
Расскажите о себе и сути проекта?
Всем привет, я Даня, и я люблю весёлые пет-проекты.
Open-source ИИ-караоке, позволяющее из папки с mp3 файлами получить работающее караоке:

Как появилась идея? Что вдохновило?
Я люблю делать пет-проекты. Особенно это стало весело после появления сильных LLMок — можно сделать что-то весёлое, не особо думая про качество кода и надёжность системы, как в рабочих проектах.
Караоке всегда притягивало меня, потому что я люблю музыку. Когда я узнал, что существуют нейросети, которые могут разделять музыку на инструментал и вокал, я побежал делать генерацию инструментальных дорожек для всех своих любимых песен с помощью Demucs и spleeter (актуальные модели на 2024 год).
Нулевой проект: инструментал-видео на ютубе
Я понял, что на это может быть спрос, и сделал скрипт, который генерит вот такие видео со статичной картинкой:
Я нагенерировал (скриптом) и загрузил (более сложным скриптом) больше тысячи таких видео на новый ютуб-канал и собрал почти миллион просмотров! Но, если кому интересно, мне это ничего не дало ни материально, ни в плане подписчиков телеграм-канала. Но было прикольно, что люди в комментариях радуются, что для их любимых треков есть караоке-версии хоть в каком-то качестве (моделька для разделения тогда работала не очень!)
Это была нулевая итерация караоке-поделок. Текст приходилось открывать самому.
Первый проект: accompanist
Потом я сделал новый, более похожий на караоке, проект, который имел web UI. Можно было ввести название альбома, он скачает его, разделит каждую песню на вокал/инструментал, скачает текст с Genius, можно петь караоке в целом.
У первой версии не хватало разметки текста по времени — был просто сплошной текст + instrumental-дорожка, надо мотать мышкой, неудобно! Хотелось, чтобы при воспроизведении трека показывались 2-3 строчки текущих, как в настоящем караоке.
Загвоздка в том, как получить эти тайминги для слов. Есть Musixmatch, у которого, например, Яндекс.Музыка покупает эти слова + тайминги. Но у них платный API, мне это не подходит, не весело.
Сначала я сделал ручной режим разметки песен. Чтобы получить караоке-версию, надо было включить трек и кликать мышкой на специальную кнопку, когда очередная строчка трека кончается. Получается разметка в виде джейсонки [{"text": "Строка один", "end_ts": 1.44}, {"text": "Вторая строчка песни", "end_ts": 5.22}, ...]
Что-то было в этом прикольное: шарм создания собственной коллекции избранных песен. Но, конечно, это очень трудоёмко. Да и сама система получилась громоздкой: ШЕСТЬ докер-контейнеров с не самым правильным compose-файлом.. (потому что UI был на JS, был бэкенд на питоне, были отдельные GPU-воркеры, и так далее)
Я пробовал STT модельки, чтобы сопоставить тайминги: брать куски по k секунд, транскрибировать, дальше сделать какой-то алгоритм, который используя текст и эти кусочки получает тайминги для каждой строчки, но у меня не получилось, и я забил.
Проект заглох, потому что вручную размечать каждый трек очень трудоёмко и скучно.
Текущий проект: ai-karaoke
Наконец-то мы добрались от предыстории к текущему проекту!
Про этот проект я снял пятиминутный ролик 👇, но и в посте сейчас примерно то же самое перескажу.
Учитывая опыт работы с караоке-подобными проектами выше, я смог за неделю навайбкодить идеальное для меня решение, о нём, собственно, этот пост.
