
Расскажите о себе и сути проекта?
Меня зовут Павел Яковлев, я вычислительный биолог из Петербурга, работаю в фарме.
Для начала — контекст для тех, кто далёк от молекулярной биологии. Белки, ДНК, лекарственные молекулы — это всё трёхмерные объекты, и чтобы с ними работать, нужно их как-то смотреть глазами: покрутить, покрасить по цепям, показать поверхность, посмотреть, как лиганд сидит в кармане рецептора. Для этого существуют молекулярные просмотрщики, и PyMOL — это безоговорочный король среди них. Если вы когда-нибудь видели красивую картинку белка в статье Nature, в учебнике по биохимии или в презентации фарм-компании — с вероятностью процентов 70 она сделана именно в PyMOL.
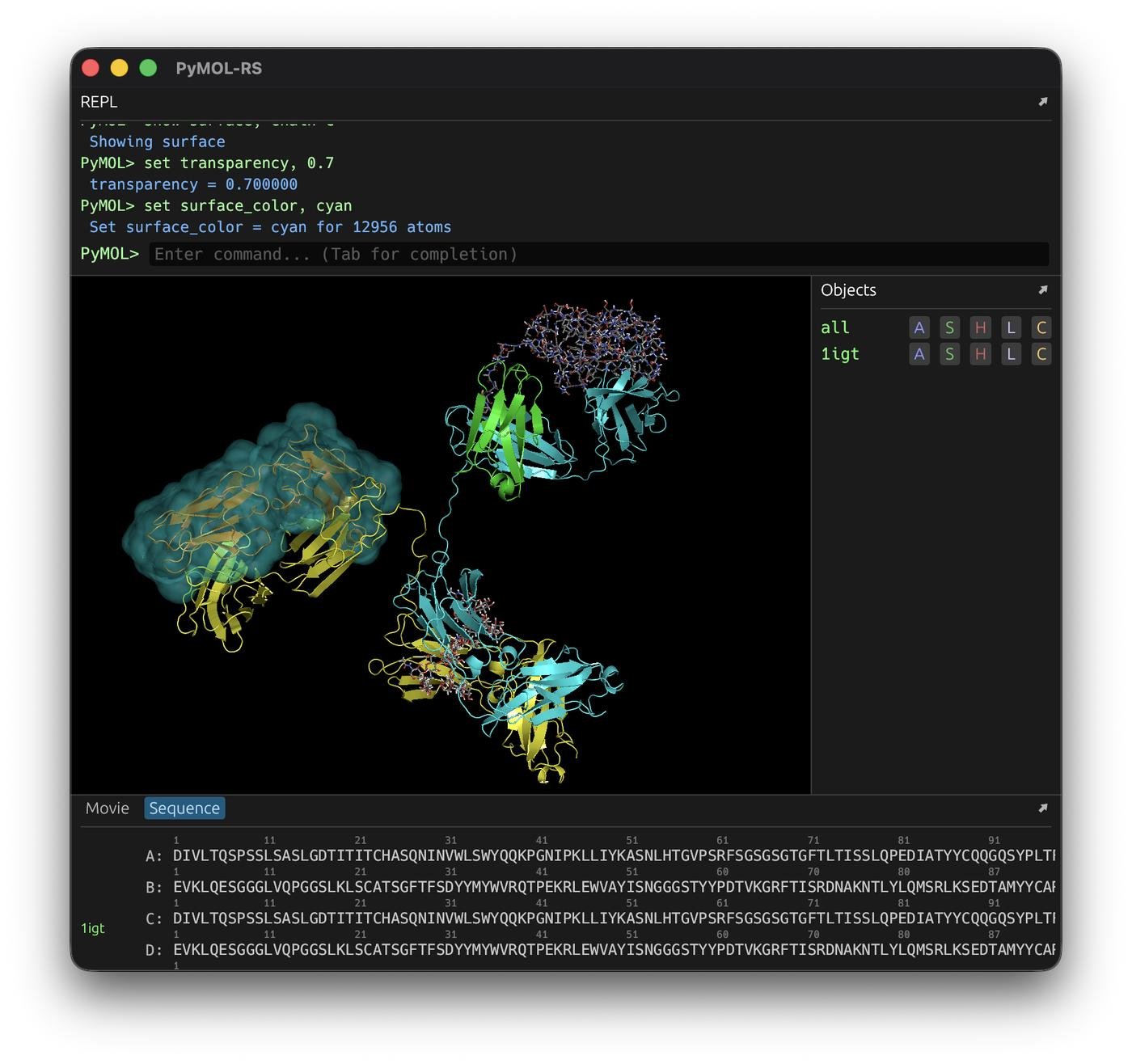
PyMOL появился в 2000 году, его создал Warren DeLano — один из тех людей, которые сделали структурную биологию визуальной. За 25 лет программа обросла невероятным количеством функций: от простого отображения шариков и палочек до продвинутого рей-трейсинга, молекулярных поверхностей, структурного выравнивания, поддержки сотен форматов файлов и собственного скриптового языка, на котором написаны тысячи лабораторных пайплайнов по всему миру.
