

Допустим, вы ничего не знаете про статистику (уверена, таких много, я была среди них).
Вам задают вопрос:
у нас магазин, вот мы провели аб-тест, в группах было по 100 000 человек. Мы сделали изменение (добавили новую функцию). В контрольной группе купило 1 000 человек. А в тестовой — 1 100 человек. Катить изменение на прод или не катить?
После этой статьи вы сможете на него ответить. Или нет :) Напишите в комментариях свои впечатления. Так же призываются дата-сатанисты и аналитики, я вполне могла где-то ошибиться, а цель — дать людям простые инструменты и понимание одного из самых задротских разделов математики.
Когда я только начинала свой путь в понимании аб-тестов, я задала вопрос аналитику — а как понять, какого размера должна быть выборка, сколько должен длиться тест, чтобы мы могли принять решение об изменении? Он мне прислал ссылку на калькулятор — вот, посчитать тут, что может быть проще!

(действительно, а что значит каждая из этих крякозябр — видимо, впитывает с молоком матери каждый человек)
А потом я потратила кучу времени и энергии — прошла полностью раздел математики под названием Статистика, прочла несколько книжек и ещё курс от Гугла про АБ-тесты (он, кстати, классный и бесплатный, если что гуглите Юдасити Гугл АБ-тесты на англ). Всё на английском, потому что на русском там не русский, а такой язык, что я одно предложение-то понять не могу (до сих пор). И всё это для того, чтобы просто понять, что такое:
- стат значимость
- доверительные интервалы
- как понимать, можем мы верить аб-тесту или нет, хотя бы верхнеуровнево
И на самом деле мне нафиг не нужны были такие глубокие знания, но никакой вменяемой статьи или видео на Youtube, которые бы на пальцах погружали в статистику, я не нашла. Кажется, их до сих пор не существует. Исправляю такую несправедливость!
Распределения
Смотрите, допустим, вы подбрасываете монетку. Монетку может выпасть орлом или решкой. Если монетка правильная, не утяжеленная с какой-то из сторон, вероятность выпадения орла 50%. Значит ли это, что если вы подбросите монетку 10 раз, у вас 5 раз выпадет орел и 5 раз решка?
Нет! У вас может получиться любой результат — и 4 орла на 6 решек, и 3 на 7, и 2 на 8, да даже 10 орлов может выпасть. Но если одновременно с вами монетку подбрасывает ещё 100 человек, то чаще всего будет результат 5 орлов на 5 решек, и только у вас — 10 орлов.
В каком-то сумасшедшем мире монетку подбросили 1 миллиард раз, и получили вот такое распределение результатов:
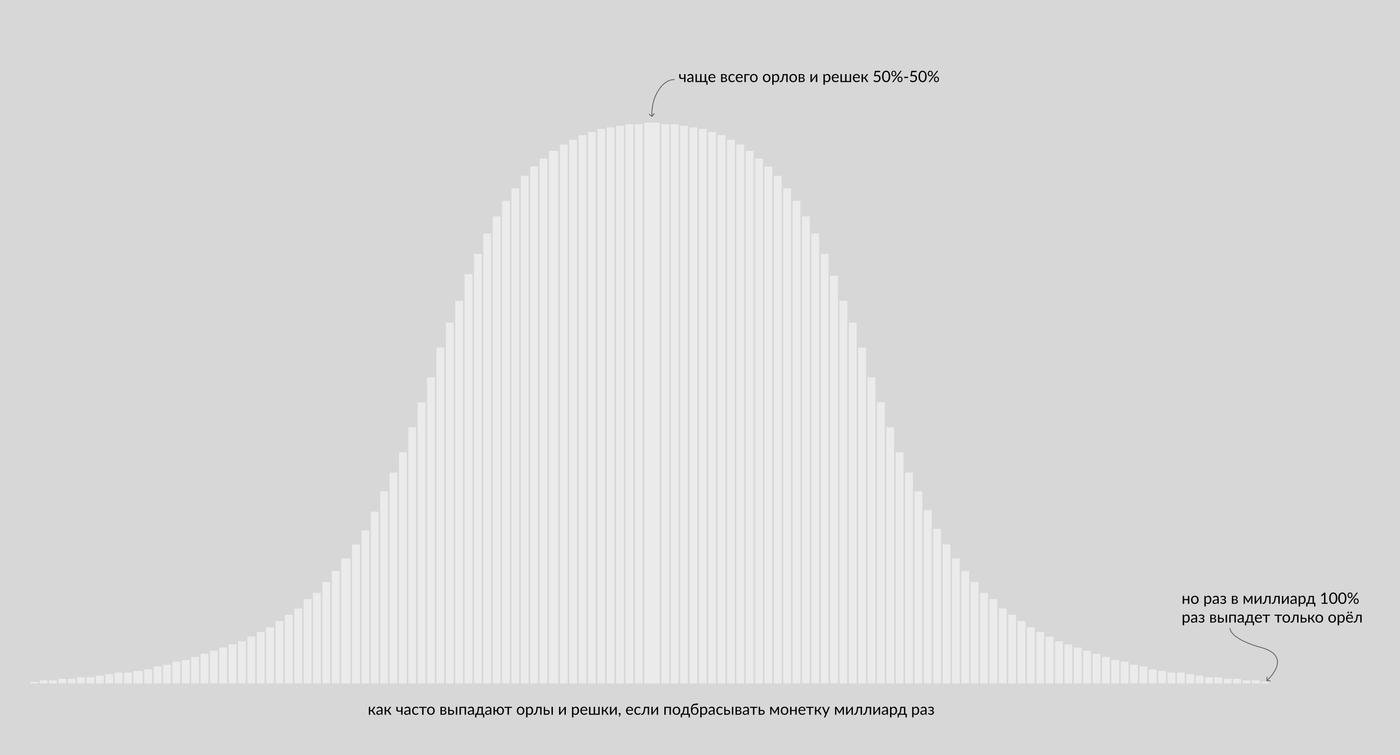
Это у нас будет истинная картинка, так распределено в генеральной совокупности. То есть правильные, не утяжеленные с одной из сторон, монетки, выпадают орлами-решками вот так
Так как у нас два исхода, такое распределение называется биномиальным (bis=дважды по-латински).
