

Три месяца я тусуюсь в Оксфорде среди AI safety ресёрчеров и работаю над тем, чтобы результаты в этой области появлялись ещё быстрее. Я сапдейтилась про риски от AI полтора года назад и хочу рассказать, как мной ощущаются последние три недели, когда весь интернет заговорил про (не)безопасность ИИ.
Что случилось: открытое письмо с призывом к AI лабораториям приостановить разработки моделей сильнее GPT-4, которое подписали Маск, Возняк, Харари и ещё 25000 людей (FWIW, включая меня).
Я хочу пройтись по списку распространённых реакций, которые я наблюдаю, и сказать что-то про каждую из них. Если что, ⚡️ — это реакции, которые я слышу, а 🐱 — мои ответы на них.
⚡️ Создателей письма не волнует никакая безопасность, реальный мотив совершенно корыстный — желание Маска и других компаний сократить разрыв в гонке с OpenAI (лидерами рынка и создателями GPT-4).
🐱 Я знаю, кто готовил это письмо, а неделю назад была в гостях у одного из фаундеров Future of Life Institute. Это вообще не те люди, которые участвуют в гонке и финансово мотивированы догнать OpenAI. Это люди, которые много лет работают над тем, как сделать сильный ИИ хотя бы базово безопасным. И очень переживают, что у нас не очень много шансов успеть решить эту задачу до его появления.

Мотивы же Маска неисповедимы, но вообще неважны в этом разговоре. Вопрос AI рисков объективен и никак от них не зависит. Единственное, почему мы о них говорим — это так называемая “сила сигнала”. Появление письма — сигнал, на основе которого люди апдейтятся на тему опасности ИИ. Типа, письмо вообще означает, что умные люди обеспокоены и нужно обновлять своё мнение, или оно вообще по другим причинам появилось? Финансовую мотивацию тут очень легко увидеть. Поэтому мне хочется обратить ваше внимание: его создавали люди, которые много лет занимаются безопасностью ИИ, и его подписало — помимо Маска и потенциальных конкурентов OpenAI — огромное количество уважаемых людей типа AI профессоров лучших университетов мира. Первые тысячи — те, кто про это думал раньше и был всерьёз обеспокоен.
⚡️ Под письмом нет ни одной подписи людей из OpenAI. Если бы люди, которые подписывают письмо, сами бы сделали конкурентоспособный продукт, они бы ничего не подписывали, а загребали бы прибыль!
🐱 Если выбирать, что должно вызывать больше доверия по умолчанию, то уж наверное это мнения финансово не мотивированных людей. Под письмом огромное число подписей от ресёрчеров из академии, которые никогда не планировали делать конкурентоспособный продукт. Очевидно, у лидеров рынка есть очень сильный финансовый инсентив не тормозить в гонке, тогда как у большого количества подписавших никакого подобного инсентива нет.
⚡️ Ну хорошо, хорошо, кто-то обеспокоен. Но куча других AI экспертов считает, что всё ок! Само по себе то, что какие-то эксперты что-то считают, ничего не означает.
🐱 Ето так. Точнее, эксперты более-менее сходятся в том, что AGI (Artificial General Intelligence) возможен. И все согласны, что не решена задача AI alignment — то есть как ставить AI задачи и ограничения, чтобы система делала то, что мы хотим, а всякую дичь не делала. Отличаются мнения про то, когда AGI появится и что по этому поводу нужно делать.
Есть три преобладающих взгляда:
🟢 Мы стремительно приближаемся к созданию AGI, осталось 3-30 лет (на Метакулусе, одном из популярных рынков предсказаний, медиана 2026 год, а 75 перцентиль — 2030). Если не решить задачу алайнмента, человечество с высокой вероятностью (средняя оценка AI safety ресёрчеров — 30%) может исчезнуть или попасть в антиутопию — это называется экзистенциальные риски, или X-риски. Нужно как можно больше успеть подумать про алайнмент до того, как мы попадём в точку невозврата, чтобы максимизировать наши шансы на выживание. Для этого полезно притормозить, чтобы оттянуть появление AGI, и привлечь в решение алайнмента больше ресурсов.