DeLano покончил с собой в 2009 году (по этому поводу среди структурных биологов много грустного черного юмора), и сейчас коммерческую версию развивает Schrödinger, а open-source версия тихо стагнирует.
PyMOL-RS — это полная переписка PyMOL с нуля на Rust. Тот же командный язык, те же workflow, к которым привыкли тысячи учёных, но внутри — современный движок на WebGPU вместо OpenGL 2.x из начала нулевых, memory safety вместо ручного управления памятью на C, и модульная система из независимых крейтов вместо монолитной кодовой базы, копившейся 25 лет. И, конечно, новые фишки.
А ещё этот проект написан почти целиком с помощью Claude Code и является моим первым столь масштабным опытом вайб-кодинга проекта, который уже перевалил за 65 тысяч строк кода. Так что этот пост не про хвастовство классным проектом, а про опыт использования Claude Code в реально большом и алгоритмически сложном проекте и том, как не повторить участь Уоррена, работая с молекулярной визуализацией.
Как появилась идея? Что вдохновило?
На старый Новый год мы неудачно поели утки по-пекински и свалились на две недели с острым сальмонеллёзом. Когда спустя несколько дней я похудел на 5 кг, но уже перестал жить между унитазом и кроватью, а сознание ко мне вернулось, я понял, что у меня впервые за несколько лет появилось достаточно свободного времени для pet-проекта.
Если серьёзно, мотивация накопилась задолго до утки. Поставить open-source версию PyMOL — это отдельная боль. Schrödinger делает всё, чтобы никто не распространял бинарники (а вместо этого покупал коммерческую версию). При этом сборка из исходников как будто намеренно сделана максимально болезненной, а ещё требует установки кучи зависимостей. Добрые люди сделали формулу для Homebrew, но она тянет за собой несколько десятков дополнительных пакетов, которые начинают конфликтовать по версиям и добавляют хаоса в систему. Если этого мало, сверху идёт набор ограничений и проблем, которые не решаются годами, как, например, сломанная интеграция с Jupyter на маках.
Коммерческая версия от Schrödinger не сильно решает эти проблемы. Релизы прибиты гвоздями к той версии Python, с которой поставляются, выходят редко (уже почти год не было новых). Версии под Apple Silicon нет до сих пор, хотя macOS Tahoe как будто бы последняя версия, поддерживающая Intel-маки. Отдельная боль — это интерфейс. Научные сотрудники привыкли страдать, но здесь какой-то перебор. Мне реально проще написать несколько команд на встроенном скриптовом языке, чем хоть что-то накликать в нём мышкой. Кажется, так быть не должно.
В общем, продукт велик и могуч, но как будто бы мёртв.
И это — типичная история для научного ПО в целом. Учёные привыкли, что их инструменты неудобны, плохо выглядят и медленно работают. Наука — это про результаты и жертвы ради их достижения, а не про создание среды, которая бы способствовала лучшему творчеству. Вы бы видели интерфейсы софта для рентгеноструктурного анализа или молекулярной динамики. Люди буквально мирятся с тем, что инструмент, которым они пользуются каждый день, выглядит и ведёт себя так, будто его делали для осминогоподобных марсиан. И это не просто бытовое неудобство — это реально тормозит науку, потому что исследователь тратит часы на борьбу с софтом вместо того, чтобы думать о биологии.
Я и раньше экспериментировал с прикручиванием AI к PyMOL — несколько лет назад написал небольшой плагин под названием pymol-gpt, который встраивал ChatGPT прямо в интерфейс PyMOL. Но тут созрела идея поинтереснее: а что если взять и просто переписать всё целиком, сделав его так, как я хочу?
Что вошло в прототип и сколько времени на него было потрачено?
