




Для технологической индустрии 2023 год был богат на истории по которым HBO смело можно снимать сериалы. Наверняка вам сразу приходит на ум недавнее увольнение Сэма Альтмана.
Но я хочу рассказать о том, что поважнее, глобальнее и пока не настолько у всех на слуху.
Это история о дерзком гамбите Марка Цукерберга и мои размышления о том, как Бигтех компании будут делить рынок AI с Опенсорсом.

Позвольте мне немножко похайповать в самом начале, чтобы разжечь интерес.
Я всегда думал про Марка Цукерберга как про миллиардера с самой грустной судьбой. В попытке перестать быть вечно догоняющим, он продал душу богу конкуренции… И все равно проиграл.
Исторически так сложилось, что смартфоны, операционные системы и магазины приложений делает не его компания. А все кто стоит раньше него в цепочке создания ценности почему то первее и вот в этом списке:
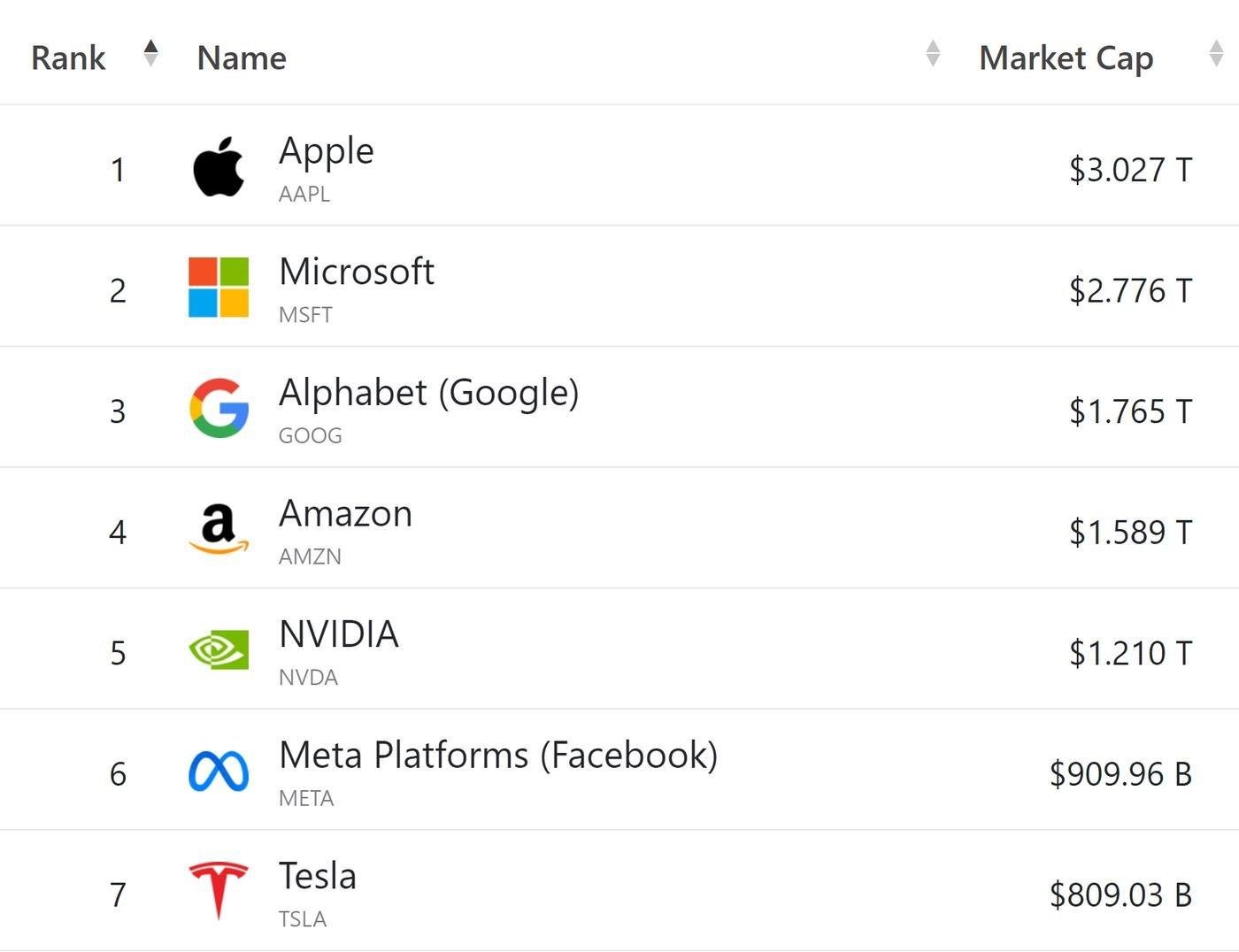
И каким бы крутым лидером он не был, как быстро бы не росла компания - стратегия бьет тактику. Против фундаментальных рыночных барьеров не попрешь. Эра мобильных приложений пришла после персональных компьютеров и интернета. По сути Марк проиграл еще в момент создания компании.
Статья бы на этом и закончилась, если бы Цукерберг не был известен своим соревновательным майндсетом:
Это прикольный вид боевых искуств, который учит смирению с поражениями, важности понимаия своих сильных сторон и использования уязвимостей соперника. Все как в бизнесе. После почти двух десятков лет удушающих от Apple и Google, Марк все еще не сдается, мечтая найти свое стратегическое преимущество.
Meta - одна из немногих бигтех компаний где у руля все еще ее основатель. Этот факт и позиция догоняющих дает возможность ему делать смелые шаги. Выбирать рисковое направление и вести за собой всю компанию.
Одно из направлений - это очки дополненной реальности.
Марк мечтает создать Метаверс, где уже он будет контролировать технологию и цепочку создания ценности. А остальным компаниям придется корячиться в позиции снизу.
В 2014 году Meta купили за $2b стартап Reality Labs, производителя очков Oculus. А два года назад, Марк переименовал компанию и начал инвестировать в это направление все больше и больше.
Другое направление - это искуственный интеллект.
Статья будет про него.
В английском есть прикольный термин - Force Multiplier. Это фактор, кратно улучшающий эффективность. Например, комбайн делает из обычного фермера супергероя.
AI это штука покруче трактора. Это технология которая будет растить всё к чему только сможет притронуться, а не только бедного фермера. И тот кто будет контролировать ее, получит сильнейшую позицию.
Чтобы ставка сработала, Марк откопал старые чертежи конкурентной борьбы с использованием Опенсорса. Откуда то из времен кринжевых танцев от Microsoft:
Весной 2023 Meta на практике разворачивает чертежи и с двух ног врывается в AI через Опенсорс. Да так, что у традиционных лидеров в этом направлении - Google и Microsoft появились серьезные опасения, что защищающие их стратегические барьеры не так уж и высоки.
Дальше в статье я расскажу:
- Что же произошло и что это за чертежи такие?
- Какие есть барьеры и насколько они высоки?
- Порассуждаю о том, будут ли Apple, Google, Microsoft, Meta и Amazon так же бессменно влиять на наши жизни как и сейчас.
Дисклеймеры:
- Я иногда вольно обращаюсь с цифрами, накидываю и округляю, чтобы было проще делать выводы.
- Не всегда даю ссылки на источники, хотя и стараюсь.
- Использую сокращения и англицизмы, сорян. Например, ОС = Опенсорс = открытое програмное обеспечение.
- Статья большая, я 100% где то ошибся или выдал свои догадки за факты. Буду рад фидбеку и уточнениям.
- Большущее спасибо Антону Яценко за помощь в вычитке и советы как улучшить пост.
Содержание
- Meta - У компании серьезные проблемы?
- Опенсорс - Цукерберг хочет сделать нейросети дешевыми
- Лама - Что же произошло весной?
- Как обучают большие модели - Ликбез по этапам тренировки
- Магия ОС - Бигтех испугался быстро сокращения отставания?
- Какие барьеры защищают рынок:
- Барьер 1 - На рынке огромный спрос на железо
- Барьер 2 - Данные это узкое место, но преодолимое
- Барьер 3 - Алгоритмы важны так же как и скейлинг
- Барьер 4 - Регуляции пока не барьер, но могут им стать
- Выводы - Достаточно ли магии ОС, чтобы снести барьеры бигтеха?
Meta - У компании серьезные проблемы?
Прошлой осенью Марка Цукерберга всем интернетом отправляли на пенсию. Он занимает должность СЕО компании уже почти 20 лет. Пора на пенсию, не?
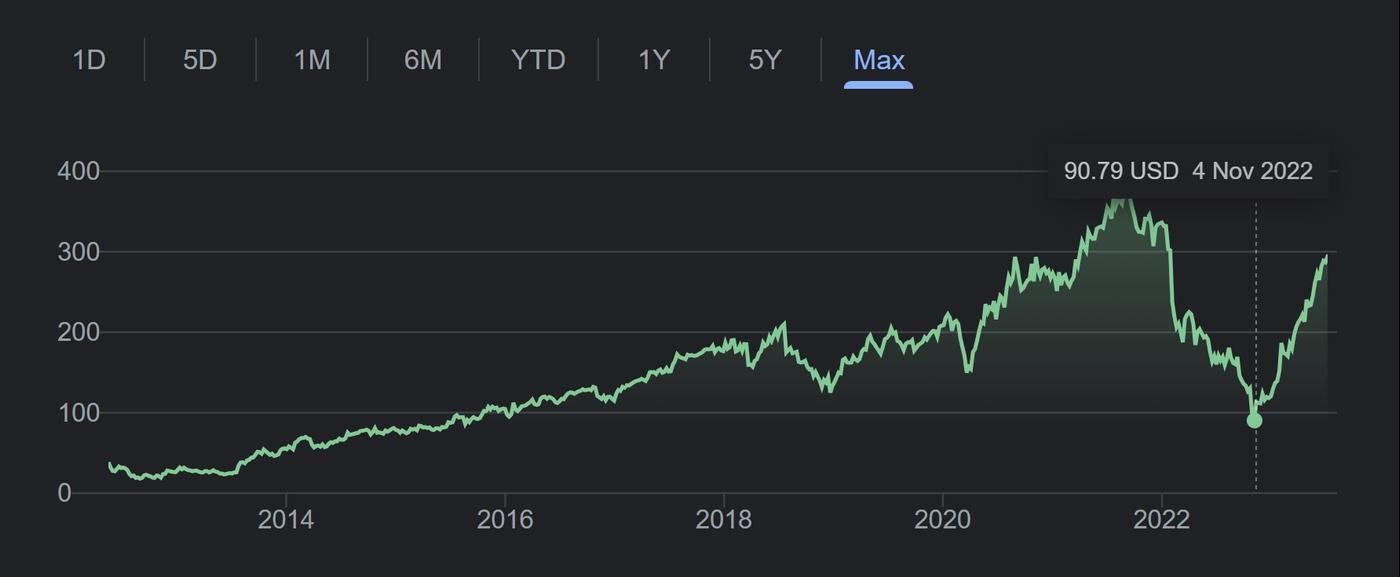
Основная причина - пока развлекался со своим Метаверсом, он проворонил TikTok и наезд на рекламный рынок от Apple.
Графики дохода выглядят тревожно, но на самом деле у него все хорошо.
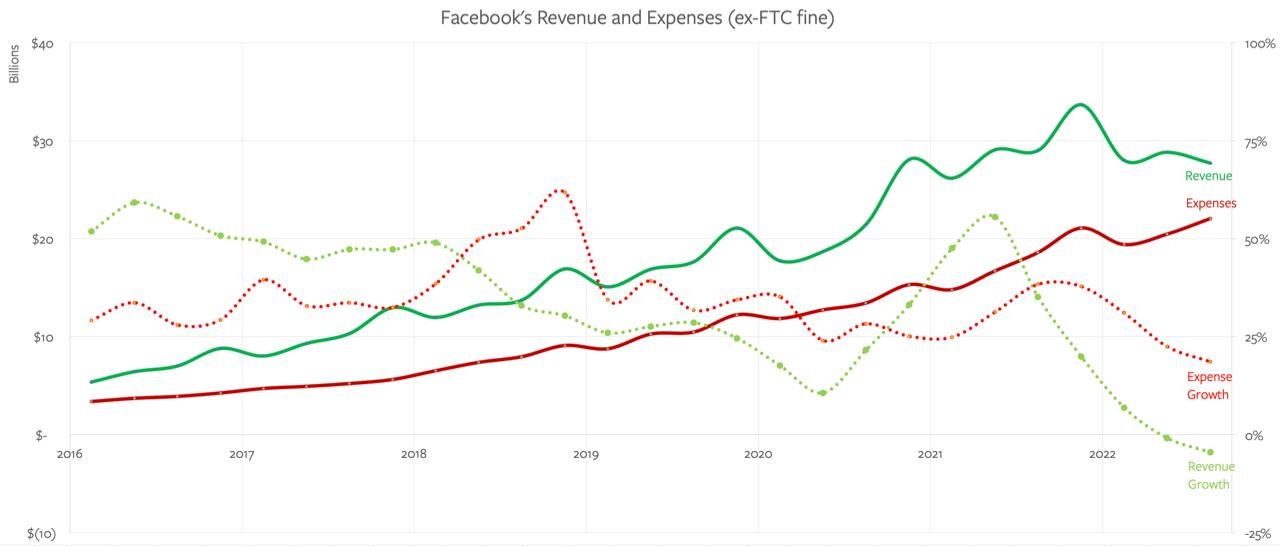
1 . Переименование компании из Фейсбука в Мету вовсе не говорит, что они забили на все остальное. Затраты на Метаверс составляют всего 10 млрд из 117 общего дохода. Много, но не смертельно.
2 . Apple готовятся запустить ATT. Это их App Tracking Transparency policy - теперь приложухам нужно активное согласие юзера, чтобы шейрить данные о нем. Стало сложнее понимать, сработала реклама или нет, потому что.. Ну камон, кто в своем уме будет рарешать им собирать данные.
И так как основной бизнес Меты это реклама, они сильно пострадали.
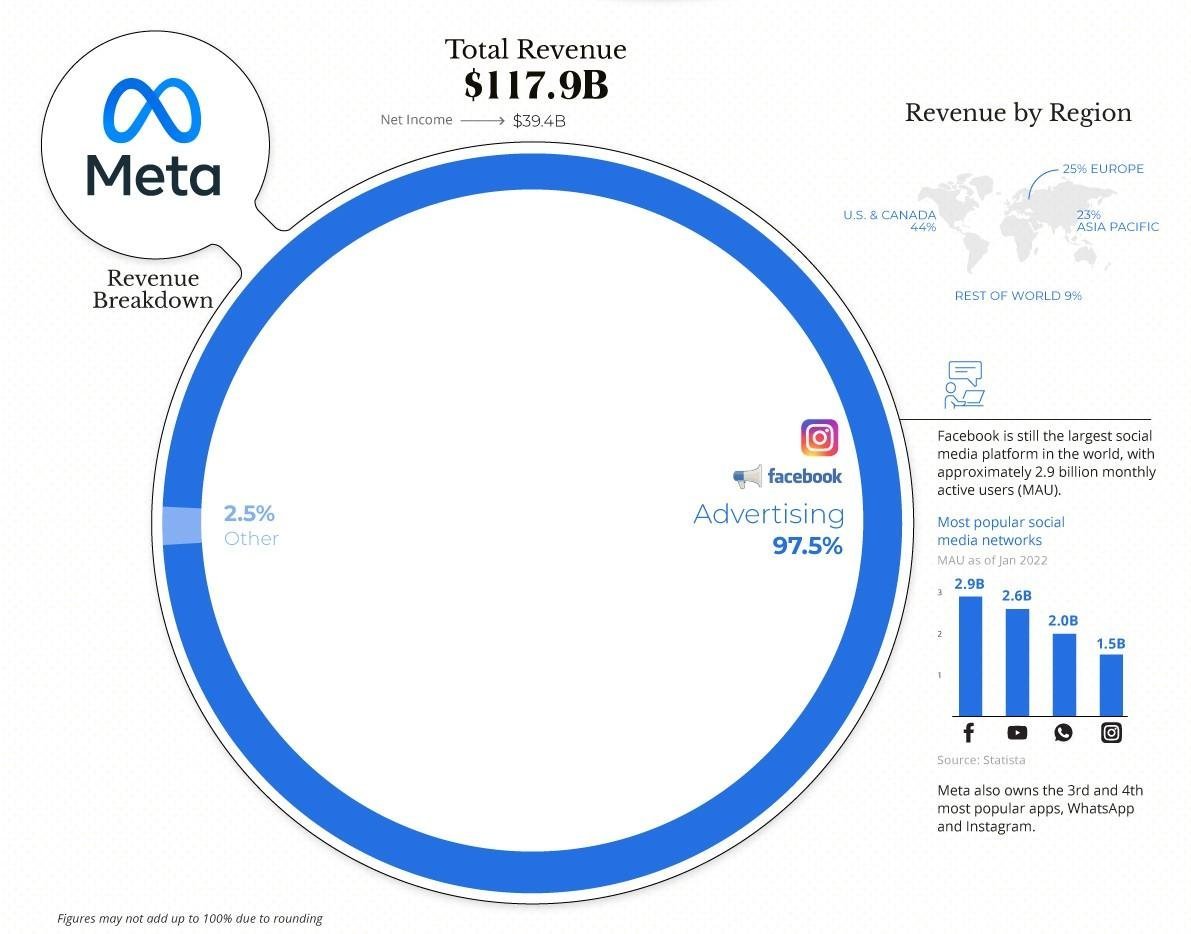
Это еще 10 млрд недополученного дохода каждый год. Плохо, но не смертельно?
