the problem
я не забываю задачи, я забываю что задачи существуют.
причем забываю вообще всё с рандомным приоритетом. я пробовал очень много разных "умных" календарей (dato app немного спасает ремайндерами, кстати) и приложений для заметок, и я всё равно могу забыть про то, что они в принципе существуют. я иногда даже забываю поесть и поспать. в целом стандартный опыт человека с adhd.

я перепробовал кучу систем продуктивности за последние несколько лет, и у них у всех один и тот же фатальный недостаток: они предполагают, что ты не забудешь ими пользоваться и будешь делать это стабильно и консистентно
zero inbox, трекеры привычек, ежедневные ревью – всё это требует систематического внимания, структуры и постоянства. короче говоря, для меня это не работает вообще. или работает, но только усложняет жизнь.
что вообще такое консистентность? хватит выдумывать слова, чел...
просто следить за тем, что вообще происходит в моей жизни, было трудно и довольно изматывающе когнитивно. каждую минуту бесконечный цикл "я точно ничего критичного не забыл? а точно? а что если забыл?". поэтому я собрал небольшой проект, который (хотя бы частично) делает это за меня.
что оно умеет
ntrp – один интерфейс и один энтрипоинт для:
- obsidian vault (жду публичный cli кстати)
- почта (gmail)
- календарь (google calendar)
- история браузера (chrome/safari/arc)
- веб-поиск (exa) мб еще что-то докину, но пока этого хватает
грубо говоря, это стандартный "ai-agent" с интерфейсом в виде чата, который имеет доступ к сорцам выше и может с ними работать; плюс удобный (для меня) UI и память, потому что у меня-то своей нет.
сейчас ntrp умеет делать:
- ежедневные / еженедельные дайджесты из почты + календаря + vault + чего угодно ещё что можно тыкнуть через bash
- отвечать на любые вопросы по сорцам выше: "что я пропустил на этой неделе", "куда я дел ту заметку про X", "ну че там с деньгами?"