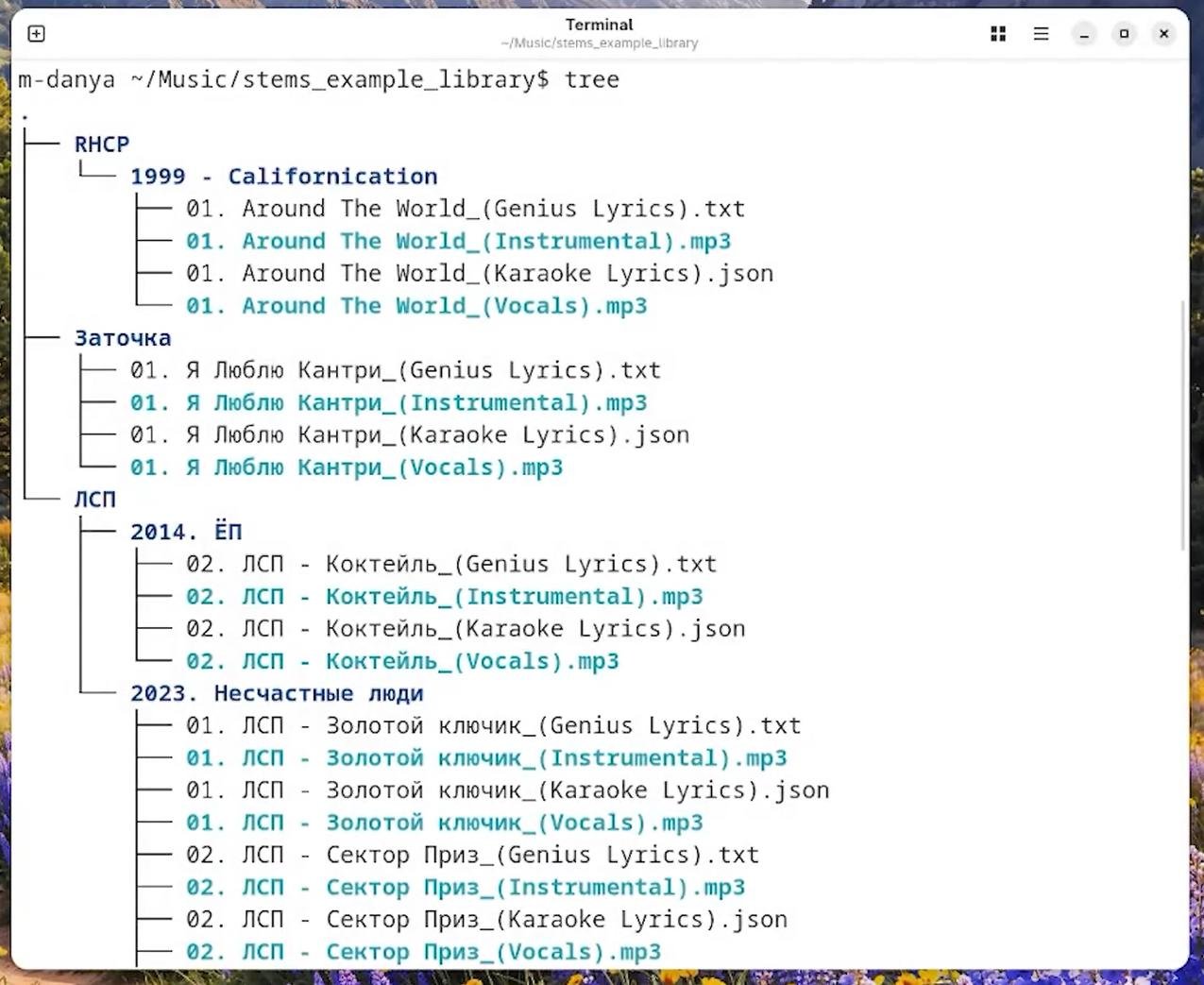
Как работает проект на примере папки с mp3
Берём папку с mp3шками:
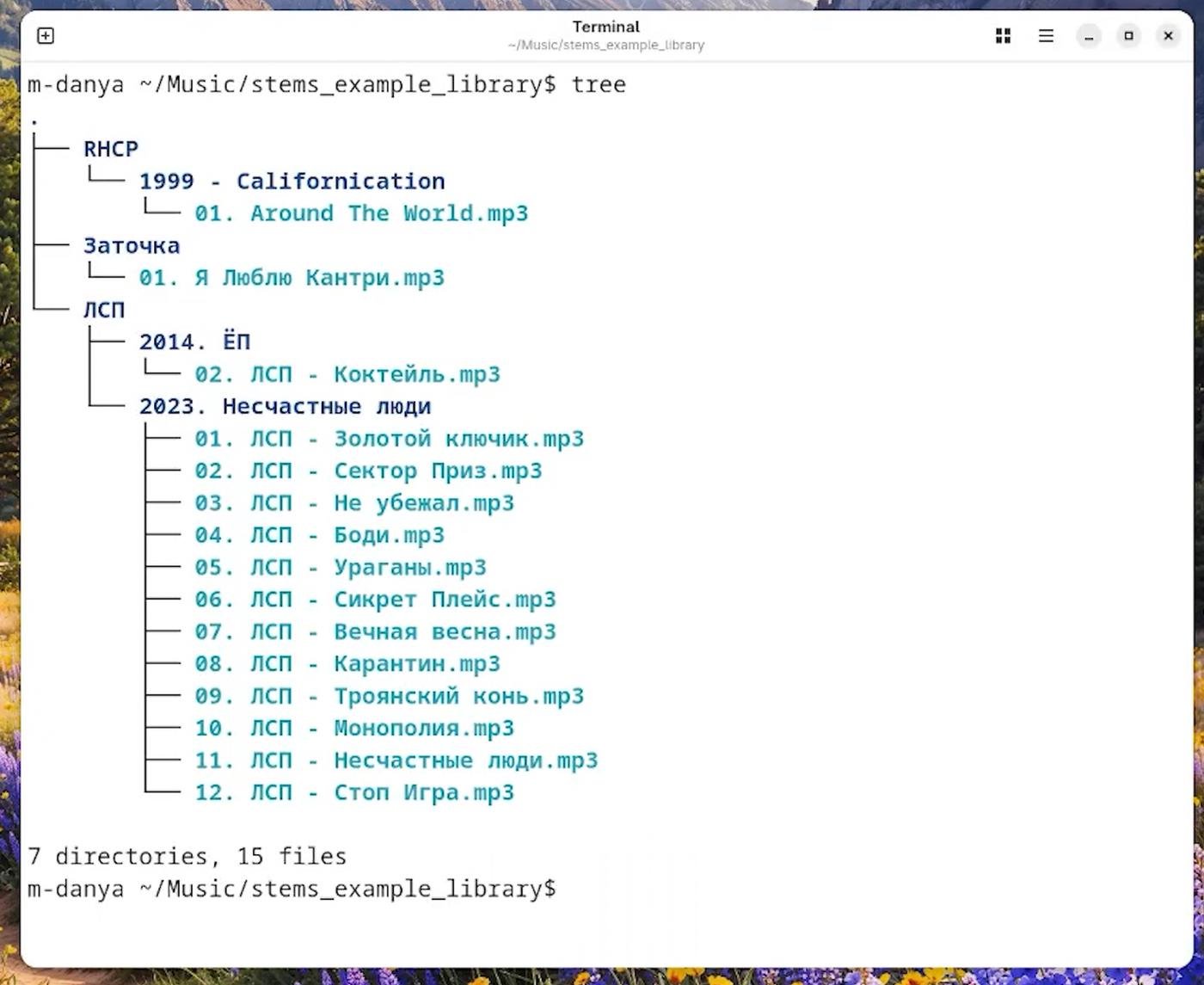
Указываем программе папку с mp3-файлами, ждём и получаем готовые караоке-треки! Всё!