3 . Окей, а что с TikTok? Тут тоже все лучше чем кажется - он не забирает рынок, а расширяет его. Юзеры у Меты не уходят, вовлеченность растет. Все еще хорошая машинка по выжиманию дофамина.
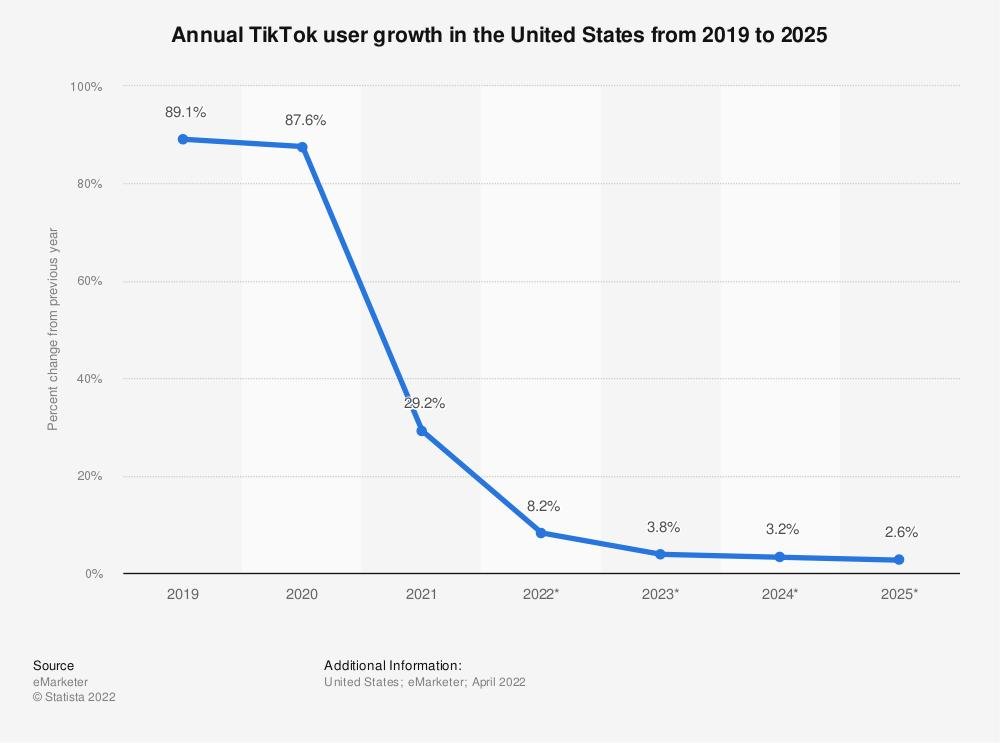
Конкуренция это конечно серьезный повод не расслабляться. Но не уходить же из-за этого на пенсию!
А что делать? Удивительно, но стратегическое решение сразу для обоих угроз (ATT и TikTok) - закупаться железом для нейронок. Универсальный Force Multiplier же.
Крутые алгоритмы и свое железо помогут лучше рекомендовать контент, чтобы не терять людей и предсказывать окупаемость рекламы в обход ATT, чтобы не терять рекламодателей.
Но сейчас у Меты вся инфраструктура заточена под старые рекомендательные модели на процессорах (CPU). А новым нужны дорогущие тензорные видеокарты (TPU).
И.. Марк закупается!
Вот еще раз график, который так напугал инвесторов.
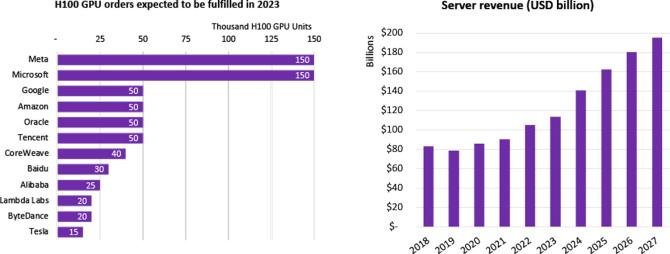
Одна интересная побочная штука. Никто кроме Meta и Google не может себе позволить таких вложений. Это очень сильный рыночный барьер. Скоро никто не сможет делать рекламу с такой же эффективностью как они.
Чтобы немного понимать масштаб (данные не точные):
Опенсорс - Цукерберг хочет сделать нейросети дешевыми
Чтобы продолжить обсуждать барьеры, хочу рассказать идею про те самые чертежи. Эту идею я услышал от Байрама Аннакова. У него есть классный канал про бизнес. Обожаю как он умеет смотреть на вещи со стороны науки и первых принципов.
В чем фишка Опенсорса с точки зрения экономической науки? Вот один из возможных ответов, на примере того как Microsoft давным-давно рубился на рынке через любопытный механизм.
Вспомните про два типа товаров - комплименты и субституты. Первые дополняют друг друга вторые заменяют (конкурируют). Например, софт как товар дополняет ПК, и заменяет вебсайты.
Когда цена дополняющего товара падает -> спрос на продукт растет.
Дешевле компы -> больше юзеров с компами -> больше спрос на приложения.
Если ты превращаешь дополняющий тебя товар в коммодитис (товары массового потребления, когда несколько компаний предлагают почти не отличающиеся друг от друга товары) - твоя ценность растет.
И вот идея - Опенсорс как раз такой превращатель.
Реклама Меты завязана на то что юзеры генерят и потребляют контент. Больше качественного контента -> больше столкновений с рекламой.
Не знаю как у вас, но у меня Инстаграм на 2/3 состоит из рекламы и рекомендаций. Умножаем на 1.4b дневной аудитории и получаем, что рекомендации это дорого.
avg user spends ~40 min in app / day
app makes ~100 predictions per user / day
this costs $0.004 per prediction with gpt 3.5-turbo
so each user costs additional 40 cents / day
old AWS recomendations is much cheaper $0.0000417 / predictionОчень грубо, каждый юзер при текущих ценах на нейронки будет стоить 40 центов в день
Что если предсказания рекомендательной системы станут кратно дешевле? Что если, попробовать превратить нейронки в коммодитис, например, выложив свою модель в открытый доступ.
Открываем модель ->
Коммьюнити допиливает ее и удешевляет ->
Рекомендации модели как товар дешевеют ->
Рост спроса на нейронки, которые раньше были не по карману ->
Рост спроса на рекламу, потому что нейронки дополняют ее эффективность -> бабосики.
Лама - Что же произошло весной?
Ну и неожиданный поворот - в начале весны Meta заопенсорсила свою Foundational LLM под названием LLaMA. Модель не хватала звезд с неба, но в целом была достойной. На обучение без учета зп команде потратили всего ~$3m.
Спозиционировали ее как ОС, но по факту не было доступа к коду для обучения и весам модели. И лицензия не разрешает коммерческое использование. Как то даже стыдно такое ОС называть. Типа только для ресерча.. и полностью модель они планировали давать отдельно по запросу.
Планировали - потому что через неделю два чувака выложили на форчане торрент ссылки на веса модели.
И дальше случилась магия. Про нее я узнал из наделавшей шуму статьи от рандомного чувака из Google.
Основной посыл - что мы в Google сочно продолбались, но пока еще не поздно все поправить. Мы пытаемся усидеть на двух стульях: быть лидером в инновациях и быть гейткипером, не отдавая эти инновации другим.
Большие модели обучать дорого и долго. Нужны крутые ученые и инженеры с шестизначными зп, сервера, данные в огромных количествах.
И.. и все это у Google есть? Бигтех же.
Но в преимуществе лежит слабость.
Архитектура трансформеров, на которой работают все современные модели, создана чуваками из Google 6 лет назад (а идея attention в ее основе вообще из 2014). Оказалось, что архитектура отлично масштабируется, то есть перфоманс модели улучшается с ростом ее размера.
И вот спустя 6 лет мы юзаем те же трансформеры. С доработками, но те же. И на тренировку новых моделей каждый год тратится все больше и больше ресурсов. Экспериментировать и пробовать что то новое в таких условиях долго, дорого и рискованно. Все авторы статьи Attention Is All You Need, где представили архитектуру трансформеров, за это время уволились и разбежались.
На контрасте - опенсорс после выхода Ламы получил возможность много экспериментировать с более слабыми моделями. В итоге куча людей предлагают и пробуют новые идеи.
Год назад похожая история случилась на рынке генерации картинок. Закрытый DALLE-2 всосал конкуренцию открытому Stable Diffusion примерно по той же схеме.
Ну и вывод чувака, что Google и OpenAI, пока бодались между собой, упустили нового игрока - опенсорс. Вот суть статьи в одной цитате: Focusing on maintaining some of the largest models on the planet actually puts us at a disadvantage.
В преимуществе лежит слабость - красиво.
Как обучают большие модели - Ликбез по этапам тренировки
"Утечка" LLaMA - это первый раз когда простым работягам в руки попала Foundational model. То есть прям большая, на которую деньги есть только у богатых компаний. Правда, модель голая (pretrained model) - без наворотов, которые позволяют вести диалог и давать адекватные ответы.
Чтобы разобраться, что это за навороты такие, нужен немножко душный блок про то, из чего состоит обучение модели. В AI/ML уже столько терминов, что без душноты будет сложно. Так как я не настоящий сварщик, то вот классная статья. Попытаюсь ее пересказать.
Чо за большие нейронки то?
- LLM - это Глубинная нейросеть с миллиардами параметров.
- Глубинная - эт когда много слоев цифровых нейронов, каждый из которых все лучше (глубже) "понимает" суть данных. Например, первые слои выделяют линии на картинке, границы обьектов, а последние могут сказать, что это котик.
- Параметры (веса) - это мозг нейронки, замерший в одном состоянии. Это матрицы с коэффициентами, говорящие каким нейронам зажигаться в ответ на определенный набор токенов.
- Токены - это данные, на которых мы учим модель, слова порезаные на кусочки. Тут можно посмотреть как это выглядит.
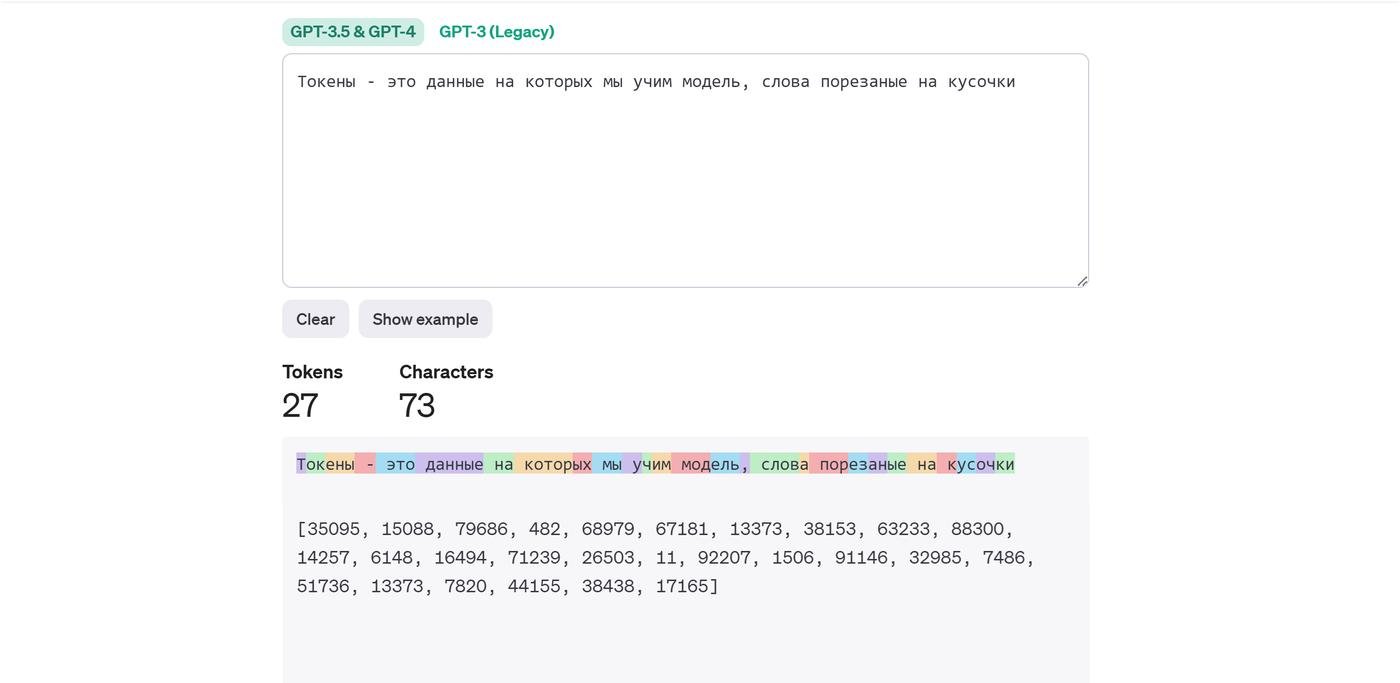
В тренировке несколько этапов.