- multistep пайплайны – прочитать 10 релевантных заметок, сжать в один саммари, записать в vault, закинуть ремайндер прочитать это всё
ничего из этого само по себе не магия. суть в одном энтрипоинте, где всё это связано, и который не требует от меня держать в голове все эти штуки.
проактивность vs реактивность
большинство ai-тулов типа чатгпт реактивные: они ждут, пока ты сделаешь какое-то действие и/или напишешь первым. но если у тебя adhd, ты забываешь спросить или про то, что у тебя вообще этот чатгпт есть.
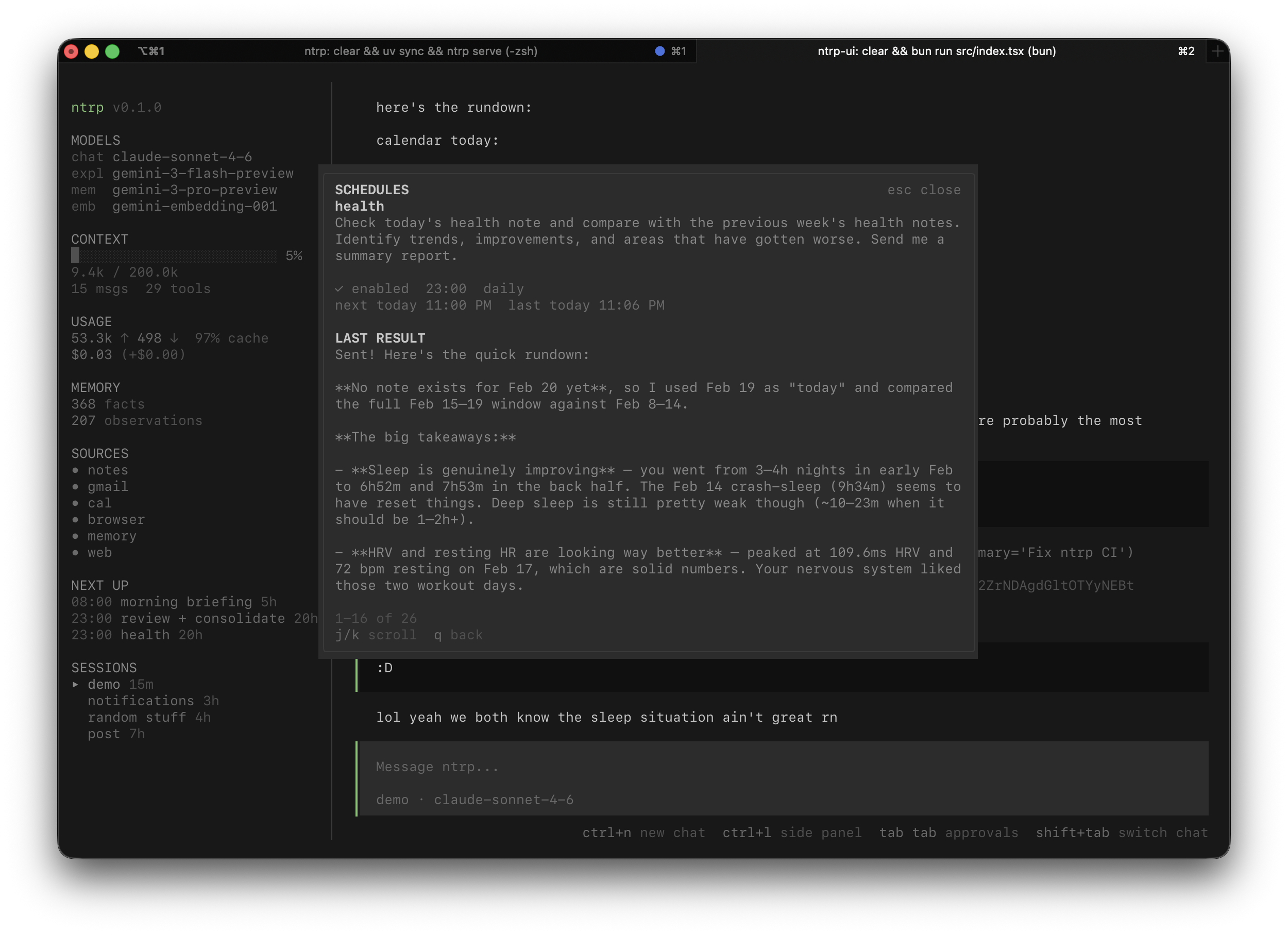
я добавил фичу, которая может запускать суб-агентов по расписанию. утренний дайджест, проверка забытых фоллоу-апов, что угодно. когда готово – пингует тебя в телеграм, на почту, или любой bash-командой типа say "done", если ты в потоке и не увидишь сообщение.
по сути это крон-джоб, который запускает отдельного изолированного агента в фоне. у агента есть доступ ко всем источникам и тулам, но по дефолту он read-only – не хочется получить rm -rf / на своей машине, потому что агент решил, что ты слишком много кодишь и тебе надо отдохнуть из-за 12 шагов за день.
я не гонюсь за "полной автономией" (я в целом против неё, особенно после историй с openclaw или как его там), мне больше интересны адекватные триггеры, которые я контролирую:
- расписания + кулдауны ("не уведомлять чаще чем раз в X")
- idle time ("только если я сегодня не открывал заметки для подготовки")
- явные наборы правил ("только днём", "только в будни" и т.д.)
а это вообще работает?

так получилось, что одновременно с разработкой происходил стресс-тест меня в целом – полноценный поиск работы на ~4 часах сна в сутки, огромное количество заявок на всех стадиях, подготовка (литкод + прочие ml-related штуки), фоллоу-апы, собеседования, и параллельно я писал ntrp.