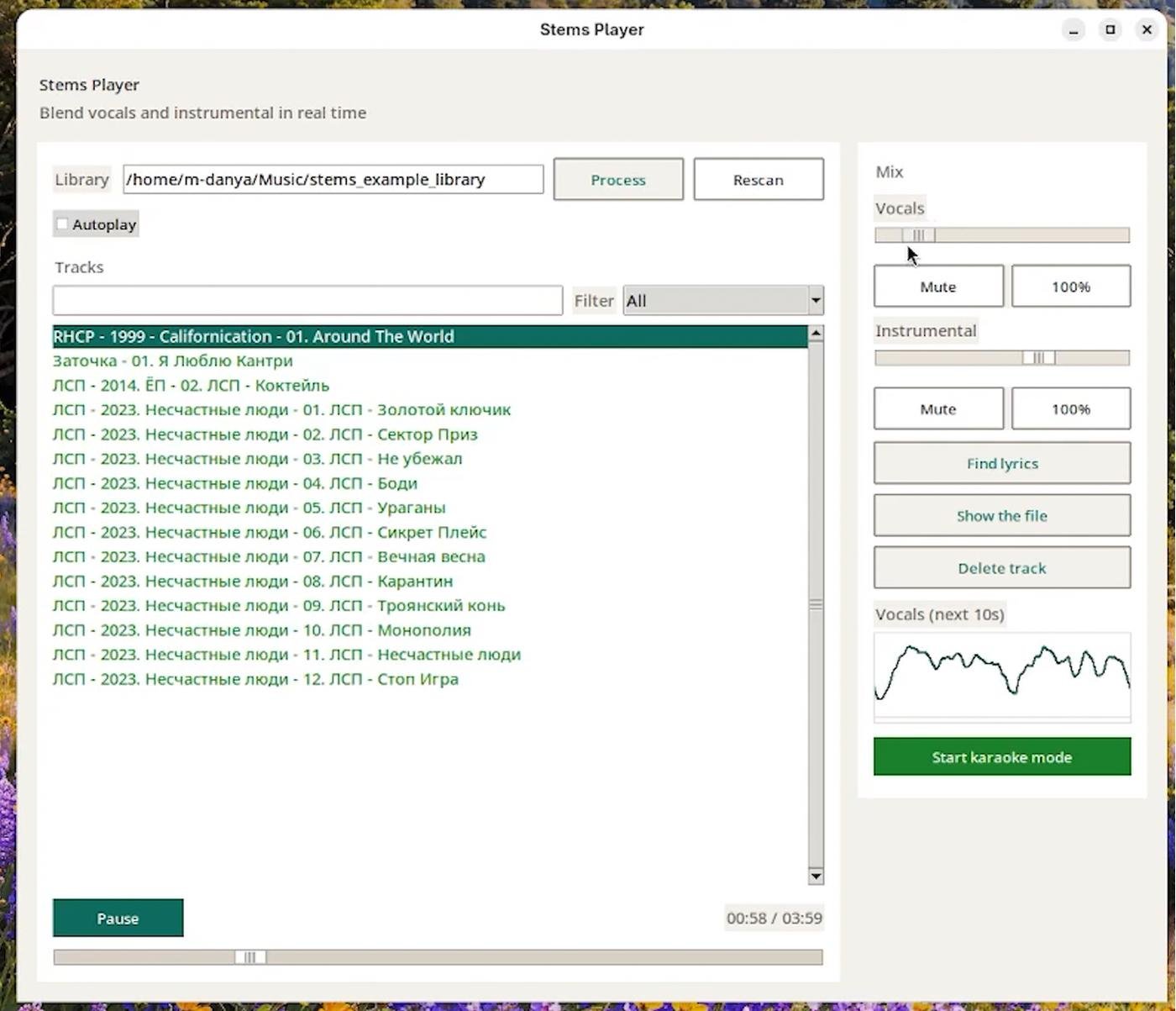
Это режим выбора песни и предпрослушивания. А вот как выглядит сам полноэкранный karaoke mode:
Можно регулировать громкость вокальной и инструментальной дорожки, свободно перематывать трек, получать удовольствие от караоке-версий своих любимых песен 🎶🕺💃
Процесс разработки
Я по сути уже знал, что мне нужно, это очень приятно сказалось на процессе вайб-кодинга: я мог чётко формулировать задачи для Codex.
Я нашёл готовые решения для всех трёх подзадач, которые нужно было решить для настоящего караоке.