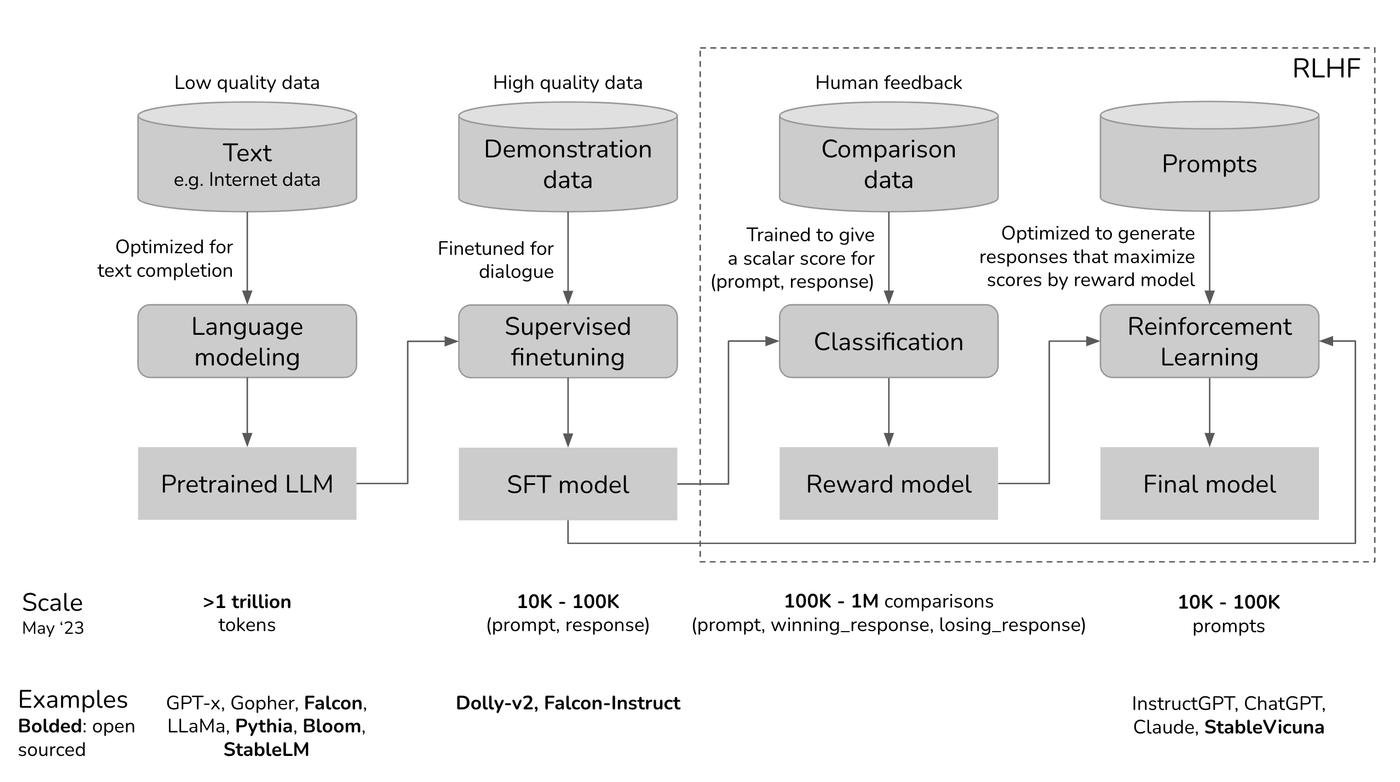
1 . Pre-training - учим (unsupervised learning) модель предсказывать следующий токен, постоянно корректируя веса, исходя из функции потерь (плохо / хорошо). Плохо предсказала? Чуток меняем веса. И с каждым шагом cтановится лучше.
Тут модель учится "понимать" язык. Мы с вами моментально на интуиции понимаем, как можно продолжить фразу "Мой любимый цвет ...". И вот тут модель "запоминает" какие слова подходят лучше, что есть разные варианты итп.
2 . Supervised finetuning (SFT) - дообучаем модель, чтобы она умела вести диалог и выполнять инструкции. До этого этапа модель училась на текстах из интрнета (безумный микс сеошных статей и хейтспича). И даже если она понимает как дополнить фразу, не факт, что это будет то что хочет юзер.
Например, спрашиваем ее "Как приготовить пиццу". Понятно, что это запрос на какую-то инструкцию и рецепт. Но если модель училась только дополнять текст, так что она может выдать что то вроде этого:
"Как приготовить пиццу для семьи из шести человек? Мать семейства работает ..."
"Как приготовить пиццу? Какие ингредиенты мне нужны? Сколько времени это займет?"
Кажется, тут юзер не хочет рассказ про семью или бесконечный спам вопросами - он хочет рецепт. Чтобы это пофиксить - накидываем модели качественные данные, размеченые людьми или спижженые со StackOverflow.
Тут модель учится "понимать" контекст, делать саммари, отвечать на вопросы, вести диалог и всяким другим штукам.
3 . RLHF - Reinforcement learning from human feedback. Даже понимая контекст, можно ответить по-разному. А мы никак не даем модели понять, какой ответ понравится юзеру. Например, не учим ее, что газлайтить юзера - плохо.
Фиксится это сложно. Нужно натренировать отдельную вспомогательную модель (reward model) на основе существующей, которую научить оценивать хорошесть пар промпт-ответ. А затем оптимизировать основную модель с SFT этапа, чтобы она давала ответы с высокой оценкой.
Сложно потому, что тут нужны ОООчень хорошие дынные. Чуваки, вручную сравнивают разные ответы на те же вопросы и выбирают что лучше. Потом из этого получается оценочная функция, которая поставит низкую оценку ответу с газлайтингом после промпта юзера про пиццу.
Мы тут не даем модели новые знания, они у нее уже итак есть где-то внутри. Просто мы ее калибруем, чтобы модель выбирала хорошие варианты. Тут не нужно много данных, а важно их качество.
Магия ОС - Бигтех испугался быстро сокращения отставания?
Напомню, что Meta выложили голую pre-trained модель. И буквально за месяц комьюнити запилили все недостающие шаги - файнтюнинг (SFT) на инструкции, RLHF, мультимодальность (это когда не только текст, но еще и картинки). Построили кучу прикольной инфраструктуры для разработчиков.
Cамое интересное - это LoRA, техника сильно (в тысячи раз) снижающая затраты на файнтюнинг. Автор затюнил модель за пару часов на своей игровой GPU за $1.5к. А через пару дней другой чувак смог доработать и запустить модель на маке на встроенной видеокарте.
Ок, впечатляет. Но насколько она хуже топовых моделей?
Сильно хуже, особенно в сложных задачах.

Но дальше пошли улучшения на основе Ламы. Модель Vicuna-13b со стоимостью в $300 дает такие же результаты как гугловский чатбот Bard на основе PaLM-2 за $9+ миллионов. Это где то 90% качества ChatGPT!
Хотя, стоит сказать что дообучали ее с помощью синтетических данных от ChatGPT (aka спиздили с форумов 70к топовых диалогов), что не совсем легально.
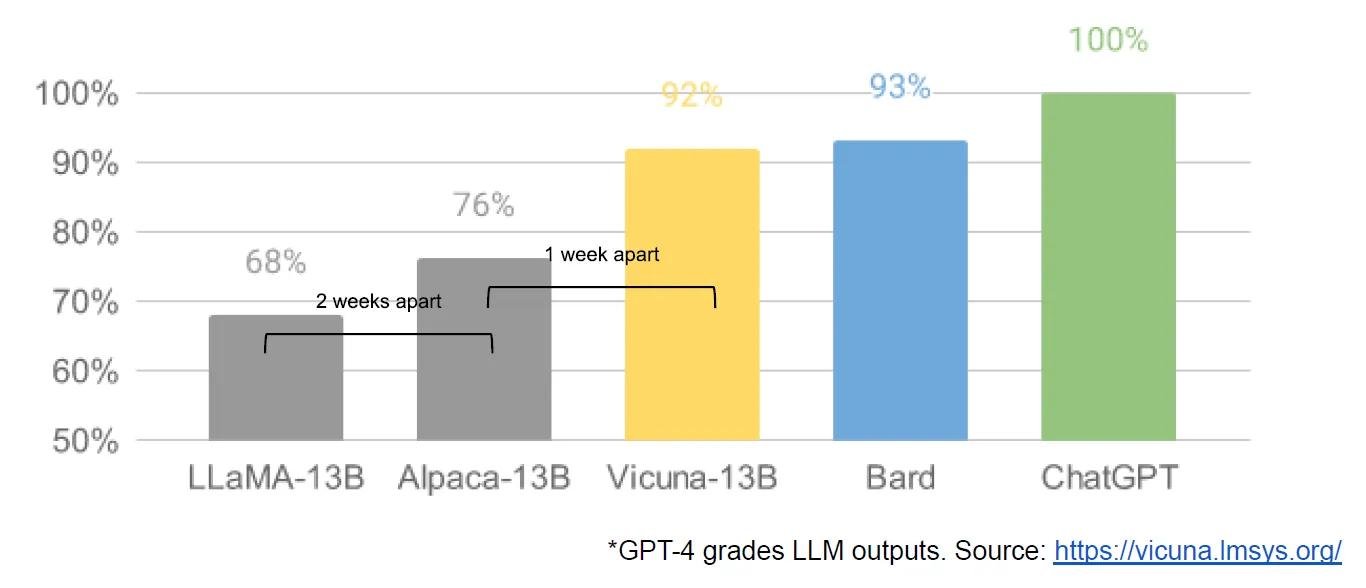
В общем, схема такая:
- Meta выпускает LLaMA ->
- Много людей получило возможность экспериментировать на основе идей друг друга ->
- Количество экспериментов больше, чем у любого бигтеха ->
- Близкие к топовым моделям результаты, но за 300 баксов.
Вот тут можно бенчмарки смотреть.
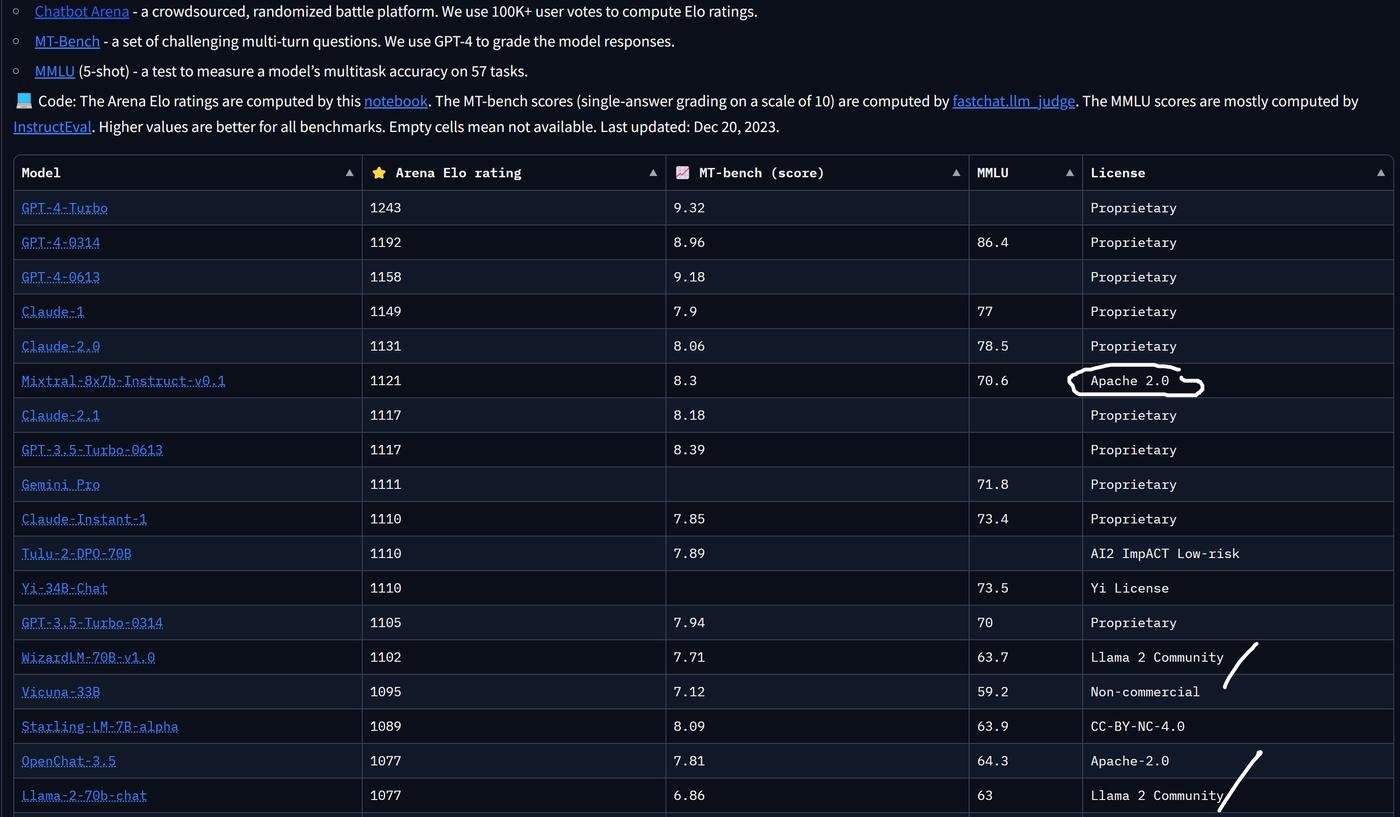
Спустя полгода, Meta выложили новую версию. И Microsoft совсем недавно натренировали на ее основе модель Orca 2.
Основной фишкой, почему ОС модели такие крутые - их как учитель "обучает" старшая модель. Грубо говоря, они дистиллируют знания GPT-3.5 или GPT-4. И для части задач это сделать сложнее, например в написании кода или в умении расуждать и выбирать из разных стратегий.
Ну и вот Orca 2 исследует, можно ли научить модель намного меньшего размера рассуждать.
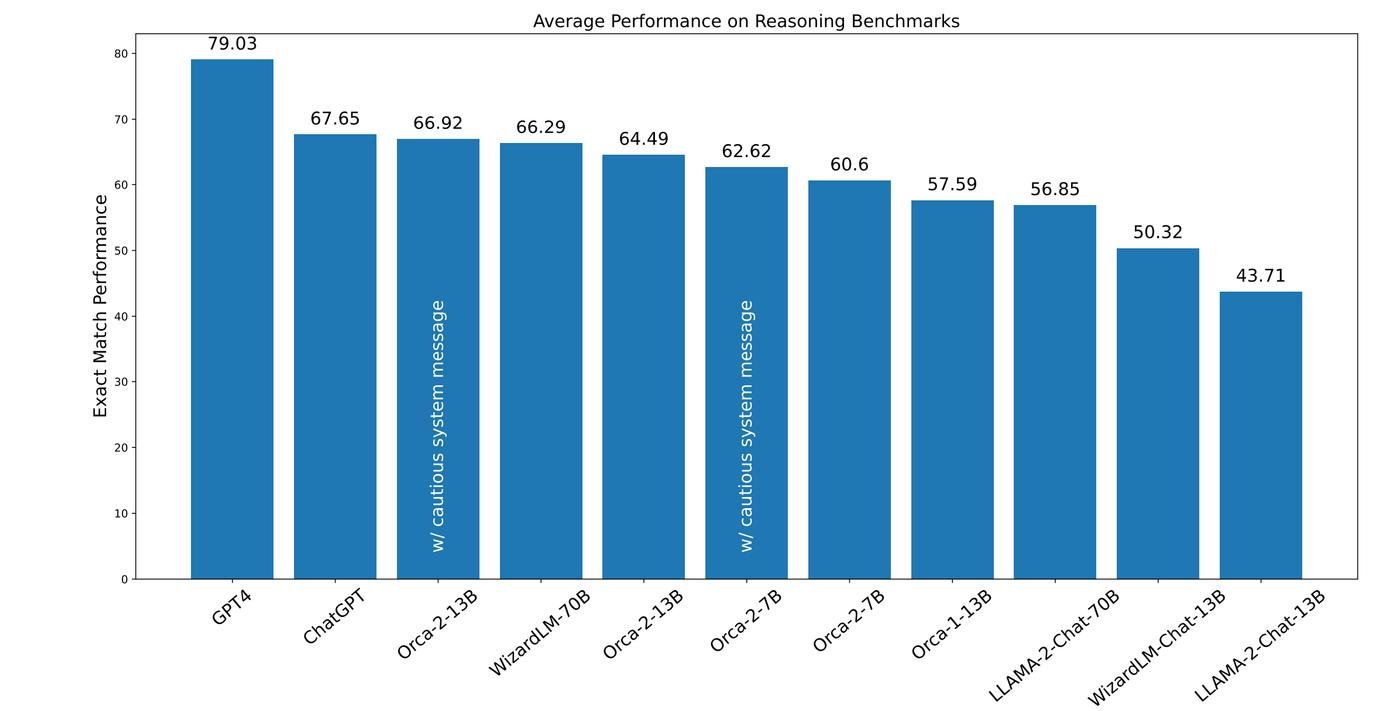
Ну то есть реально почти что угодно сделать? Да, эти модели пока уступают топовым, но совсем немного. Получается, что барьеры бигтеха больше не работают?