Полтора месяца от первого коммита до v0.1.0. Команда: я и Claude Code. Ну, и ещё Google Gemini на этапе планирования.
Начал я с того, что несколько дней обсуждал архитектуру оригинального PyMOL с Gemini. Мы разбирали исходный код, я задавал вопросы, Gemini помогал формулировать решения. В итоге получился документ на ~100 КБ, детально описывающий, что я хочу получить на выходе: какие крейты, какие зависимости между ними, какие библиотеки использовать, как должна выглядеть система рендеринга. Я правил его руками и дописывал. Этот документ потом стал фундаментом всей разработки.
На ранних этапах я подсовывал этот документ Claude Code целиком и формировал отдельный промпт для каждого модуля. Выглядело это примерно так: «Вот общая архитектура проекта (те самые 100 КБ). Сейчас нужно написать крейт pymol-select — парсер языка селекции атомов. Он должен поддерживать вот эти операторы, работать вот так, возвращать вот такие структуры». И Claude Code писал. Много. Быстро. И в целом хорошо.
Дальше, когда скелет проекта уже стоял, всё чаще стал полагаться на встроенный модуль планирования Claude Code, но всё равно обычно планирую очень подробно перед тем, как дать задачу. Типичный промпт для конкретной фичи — это не «сделай красиво», а детальное ТЗ:
Redesign Object List buttons (A, S, H, L, C):
Action menu
- zoom → `zoom {obj}`
- orient → `orient {obj}`
- center → `center {obj}`
Show menu
- as → opens submenu with representations (uses `show_as {rep}, {obj}`)
- separator
- lines / sticks
- separator
- cartoon / ribbon
- separator
- surface / mesh
...
Каждая кнопка, каждая команда, каждый разделитель. Чем подробнее промпт — тем ближе результат к тому, что ты хочешь. Это контринтуитивно, потому что кажется, что подробный промпт — это больше работы, но на практике один детальный промпт экономит пять итераций «нет, я имел в виду другое».
На выходе за полтора месяца: 13 независимых крейтов, 65+ тысяч строк кода. Полный PyMOL-совместимый язык селекции с 95+ ключевыми словами, парсеры для семи форматов файлов, GPU-рендеринг с импосторными шейдерами, рей-трейсинг, структурное выравнивание, Python API через PyO3.
Какой технологический стек вы использовали? Почему?
Rust + wgpu (WebGPU) + egui + PyO3. Но если честно, главный «технологический стек» — это Claude Code.
Rust выбран по двум причинам. Во-первых, memory safety без сборщика мусора — для визуализации молекул это критично, мы ворочаем миллионы атомов. Во-вторых, cargo build — и всё работает на любой платформе. Без танцев с зависимостями, без тридцати пакетов из Homebrew, без сломанных конфигов. Один бинарник — и всё. Именно то, чего так не хватает оригинальному PyMOL.
wgpu даёт доступ к современному графическому пайплайну. Мы рендерим сферы не сетками из треугольников, как в 2003 году, а GPU-импосторами — плоский квад, на котором шейдер рисует идеально гладкую сферу. Это и быстрее, и красивее.
egui — быстрый GUI без тонн бойлерплейта.
PyO3 — Python-биндинги, давая заветный и привычный from pymol_rs import cmd.
Теперь про Claude Code. Модель разработки выглядела так: я формулирую задачу, Claude Code пишет код, я делаю ревью, вношу правки руками или описываю текущие проблемы промптом, и идём в следующую итерацию. Описание проблем промптами я сохранял в отдельной папке и регулярно подсовывал её в Claude, как пример того, какие бывают косяки, и как мы их исправляли в прошлом. Как будто бы этот подход работает. Правда, контекст улетает очень быстро, почти два-три запроса, и 200k исчерпаны.
Для планирования и для того, чтобы «подумать об кого-то», я использую Gemini — он хорош для формирования больших структурированных промптов, когда нужно охватить целый модуль или архитектурное решение.
Что реально впечатлило: в процессе работы над молекулярными поверхностями Claude заметил, что в PyMOL алгоритм их построения реализован, мягко говоря, неоптимально. Я погуглил, нашёл статьи с более современными подходами, закинул их Claude, и мы вместе реализовали решение, которое оказалось примерно в 1000 раз быстрее оригинала. То, что в PyMOL считается несколько минут, у нас занимает меньше секунды. Это не преувеличение — это замер. Дальше мы воткнули параллелизацию через rayon, и генерация поверхности для полноразмерного белка из операции «пойти за кофе» превращается в «моргнуть и готово».