А вот нормальное распределение. Очень похожее, просто больше конкретных значений. Большинство величин в нашем физическом мире распределены нормально. Например, рост людей, или размер песчинок, или количество полосок у зебр.
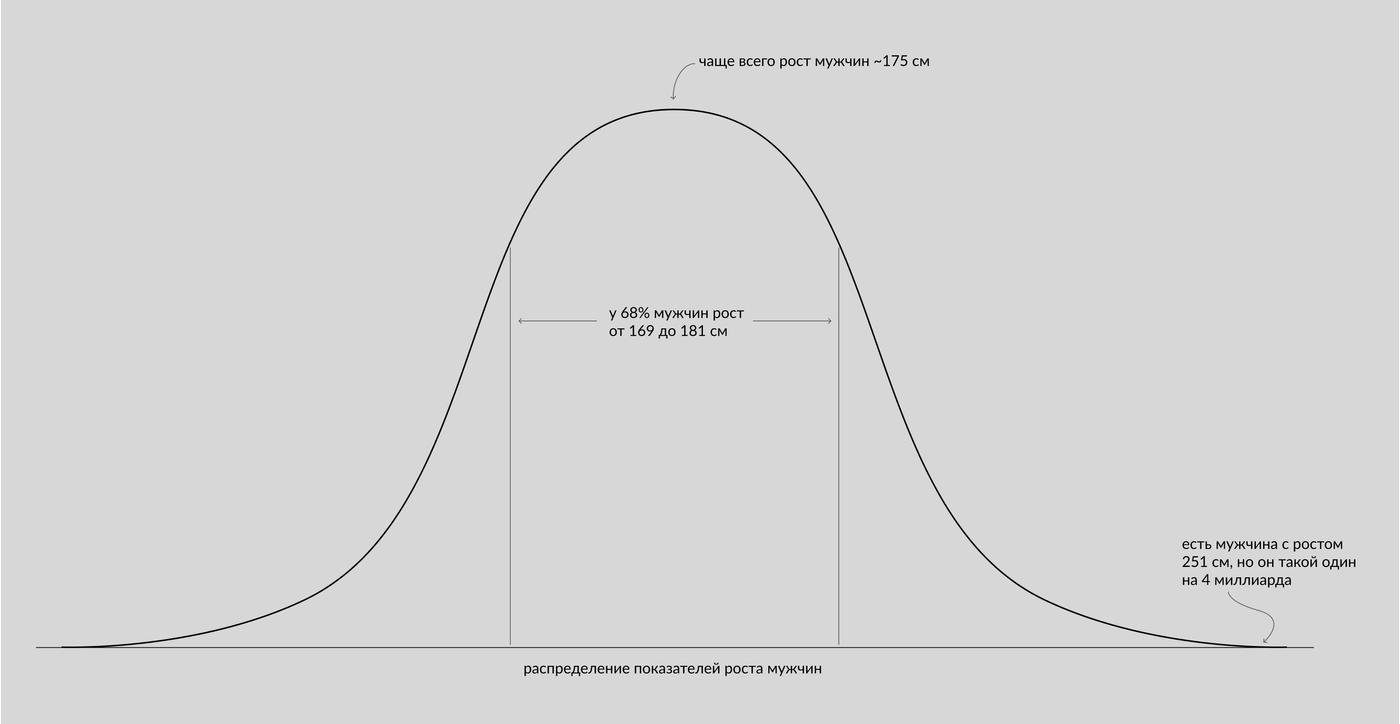
Провязываем это с нашим диджитал миром:
большинство штук, которые мы делаем на сайте, в конечном счете влияют на конверсию. То есть мы замеряем в аб-тесте “купил-не купил”, “нажал на кнопку-не нажал”, “открыл письмо-не открыл”. Это всего два исхода. Значит, они распределяются биномиально, как орлы с решками.
А если, например, вы экспериментируете с нагрузкой на сервер или на отдел продаж, где у вас к событиям добавляется время, то это уже распределение Пуассона.
Но мы здесь не будем про него, потому что большинство гипотез, проверяемых с помощью сплит-тестов — про биномиальное распределение. Товарища Пуассона оставьте дата-сатанистам с аналитиками.