Вот кстати эти барьеры, слева направо:
- Вычислительные мощности
- Данные для обучения
- Новые алгоритмы и архитектуры
Опенсорс показал, что сократить отставание от лидера можно в разы дешевле и очень быстро. И чем дальше, тем дороже будет обходиться лидерство.
Дальше подробнее про каждый из барьеров.
Барьер 1 - У бигтеха большие датацентры
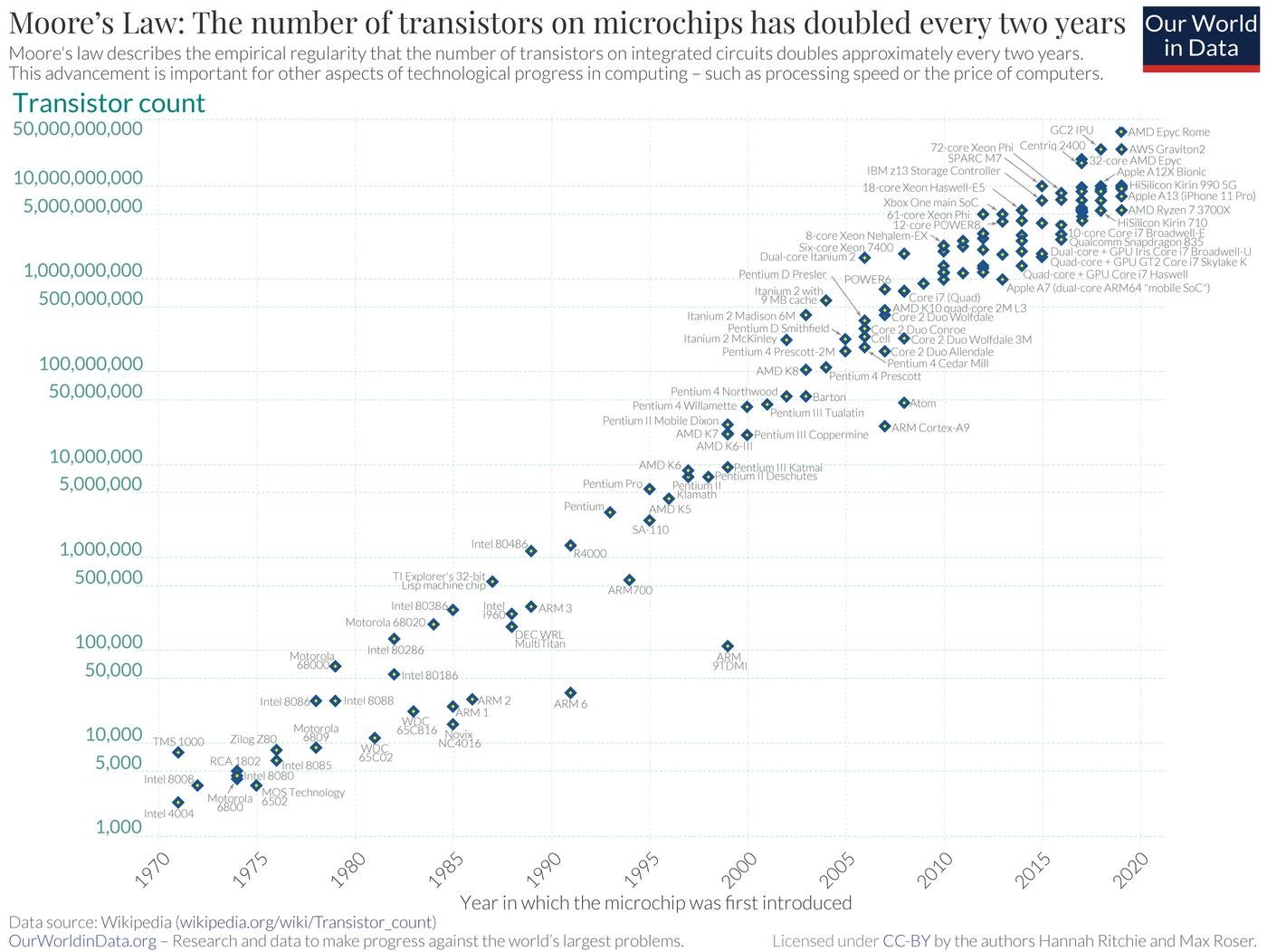
В 2019 году, Richard Sutton (один из топовых ресерчеров по RL) сформулировал классную мысль с мемным названием - Горький Урок.
Самый большой урок за 70 лет AI исследований в том, что методы, которые проще всего масштабируют вычисления, в конечном итоге оказываются наиболее эффективными, причем с большим отрывом.
Ну и вот оказывается, что у больших компаний уже есть большие датацентры. И, кажется, это сильный барьер, потому что эффективность моделей упирается в вычисления. Хочу дальше понять, насколько высоко этот барьер высокий.
Чтобы юзеры смогли пользоваться, модель нужно сначала обучить, а потом выложить в продакшн. Все это стоит денег на команду и датацентры.
Чтобы понять сколько, перескажу несколько статей: раз и два.
Стоимость обучения
Большая часть денег (80%) уходит на инфраструктуру, а остальное на команду. Две трети инфраструктуры это видеокарты.
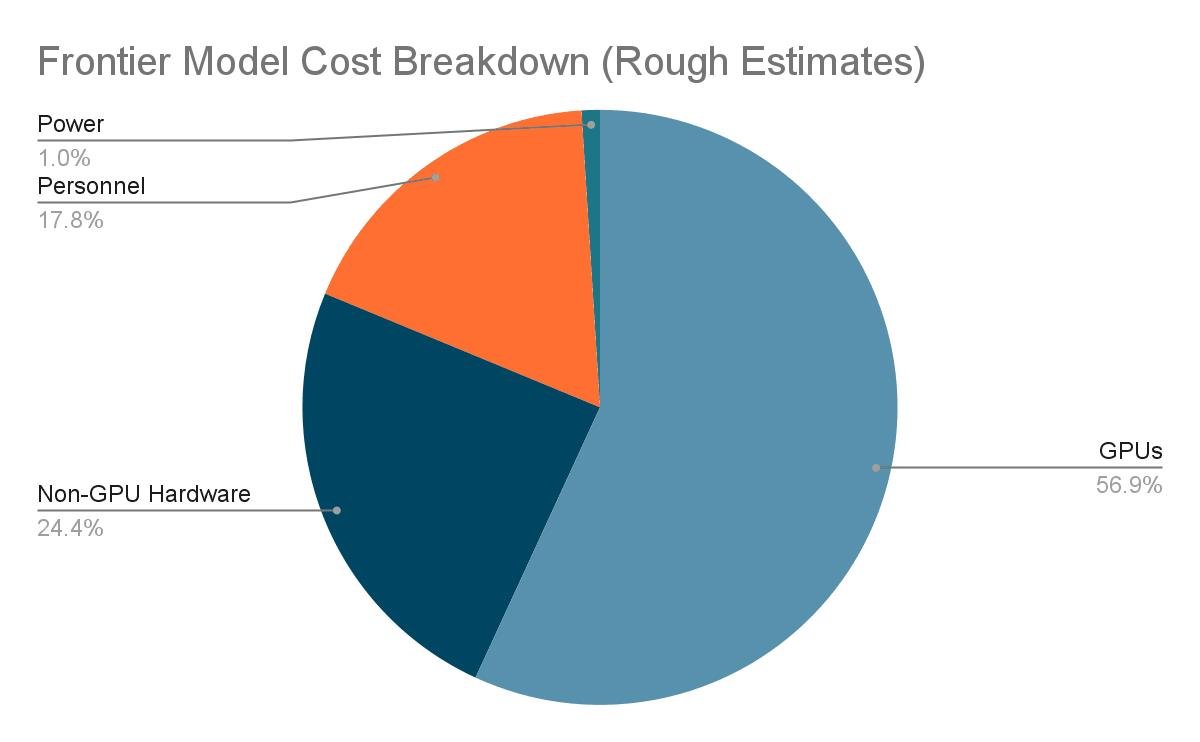
Чтобы это в бабосики перевести, есть простая формула:
Стоимость зависит от: 6 * Размер модели * Обьем данных для тренировки * Стоимость вычислений.
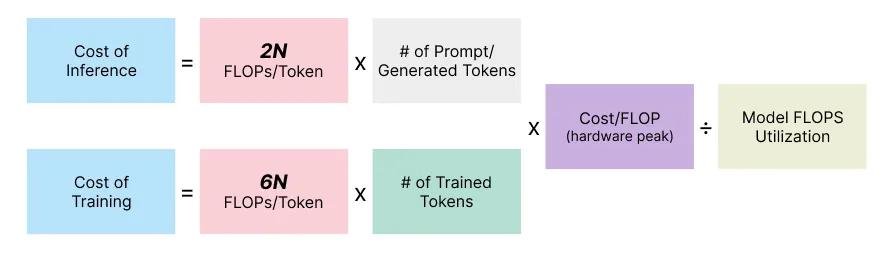
Например, GPT-3 размером 175b параметров. Это значит, что 1 токен, просеяный через модель это 6 * 175b. Это один, а модель обучалась на 500b токенах. То есть это уже 6 * 175b * 500b.
Чувствуете проблему? Размер моделей и обьем данных постоянно растут и перемножаются друг на друга.
Чтобы первратить наши 6 * 175b * 500b в бабки, нужно еще понять как дорого это вычислять.
Стоимость вычислений
Вычисления это операции с циферками, их много разных типов есть. Самый популярный способ измерить - это посчитать FLOPS. Не важно че это, просто один из типов операций. Урощая FLOPS = вычисления в секунду.
Они зависят от трех вещей:
1 . Тензорных карт.
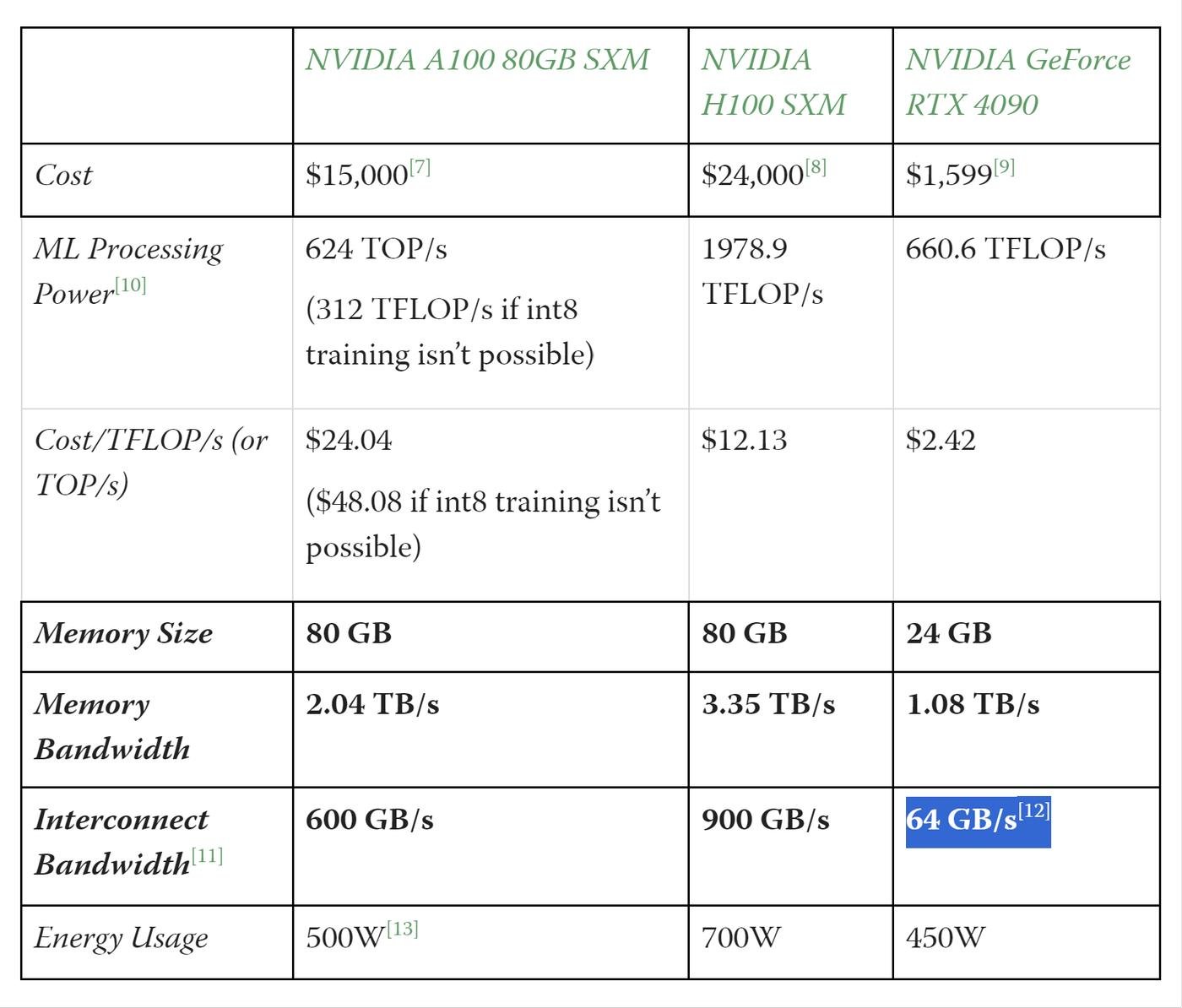
Это специальные видеокарты, которые умеют напрямую работать с матрицами весов, а не с векторами. Они в 2 раза эффективнее по вычислениям на $1.
Чтобы не тренировать супер долго, карт нужно много. Например, GPT-3 тренировали ~2 недели на 10k карт. Одна такая карта (Nvidia A100) стоит $15k. Дорого.

2 . Стоимости электричества и обслуживания датацентра.
Сейчас электричество это меньше 5% общей стоимости. С каждым поколением карт (~2 года) эффективность растет в полтора-два раза. И в энергоэффективности и в вычислениях на 1$. Короче, пока это не такая важная часть расходов.
3 . Утилизации карт.
Больше половины мощностей карт нельзя (пока что) использовать из за ограничений пропускной способности. Карта проставивает, ожидая разных других операций, типа записи или чтения из памяти, синка с другими картами в кластере и тп. А еще иногда во время обучения делают откаты, возвращая модель к предыдущим состояниям.
Когда размер кластера (кусок датацентра на котором идет тренировка) растет, число связей, которые нужно поддерживать картам друг с другом, растет нелинейно. В цену карт заложены технологии, позоляющие делать это лучше. Что делает тензорные карты в 10 раз дороже игровых.
У карт предыдущего поколения плохо растет эффективность при масштабировании
Еще можно использовать чужое облако, чтобы не покупать карты. С 2020 года, стоимость облачных вычислений упала на 60%. Но если трейнить на своем железе - все равно получается раза в 2 дешевле.
С другой стороны Nvidia скорее всего продает карты с огромной наценкой за монополию и высокий спрос. Возможно (оч спекулятивно), карты стоят x5 от их себестоимости.