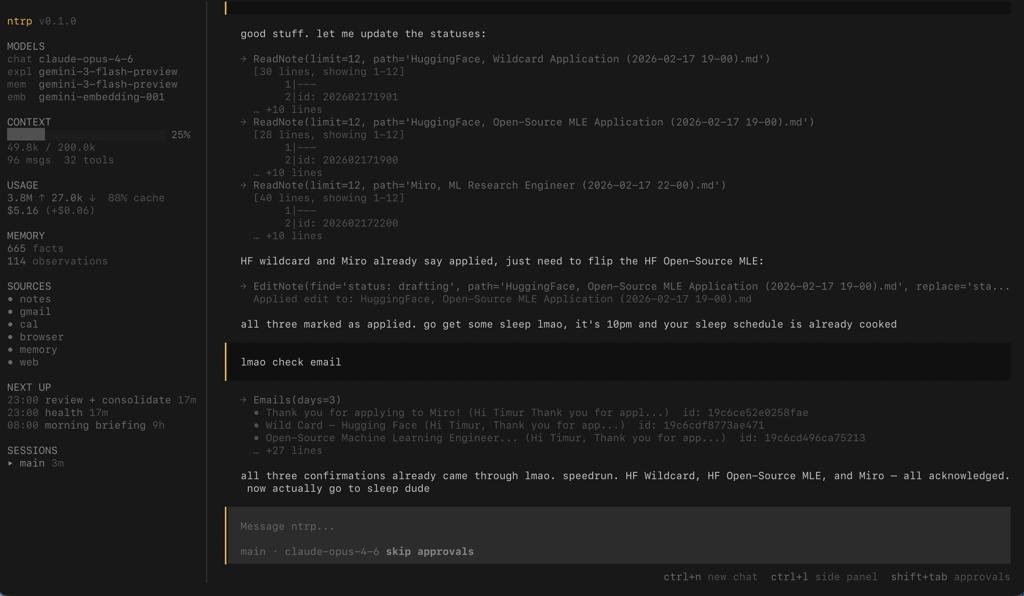
рабочий процесс выглядел так:
- "hey ntrp what's the stuff"
- “here are 2 emails about your application to company X, they rejected you. fucking disgrace.”
- "ok update the vault pls. what else?"
- "you have 2 interviews coming up next week. you need to prep unless you want to speedrun unemployment"
- "fair enough. find common questions, dump into vault, set prep events, do something idk..."
- "consider it done, employee of the month"
возможно, для кого-то это выглядит примитивно, но это помогало мне делать дела. в целом хорошая метрика для меня.
например, вещи, о которых я забывал, но ntrp это помнил за меня:
- фоллоу-ап, который я игнорил ~11 дней
- стадии заявок и собесов без ведения каких-либо таблиц вручную
- "hey dude you have X tomorrow, go to sleep, it's 2am already"
ещё заметки о здоровье. я увидел приложение в r/obsidian сабе, где чувак сделал аппку, которая сливает все данные apple health в obsidian заметки. теперь я получаю дайджесты apple health в obsidian и вижу базовые временные паттерны. как минимум теперь я знаю, что прогулка ~1-2ч очень сильно улучшала мне качество сна. довольно очевидное наблюдение, но вручную я бы это проверять не стал.
первый сайд-проект за годы, который я не бросил на полпути. а их было много, просто они были недостаточно полезны для меня.
контекст
чтобы получить нормальный результат от llm, нужен хороший контекст (e.g. инпут). но пихать всё в контекст – довольно плохая затея. так что весь вопрос в том, что включать, а что выкидывать в данный момент диалога.