Первая подзадача: разделение дорожек
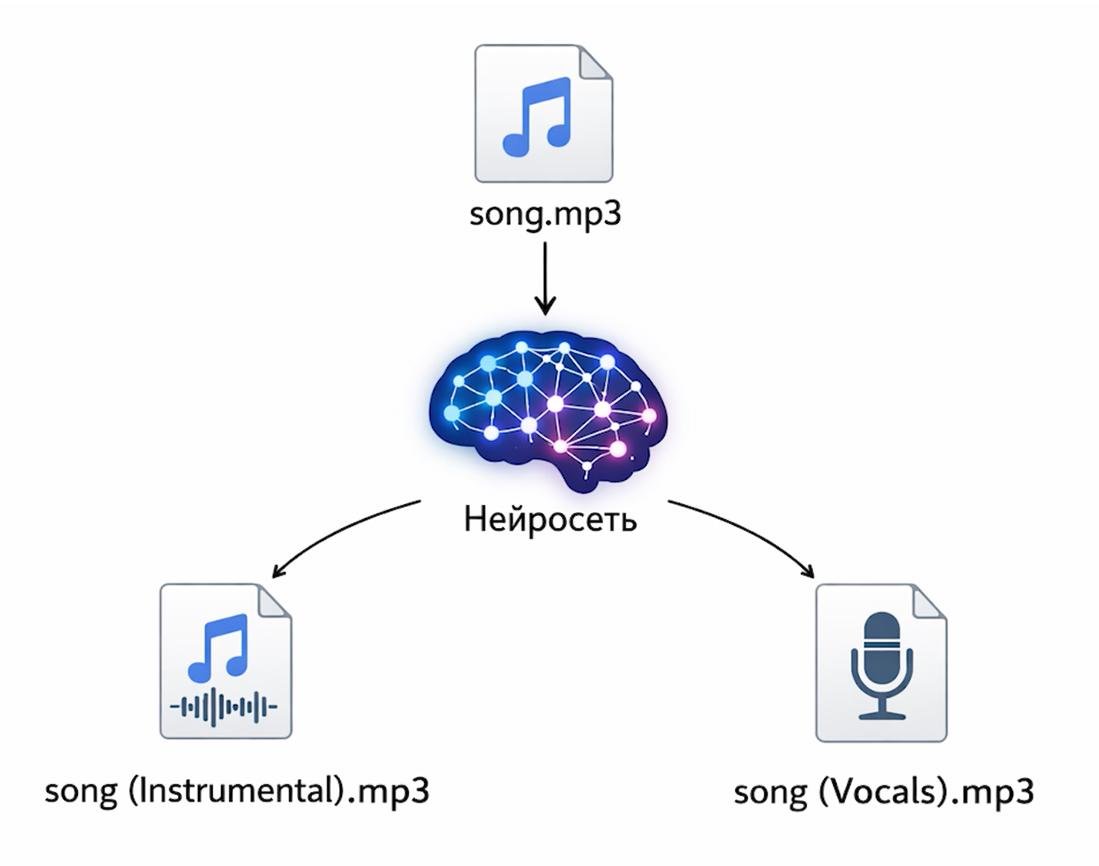
Нейросеть делит mp3 файл на вокальную и инструментальную дорожки. Я попросил Codex взять питон-скрипт https://github.com/nomadkaraoke/python-audio-separator и использовать его для решения этой задачи.
Главное, что я тут и дальше делал для успешного вайбкодинга — проектировал архитектуру так, чтобы она была максимально простой и поддерживаемой. Я чётко описывал, как должен выглядеть результат решённой подзадачи в плане конкретного выхлопа . Есть полуочевидная статья на эту тему: https://ianbull.com/posts/software-architecture. Например, для этой подзадачи я чётко описал, что надо
- рекурсивно просканировать папку с mp3
- проигнорировать уже обработанные файлы (то есть те, у которых и так есть суффиксы
_Instrumentalи_Vocalsв названии файла) - разделить трек на дорожки, назвать файлы как надо
- удалить оригинал
Если бы я этого не указал, кто знает, что бы придумал Codex в плане архитектуры решения здесь и дальше: вариантов много, и все они были бы менее удобными для меня. Так чтоесли в процессе постановки задачи всплывают какие-то хотелки — лучше их написать, чем потом удивляться тому, что придумал Codex. Кстати его planning mode, который сам придмуывает и задаёт уточняющие вопросы от этого частично спасает.
