Solovey: инсайды о проекте
Версия для публикации в Клубе.
Расскажите о себе и сути проекта?
Я развиваю Solovey: macOS-приложение для постобработки речи в офлайн-режиме.
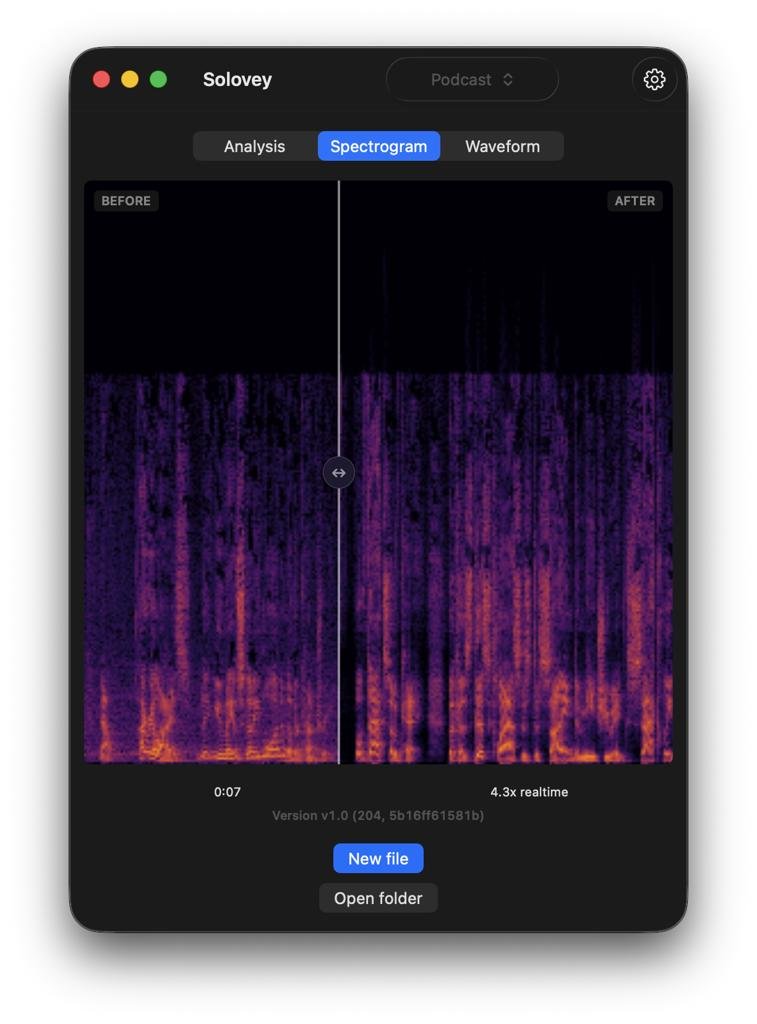
Основной сценарий простой и практичный: импорт аудио -> превью -> полная обработка -> экспорт.
Проект фокусируется именно на spoken-content: подкасты, интервью, лекции, озвучка.
Ключевая идея продукта сейчас:
- убрать шумы и гул,
- выровнять громкость до стабильного уровня,
- дать быстрый A/B-контроль результата до финального рендера.
Технически обработка идет локально на устройстве, без облачного рендера аудио.
Как появилась идея? Что вдохновило?
Идея появилась из очень практичного запроса. Друг показал Auphonic и пожаловался,
что ему нужна такая же удобная обработка, но офлайн. В тот момент я как раз делал
приложение для созвонов с шумоподавлением, и понял, что часть наработок можно
вынести в отдельный продукт. Так и появился Solovey: отдельное приложение именно
для локальной постобработки речи.
Что вошло в прототип и сколько времени на него было потрачено?
В ранний прототип вошел базовый рабочий цикл:
- Импорт аудиофайла.
- Построение превью-фрагмента и A/B прослушивание.
- Прогон через офлайн-пайплайн обработки речи.
- Экспорт итогового файла.
В первых итерациях основной ценностью были не «100 фич», а надежный end-to-end поток и повторяемый результат.
Первый прототип я собрал на Python примерно за 3 дня, после чего начал портировать
все в Swift для нативного macOS-приложения.
Какой технологический стек вы использовали? Почему?
Базовый стек проекта:
- SwiftUI + macOS для нативного приложения,
- Tuist для управления проектом и сборками,
- модульное ядро SoloveyCore для пайплайна и анализа,
- локальная обработка аудио через нативные DSP/аудио-компоненты,
- модели шумоподавления и адаптивной обработки речи в офлайн-сценарии.
Почему такой выбор:
- нативная производительность и стабильность на Mac,
- прозрачный контроль пайплайна обработки,
- отсутствие зависимости от облачной инфраструктуры в критичном аудиопути.
Как вы запускались и искали первых пользователей?
Пока целенаправленный запуск и поиск первых пользователей не делал.
Сейчас фокус на доводке качества и стабильности, чтобы на первых реальных тестах
люди увидели уже внятную ценность, а не «сырой концепт».
С какими самыми неожиданными трудностями пришлось столкнуться?
На технической стороне проект дал несколько нетривиальных уроков:
- адаптивные настройки, которые «на бумаге» выглядят правильно, могут ухудшать звук на узкополосных записях;
- пришлось вводить bandwidth-aware guardrails, чтобы не «восстанавливать шум как воздух»;
- проявлялись гонки между превью-рендером и переключением профилей;
- надежность пайплайна пришлось усиливать атомарной записью результатов и жесткой проверкой порядка стадий.
Главный вывод: в voice-processing критичны не только алгоритмы, но и инженерная дисциплина runtime-поведения.
Сколько потратили и заработали? Есть идеи как это можно монетизировать?
Пока по деньгам ноль: ни существенных внешних затрат, ни выручки
(если не считать мое собственное время разработки).
Монетизацию рассматриваю после валидации спроса: сначала получить стабильный
продукт и понятную обратную связь, затем выбирать модель (подписка/лицензия/про-уровень).
Какие планы на будущее?
Ближайший вектор развития продукта:
- получить фидбек от реальных пользователей,
- довести UX и качество обработки по этому фидбеку,
- выпустить релиз в App Store.
Нужны ли какие-то советы или помощь Клуба?
Да, нужен фидбек. В первую очередь интересна честная обратная связь по:
- реальному качеству результата на разных типах исходников,
- удобству сценария «импорт -> превью -> экспорт»,
- тому, за что вы лично были бы готовы платить в таком продукте.
