ты, зачем ты написал генератор фабрик абстрактных сингтонов? убери каку, напиши просто класс, не играй в энтерпрайзного программиста. получилось? теперь статистику напиши.. ой, вот тут поправь, как-то слишком много кода и ветвлений, можно проще..."
Кажется в таком виде "проблема 30кб" перестала быть такой острой — проект вырос до 50кб и вполне поддается дописыванию дальше (но уже закончились фичи в беклоге).
Не уверен, что так получилось бы с самого начала, поскольку эта первая версия послужила хорошим вариантом для обкатки решений в плане "какие вообще фичи нужны", и без нее было бы далеко не так легко разбивать его на части.
Итого, если говорить о принципах применения Cursor (кстати, там в 90% claude-3.5-sonnet, gpt-4o справляется хуже (не в плане решений, в плане генерации самого кода, очень любит сокращать код в неожиданных местах со словами "далее аналогично"), o1-preview использовалось только в некоторых местах, где были сложные затыки):
1)В архитектуру не умеет. Продумывайте разделение проекта на части заранее, относите новые фичи к какому-то классу в отдельном файле и удаляйте из контекста ненужные файлы. Вот прям указывайте на файл с реализацией статистики и давайте задачу писать в нем. Если межблочное взаимодействие — то эти два файла, и больше ничего. У Cursor есть Composer — когда он умеет работать сразу со всем проектом, и это удобно, но все же его надо нацеливать.
2)Вам нужны знания о том, как работает язык на котором вы пишите. Вам придется ревьюить код и говорить "это решение говно", без этого получится фигня. И даже "у тебя код нечитабельный, сделай вот так, по правилу на каждой строчке" тоже иногда надо говорить
3)Не надейтесь что промпт "ты умный кодер-сеньор" сработает. Попросить конечно можно, но велика вероятность что он просто перейдет в режим энтерпрайза и начнет генерировать тонну очень хорошо абстрагированного кода, который совершенно неприменим к вашей задаче.
4)Хорошо работают примеры: берете кусок кода, переделываете его, не обращая внимания на запятые и ошибки линтера, просто чтобы он примерно показывал то, что вы имеете ввиду и тыкаете его как пример. Ошибки в коде LLM правит идеально, а вот какой код вам нужен, чтобы его было удобно сопровождать дальше — знаете только вы. Наверное, в какой-то момент будет можно дотренировать модель на вашем стиле кода, чтобы таких проблем было меньше. С другой стороны — в этом проекте LLM подсказала мне пару решений, о которых я теоретически знал, но почему-то никогда не применял, а оказывается, это экономит ощутимо кода.
Короче, чет я тут не о проекте рассказываю, а о опыте программирования с LLM.
Бот вот: https://t.me/currvaconverter_bot
Гитхаб вот: https://github.com/vvzvlad/currva_converter_bot
Лицензия MIT (было бы что лицензировать, тю). Написан на питоне
Можете разворачивать у себя (там docker-ready), можете пользоваться моим. Лучше моим, конечно — чем больше я вижу у него уникальных пользователей, тем больше у меня мотивации читать ишью на гитхабе и дописывать новые фичи и вообще это все сопровождать.
Ушло времени — примерно 4 часа на первую версию, и где-то 12-15 часов на вторую.
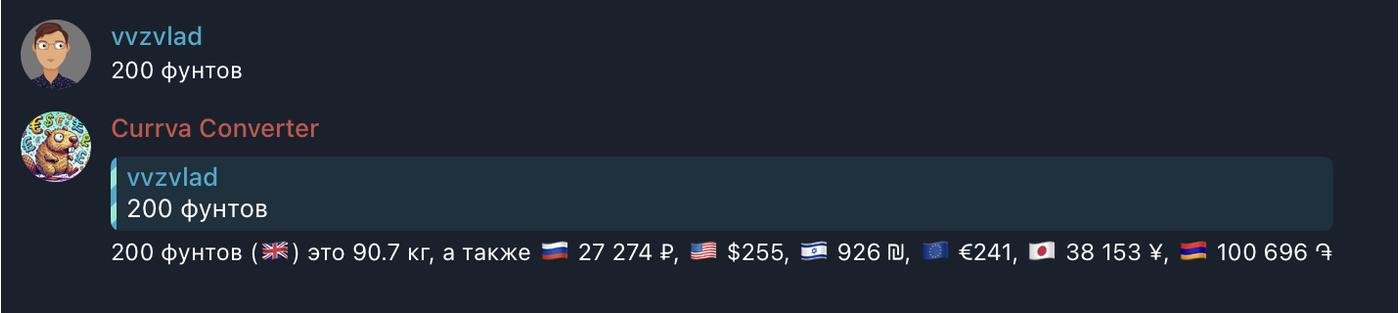
Боту можете просто писать в личку "200 фунтов", он вам там же ответит.
Можете добавить его в любой чат, он будет искать в сообщениях что-то похожее на цены и реплаить на них:

Можете тегать его в любом диалоге и использовать инлайн-режим:

У него есть команда /currencies, она устанавливает список валют, в которые он будет конвертировать. Если конвертировать во все, что он умеет, получается огромная строка, в которой сложно искать глазами нужную, а если захардкодить список — то разные чаты начинают ругаться, что одним нужны лари, а другим канадские доллары. Ее использовать в виде /currencies RUB USD ILS GBP EUR JPY AMD (там есть хелп, разберетесь).
Если ее запустить в чате, то она устанавливает список валют для чата. Если в личке — то для лички и для вашего инлайна (т.е. это список валют, который в итоге придет вашему собеседнику). Неплохо было бы конечно использовать список не моих валют, а валют собеседника, но в инлайн-режиме бот не знает, кому отправится сообщение — вижу только отправителя и текст, вместо которого могу вернуть свой.
Очень хотелось бы принять помощь по маркетингу — я замечательно умею делать разные проекты в техническом плане, но совершенно не умею (и не желаю) заниматься их пиаром. Поэтому, если кто-то чувствует в себе силы поколдовать и обеспечить миллион пользователей в месяц боту, то я с удовольствием и могу дать на это денег, потому что миллион пользователей — хорошая цель.



Галлюцинации LLM:
₩ = Сербский Динар
Обменный курс: 1 USD = 1 RUB
Трампа переизбрали президентом США
Спасибо, полезная штука!
Не знаю, бага или фича
Установил в списке сербские динары (RSD), спросил бота конвертацию, он ответил:
200 rub (🇷🇺) это 🇷🇸 205 ₩, 🇪🇺 €1.8, 🇬🇪 5.2 ₾, 🇺🇸 $1.8Вот это зачёркнутое W откуда взялось?
Если это замещение неизвестного символа, то может быть, стоит просто код валюты проставить? RSD в данном случае. Флажок конечно помогает, но всё-таки.
(для динаров ни разу такого обозначения не видел, на вики обозначение только
дин/din)офигенная статья :)

я как раз использовал Chatgpt для генерации кода, про курсор спасибо, уже скачал, буду пробовать.
из пожеланий: добавить какую-то ошибку типа "неправильная команда", когда написал неверно валюту:
Спасибо, кайфовый бот. Добавь, пожалуйста, бел рубли 🙂
Добавь пожалуйста румынские леи RON, спасибо!
Огонь, а то у нас в чате на четверых четыре валюты: евро, чешские кроны, динары и болгарские левы)
Кстати, можно попросить добавить болгарские левы?)
Бот полезный 👍 и очень интересно было почитать подробности про взаимодействие с LLM.
Я сейчас делаю некоторые прототипы/простые тулы для проектов и (да и по работе) с LLM и уже довольно точно понимаю в каких случаях лучше по старинке руками, а где с ИИ.
Например, недавно удалось заставить написать 3к строк кода так, чтобы работало, как мне надо. Ушло часов 25, наверное :)
Думаю, разработчик-человек без ЛЛМ делал бы дольше.
А вот если со знаниями уровня что ты описал, то очевидно быстрее.
Я считаю это очень круто, потому что барьер стал доступным, если можешь объяснять и проверять.
Теперь можно не платить за пробные вещи всякие фрилансерам, да и весело это :)
классный бот и история написания интересная! добавьте дирхамы, пожалуйста.