Вторая подзадача: получение текста песен
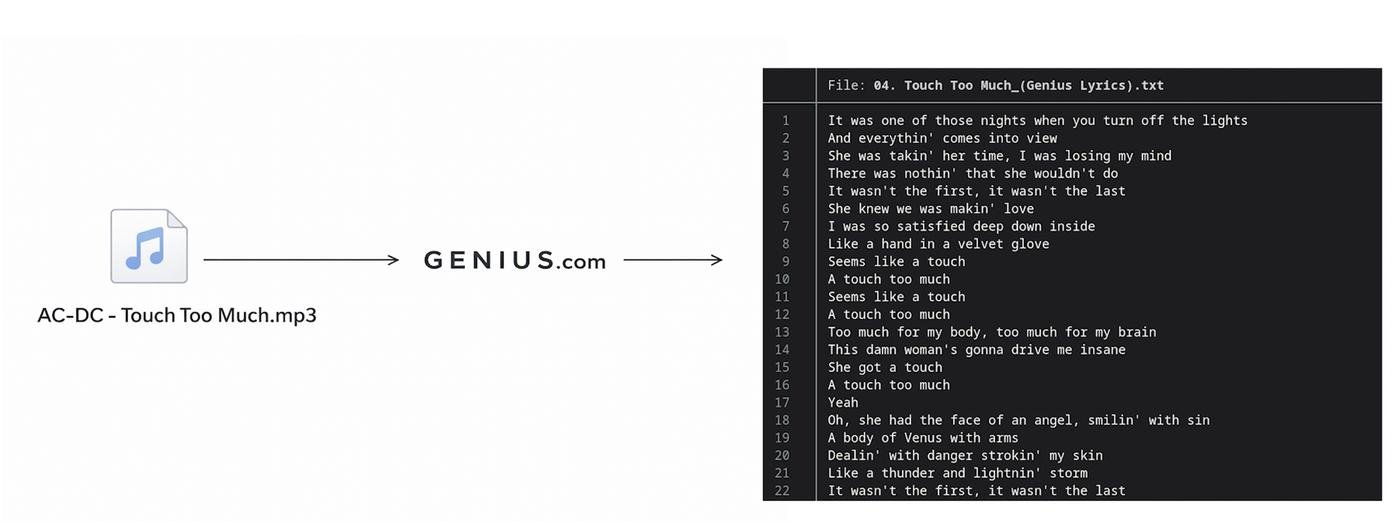
Я выбрал сайт Genius.com и питон-библиотеку для скачки текста оттуда через API: https://github.com/johnwmillr/LyricsGenius. Единственная заморочка - надо зарегаться и выпустить бесплатный API Access Token и положить его в .env (в ридми моего проекта это есть).
Третья подзадача: расставление таймкодов для каждого слова песни
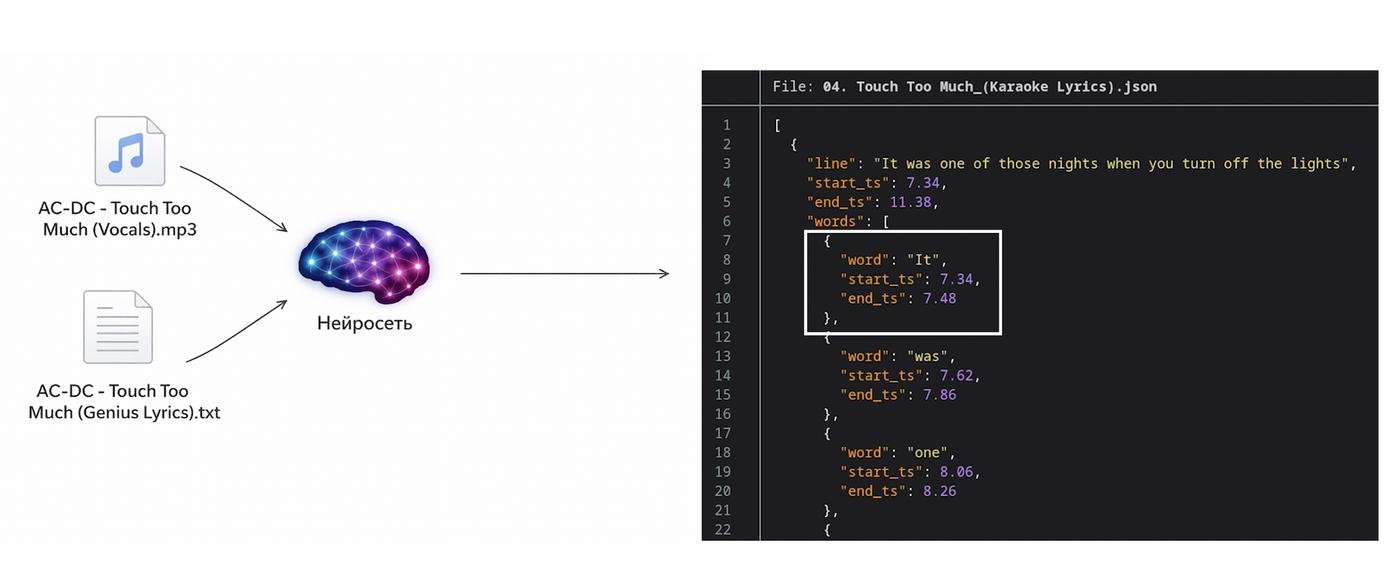
Самая интересная задача, которую я не мог решить в 2024.