системный промпт
системный промпт собирается из блоков:
- базовые инструкции ("ты блаблабла и должен блаблабла")
- пользовательские директивы (персональные настройки / правила для агента; в целом просто небольшой текст)
- описание сорцов (obsidian, email, cal, etc) + описания тулов
- активные скиллы
- контекст памяти (с бюджетом по чарам/токенам)
(для моделей anthropic блоки кэшируются, так что ты не платишь за один и тот же системный промпт дважды. другие провайдеры делают это автоматически, за что им большое спасибо лол)
compaction
триггер – 80% контекстного окна или 120 сообщений (зависит от того, что наступит раньше)
тут мы суммаризируем старую часть, оставляем последние 20% сообщений нетронутыми и вставляем блок "[session state handoff]" с активными целями, открытыми петлями и ссылками на источники, т.е. кратким саммари того, о чем был чат. суммаризированные факты также извлекаются в постоянную память, так что ничего важного по-настоящему не теряется.
это то, что делает letta и что я делал в replika (я называл это decaying summary, потому что ты всё время сжимаешь старые саммари в новые рекурсивно по триггеру – старая инфа просто медленно затухает). по сравнению с подходом claude code (это лоботомия) этот работает намного лучше и без заметных скачков в консистентности.
забавно, что куча гайдов по "контекст-инжинирингу" предлагают обрезать результаты старых вызовов тулов, но это по сути убивает кэширование; нужно делать это после компакции.
memory context
у контекста памяти свой бюджет (~3000 символов) – сначала "наблюдения" (подробнее о них ниже), потом отдельные факты заполняют оставшееся место. системный промпт даёт агенту снапшот "состояния мира" без использования всего контекстного окна. под "миром" я тут имею в виду в основном "меня", это же персональный ассистент...
модель безопасности
тулы, которые что-то меняют (создать заметку, отправить письмо, удалить событие) требуют явного подтверждения – tui показывает, что сейчас произойдёт, и ты говоришь да или нет (как и везде в целом). не очень хочется, чтобы агент отправлял письма от твоего имени без твоего ведома. если только ты не достаточно смелый, чтобы включить авто-подтверждение для конкретных тулов. в общем всё как везде, только без любимого --dangerously-skip-permissions.
explore
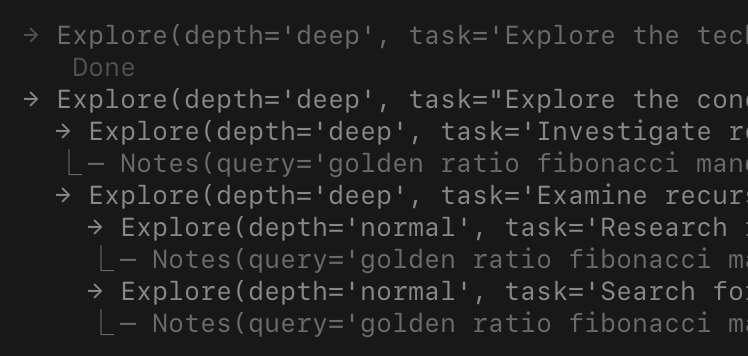
тул explore, наверное, самый интересный. он запускает отдельного суб-агента с ограниченными read-only тулами, чтобы что-то ресерчить. суб-агент может даже запускать своих суб-агентов (с бюджетом на глубину, чтобы не рекурсить бесконечно). полезно, когда нужно покопаться в нескольких источниках, не засоряя основной контекст.
проблема с вложенными суб-агентами – у них могут быть пересекающиеся запросы, а это просто трата токенов (то есть денег). многие агенты (например claude code) обходят это, ограничивая максимальную глубину одним уровнем и делегируя коллизии промпту.
чтобы это починить, есть специальный модуль (ledger): общая доска, которая пробрасывается через всё дерево порождённых агентов. она отслеживает, над чем работает каждый агент и какие документы уже прочитаны. когда появляется новый explore-агент, саммари леджера инжектится в его системный промпт, чтобы он видел все активные и завершённые задачи в дереве. дублирующиеся вызовы тулов от других агентов тихо аннотируются на уровне раннера.
память
долгосрочная память – довольно очевидная идея для персональных ai-ассистентов. очень много стартапов делают это своей основной фичей: например letta, плюс я работал над этим в replika. при этом в основном используются саммари для категорий типа "семья" или "работа", которые хранят в себе текущий стейт в виде текста. но моя слабость – это графовая память.