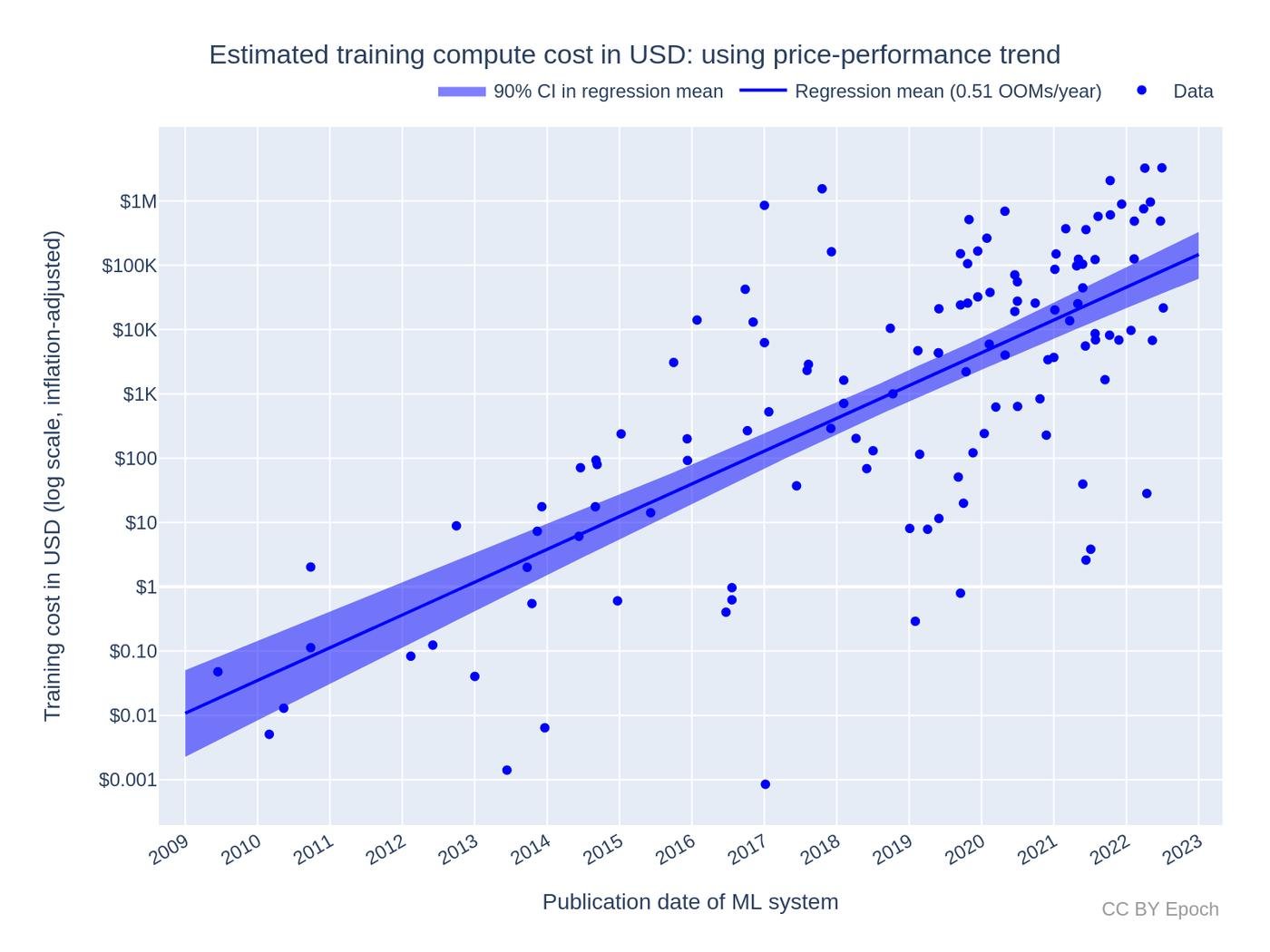
Ок, если посчитать общую сумму, то GPT-3 стоила ~$1.4m по ценам облака того времени. Кажется немного, но помните проблему, что в основной формуле все перемножается? Допустим, вы увеличиваете данные и размер в 10 раз и.. 10 * 10 = 100.
Фронтирные модели, кстати, уже в 100 раз дороже: GPT-4 ~$0.5b, Claude 2 ~1b (оч спекулятвино).
Стоимость работы (inference)
Ладно, модель обучили и выложили в прод. Сколько стоит ее работа Когда юзер отправляет запрос - модель послностью прокручивается, чтобы выдать новый токен.
Формула похожая: 2 * Размер модели * Количество запросов * Стоимость вычислений.
Вот тут посчитали (на начало 2023) во сколько обходится OpenAI обслуживание ChatGPT для 100m юзеров. Это почти 30k карт A100 и ~$21m в месяц.
Оговорюсь, что расчет в статье для ChatGPT, который в то время работал на GPT-3.5. Вот тут нашел, что на обучение 3.5 потратили в ~10 раз больше вычислений, чем на GPT-3.
За точность не ручаюсь, но хочу сделать вывод: На количестве юзеров OpenAI, стоимость обучения модели сравнима с несколькими неделями ее работы в проде.
Можно придумать много всего, чтобы снизить стоимость инференса. Например, можно инференсить на картах предыдущего поколения. Но все равно думаю что вывод останется тем же.
Если у вас много юзеров - продакшн это очень дорого.
Последнее обновление цен на API для GPT-4: ~1.5 страницы текста стоят $0.03. Звучит дешево, но умножаем это на сотни миллионов юзеров и десятки запросов в день от каждого... Думаю, что вместе с другими моделями в конце осени 2023 их затраты на инференс ~$100m в месяц.
Плюс стоимость обучения новых моделей плюс 20% на команду. В общем, это миллиарды в год.
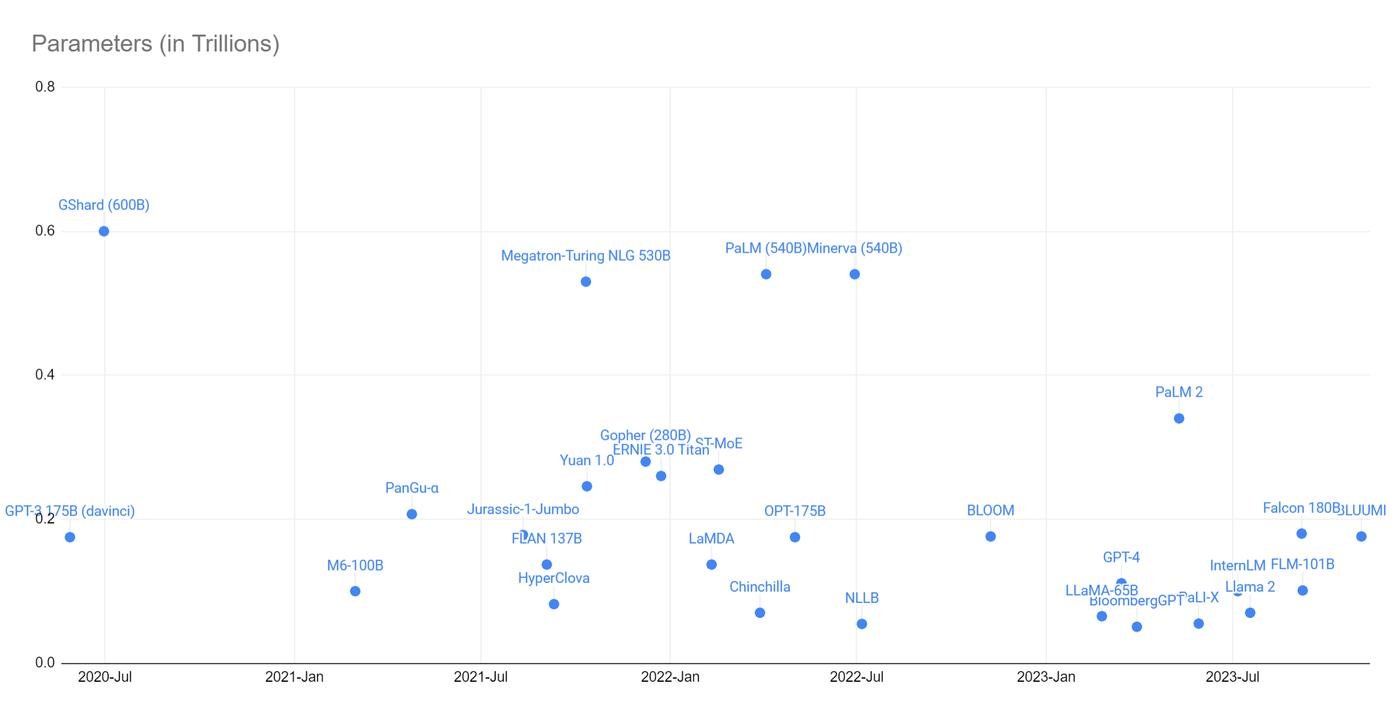
Сколько нужно рынку
На рынке GPU сложилась интересная ситуация. Большинство гиперскейлеров (так называют 4 крупных облака: Azure, AWS, GCP, Oracle), облаков поменьше (CoreWeave, Lambda) и AI лабораторий хотят намного больше карт H100, чем могут получить.
На середину лета 2023, спрос был на почти пол-миллиона карт. Это где-то $20b. И все это производят Nvidia и TSMC.
Производство карт невероятно сложный процесс.
Nvidia делает дизайн (придумывает карты) и собирает его на тайваньских заводах TSMC. Переходить на видеокарты не от Nvidia пока сложно. AMD недавно заанонсили свои, но у Nvidia намного лучше выстроена экосистема вокруг деплоя (CUDA).
Короче, только одна компания в мире делает основное железо для всей AI отрасли. И немножко не вывозит обьемы. А их конкуренты (Samsung и Intel) пока просто не умеют собирать нужные четырехнанометровые процессоры.
Вот вам коротенький видосик, про то насколько это магически обалденная технология. Реально стоит 13 минут просмотра!
Сейчас у TSMC основной затык в CoWoS (Chip-on-Wafer-on-Substrate). Это процесс вертикального соединения чипов друг с другом в более компактные 3д стэки.
Короче, если вы стартап и хотите 5к карт - смело становимся в очередь на полгода. Большинство предпочитают резервировать мощности у гиперскейлеров на длительный срок. Либо покупать свои серваки и аутсорсить их размещение и обслуживание.
Но это не все еще!
Nvidia прекрасно пользуется дефицитом на рынке. Они наверняка завышают цены. Но самая мякотка - выбирают того кому продавать большие обьемы. То есть, если Microsoft приходит за покупками, Nvidia спрашивает кто будет конечным пользователем!
Например, AI лаба Inflection уже получила свой заказ и облако CoreWeave тоже. По чистому совпадению Nvidia инвестор обоих. Ну и не дает приоритет копаниям с конкурирущими им продуктами, например Google или Amazon.
В общем, могут ли бигтех компании позволить себе тратить миллиарды, чтобы оставаться в лидерах?
Пока да.

Чтобы понять, почему пока и как долго оно продлится, го изучать следующий раздел.
Барьер 2 - У бигтеха много данных
Думаю, чтобы понять, почему вычислений никогда не будет достаточно, нужно разобраться с темой скейлинга.
Законы масштабирования
Jared Kaplan, один из основателей AI лаборатории Anthropic, до своего ухода из OpenAI успел выпустить оч важное исследование.
Оно показало, что можно предсказуемо увеличивать способности модели, увеличивая ее размер и обьем данных. А все остальное не то чтобы важно. Примерно вот такой вайб:
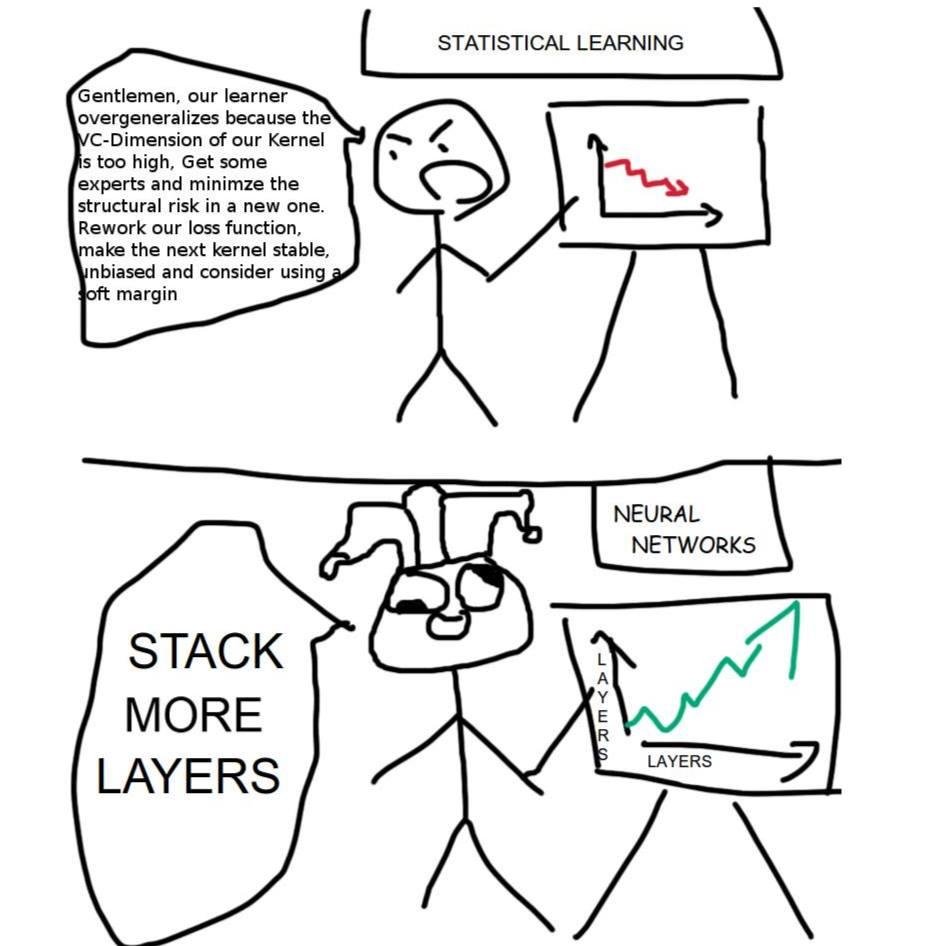
Этот вывод получил название Kaplan scaling laws и полсужил аргументом к попытке натренировать модель побольше. Статья вышла в январе 2020, через полгода после анонса первого миллиарда инвестиций от Microsoft.
И еще через полгода, летом 2020, выходит GPT-3 и показывает, что масштабирование работает!
