→
Минимум, который каждый разработчик должен знать о Unicode
Публичный пост Тех
Тех
4 октября 2023
1069

Никита @tonsky написал статью о Unicode: о его популярности и сложности.
Сначала Никита пишет, что такое Unicode сам по себе: какую проблему решает и как много символов в нем можно закодировать.
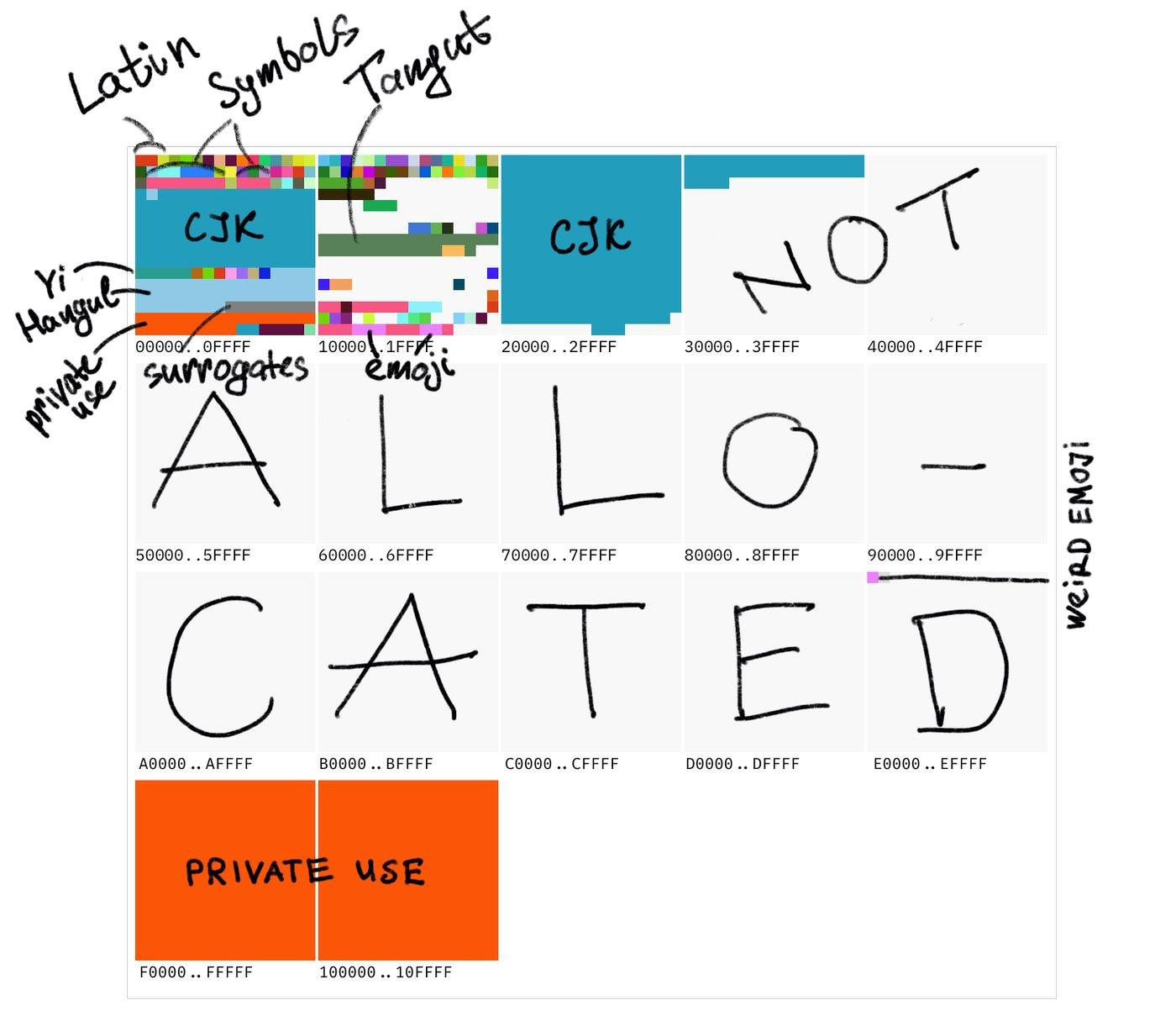
Затем говорится о UTF-8: почему латинская "b" может занять байт, кириллическая "й" — два, а "🧑💻" вообще будет одинадцать байтов.
Позже мы узнаем, что слова из разных языков могут набираться одним набором "кодов".
Если вы программист, вы узнаете:
- почему
len(text)илиtext.lengthвыдают неожиданный результат, - как делать правильно
- и почему сингулярности не будет.
Текст читается за 25 минут.
Ссылки по теме:
- Веб-архив страницы, в котором не отображаются "курсоры" читателей,
- Обсуждение статьи на Hacker News,
- "Emoji under the hood" от того же Никиты.

Не согласен с тем, что надо думать про графемные кластеры. Не надо. Просто не надо думать, что умеем работать с языком, если на самом деле не умеем.
Надо смотреть на задачу. Например, в русской кириллице действительно не особо есть разница между "графемным кластером". "символом", "что выделяется мышкой", "что стирается при нажатии на delete" и "как можно обрезать длинное сообщение".
Ну и да, лигатуры Никита упоминает, что хорошо: fi —один code point, один кластер, одна лигатура, а букв как бы две.
А потом начинается. ﷽ — один code point и один кластер. ᄀᄀᄀ각ᆨᆨ — выделяется как один символ, а вот стирается в текстовом поле уже кусочками. Сколько тут кластеров? Что происходит с арабской вязью (когда форма букв меняется в зависимости от того что рядом => с обрезкой некоторые сложности), корейским (когда иероглифы набираются из нескольких букв) или китайским (когда набирается фонетически) — очень интересно и мне неизвестно.