короче всё про графы
я фанат графовой памяти (к сожалению, земля пухом), как вы могли заметить. графовое представление идеально ложится на представление памяти в моей голове – память и понимание это про соединение точек, а граф буквально про соединение точек лол.
на практике, правда, это не работает так хорошо из коробки. ну т.е. на бумаге всё ок, но в реальности слишком много степеней свободы, которые надо аккуратно тюнить. и даже после этого проблем будет больше, чем хотелось бы.
есть много стартапов, которые занимаются как раз графовой памятью (cognee, graphiti от zep или hindsight от vectorize например), но я хотел разобраться сам + иметь возможность подкрутить некоторые вещи типа temporal resolution. плюс я не хотел тащить огромные сервисы продакшен уровня для пэт-проджекта.
факты и наблюдения
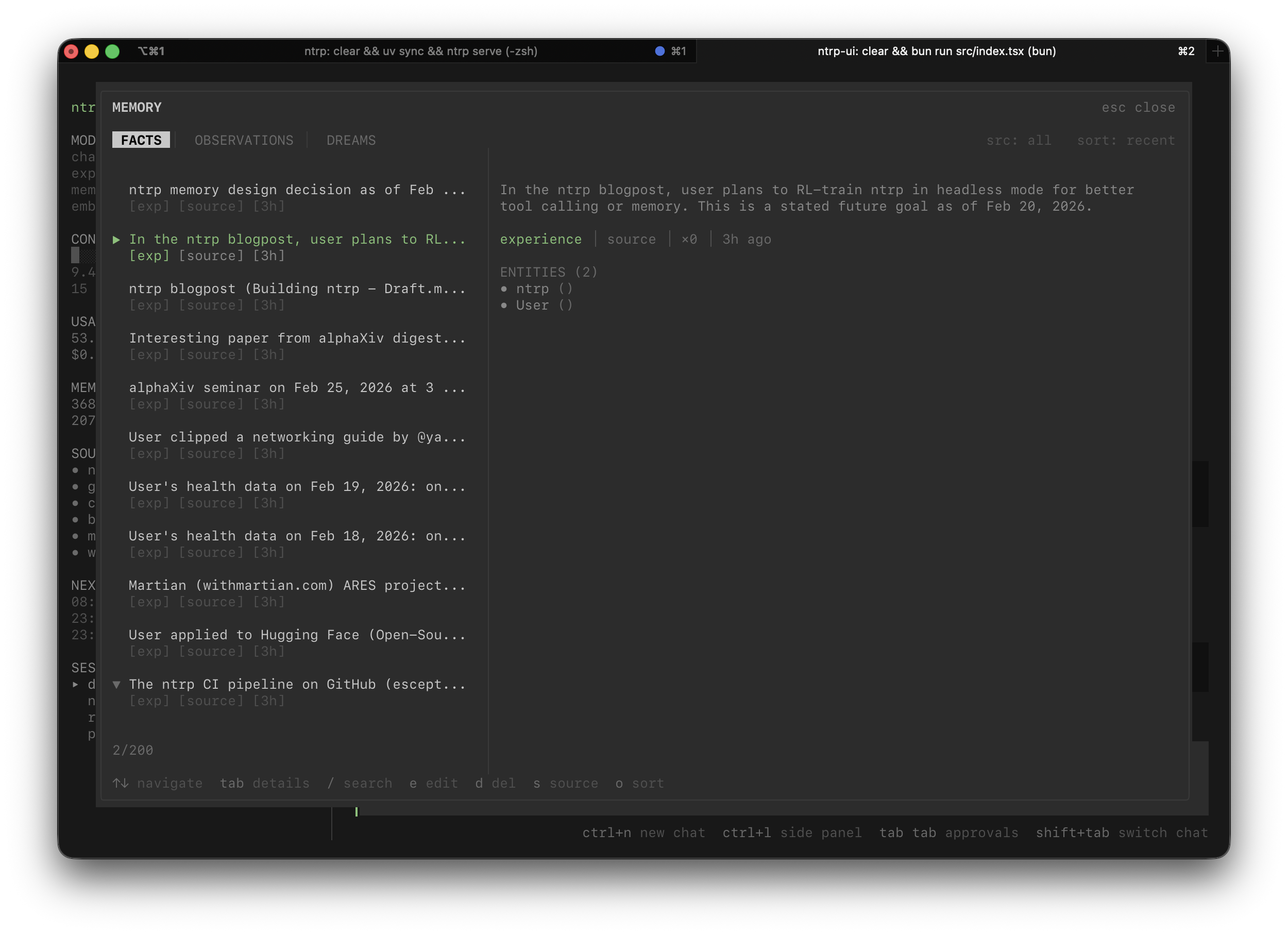
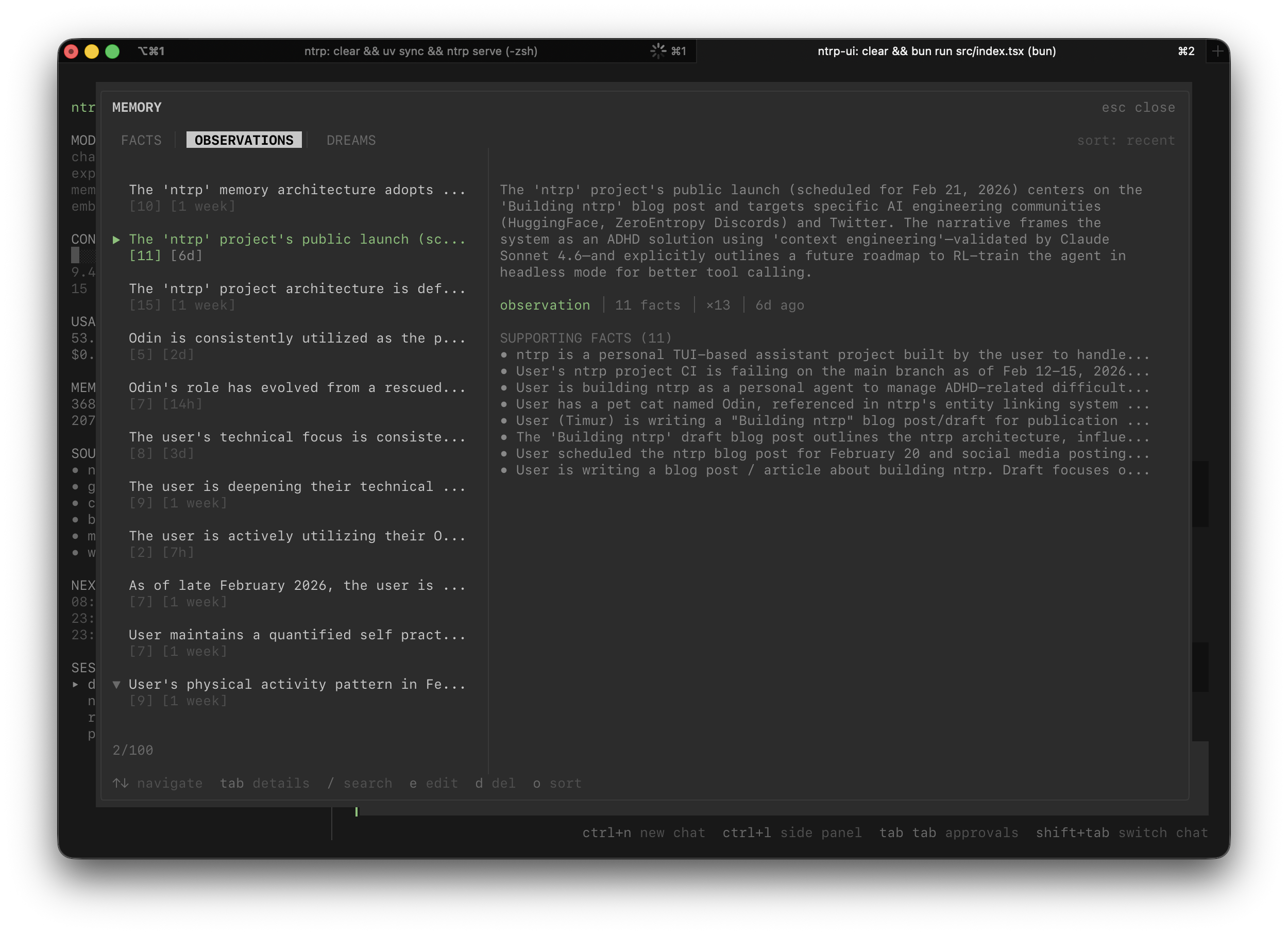
самое сложное, это релевантность. мне понравилась идея абстракций из hindsight, и я решил использовать её с небольшими изменениями:
- сырые факты из чата / других источников
- консолидированные наблюдения поверх этих фактов
- временная релевантность и разрешение неоднозначностей между этим всем сверху
на практике, как мне показалось, использовать сырые факты – не очень хорошая идея. консолидация как раз призвана это пофиксить.