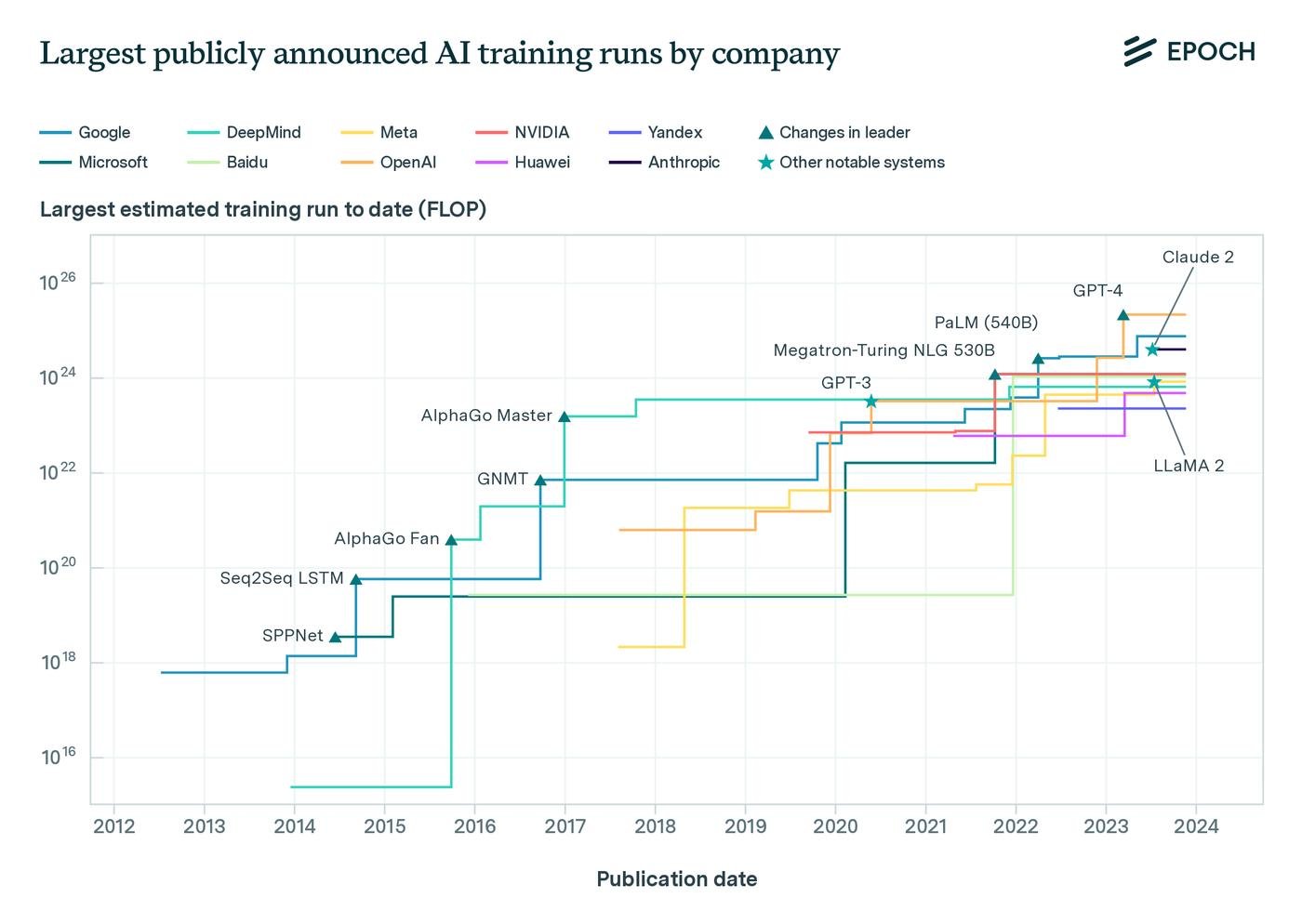
В области языковых задач есть куча направлений, типа перевода или ответа на вопросы. И в каждом лидировала своя, специально заточеная только под него модель. Так вот GPT-3 смогла показать топовые результаты сразу во всех направлениях!
Круто! Но..
Новые законы масштабирования
Год назад в Deepmind провели эксперимент, чтобы уточнить закономерности из статьи Каплана. Оказалось, что большинство моделей того времени недотренированы. То есть их размер позволял слопать намного больше данных, чем было заюзано при обучении.
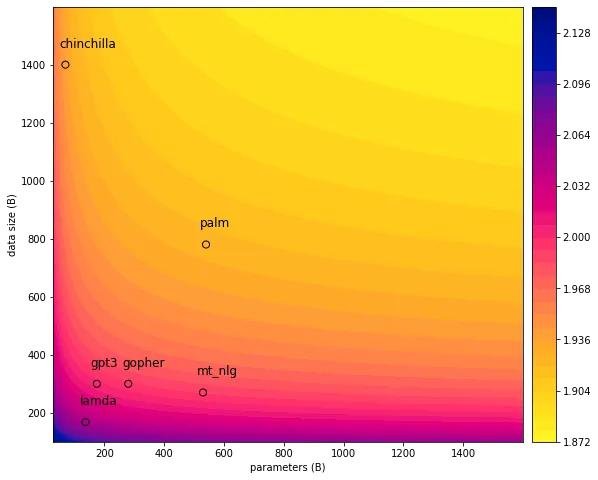
Выяснилось, что Шиншилла перформит близко к гугловской Palm, хотя последняя в 5 раз больше.
Короче, появился новый закон масштабирования - Hoffmann scaling laws. Ребята рассчитали каким в идеале должно быть соотношение размера и данных, при заданном бюджете на вычисления.
Их основной вывод - с какого то момента увеличивать размер модели без увеличения данных становится бессмысленно. Тогда все тренировали меньше чем на 500b токенов как у GPT-3.
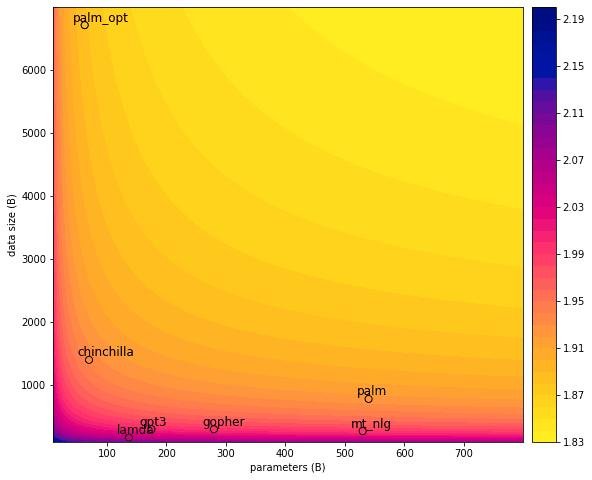
Оказалось, что трейнить большие модели на таких данных это лютое расточительство.
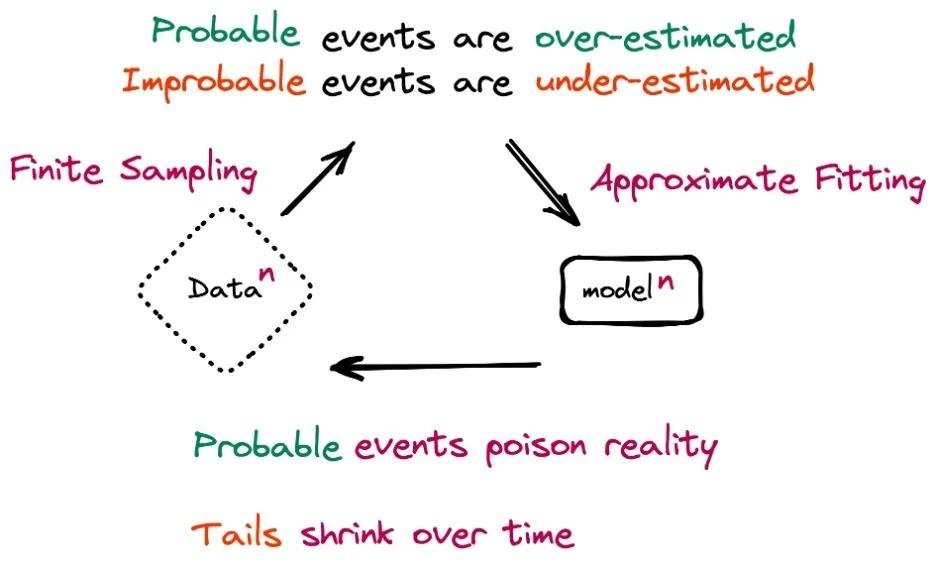
А поэтому данные вдруг тоже стали сильным барьером. Их, внезапно, конечное количество. И оно меньше, чем хотелось бы. Но не все так плохо.
Сколько есть данных?
На 2022 в открытом доступе было ~3.6t токенов. Это грубая оценка, потому что не понятно как разные источники складывать. Вот что есть:
1 . Сырые текстовые данные от парсеров интренета
CommonCrawl - самая большая публично доступная репа на 100t слов. Но это прям сырые данные и после их фильтрации остается меньше 1% которыми можно пользоваться.
RedPajama - это датасет с 30t токенов отфильтрованых из Common Crawl. Не знаю насколько все эти токены можно использовать, датасет появился осенью 2023. Авторы собрали все эвристики со всех других попыток фильтровать CC и кажется получилось что то прорывного качества.
MassiveWeb - 506b
PaLM - 211b+
2 . Специфичные данные
Код - Большая часть кода с GitHub уже вычерпана в ~1t токенов. И это в принципе большая часть всего кода. Больше нет нигде.
Arxiv и PubMed - Научные статьи тоже вычерпаны в 21b токенов.
Книги - Тут все мутно, потому что не оч понятно откуда рызные датасеты взяли книги ~1t.
Хороших данных в открытом доступе меньше, чем хотелось бы. Особенно качественных типа кода, научных статей или длинных цепочек рассуждений.
Что еще есть?
3 . Другие домены
Например, картинки и видео. Заметили, что в 2023 вдруг все хотят делать мультимодальные модели?
Другие языки. Сейчас больше 2/3 это английский.
- Приватные данные
Бигтех с доступом к непубличным данным имеет намного больше данных, чем простые смертные. Meta (данные ФБ), Google (почта), Microsoft (Outlook), Apple (imessage), правительство Китая может легко забрать данные у своих интернет компаний.
Неэтично, но очень соблазнительно. Например, Google тестировал идею unlearning - когда ты сначала обучешь модель на приватных данных, а потом вычищаешь их из модели.
- Синтетические данные
Он не верит, что возможно продолжать скейлить модели на реальных данных из интернета. Но данные - это не боттлнек, тк будут модельки которые умеют хорошо генерить данные сами.
Синтетические данные
Как такое возможно? Начну с примера из компьютерного зрения.
Можно создавать новые картинки на основе уже существующих. Ключевая идея - увеличить разнообразие за счет изменения отдельных деталей.
Например, брать обьект с одной картинки и подставить фон с кучи других. Это в ~100 раз дешевле. И, чем больше датасет, тем проще.
А с текстами такое провернуть сложнее, тк язык имеет особую структуру и там проще накосячить сделав данные бессмысленными.
Если модель рекурсивно учить переиспользуя ее же текст, начинаются дегенеративные процессы и случается model collapse.
Еще пример - это Self-play.
В 2017 Deepmind выпустили офигенный фильм про AlphaGO, где нейронки научились выигрывать в игру Го. Многие считали это невозможным, но AlphaGO без шансов выиграла у чемпиона Ли Седоля.
Прикол в том, что они на этом не остановились и сделали следующую модель. AlphaGO Zero, которую не учили на играх крутых игроков. Она наиграла сама с собой 5 миллионов игр. И после этого разьебала обычную AlphaGO со счетом 100 - 0.
Ли Седоль сказал, что против нее невозможно играть и закончил карьеру.
Языковая нейронка может делать что то похожее на self-play. Ее можно просить нагенерить задачки со сложным решением, но которое легко проверить. А потом попросить решить. И так тренироваться.
Есть возражение, что синтетические данные не создают новое знание. Они просто дистиллируют то, что уже заложено в модель. Или просто переливают знания из одной модели в другую.
Ну и отлично! Например, хорошим промптом можно улучшить результат ответа, заставив модель рассуждать, выбирать стратегию и следовать плану. Мы в этот момент не добавляем новых знаний, а просто подсказываем, что тут нужна рефлексия.
В данных зарыто ооочень много неожиданных следствий, взаимосвязей и всякого такого. Так что бесконечное количество данных не то чтобы нужно. Вот свежий пример статьи с выводом, что будущее за синтетическими данными.
Качественные данные
Грубо, схема такая:
- Есть совсем сырые данные, мы их фильтруем, чтобы на них можно было хоть чему то учиться.
- Начинаем учить модель на хоть и фильтрованых, но ахти какого качества данных. Тут модель учится вдуплять, чо вообще такое текст.
- Учим модель продвинутому дерьму. Тут уже не достаточно просто кормить ее потоком рандомных постов с Реддита. Нужны качественные данные.
За последние пол-года появилось появилось несколько мальеньких моделей, но на супер качественных данных. Им даже отдельное название выдали - SLM (small language model).
Хочу рассказать про phi-1 от Microsoft.

Ребята запрягли GPT-4 размечать, какие данные будут полезными студенту, который хочет научиться кодить. Затем еще одна модель помогла выбрать из уже размеченых данных лучшие.
Вот что получилось:
- 6b curated tokens from StachOverflow
- 1b synthetic GPT 3.5 Python code
- 180m tokens of Python exercises
Всего 7b токенов для обучения. Модель крохотная. Результаты - это топ3 модель по умению писать код. Невероятно круто для модели размером 1.3b параметров.
Тут есть две интересные штуки.
Самый большой эффект дало добавление практических упражнений с обьяснениями к текстбукам.
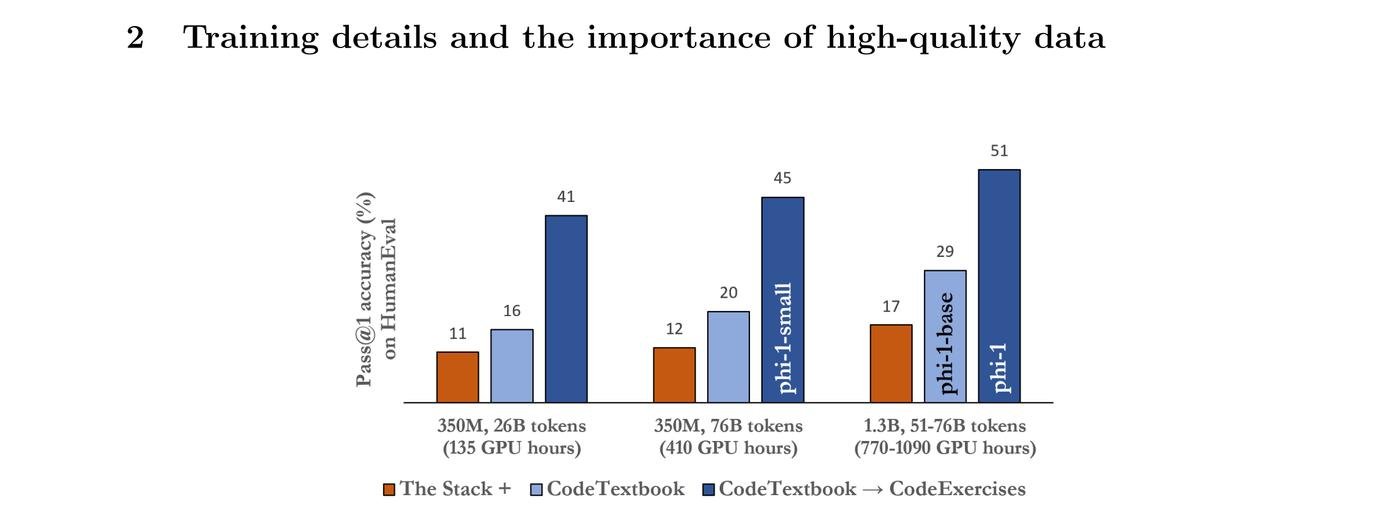
А еще прикольно, что количество эпох было намного больше обычного. Большую часть данных при обучении несколько раз переиспользуют. Это называется Эпохи, их обычно немного, примерно от 1 до 4. Так вот у Phi-1 их 40!
То есть модель из раза в раз гоняли по тем же несчастным данным. И это круто работает, когда данные такого качества!
Короче, чем лучше данные, тем лучше.
Когда данные станет не хватать?
Нашел ресерч, где ребята сделали крутой прогноз.
Размеры датасетов растут гораздо быстрее, чем появляются новые данные. То есть при таком тренде они неизбежно закончатся.
Запасы данных хорошего качества назодятся где то между 4.6b и 1.7t слов. Очень большой разброс в точности. Но вывод все равно можно сделать - мы в паре лет от исчерпания запаса.