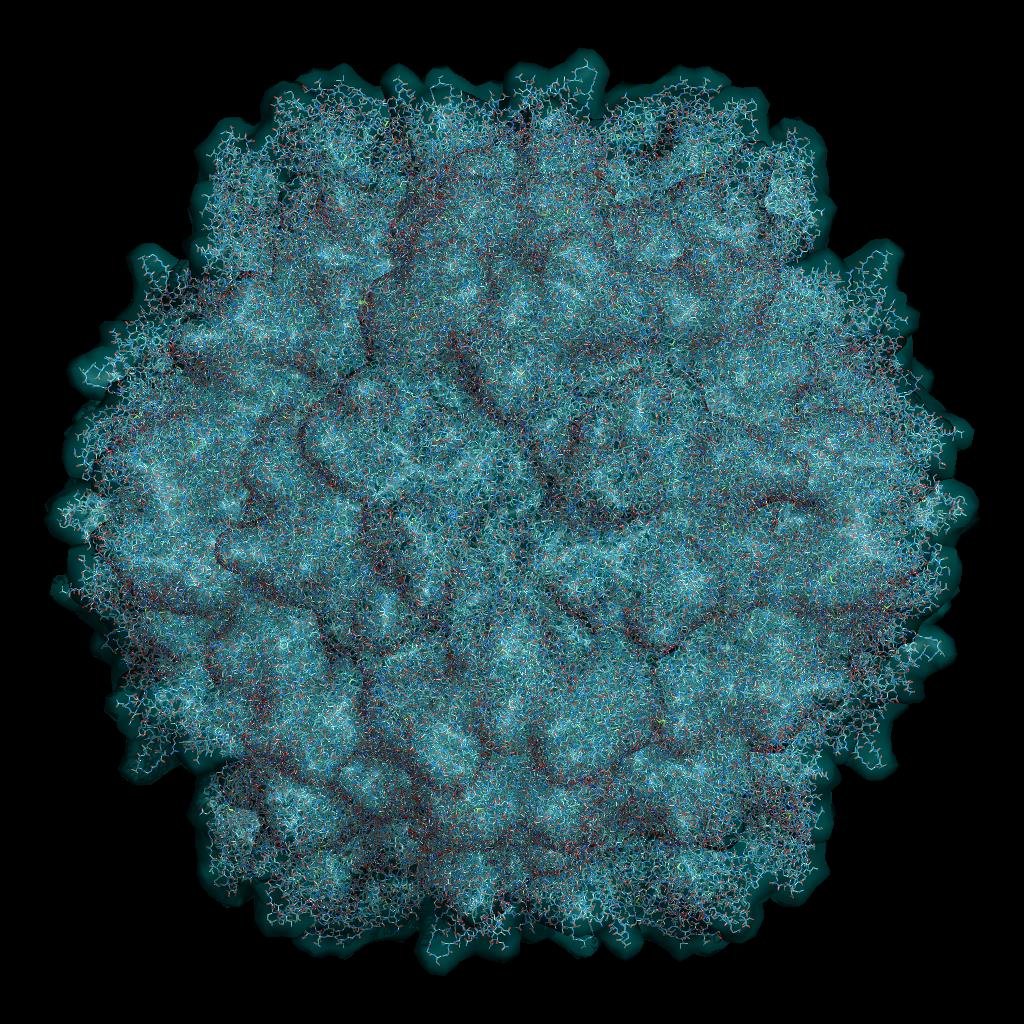
Другой пример — алгоритмы структурного выравнивания Kabsch и CE. Это математически плотные штуки: SVD-разложение, оптимальное вращение, динамическое программирование для поиска выравнивания. У нас был хороший референс в виде кода PyMOL, но всё равно — Claude Code выдал рабочую реализацию обоих алгоритмов на Rust с первой попытки.
Но переписать быстрее — это полдела. Хотелось ещё и красивее. У меня есть коллега Стас. Очень талантливый структурный биоинформатик, известный на всю компанию своими классными и понятными визуализациями. Вот только делает он их не в PyMOL, а в ChimeraX. Chimera, в отличие от PyMOL, как раз сделана для людей — у неё есть несколько очень удачных пресетов в стиле «нажми одну кнопку и получится красиво». Но ей не хватает гибкости и мощи, так что для реальной структурной работы, где не только смотрят глазками, но и измеряют-меняют-симулируют, она подходит хуже.