Зубодробительная часть
Когда вы подбрасываете монетку, если только вы не зациклившийся окр-щик, вы её подбрасываете не миллиард раз, а, ну, сто. У вас никогда не получится вот эта картинка:
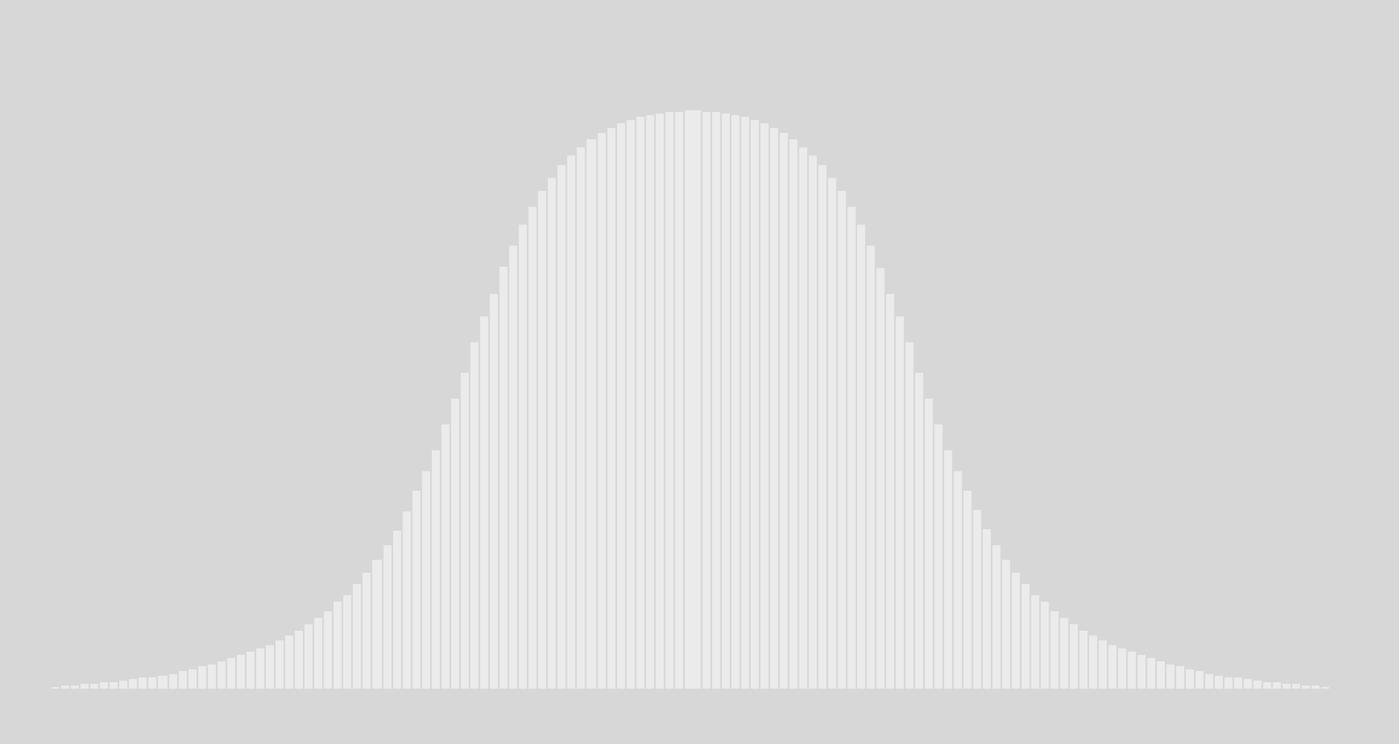
Вместо неё у вас будет что-то типа:
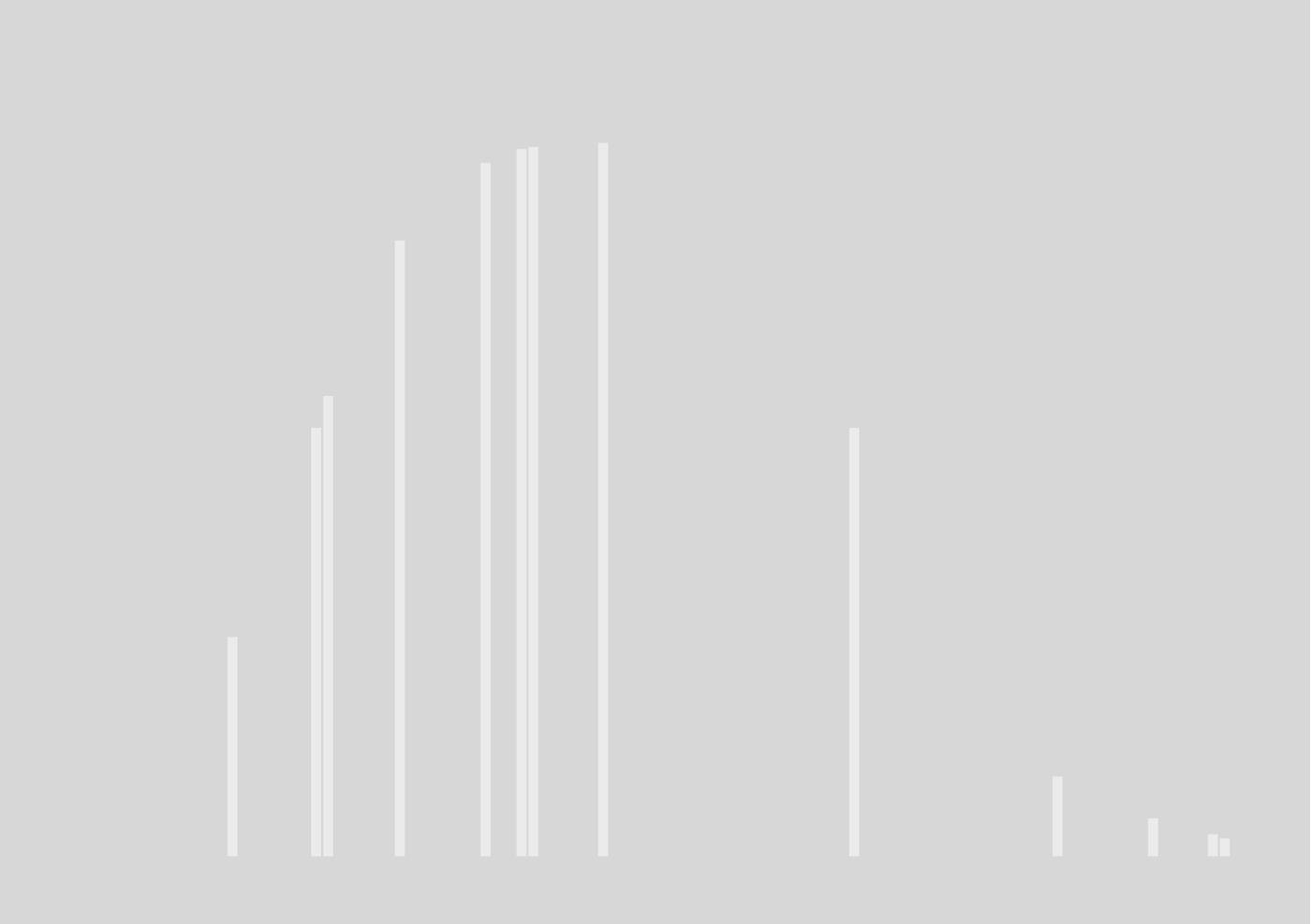
И вся суть статистики, экспериментов и непонятных формул в том, чтобы ответить на вопрос — так а что эта картинка значит? Как нам её наложить на генеральную совокупность? У нас монетка правильная или кривая, утяжелённая с одной из сторон?