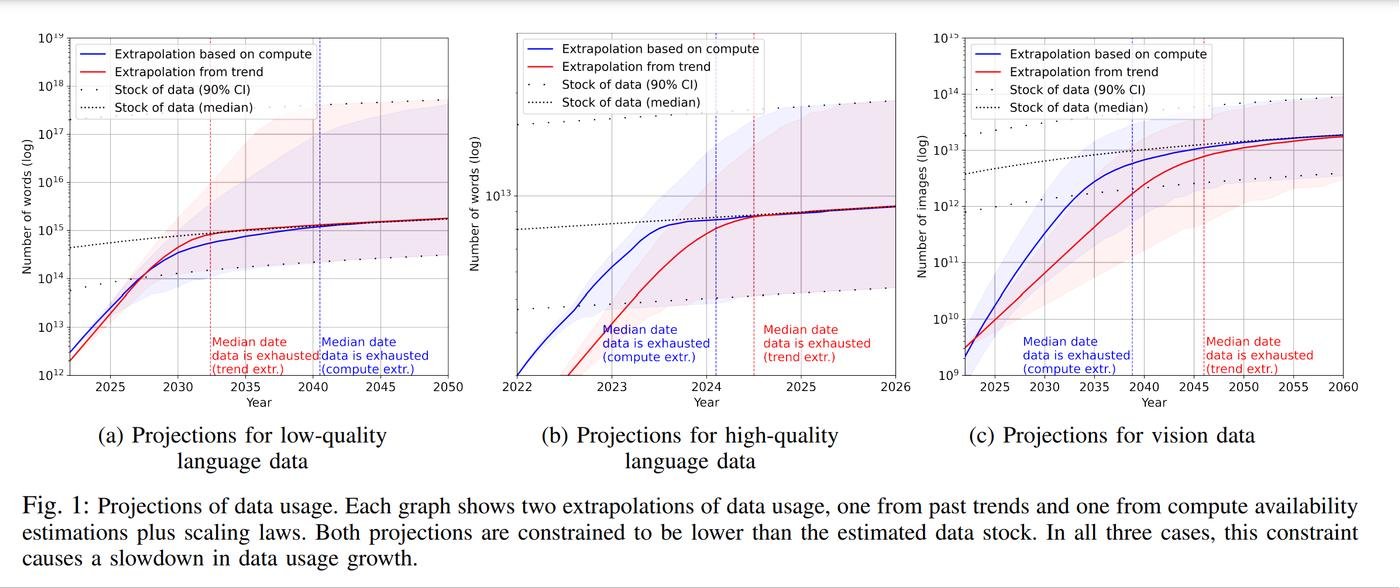
У ребят норм методология, но они много чего не учли.
- data efficiency - новые способы фильтровать сырые данные
- synthetic data - про это выше
- algorithmic factors - если найдут что то получше транформеров
- economic factors - если станет слишком дорого и рост замедлится
Ладно, можно ли какой то общий вывод сделать? Прошлый раздел я закончил на идее, что бигтех пока может тратить миллиарды.
Теперь к этому можно добавить, что траты растут супер быстро и превращаются в расточительность. Потому, что нужно тренировать на большем количестве качественных данных.
Но в АИ лабах работают запредельно умные ребята, они все прекрасно понимают. Было бы странно ожидать другого, ведь это на их работы я ссылаюсь всю статью. Короче, после выхода исследования по Шиншилле, тренд поменялся.
Следите за руками!
Например, GPT-4 по слухам (официальной инфы до сих пор нет) это не просто одна огромная модель, а ансамбль из 16 моделей по 111b параметров. И там есть прикольная оптимизация, чтобы на инференсе не вся модель прокручивалась, а только 15%. Обучали ее на 13t токенов. Что уже намного круче.
Когда модель становится больше - она становится медленнее из-за роста нагрузки на пропускную способность. И OpenAI проделали офигенную работу по оптимизации. Это больше не похоже на заливание деньгами любой проблемы.
А проблемы есть и их много. Го в следующий барьер!
Барьер 3 - Бигтех создает новые алгоритмы
У законов масштабирования 3 компоненты - размер модели, данные и алгоритмы. Последнее, это про то как использовать тот же обьем вычислений, но получить лучше результат. Как пример, впечатляющая оптимизация затрат у GPT-4.
Алгоритмы это важно
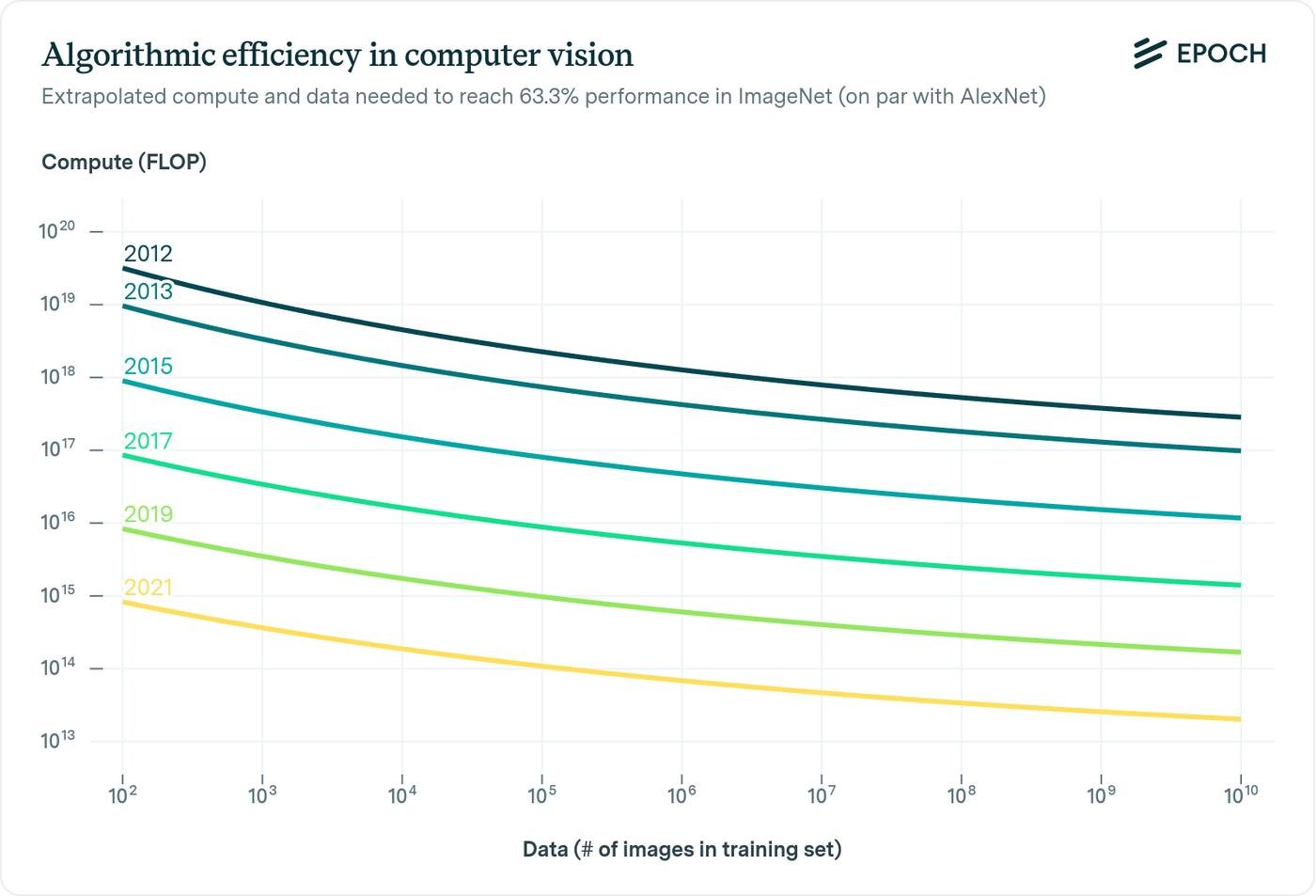
Улучшение алгоритмов - это ощутимая сила. Вот это иследование даже показывает, что эффект намного круче, чем от закона Мура. Каждые 9 месяцев новые алогоритмы дают эффект как от удвоения вычислительных бюджетов.
Ребята проводили все исследование на основе 10 лет развития в компьютерном зрении. И грубо, весь прогресс был на
- ~45% из за скейлинга вычислений
- ~10% скейлинга данных
- ~45% улучшение алгоритмов
Норм, да?
По языковым моделям сложнее сделать вывод, но кажется эффект ещё сильнее. Например, только переход на оптимальные значения от Шиншиллы дает х4 рост.
Способы улучшить готовую модель
В другой статье тот же чувак решил изучить, насколько круто можно прокачать уже натренированую модель после обучения. Уже полно способов такое делать.
Разные методы он предложил сравнивать через эквивалент сэкономленых вычислений. Если какой нибудь метод улучшает модель, то того же самого можно добиться увеличением затрат на вычисления.
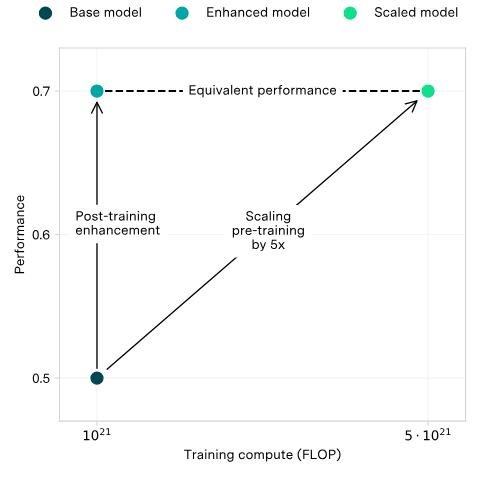
Сами методы не бесплатные, хотя довольно дешевые и выгодные.
- Затраты могут быть одноразовыми - например, научить модель пользоваться поиском в интернете.
- А могут быть постоянными - например, каждый раз просить модель нагенерить несколько вариантов и выбирать лучший.
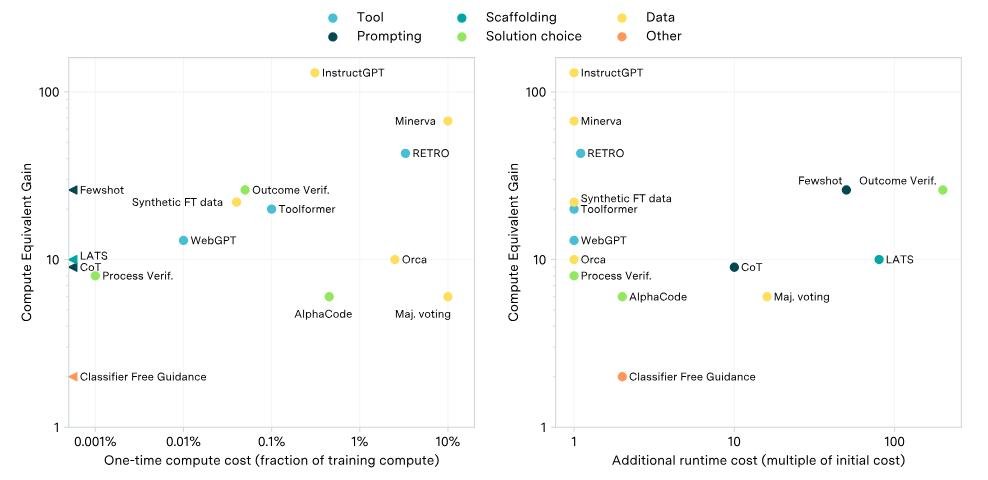
Новые архитектуры
Трансфармеры на которых работают все LLM не особенно то и хороши. Например, люди у себя в мозгах делают что то на много порядков более эффективное по затратам ресурсов. Но нейронки компенсируют неэффективность алгоритмов отличной масштабируемостью. Помните про Горький Урок?
Так вот, в последнее время появляется все больше разговоров о убывающей отдаче у маштабирования. Чем способнее модель, тем кратно дороже каждый следующий апгрейд.
Видимо есть что то еще, чего мы пока не понимаем, как в случае с работой мозга. Возможно недостающая часть - это способность модели самой проводить эксперименты и учиться на результатах. То есть обучение станет активным и непрерывным. Помните как у Phi-1 выросла эффективность, когда ей дали упражнения по написанию кода?
Вот что про это Сэм Альтман говорил:
- Скейлинг все еще играет большую роль
- Они работают над новой парадигмой, которая даст рост на три порядка!
- Часть парадигмы - это онлайн обучение
Сейчас модели после всех процессов дообучения - статичны. В новом окне чата модель не помнит ничего, что было в старом. Онлайн обучение дает ей менять свои веса и internal states когда юзер или сама модель накидывает новые данные.
Тут сразу много вопросиков к оверфиту, стабильности работы и этике. Пока не буду про это писать.
Еще одна потенцильно недостающая чать - это Эмбадимент.
То есть наличие у модели внутреннией картины мира. Качество этой картины кажется напрямую завязано на возможность экспериментировать и искать границы.
Вот тут классно показано, почему это важно. Нейросети страшно тупят в задачах, которые касаются физического мира.
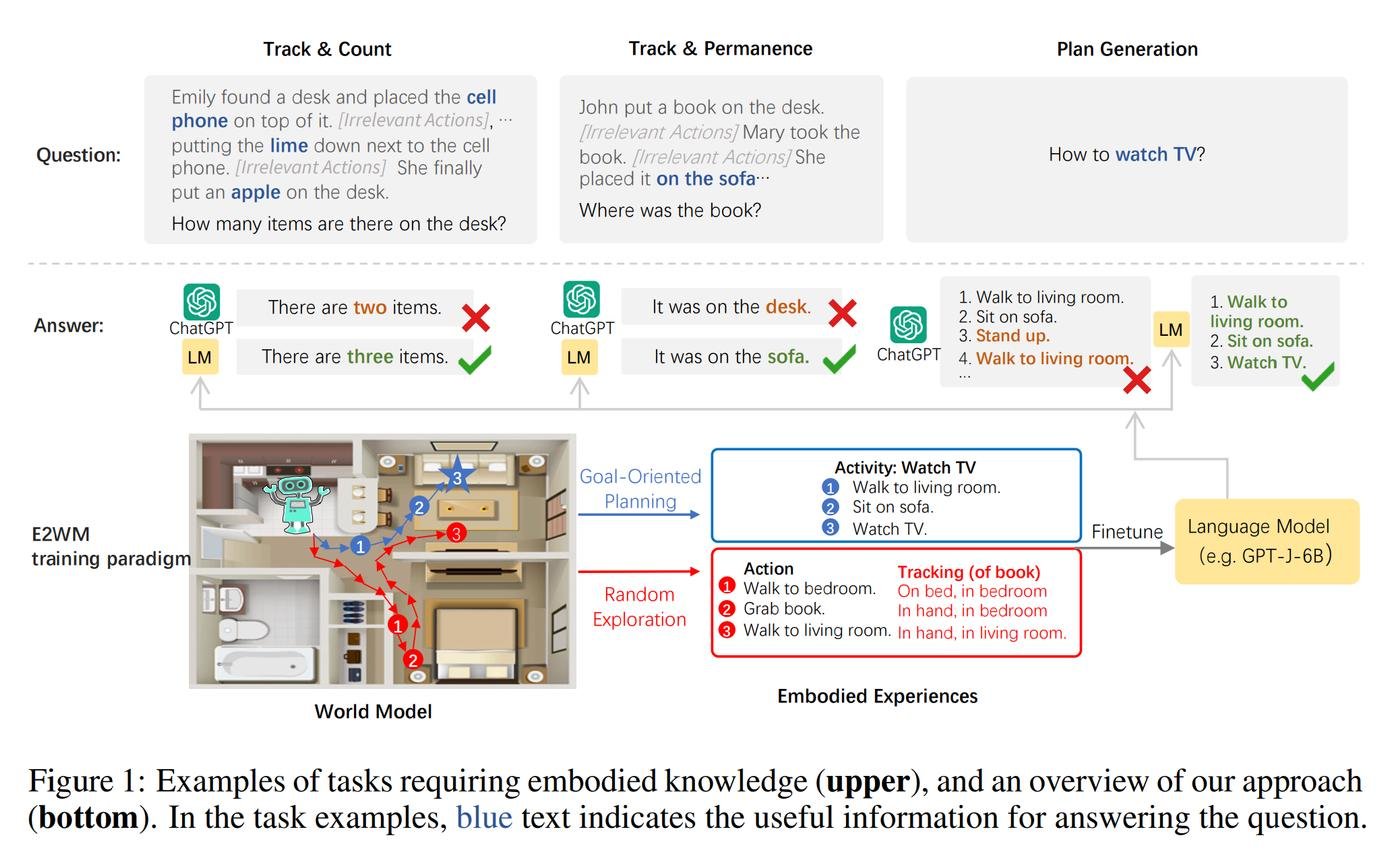
Это из за того, что модель натренирована на тексте - в нем обычно не достаточно информации, чтобы выработались embodiment скилы.