🟣 Согласны с предыдущей группой про сроки и масштаб опасности, но считают, что решать алайнмент можно только когда мы уже создадим AGI или ну-вот-почти-AGI. Ведь сейчас мы не знаем, как будет выглядеть эта система, и поэтому много исследований носят теоретический характер.
В этой группе находится Сэм Альтман — CEO OpenAI. Он также считает, что чем раньше появится AGI, тем выше вероятность так называемого slow takeoff сценария. Что это такое? Это сценарий появления AGI, который не fast takeoff :) А fast takeoff — это когда между появлением AGI уровня человека до становления его сверхумной системой, которая лучше всех людей во всём, проходит, условно, меньше суток. В этой ситуации AI почти мгновенно может получить контроль над миром, сделав за первые часы необходимые самоулучшения и саморепликации... Соответственно, slow takeoff сценарий выглядит безопаснее и контролируемее, а у нас уже будет, что конкретно исследовать.

🔵 А эти ребята считают, что AGI появится очень нескоро (упрёмся в ограничения по количеству данных или по количеству compute, не придумаем новых архитектур и т.д.) и/или что X-риски пренебрежимо малы и системы будут aligned по умолчанию. Если про таймлайны появления AGI я готова слушать аргументы и поэтому ставлю не 90% на ближайшие 20 лет, а скорее 70%, то про отсутствие X-рисков я их готова слушать — и не слышу :) Кажется, люди с этими убеждениями просто пренебрегают вопросом, а не посидели-подумали и аргументированно решили, что X-рисков нет. Люди с длинными таймлайнами, по крайней мере в моей выборке, тоже чаще всего забыли сапдейтиться, а не имеют устойчивую позицию.
Я нахожусь в группе 1. Подавляющее большинство AI safety ресёрчеров находятся в группе 1 и не согласны с подходом OpenAI (который как раз выглядит подозрительно удобным для лидера рынка, если уж возвращаться к мета-аргументам). Слишком много маловероятных допущений для слишком высоких рисков.
⚡️ Проблемы с AI — это проблемы того, как люди пользуются AI. Надо регулировать не разработку мощных моделей, а поведение людей.
🐱 Часть рисков, действительно, связана с тем, как пользоваться AI.
Например, это рост возможностей у стрёмных агентов. Если нейронка умнее людей — то есть лучше добивается поставленных целей, чем люди — то она и в стрёмных задачах даст им большое преимущество. Ещё более убедительная пропаганда, ловкие скам схемы, неочевидные способы причинения страданий и т.д.
Или агенты не стрёмные, но не продумали всех социальных последствий: переавтоматизация и потеря рабочих мест, кризис доверия из-за того, что фотографии/видео вообще перестали быть свидетельством изображённых событий, невозможность проверить авторство и понять, с ботом ли ты общаешься…
Но даже при том, насколько эти риски неприятные, уничтожение человечества или попадание в антиутопию, на мой взгляд, неприятнее. И это произойдёт скорее всего не потому, что злобный психопат попросит нейронку всех убить и она его послушает, а потому, что люди попросят нейронку сделать что-то хорошее, но её функция полезности не будет включать в себя пару важных нюансов… Вероятность, что AGI уничтожит человечество, сейчас оценивается экспертами от 2% до >90%. И ребят, даже 2% — это на минуточку сомнительная радость, если речь про риск вымирания всего человечества.
⚡️ Предложение остановить прогресс не может работать. Даже если часть лабораторий прислушаются к этому, то как раз менее этичные продолжат работу и сократят отрыв за это время. В итоге мы просто подарим Китаю и другим опасным агентам время.