Тут начинается самое интересное :)
Допустим, есть вы и ваш друг. Вы подбрасываете монетку, каждый по 100 раз (ну вот дело было вечером, делать было нечего, бывает же). И у вас 10 раз выпал орел. Если монетки были одинаковые, значит ли это, что у друга тоже орел выпал 10 раз из 100?
Конечно, нет. Ну то есть такая вероятность существует, но она не очень высока. Вы не можете экстраполировать свои результаты на друга со 100%-ной уверенностью.
А что можете? Ну, допустим, с уверенностью 50% вы можете утверждать, что у друга выпал орел от 8 до 12 раз. То есть вы прям выходите к нему и такой:

Или с уверенностью 99,7% вы можете ставить сотку, что у друга выпал орел от 2 до 18 раз. Всего 1%, что вы ошибаетесь и свою сотку проиграете

Сечёте фишку? Чем выше ваша уверенность (и ставки 😁), тем больше погрешность.
В статистике ваша уверенность называется Confidence level. Вероятность ошибки — это Significance level. Если уверенность на 95%, то вероятность ошибиться меньше 5%. Логично ведь?
Вот это вот от 8 до 12 раз — доверительный интервал, диапазон, в котором лежит истинное (полученное другом) значение. Чем выше ваша уверенность, точность вашего предсказания результатов друга — тем шире диапазон.