Так вот ресерчеры зафайнтюнили модель нужным опытом. Запихнули ее в виртуальную квартиру и через всякие активности научили понимать как передвигиться, где какие обьекты и тп.
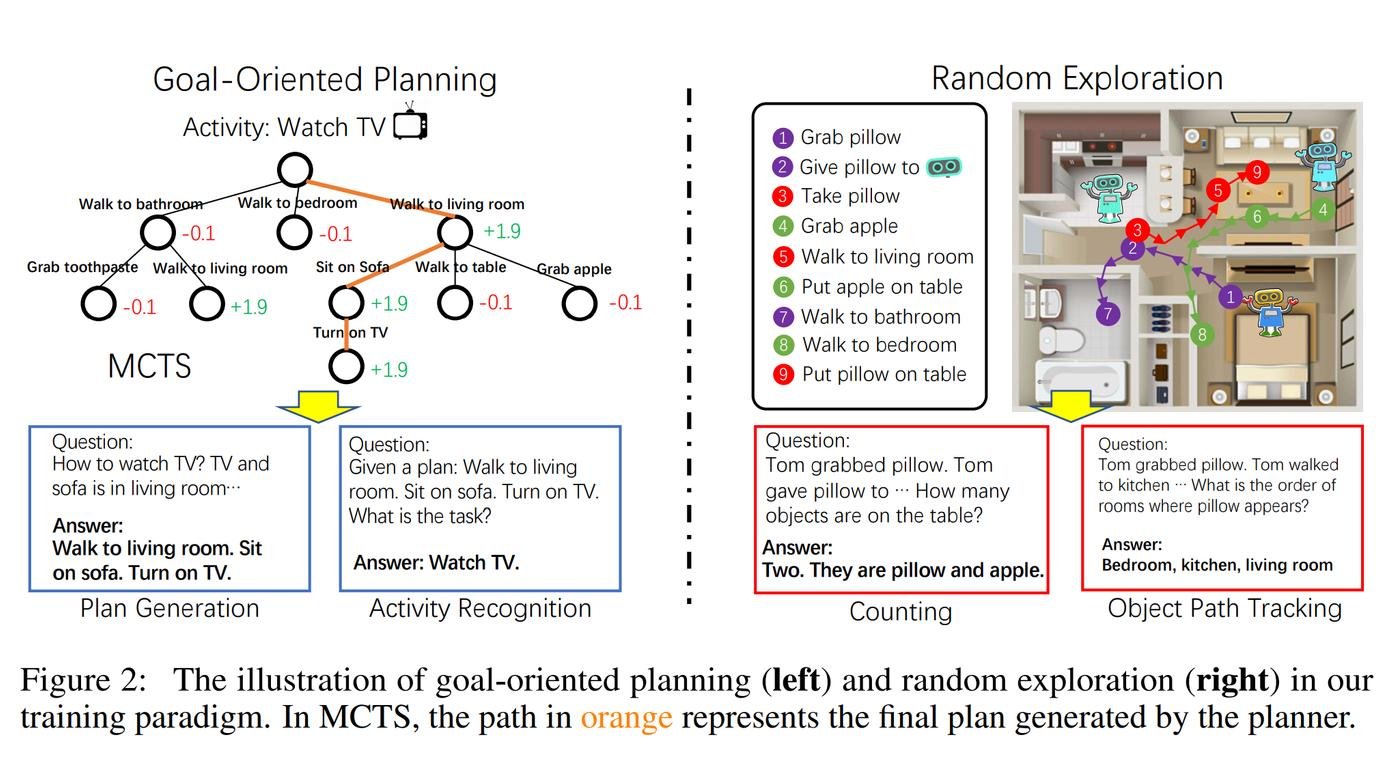
А еще смогли сохранить способность модели обобщать - то есть переносить выученные знания на разные ситуации.
Короче, алгоритмы - это важно.
Чтобы не разориться на видеокартах - нужно, чтобы нейронки научились экспериментровать и обновлять свою модель мира.
Барьер 4 - Регуляции
Есть еще один странный барьер: ОС могут зарегулировать.
Во многих традиционных отраслях есть лицензирование с дорогим и долгим порогом входа. Например, заявление на регистрацию нового лекарства в FDA стоит несколько миллионов долларов. И это только малая часть затрат.
Бигтех умеет тратиться на комплаенс и получать лицензии. Чем больше компания, тем меньшую долю в расходах занимают регуляции.
Еще у меня есть убеждение, что алайнмент коммьюнити боится ОС. Но кажется это не совсем так. Перескажу основную позицию и попробую понять, согласен с ней или нет.
В чем позиция против ОС
Конечно круто, что ОС дает возможность простым работягам покрутить модельки у себя на ноутбуках. Важно, чтобы эта технология была доступна не только нескольким избранным АИ лабам. Демократизация - это важно.
Но если в открытом доступе появятся по настоящему сильные модели - будет оч плохо. Например такие, которые могут по шагам помочь создать новый неизвестный науке патоген.
ОС опасен, потому что невозможно успешно кооперировать при таком количестве агентов.
Дать каждому человеку в мире девайс судного дня - это не демократизация. Мы по сути рискуем дать судьбу всего мира в руки одного мизантропа. Что выглядит ровной противоположностью демократии.
А защищающие бигтех барьеры, это по иронии то, что возможно сохранит нам всем жизнь.
Критика этой позиции
Вот 10 минут про то как Марк Цукерберг про это думает.
TLDR позиции Цукерберга (и Яна ЛеКуна):
- Стоит разделять краткосрочные риски и супералайнмент. Сейчас есть куча понятных проблем, которые точно нас ждут в ближайшем будущем. Например, фрод и фейки.
- Пока что ОС это хорошо. ОС дает возможность большему числу людей тестировать модели, что поможет решить краткосрочные проблемы. А еще поможет избежать консолидации власти в руках одной компании.
- Мы пока не дошли до AGI, но это серьезная тема. Марк держит руку на пульсе и ближе к делу пересмотрит свою позицию. Больше всего он обеспокоен автономностью и агентностью.
Еще классную крутику нашел у чувака, который перечитал основные исследования и намного глубже меня разобрался в теме.
Позиция опасности ОС подтверждена пока только теоретическими рассуждениями, но не нормальными иследованиями. More advocacy than science.
Если ты предлагаешь ограничить ОС, то хочется видеть сильные, последовательные и понятные аргументы. Без додумываний за рамками того что можно проверить экспериментом. С открытым диалогом с чуваками с противоположным мнением.
Но пока такого нет. Вместо этого самый авторитетный ресерч от Anthropic ссылается на неопубликованые внутренние исследования и просят поверить на слово.
Чо за ресерч то?
Людям без спец знаний дали нейронку и попросили с помощью нее создать вирус. Но исследование так задизайнено, что неясно насколько нейронка упрощает задачу лучше, чем поисковик или онлайн крусы. Хотя логика за этим все же есть.
Сэм Альтман в последнее время много рассказывает про фокус на то, чтобы научить модели сособностям ученых. Доказывать теоремы, проводить эксперименты и создавать новое знание. Если они в будущем будут способны находить лекарства от болезней, то почему нельзя попросить их сделать что то плохое?
Хотя уже сейчас GPT-4 может как репетитор простым образом обьяснять сложые научные штуки. И кажется, что по настоящему сдерживающим фактором должен быть не доступ к знаниям. А невозможность собрать все компоненты в лабе.
Тут есть что пообсуждать, это открытый вопрос, но я пока стопну и попробую сделать выводы.
ОС это плохо?
Доказывающих опасность ОС исследований нет, по крайней мере в публичном доступе. Но и не похоже, что текущие полиси предлагают криминализировать и банить ОС. А что предлагается?
Например обсуждается ответственность за катастрофу. Это такая принудительная страховка для тех кто публикует веса большой модели. Кто то накосячил, используя твою технологию - ответственность на тебе.
Это должно смотивировать хорошенько подумать перед релизом. Расписать какие угрозы могут быть, поресерчить их и собрать доказательства.
В общем, регуляции могут дать еще одно преимущество для бигтеха, но все будет сильно зависеть от конкретной реализации. Пока признаков не вижу.
Выводы
Давайте попробую собрать Франкенштейна в одно целое и сделать какие то выводы.
Про что мы успели поговорить?
- Meta - У компании серьезные проблемы?
- Опенсорс - Цукерберг хочет сделать нейросети дешевыми
- Лама - Что же произошло весной?
- Как обучают большие модели - Ликбез по этапам тренировки
- Магия ОС - Бигтех испугался быстро сокращения отставания?
- Какие барьеры защищают рынок:
- Барьер 1 - На рынке огромный спрос на железо
- Барьер 2 - Данные это узкое место, но преодолимое
- Барьер 3 - Алгоритмы важны так же как и скейлинг
- Барьер 4 - Регуляции пока не барьер, но могут им стать
- Выводы - Достаточно ли магии ОС, чтобы снести барьеры бигтеха?
Марк Цукерберг делает смелые стратегические шаги и ведет Meta за собой в светлое будущее. Он хочет сделать нейросети дешевыми потому, что продукты компании от этого выиграют больше конкурентов.
Весной случился восхитительный прогресс ОС после получения доступа к Ламе с его подачи. Спустя полгода появились маленькие и быстрые модели с 90% качества от топовых.
Это дало повод усомниться в защищающих рынок бигтеха барьерах. Но после внимательного изучения, хочу сделать осторожные выводы: у бигтеха есть и другие барьеры, а успеха ОС пока не достаточно, чтобы подорвать рынок. Но у маленьких и дешевых моделей будет своя ниша.
- Существующая экосистема продуктов это тоже отличный барьер
- Meta для рекомендаций в ленте, дешевых и быстрых ОС нейронок будет достаточно
- У бигтеха будут свои рынки с совершенно другими проблемами
Все у кого еще нет маркет фита и экосистемы - в невыгодном положении
Сложно построить бизнес, единственным преимуществом которого является чистая инновация. Продукт это не только его техническая часть. Если ты на коленке накодишь клон Твиттера за выходные, ты не станешь им реальным конкурентом.
У продукта есть инфраструктура, экосистема и коммьюнити разработчиков. Есть устойчивые каналы дитрибуции, накопленная аудитория. У юзеров есть привычки, приверженность бренду и потребность в вылизаном customer experience.
У OpenAI отличный PMF (product-market-fit) - их продукт решает боли пользователя. Их модель монетизации уже работает и позволяет продукту расти. Сейчас они уже решают следующую проблему - как скейлить модели еще дальше.
Интересно, что они достигли PMF плавно, на ранних и дешевых моделях. И уже потом смогли не рискуя начать их скейлить. А все у кого нет PMF и экосистемы оказываются в оч невыгодном положении.
Новым игрокам нужно сразу быть лучше или дешевле моделей OpenAI. То есть, сначала серьезно вложиться в железо, а уже потом с риском искать как получить себе долю рынка.
Гонка на дно делит рынок на тех кто в ней участвует - и тех кто нет
Не считая OpenAI, сейчас на рынке 5 компаний имеют модели, сравнимые с GPT 3.5.
- Mistral - Mixtral
- Inflection AI - Inflection-2
- Anthropic - Claude 2
- Google - Gemini Pro
- X.AI - Grok
И скоро будет еще 5: Meta, Databricks, 01.AI (Yi), Baidu и Bytedance. Любопытно, что у Mistral и X.AI меньше 20 человек в команде!
Короче, создание моделей на 10% хуже топовых - это уже коммодити. Десять компаний могут это делать. А с релизом Mixtral вообще стартовала гонка на дно: стартапы жгут инвесторские деньги и предлагают все более убыточные для себя условия. Надеясь, что это привлечет пользователей и получится выстроить стабильный продукт.
Если ты не лидер рынка, ты почти вынужден играть руку догоняющего. Например, Google для Gemini Pro дает 60 бесплатных запросов в минуту. Весь рынок сейчас теряет бабки на таких субсидиях.

Остались ли способы заработать что то на рынке создания и обслуживания ОС моделей?
- Уникальная дистрибуция благодаря прямому доступу к клиенту через SAAS или медиа. Например, Copilot.
- Помогать обучать и файнтюнить узкоцпециализированые модели другим компаниям на их данных. Например, Stability AI.
- Гарантировать комплаенс и защиту данных для энтерпрайза.
И все это не то чтобы опасно для OpenAI.
Большие модели будут решать другие проблемы
У маленьких ОС моделей есть два узких места:
- С уменьшением размера, растет рандомность в ответах - на модель сложнее полагаться.
- Более сложные эмерджентные свойства требуют большего количества параметров. Эмерджентные - это новые способности, которые появляются у модели с ростом размера. Например, умение писать код.
Отличный пример альтернативы - это Emad Mostaque из https://stability.ai/. Он строит стратегию компании вокруг узкодоменных моделей. Любой желающий сможет файнтюнить модели на своих данных для своих задач. Наверняка у этого есть классный рынок.
Но думаю у больших моделей с новыми эмерджентными фичами рынок несопоставимо больше.
То есть тут вопрос не в том, будут ли люди платить больше за чуть более крутую модель. А скорее, люди будут хотеть решения своих проблем, большинство из которых будет слишком сложны для ОС моделей.
Но я думаю, что до момента, когда через 3-4 года Foundational LLM не просто перестанут выкладывать, но и доступа к ним не будет.
Выводы из выводов
Марк Цукерберг хочет заполучить фундаментально выигрышную стратегическую позицию. За тот самый Force Multiplier из начала статьи будут бороться все бигтех компании. А у ОС моделей будет своя ниша поменьше.
И самый сильный барьер в этой борьбе - это способность раньше всех понимать, что будет дальше. И по полной комититься в свои идеи, что у меня лично вызывает огромное уважение. Это долгосрочная, затратная и рисковая стратегия, которую могут позволить себе только крупные компании.
В силе бигтеха лежит слабость, а в этой слабости сила.



Немного комментариев к статье.
Юдковского и его подходы уже поносили в вастрик.клубе, когда обсуждали ai alignment, повторяться не будем. Но с того времени вынесу еще раз мою позицию касаемо опенсорса в LLM: OpenAI нихрена не Open, ML-комьюнити активно развивается и справляется с задачами технологического и этического характера только при опенсорсе, нормальное развитие применения LLM лежит в демократизации доступа к ней.
Не пугай людей, эти модели стоят порядка $100M, модели порядка миллиарда пойдут только в следующем году.
Блин, добавь сноску что это СЛУХ, который никем не подтверждён. А то люди понесут по чатам и потом сиди с ними спорь.
Классный пост, пока еще читаю, но уже возник вопрос
это откуда? Почему gpt3.5-turbo и т.д.?
Круто, спасибо за разбор!
Ахуенно! Пиши больше :)
Спасибо за пост!
Интересно и захватывающе было читать, понравилось, спасибо!
Офигенный текст, спасибо, пиши еще!
Очень интересно и познавательно, спасибо за статью
@ialgos, @Yaanton, @lexibender, @vetrov, @Shambler, @akudashkin
Спасибо ребят, приятно что вам понравилось!
А что же Илон?
Отличная статья, пиши ещё!