Во время обсуждения реализации с коллегами Стас посетовал, что в PyMOL ему даже выкрутив все возможные настройки не удаётся сделать так же красиво, как в Химере. Я пошёл читать код — и обнаружил, что там используется принципиально другая модель освещения, и действительно некоторые режимы просто изменением настроек получить нельзя. В итоге в PyMOL-RS теперь есть две модели освещения — classic (как в оригинальном PyMOL) и skripkin (вдохновлённая ChimeraX и пожеланиями Стаса Скрипкина). Переключается одной настройкой.

Вообще, классно, что у нас быстро появился чатик, где ребята делились какими-то болями, а вечером того же дня получали релиз, исправляющий эти боли. Когда между «хочу вот так» и «готово» проходит не полгода, а несколько часов — это меняет динамику целиком. И это тоже про то, каким научное ПО может быть, если его делать для людей, а не для галочки.
Как вы запускались и искали первых пользователей?
Выложил на GitHub, написал анонс на Hacker News (Show HN), запостил в свой телеграм-канал. На HN получил дельные комментарии от человека, который глубоко разбирается в молекулярных форматах и нашёл несколько тонких багов в парсере SDF. А ещё справедливо заметил, что некоторые алгоритмы (в частности, DSS — определение вторичной структуры) слишком похожи на оригинальный код PyMOL, и нужно аккуратнее с лицензированием. Это смотивировало переписать кое-какие куски с С-копипасты на идиоматичный Rust.
Пользовательская база пока маленькая, но самая важная — сотрудники департамента вычислительной биологии нашей компании. Но это нишевый продукт для структурных биологов, их вообще немного. Вот только в мире структурной биологии новый молекулярный вьюер — это событие, которое случается раз в десятилетие, а потому даже с небольшим количеством последователей я буду уже доволен.
С какими самыми неожиданными трудностями пришлось столкнуться?
Дольше всего — недели полторы из моих полутора месяцев — я мучился с отображением вторичных структур белков. Небольшое пояснение: белковая цепь в пространстве складывается в характерные элементы — альфа-спирали (закрученные винтом) и бета-листы (плоские стрелки). В PyMOL и любом молекулярном вьюере их принято рисовать красивыми лентами: спирали — толстыми цилиндрическими рулонами, листы — плоскими стрелками с заострением на конце, а соединяющие их петли — тонкими трубками. Это так называемое cartoon-представление, и оно должно выглядеть гладко, аккуратно и — самое сложное — правильно стыковаться на переходах между элементами.
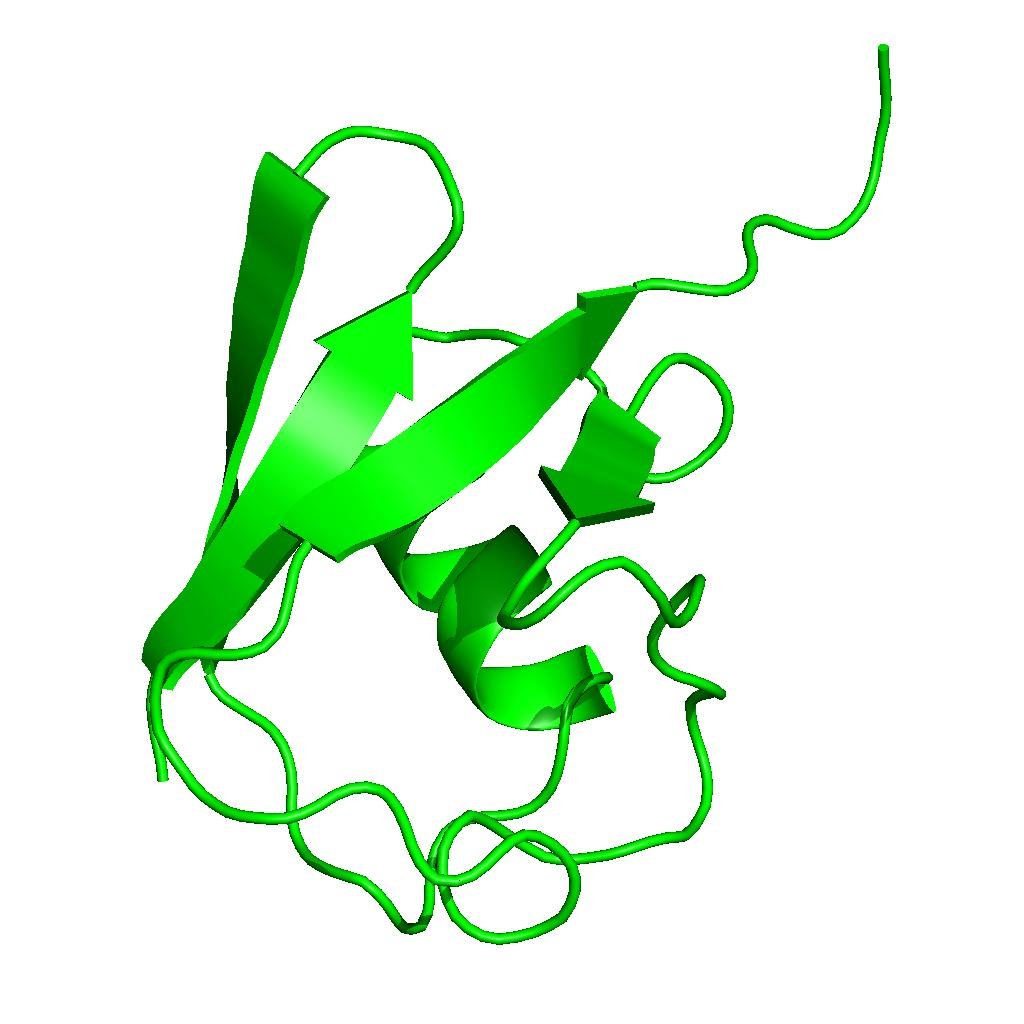