Для стопроцентной точности (вот чтоб прям к гадалке не ходи!) вам придётся сказать “я точно знаю, что у тебя выпал орел от 0 до 100 раз”. Потому что вероятность получить 100 орлов или 100 решек из ста ничтожно мала, но она есть.
Теперь немного математики и формул. Откуда я получила вообще все эти значения?
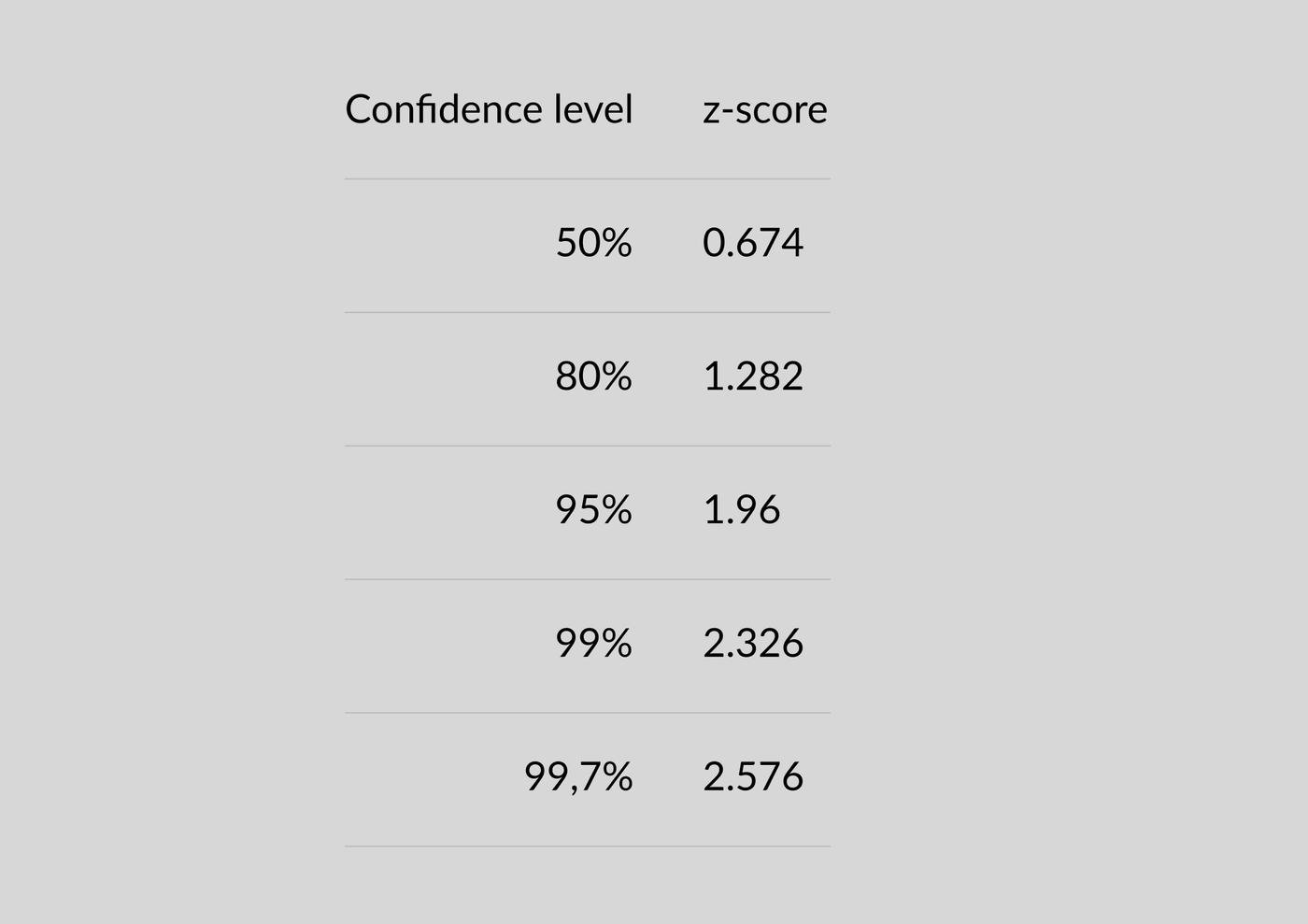
Есть формула для расчета доверительного интервала. Формулы будут разными в зависимости от распределения. Просто гуглите “формула доверительного интервала для распределения …” и вуа-ля. Для биномиального распределения используется формула:
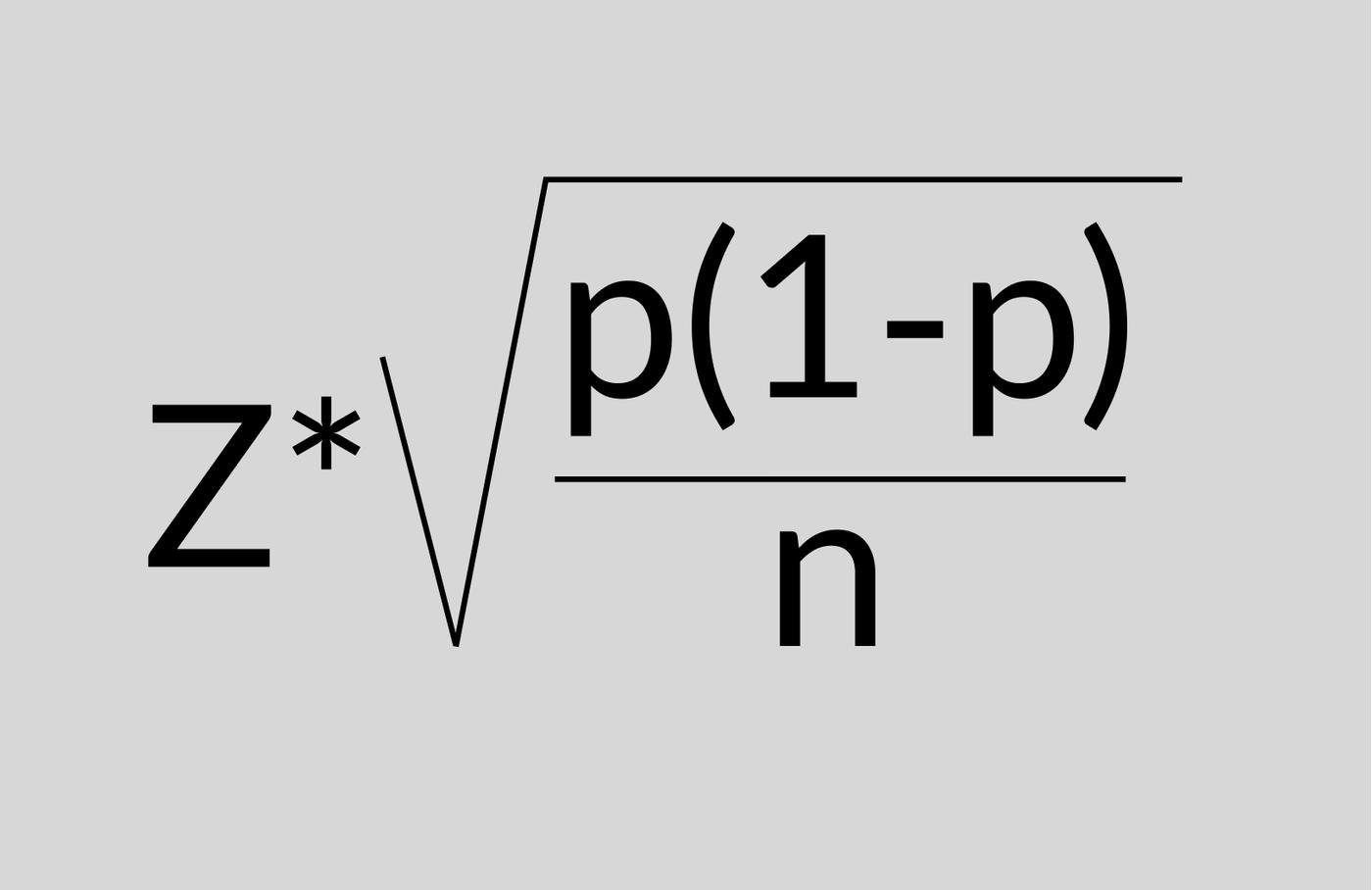
где z = z-score, он гуглится в зависимости от того, какой Confidence level вам нужен, насколько сильно вы хотите быть уверены в том, что выпало у друга
p = сколько (в процентах) у вас выпало орлов
1-p = сколько (в процентах) у вас выпало решек
n = размер выборки, сколько раз (в абсолюте) вы подбрасывали монетку
В гуглотаблицах это выглядит так:
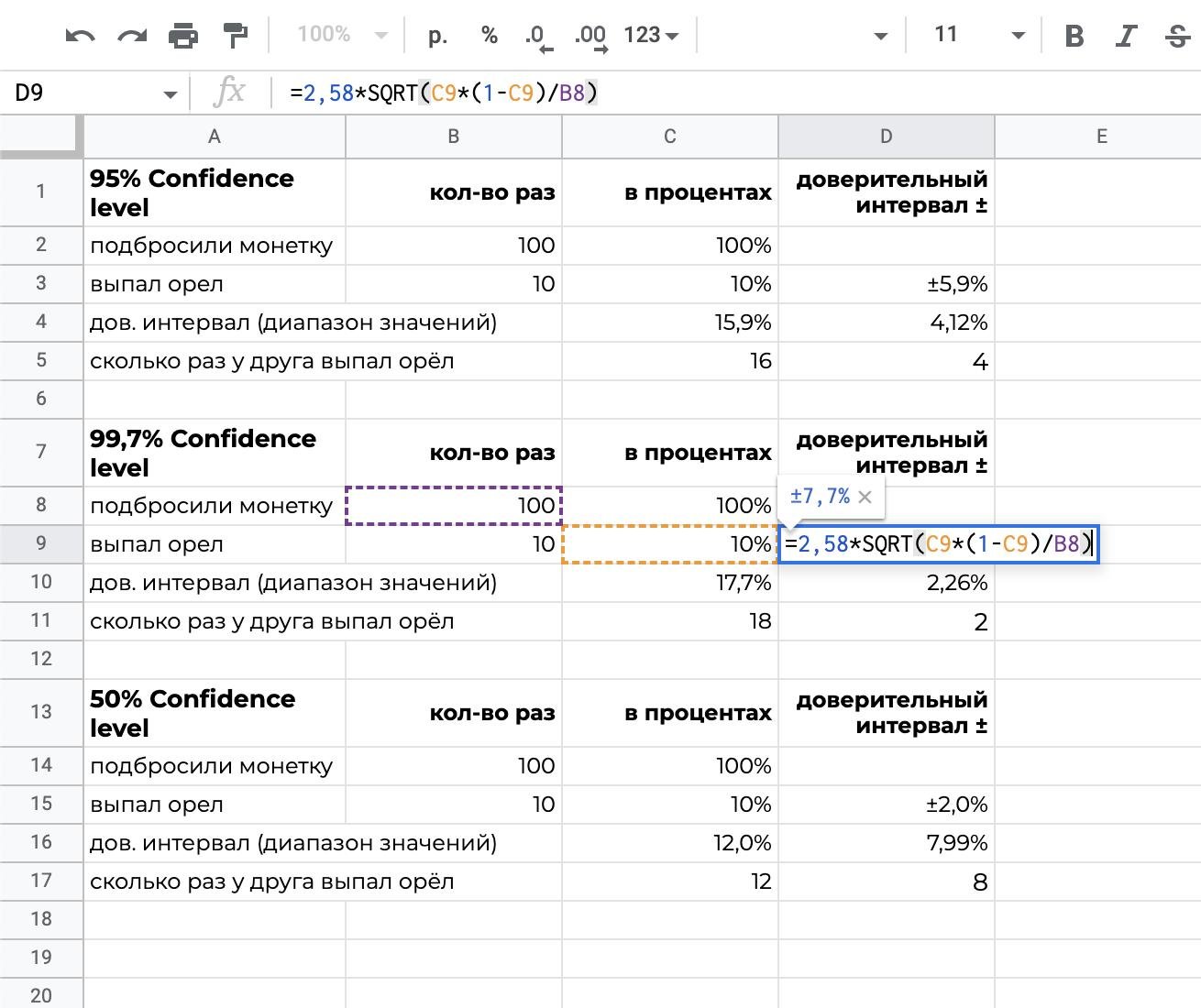
Теперь возвращаемся в дивный диджитал мир. Тут у нас никаких решек с орлами, тут только хардкор и конверсии.