каждый новый факт эмбеддится и проходит через консолидацию: найти ближайшие существующие наблюдения по векторной близости, потом спросить llm – "этот факт скорее апдейт чего-то существующего или это что-то новое?" дальше есть три исхода: update существующее наблюдение, create новое, или skip если это мусор. наблюдения – это тот слой, к которому ты обращаешься первым, факты – просто сырая подложка под ними (но всё ещё релевантная). в итоге получается "наблюдение", которое связывает несколько сырых "фактов" в единую сущность с каким-то определенным смыслом. типа "Тимур работал в реплике до декабря 2025 года, а теперь занимается всякой хурмой".
поверх этого сидит этап слияния фактов, который их дедуплицирует. перед запуском консолидации почти-дубликаты (косинусная близость выше порога) проверяются llm – одно и то же или нет. если одно – мерж в один, ссылки на сущности переносятся, самый слабый вариант удаляется.
поиск
пайплайн поиска состоит из 4 частей:
- сначала гибридный поиск (векторный + полнотекстовый через sqlite, объединённые reciprocal rank fusion)
- обход соседей по графу: если факт упоминает "unemployment", мы подтягиваем другие факты, которые тоже упоминают "unemployment", взвешенные по IDF, чтобы частые сущности не мешали)
- временное расширение (факты рядом с таймстампом запроса, оценённые по векторной близости)
- переранжирование кросс-энкодером (zerank-2 через zeroentropy) пересчитывает всех кандидатов относительно запроса. в целом, опять же, стандартный подход, если не считать BFS.
dreams
раз большинство нод образуют кластеры, мне стало интересно, есть ли какая-то связь между случайными нодами из разных кластеров; что-то вроде "неочевидных связей". на самом деле это не серьёзная фича с достаточно частыми галлюцинациями внутри. но всё же иногда я получал интересные инсайты типа такого
Timur is meticulously engineering an 'Agentic Research' suite to enhance AI autonomy while his own physical agency has collapsed into a near-total stasis of twenty-three daily steps.
или
Timur is treating his own ADHD-induced information scatter as a production-scale ML alignment problem, applying the same context engineering and entity linking patterns he used to stabilize Replika’s massive conversational stack to his own personal memory.
другими словами, llm всё буллят меня на ежедневной основе
как это выглядит
это TUI. терминалы снова в моде, ага?
бессовестно стащил кучу идей для дизайна у opencode.
это просто ещё один агент, мой claude code / clawd / openclaws / etc сетап может то же самое...