Проблема в том, что это задача не столько алгоритмическая, сколько геометрическая и визуальная. Нужно построить правильные полигоны для каждого типа структуры, сгладить переходы между ними, правильно развернуть нормали для освещения, обеспечить тейперинг (сужение) на концах стрелок бета-листов. Словами объяснить, как именно должен выглядеть стык спирали и петли — практически невозможно. Claude Code генерировал код, который компилировался и что-то рисовал, но результат каждый раз выглядел как макароны из адской кухни.

В какой-то момент я уже был готов сдаться. Я раз за разом показывал Claude Code скриншоты и уже не сдерживая эмоций писал, что всё это полный трэш. Claude отвечал, что "user seems to be frustrated...".
Спасло то, что я буквально взял бумагу и ручку и нарисовал, как именно должны выглядеть полигоны для каждого типа структуры, как стыковать фрагменты друг с другом, куда направлять нормали. Потом подробно описал всё это текстом, приложил фотографии рисунков — и только тогда мы смогли добиться результата.
Это, пожалуй, главный урок: есть вещи, которые проще написать руками, чем объяснить. Шейдеры, тонкая визуальная геометрия, нюансы освещения — всё это требует визуального мышления, которое пока не получается передать через промпт.
Вторая неожиданная трудность — архитектурная энтропия. Claude Code пишет код быстро и много, но у него нет вкуса к архитектуре. Дай ему волю — и он начнёт дублировать константы в пяти местах, создавать структуры-обёртки из одного поля, впихивать хаки в неожиданные модули. После каждой крупной фичи приходилось проводить сессию рефакторинга. Мой самый частый промпт за всё время разработки выглядел примерно так: «Посмотри на вот эти файлы. Здесь дублируется логика X, константы Y определены в трёх разных местах, структура Z бессмысленна. Вычисти».
Это создаёт интересную динамику: ты тратишь час на написание фичи и потом два часа на то, чтобы навести порядок после того, как она написана. Суммарно всё равно быстрее, чем писать руками, но далеко не так молниеносно, как может показаться со стороны.
И третья: деньги. Я начал с Cursor + Claude Opus и потратил подписку за 200 долларов за четыре дня (!!!). После этого перешёл на Claude Code с подпиской Max за 200 в месяц, и на ней живу до сих пор. Расход токенов на таком проекте колоссальный — длинные промпты, большой контекст, много итераций. Любая модель оплаты за токены оставила бы меня без штанов.
Сколько потратили и заработали? Есть идеи как это можно монетизировать?
Прямые расходы: $200/мес на Claude Max и ещё $200, сгоревшие за четыре героических дня в Cursor. Итого порядка $600.
Заработано: ноль. Проект под BSD 3-Clause лицензией, полностью открытый. Монетизировать в классическом смысле я не планирую — это инструмент для научного сообщества.