Скажите, вам эта предыдущая картинка ничего не напоминает?
По сути это воронка. И нам ничто не мешает считать доверительные интервалы для каждого шага воронки. Ну только ещё один столбик надо добавить, с относительной конверсией. Для p всегда берём процентное значение и для n — выборку относительно этого значения.
Результаты, которым можно верить, лежат за пределами доверительного интервала.
Расшифровывается это следующим образом:
Мы с уверенностью в |...%, confidence level| можем считать, что если конверсия в тестовой группе будет за пределами доверительного интервала значения в контрольной группе – это не погрешность.
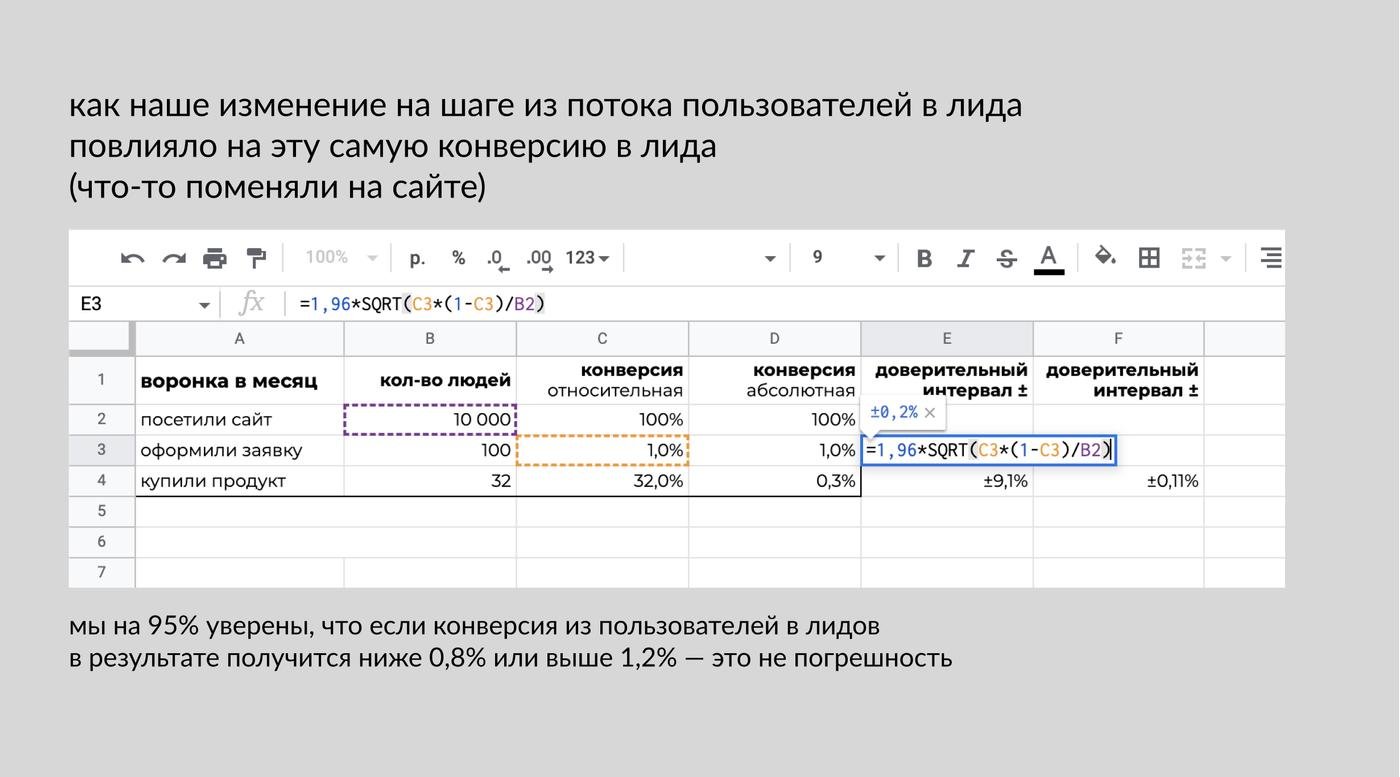


Так а нафига мы это считали?
Переходим к тому, как это применять на практике.