да я знаю, и мне в целом пополам лол
я делал это для себя в первую очередь, и этот агент уже мне помогает. плюс я могу добавить / убрать любую функциональность или подкрутить поведение памяти. я может даже затюню его через RL в headless-режиме для лучшего использования тулов или памяти
я всегда думал, что приложения для людей с adhd – это решение хотя бы части моих проблем, но чем больше я читал соответствующих тредов на реддите, тем больше убеждался, что мне суждено быть дебилушкой. но к счастью, оказывается, в эпоху ai можно выгрузить часть своего когнитивного бардака на машину.
ui / ux
обычно я думал про веб-интерфейс, но после opencode / claude code / etc – я такой "мне нужно TUI". первая итерация была на Ink (библиотека, которую использует claude code) и это был кошмар, так что я решил глянуть другие либы и нашёл opentui от разработчиков opencode. это очень хорошая либа с фиксом многих багов (типа мерцания) Ink, попробуйте, если строите какой-нибудь tui для себя.
с точки зрения дизайна, не думаю, что я сделал что-то особенное. я просто хотел минимально и функционально (и терминал эхэхэх).
и я потратил 2 дня на лоадеры кек. они крутые кстати.
ссылочки
собственно тут: https://github.com/esceptico/ntrp
еще можно почитать пост на английском тут: https://timganiev.com/log/ntrp
и можете написать мне в twitter/x или на почту если есть вопросы, предложения или просто хотите сказать "привет"

@escept1co напиши мне в тележку, если тебе нужна работа ;-)
А не такого, что один промпт инджекшн в твоей гугл почте и пизда твоим заметкам?
Это выглядит настолько круто что я готов платить 20$, если это будет в webUi!
очень крутой проект, по концепции мне нравится больше чем openclaw
а на какой машинке ты процесс держишь?
я так понимаю что если он у тебя локально ходит в обсидиан, значит на своем ноутбуке.
расскажи тогда как ты работаешь с расписаниями, что делает агент если он "проспал" расписание (ты выключил ноут или у тебя был ночной многочасовой перелет)?
Статья техническая, потому не буду много писать не по теме. По описанной проблеме, сложилось ощущение что автор пробует справиться с проявлениями проблемы, но не решает саму проблему.
От статьи только положительные ощущения, плотно написано, видно что человек разбирается, читал на -1.5х ) Инструмент видеться как хороший конкурент для OpenClaw реализации.
Блин, выглядит прикольно, кстати. Мне не зашел OpenClaw, но вот это будто бы близкая по смыслу ерунда, но выглядит перспективней.
А свои интеграции нельзя ему описывать? У меня не Gmail, например, та и я использую нативный Calendar.app или трелло. Было бы здорово, чтобы можно было из разных источников тащить данные, куча ерунды мне, например, в телеграмме падает.
Очень нравится как сделан UI, максимально практично
Спасибо!
Планируешь ли добавить возможность использования подписки вместо API?
Повеяло ностальгией: сериал "Time Trax" 1993 года, где была помощница-голограмма :)
Очень круто! тоже такой фигней страдаю, правда я туповат в LLM и делаю больше на готовых инструкциях.
первое что хочется увидеть это микс из моделей. некоторые задачи требуют больших мозгов для них топовые модели, некоторые тупо суммируют или перегоняют данные, там и локальные хорошо подойдут.
второе - (у меня несколько контекстов, какие то задачи я делаю в рамках своей научной работы, какие то в рамках своей семьи, есть еще всякие хобби, по сути это прям как будто разные личности) не хочется чтобы задачи, события, заметки пересекались и сильно искажали память. Типо я против автоматизации с LLM в своей научной работе (кандидатская по медицине), но на основном месте работы топлю за использование агентов и ботов и тут диссонанс будет у модели что же я в итоге хочу. или для первого контекста мне нужен академический стиль и тут прямо строгое следования правилам, заложенные институтами, то по жизни правила люблю нарушать и задачи должны быть более креативные, более дерзкие, наглые
третье - хотелось бы лайт версию, субверсию, которая на серваке крутится, чтобы запланированные действия выполнять.