Но есть нюанс, связанный с модульной архитектурой. PyMOL-RS — это не монолит, а 13 независимых крейтов. Нужен парсер PDB для вашего биоинформатического тулкита? Подключаете pymol-io и pymol-mol, без всего остального GUI-балласта. Нужен язык селекции атомов для своего пайплайна? Берёте pymol-select. Это то, чего у оригинального PyMOL нет и никогда не будет — там монолит, и ты либо берёшь всё, либо ничего. В мире, где научные пайплайны всё чаще собираются из кубиков, иметь хорошую библиотеку для работы с молекулярными структурами — это всегда полезно.
Какие планы на будущее?
В ближайшем роадмапе: карты электронной плотности (isomesh/isosurface) — без них кристаллографы нас не полюбят, экспорт видео и группировка объектов. Хочется довести до ума поддержку .pse-сессий от оригинального PyMOL, чтобы люди могли безболезненно мигрировать — открыть свой старый сеанс работы и увидеть всё так же, как было. А ещё полностью переработать интеграцию с Python и, возможно, другими языками. Сейчас это слабое место.
В более отдалённой перспективе мечтаю про WASM-сборку и запуск в браузере — в виде jupyter-плагина или standalone web-сервиса. Rust и wgpu для этого идеально подходят, и это решило бы проблему «установить PyMOL — это приключение» раз и навсегда. Представьте: зашёл по ссылке, открыл структуру, покрутил, обработал, сгенерировал фильм и показал на конференции. Без установки, без зависимостей, без страданий.
А на более философском уровне — хочется показать, что научное ПО не обязано быть уродливым и неудобным. Что можно сделать инструмент, который уважает время исследователя. Что учёные заслуживают софт, сделанный для людей, а не для терминала из девяностых. Потому что когда твой инструмент не мешает тебе думать — ты думаешь лучше. И делаешь лучшую науку.
Нужны ли какие-то советы или помощь Клуба?
Я много пишу про отсутствие страданий, но я сам продукт системы. И точно не UI/UX-разработчик (да и не разработчик вообще уже много лет как). Так что я создал базу для построения лучшей (как мне кажется) платформы молекулярной визуализации. Но интерфейс нужно продумывать и рисовать, а я в этом слаб. Так что любые комментарии и рекомендации, как сделать реально удобно и красиво, очень приветствуются.
Ну и если среди вас есть структурные биологи, которые хотят потыкать — GitHub открыт: github.com/zmactep/pymol-rs.
Какой совет вы бы сами могли дать идущим по вашим стопам?
Первое и главное: AI-ассистенты для кодинга — это не «нажал кнопку и получил проект». Это мультипликатор вашей собственной экспертизы. Claude Code не знает, как правильно рендерить молекулярные поверхности или стыковать полигоны вторичных структур. Но если вы знаете и можете это описать — он напишет за вас тысячи строк качественного кода за часы вместо недель.
Из этого следует неочевидный вывод: вайб-кодинг работает тем лучше, чем глубже вы разбираетесь в предметной области. Это не инструмент для того, чтобы делать то, что вы не умеете. Это инструмент для того, чтобы делать то, что вы умеете, но в десять раз быстрее.
Конкретные советы:
- Вкладывайте время в планирование. Мой документ на 100 КБ с архитектурой — возможно, самая важная часть проекта. Без него Claude Code писал бы код, который потом пришлось бы выбрасывать.
- Не жалейте токенов на подробные промпты. Короткий промпт → неожиданный результат → больше итераций → больше токенов в итоге. Лучше один раз написать полтора экрана текста и получить то, что нужно.
- Закладывайте время на рефакторинг. После каждой большой фичи — сессия чистки. AI генерирует код быстро, но не всегда чисто. Архитектурная дисциплина — ваша ответственность, не его.
- Используйте разные модели для разных задач. Gemini — для планирования и обсуждений, Claude Code — для написания кода и рефакторинга. Каждая модель хороша в своём.
- Не бойтесь рисовать на бумажке. Серьёзно. Когда Claude Code не может понять, что вы хотите, проблема почти всегда в промпте, а не в модели. Иногда нужно сначала разобраться самому — ручкой на листе А4 — и только потом объяснять машине.
И, пожалуй, самое главное: не ешьте подозрительную утку по-пекински. Хотя, с другой стороны, без неё бы не было PyMOL-RS.