До запуска следите за тем, чтобы размер погрешности был как можно дальше от того, на сколько меняется целевая метрика
Когда вы делаете изменение (на сайте, в приложении и тд) — вы выдвигаете гипотезу. Эта гипотеза всегда привязана к метрике, на которую вы хотите повлиять изменением. То есть, допустим, добавляя функцию на сайт, вы такие “Гипотетически, добавив вот эту зашибенную фичу, мы повысим конверсию в лида”
Если у вас есть хоть какой-то опыт в взращивании целевой метрики, вы можете предположить, на сколько вы её увеличите. Если экспертизы нет — идёте к коллегам по цеху в чатики или на экспертные интервью, они могут не поделиться конфиденциальными данными, но общий порядок цифр они дадут.
Так вот допустим, вы верите, что увеличите конверсию в лида на 0,1%. А доверительный интервал у вас тоже — 0,1%. То есть ваше изменение, даже если вы его “засечёте”, не очень понятно вообще от чего произошло — это вы повлияли фичей, или оно само так вышло.
Классная это гипотеза? Ну, есть надежда, что у вас есть получше. И это точно плохой кандидат на аб-тест.
При анализе результатов аб-теста чем дальше полученные результаты контрольной и тестовой групп друг от друга, тем лучше
Сплит-тесты на то и были придуманы, что у вас есть две группы, контрольная и тестовая. В контрольной вы ничего не меняете, они живут как жили, вы их замеряете. В тестовой вы выкатываете фичу и замеряете, что получается.
В результате у вас будут две воронки, с разными показателями. И у каждого свои доверительные интервалы.
Если это изобразить графически, то будет выглядеть вот так:

Важно, чтобы доверительные интервалы контрольной и тестовой групп не пересекались. Потому что если они пересекаются — то не понятно, это в рамках погрешности у нас такой результат? Или это наша фича повлияла?
Последнее — не следует из этой статьи, но я всё равно скажу
АБ-тесты создают видимость сильной аргументации. Типа “ну это же цифры, это математика! Давай поспорь со мной, с моими гипотезами и результатами, когда я всё могу доказать количественными показателями”
Но на самом деле это всего лишь инструмент, который не всегда уместен.
Основной аргумент за аб-тесты — не повышение вашей уверенности в выкатываемых изменениях, а в снижении рисков.
На больших выборках, когда у продукта сотни тысяч и миллионы пользователей, изменение в несчастные 0,01% конверсии может измеряться сотнями тысяч рублей. Поэтому тот же Booking ссыт выкатывать что угодно сразу на всю аудиторию — цена ошибки слишком высока, компания может за одно изменение потерять годовую зп продакта, который это изменение решил ввести. Проще проверить на небольших группах, а потом решать.
Я считаю полнейшей дичью применять критерий Стьюдента для работы с малыми выборками в стартапе с 10 000 пользователей в месяц или в b2b с 200 клиентами в месяц.
У стартапа обычно огромный потенциалы роста в улучшениях тупо по обратной связи или с привлечением грамотных специалистов (ux-аудит). А любые изменения обычно проще катить на прод. Потерять вы можете — ну сколько? Ну 50 лидов в худшем случае (хоть я и не представляю, что нужно сделать на плохом сайте такого, чтобы статистически значимо ещё сильнее ухудшить конверсию). А любые, даже минимальные улучшения конверсии, дают вам прирост лидов.
В b2b вместо того, чтобы высчитывать доверительные интервалы на 200 человек проще тупо опросить аккаунт-менеджеров или напрямую клиентов. Это даст намного больше инсайтов и аргументов в вашу защиту перед стейкхолдерами.
Шпаргалка (цифры для примера)
Уровень значимости = Significance level = α, записывается обычно p<0.05 или 5% = насколько вероятно, что мы ошибаемся
Уровень доверия = Confidence level, записывается обычно 95% = насколько мы уверены, что полученное значение лежит в истинном диапазоне
Уровень значимости обычно коррелирует с уровнем доверия, потому что они примерно об одном и том же, но с разных сторон. При уровне значимости p<0.01 – уровень доверия 99%
Доверительный интервал = Confidence interval, записывается обычно 60%+-4% или 56% - 64%
У разных распределений разные формулы для расчёта доверительных интервалов.
У биномиального распределения формула расчета дов. интервала = ZxSquare-root(p(1-p)/n)
Для эксель и гугл таблиц c Confidence level 95% =1.96SQRT(ячейка с конверсией*(1-ячейка с конверсией)/ячейка с выборкой,из которой посчитана конверсия)
z = z-score = специальный коэффициент, его надо подставлять в формулу расчета дов интервала в зависимости от желаемого уровня доверия
Если статья полезная, пожалуйста, поддержите её плюсиками, чтоб как можно больше нуждающихся людей её увидело
Если вы знаете полезные не зубодробительные ресурсы про статистику и аб-тестам – я слоупок и их упустила, буду благодарна за ссылки
Если вы дата-сатанист и у меня тут ошибки – не стесняйтесь, делитесь жопоболью, я всё исправлю и спасибо, что вам не все равно

Вчера я откомментировал как-то коротко и поверхностно, но я считаю, что пост очень и полезный. Хочу немножко добавить, пользуясь тем, за последние три года я провёл около 100 A/B-тестов и ещё штук 70 проверил за другим человеком.
Вообще это не про А/Б-тесты, а про философию, но мне очень понравилась вот эта фраза:
Не случайно формулировка нулевой гипотезы такова, что у между изменением и результатом нет связи. Очень хочется увидеть, что какое-то изменение работает, но на самом деле твоя задача и в аб, и во всём остальном -- доказать себе, что ты не прав(а).
Мне очень помогло с этим:
а) смотреть на чужие тесты — чужую идею всегда рубить приятнее, чем свою
б) начать смотреть на свои так же, как на чужие. Я всегда представляю себе вопрос от зрителя: "А если тут будет вот так?"
Не делать изменений ради изменений, принять, что не все идеи работают, — важная штука. В обмен на неё получаешь значительно больше уверенности в том, что знаешь, как работает продукт и какие изменения были стоящими.
Ещё из хороших слов в этом тексте:
Вы выбираете гипотезу и не меняете её на ходу. Это может сработать как на вас, так и против вас.
