Утечка исходников Яндекса на 44 ГБ
Публичный пост
Вчера, 25 января, на breached.vc пользователь borderline2023 выложил репозиторий с фрагментами исходников Яндекса. Объём архивов (в сжатом виде) составляет более 44.7 ГБ.
Компания Яндекс подтвердила утечку, но заявила, что она произошла не в результате взлома. На хабре пишут, что, по словам источника из «Яндекса», фрагменты исходного кода попали в открытый доступ по вине одного из сотрудников компании.
Что внутри
Разработчик Арсений Шестаков выложил у себя на сайте список файлов и написал краткое содержание слитого репозитория.
«Похоже, что как минимум исходники всех основных сервисов Яндекса утекли:
- Поисковая система и индексирующий бот
- Карты, Алиса, Такси
- Директ, Почта, Диск
- Market, Яндекс.Travel, Облако
- Яндекс.360, Яндекс.Pay, Яндекс.Метрика
И по крайней мере backend часть большинства других сервисов компании есть. Самый большой архив под названием «frontend» еще предстоит изучить»
На хабре юзер GAG выложил статистику слитого кода:
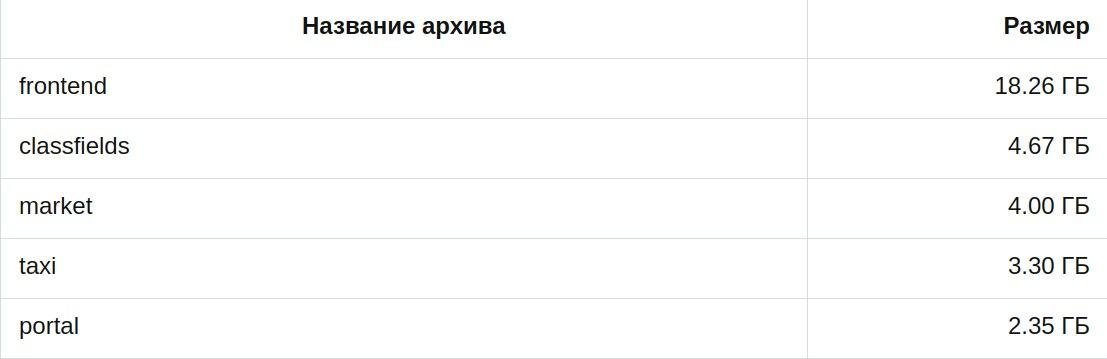
Общее количество папок: 83
Языки программирования и описания данных: Python, C++,
Go, TypeScript, Protocol Buffers, Yaml, JSON etc.
Ребята в Вастрик.Баре выложили скрин исходников внутреннего чат-бота:
Что думаете об этом? Будете скачивать и рассматривать исходники?
Магнет ссылка для потомков:
magnet:?xt=urn:btih:7e0ac90b489baee8a823381792ec67d465488fef&dn=yandexarc&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2F9.rarbg.to%3A2920&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2Fexodus.desync.com%3A6969&tr=udp%3A%2F%2Fbt1.archive.org%3A6969%2Fannounce&tr=udp%3A%2F%2Fbt2.archive.org%3A6969%2Fannounce&tr=udp%3A%2F%2Fopen.demonii.com%3A1337%2Fannounce




Рад видеть, что всё больше и больше компаний начинают вкладываться в Open Source разработку, хоть иногда и против своей воли!
Кто-нибудь развенчайте или подтвердите этот ебучий миф про цену такси и батарейку пожалуйста, я не сплю ночами и думаю об этом
Вообще вроде и просто код, но на самом деле и датасетов немало слито
Все это полезно, если самому надо непотребства всякие отфильтровывать.
А вот тут search/wizard/data/fresh/adult/white_markers/classifier.txt примеры поисковых запросов - кеки хоть лопатой разгребай
Я лучше подожду пока на реддите кто-нибудь скормит этот архив chatGPT и получит ревью:)
Было желание скачать почитать, что там понавертели с моим сервисом за 3.5 года после моего увольнения. Потом думаю, да ну его нах.
Сомнительное достижение на сегодня: работала в сервисе из топ-3 смешных названий по версии автора хабростатьи.
Буду ждать, когда кто-нибудь сделает Алису без ограничений, чтобы могла говорить совсем о чём угодно.
Это вот будет интересно
Если скормить все эти 44.7 ГБ кода какой-нибудь нейронке, может она научится писать новые яндекс сервисы?
Ух там ща пойдёт охота на людей с некрасным паспортом.
Прочитал эту новость уже в нескольких источников. И моя мысль постепенно развивается от "ну ок" до "может скачать, вдруг понадобится?"
Главное на свой Яндекс.Диск этот архив не выкладывать )
Ждем кучу призов на Bug bounty.
https://yandex.ru/company/press_releases/2023/30-01-2023
Вот несколько примеров:
● В коде содержались контактные данные некоторых партнёров. Например, водителей — в некоторых случаях их контакты и номера водительских удостоверений передавались из одного таксопарка в другой.
● Зафиксированы случаи, когда логику работы сервисов корректировали не алгоритмическим способом, а «костылями» (на языке разработчиков так называется временное решение, реализованное неоптимально и впопыхах). Через такие «костыли» исправляли отдельные ошибки системы рекомендаций, которая отвечает за дополнительные элементы поисковой выдачи, и регулировали настройки поиска по картинкам и видео.
● В сервисе Яндекс Лавка существовала возможность ручной настройки рекомендаций любых товаров без пометки об их рекламном характере.
● Наличие приоритетной поддержки для отдельных групп пользователей в сервисах Такси и Еды.
● Некоторые части кода содержали слова, которые никак не влияли на работу сервисов, но сами по себе оскорбительны для людей разных рас и национальностей.
для улучшения качества активации ассистента и уменьшения количества ложных срабатываний в бета-версии для сотрудников применяется настройка, которая включает микрофон устройства на несколько секунд в случайный момент без упоминания «Алисы»
Хуй в скафандре - прям хорошо
https://meduza.io/feature/2023/01/30/yandeks-blokiroval-izobrazheniya-putina-kogda-polzovateli-iskali-bunkernogo-deda-i-natsistskie-simvoly-kogda-oni-iskali-z
😱 Комментарий удален его автором...
Там зарыта радость для SEO-шников или не очень? В смысле алгоритмов выдачи контента.
Больше утечек — лучше безопасность!
Хорошая новость.
Как думаeтe,
Это сдeлал 1 чeловeк?
Eсли да, то откуда у него столько прав?)
Я правильно понимаю, что так как там используются либы под лицензией MIT, половину реп можно свободно перезаливать куда угодно, потому что КОД-ТО ОБЩИЙ?
Кто-нибудь заселфхостил чего или применил в домашних проектах:)?
А кто смотрел, там есть самое интересное: блейм и текст коммитов?