В этот раз с ChatGPT я узнал, что такая задача назвается "forced alignment", и что она уже решена: https://github.com/MahmoudAshraf97/ctc-forced-aligner. Опять же, попросил codex встроить и это в мой проект, указав ему как конкретно я хочу чтобы выглядел output-формат. На скришоте можно заметить, что текст дублируется: в виде строчек с их таймкодами и в виде отдельных слов. Это несложно сделать на этом этапе, зато UI будет проще дальше писать.
Четвёртая подзадача: UI
Теперь, когда у нас есть все нужные файлы:
осталось просто это красиво отрендерить.
Из опыта accompanist я решил делать проект не в вебе, а в виде десктопного питон-приложения. Причины примерно две:
- мне не понравилась работа со звуком в JS. Даже запустить две дорожки одновременно уже не очень удобно было, все audio-related HTML-элементы скорее нацелены на то, чтобы ими управлял пользователь браузера, а не JS. Возможно это субъективно и от отсутствия опыта, но мне и не особо интересно в это погружаться)
- Я не хотел плодить сервисы. Центральная часть системы - processing треков, он работает на питоне. Поэтому минималистичным решением будет взять tkinter/qt и просто рядом сделать GUI. Один проект, красота, никаких контейнеров и сложных зависимостей.
Мне понравилось, что вайб-кодинг даёт возможность реализовывать приятные фичи за бесплатно. Пример: мне точно было бы лень делать самому следующие фичи, но я их с радостью завайбкодил:
- плавный старт/пауза для треков (с затуханием громкости). очень приятно ощущается, не очень приятно реализуется, хорошо изолируется в плане кода.
- изменение количества строчек и размера шрифта
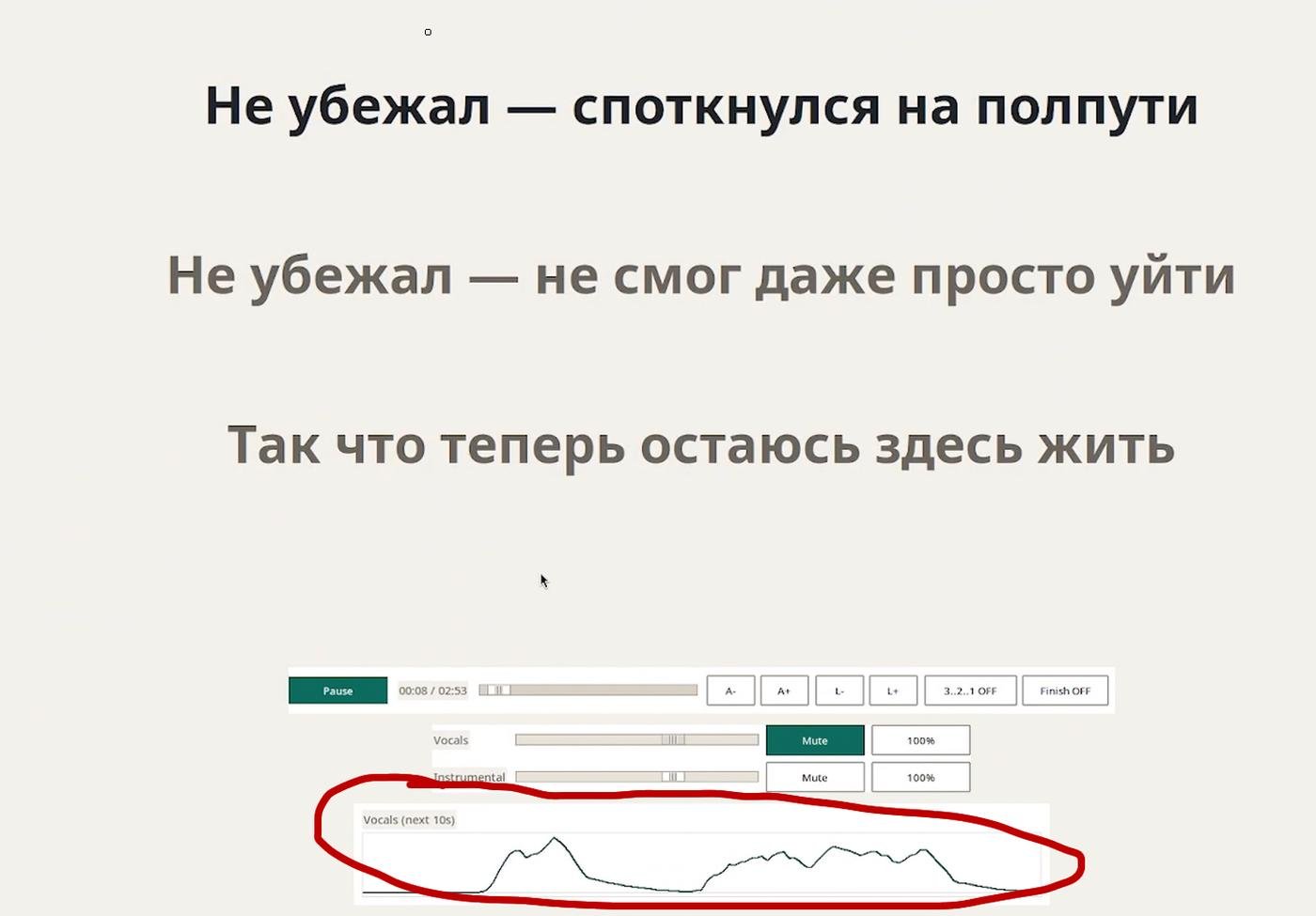
- график громкости следующих 10 секунд вокальной дорожки, чтобы понимать, когда пора вступать:
- функционал плейлистов и добавления в списки через ПКМ (не жизненно важный, поэтому мне было бы лень делать его самому, но точно повышает удобство использования)
Как выглядит мой финальный сетап
У меня есть колонка JBL Partybox 120, в которую я подключил набор беспроводных микрофонов за 2000₽. Колонка подключена к комьпютеру по блютузу. В ролике есть весёлая нарезка эмоций от караоке с друзьями 😝
Как запустить
Следовать ридми репозитория, там удобный скрипт для установки, требуется только uv (лучший пакетный менеджер для питона). Тестировалось и использовалось на линуксе.
Можно запускать и без видеокарты, но тогда обработка треков будет очень медленной. На моей видеокарте разделение каждого трека занимает ~25 секунд, я ещё и в параллель запускаю (есть прям такой параметр в GUI -j, надо смотреть по видеопамяти вашей видеокарты).
Поддержка Windows: Я попробовал разок упаковать весь проект в зипку с exe-файлом, с первого наскока не получилось. Но если будет спрос, можно попробовать потраблшутить.. Issues и Pull Requests приветствуются!
Сколько потратили и заработали? Есть идеи как это можно монетизировать?
Проект полностью open-source и разворачивать всё надо самому. Монетизировать пока нет планов
Спасибо за прочтение этого поста. Он был адаптирован из ролика на ютубе и постов в моём телеграм-канале, буду рад вашей подписке! И, конечно, зведочкам репозиторию

Отличная идея!
Неплохо бы еще конечно шарить сгенерированные караоке-файлы между пользователями чтобы не жечь токены на одни и те же песни.
Но это выглядит как потенциальная проблема с правообладателями.
Отличный проект!
График громкости 👏
И спасибо за наводку на "forced alignment", буду использовать в своих проектах!
Есть идеи:
-А на потоке участника с микрофоном - тоже и подсветить где он дотягивает, а где фальшивит?
У знакомого тоже аналогичный проект есть https://github.com/vxltersmith/lyri