Пример из игровой индустрии. Ваша гипотеза заключается в том, что при добавлении нового баннера вы повысите конверсию в покупку конкретного оффера и тем самым повысите общую конверсию.
Вы выкатываете изменение и смотрите на результаты, конверсия в покупку выросла с 0.1% до 0.2%, общая конверсия выросла с 2.01% до 2.08%, но средняя выручка на пользователя упала. Что делать?
Во-первых, вспоминаем гипотезу. Зачем изменение придумывалось? Чтобы повысить конверсию. Значит, идея работает.
Во-вторых, смотрим - а почему выручка упала? Очень вероятно, в одной группе случайно оказался кит, который перетянул равновесие. В такой ситуации можно сделать несколько вещей:
В целом вообще залезть в детали - хорошо, но не чтобы натянуть сову на глобус и доказать себе свою правоту, исходя из каких-то странных нюансов, а чтобы в определённый момент, задавая себе вопрос "почему я могу ошибаться?" - вы не смогли на него ответить.
Это вопрос простой. А что если спросить так:
Казалось бы, ответ "нет". Но если я вижу такие результаты, я хочу понять, так ли это. Например, у меня есть стул с флагом Японии на спинке, который я продаю в США и Японии, у меня есть 1000 покупателей в каждой стране. Итого 2000.
Я решаю продавать стул с флагом США, и тоже продаю 2000 стульев.
Изменение ничего не даёт?
Ну нет, на самом деле я просто продал 1500 стульев в США и 500 в Японии. И я теперь знаю, что я могу выкатить изменение на один из сегментов моего рынка.
Сегментировать опять же можно на очень разных основаниях: страна, тип девайса, прошлые покупки и всякое такое. Протестировать можно на всех, и круто, если изменение влияет на всех одинаково, но всегда стоит посмотреть - а можем ли мы назвать пользователей, которые отличаются от других?
И последнее, о чём я хотел написать: есть большие тесты, а есть маленькие.
Иногда я менял картинку, которую мы показываем с товаром. И это влияло сильно. Иногда я менял баннер, и это не влияло на итоговые результаты не так. Оба теста - очень маленькие, и их легко посчитать. Но иногда в попытке угнаться за маленькими trackable изменениями ты играешь на балалайке вприсядку. Вместо маленьких изменений можно забабахать одно большое, но объединённое общей идеей, - и посмотреть, как оно отработает. Это пересекается с мыслью, что если вы стартап, то хрен вы наберёте статистически значимое количество юзеров. На самом деле, вы можете набрать, но тогда, когда готовы делать большие изменения.
Так кактить или не катить? Статью прочитал, ответить не могу. :(
Не вполне понятно, что имеется в виду под фразой «Я считаю полнейшей дичью применять критерий Стьюдента для работы с малыми выборками…»
Дальше по тексту вроде как речь идет о том, что в некоторых случаях количественный анализ лучше заменить качественным исследованием, но сам то критерий чем провинился, он для малых выборок так то и придуман.
We reject the null hypothesis based on the 'hot damn, check out this chart' test.
p.s. просто решил поделиться
О, спасибо, буду джунам отправлять. :)
По простым материалам — "Статистика и котики", конечно. :)
А скоро выйдет "Статистика и котики для бизнеса", инсайдерская инфа, автор — мой коллега, из Контура. :)
Классная статья!
Могу дополнить, что основы статистики хорошо изложены в книжке "Статистика и котики" и в курсе https://stepik.org/course/Основы-статистики-76
По аб тестам рекомендую почитать
https://link.medium.com/GvLpi0V2Nxb
https://habr.com/ru/company/avito/blog/571094/
https://habr.com/ru/company/avito/blog/571096/
Привет! Хочу поделиться своим опытом – поворотной точкой в работе с экспериментами для меня стала вот эта концепция – смотреть на эксперименты как на линейную модель.
В простом случае у тебя получается следующее
метрика = константа + эффект * группа(0 или 1)
то есть, если группа тестовая (1), ты получаешь прибавку к метрике в контрольной (0) группе.
Такой подход позволяет за счет свойств линейных моделей расширять подход – делать подобие CUPED и добавлять сетевые эффекты (когда у тебя юзеры между группами взаимодействуют и искажают эффект от фичи).
есть такая задачка про тестирование. у аделины и беллы аккаунты на онлифанс с конверсией, скажем 20%. они меняют верстку и смотрят, че там с деньгами. при этом белла наняла аналитика и принимает изменения по p-value < 0.05, а аделина просто смотрит на среднее и катит по среднему.
пусть у каждой было 100 правочек, правочки дают N(0, 1) на конверсию и даже пусть правочки вообще одинаковые для обеих девочек, там один и тот же фронтендер фрилансит. кто после ста правочек вырвется вперед по конверсии? сэмпл сайз 1000 на контрол и тритмент у каждой, чтобы картина ровная была.
(это была подпись к одной из картинок, про изменение на этапе всего потока, повлиявшее на конверсию в покупателей)
такое можно считать, потому что конечная цель - это совершение покупки, если на этапе лидогенерации написать, что вы дадите миллион долларов за совершение покупки, можно нагнать мусорных пользователей в следующий этап воронки, и они отвалятся)
Выдержка:
У тебя есть 2 стула, один точно лучше другого, какой купишь? Ответить сможешь после того как почитаешь :)
Нормальное распределение выглядит на графике как колокол. Означает кол-во значений в каждом диапазоне.
Обычно всё выглядит как колокол, но это не твой случай, у тебя его не будет.
Монетку с другом лучше не кидать - ты всё равно ничего не знаешь.
Доверительный интервал это...? (напрягаешься, потеешь);
Это интервал, в котором значение НЕ должно находиться, чтобы мы могли предположить с некоторой увереностью, что это не случайность.
Хорошо, когда погрешность маленькая, а изменение большое;
Лучше, когда метрика выросла настолько, что ты получил повышение.
Если у тебя мало данных - не делай A/B-тест, лучше поболтай сходи.
А стул я покупать не буду, мой удобнее.
Statquest же есть, там и цикл про p-value и тесты имеется