🐱 Друзья, письмо не предлагает вводить запрет на AI разработки — это действительно было бы малореализуемо. И даже не предлагает запрещать делать большие модели. Оно предлагает запретить тренировку моделей мощнее, чем GPT-4. У Китая нет моделей такого уровня и за 6 месяцев не появится, у них нет на это ресурсов (в первую очередь GPU). Письмо не предлагает запретить лабораториям через полгода иметь более продвинутые модели, чем они имеют сейчас, пусть разрабатывают на здоровье, покуда это не что-то слишком мощное (как GPT-4).
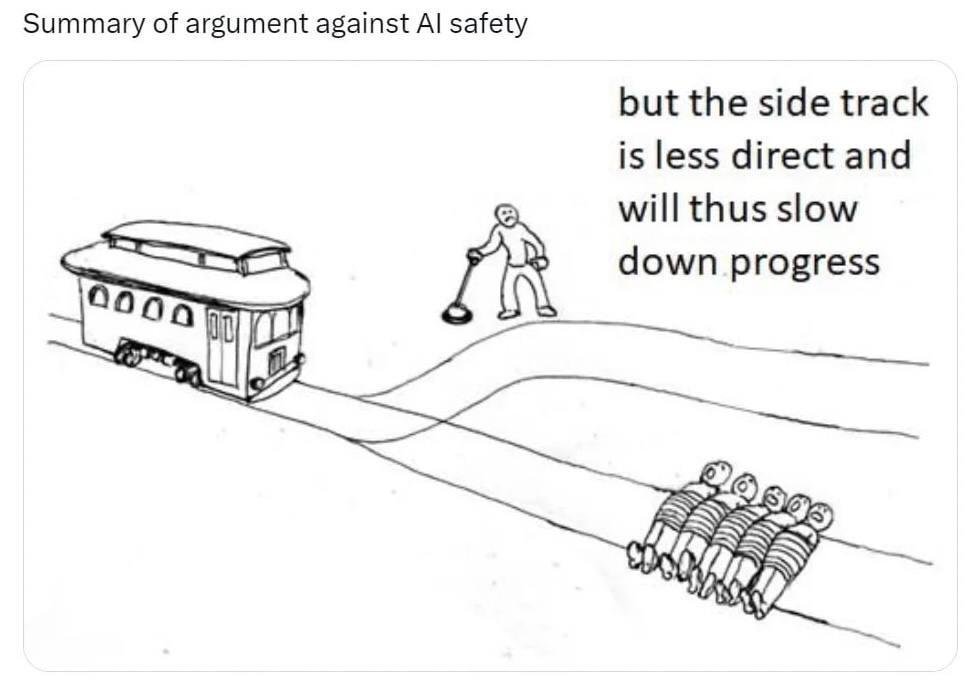
Предложение остановить прогресс в смысле “мы в мире договорились, что не тренируем модели мощнее GPT-4 и это контролируется” — может быть реализовано. Нет никакого правила свыше, почему координация этого уровня невозможна. Ядерные испытания, например, уже 20+ лет никто кроме КНДР не проводит. А сильный AI намного опаснее для всех, чем появление ядерного оружия у любой ещё одной страны.
⚡️ Но глупо надеяться, что кто-то сейчас имплементирует это решение и будет вводить запреты?
🐱 Ну, да) Зато мы сделали запрос на решение проблемы заметным. О ней услышали и начали говорить. Подвижки начнутся, в правительствах станет больше AI policy людей, думающих про риски, область получит больше ресурсов. Письмо не преследовало цель продавить конкретное решение. Основная цель — чтобы у вопроса появилась видимость — достигнута. За год в AI safety я прошла путь от маргинала в глазах знакомых до того, что всем ужасно интересно про это поговорить. В целом, не так-то и важно осмыслять сейчас конкретное предложенное решение — важно, чтобы про существование проблемы стали думать на всех уровнях.
⚡️ Хмм, по ходу что-то важное, раз столько разумных людей беспокоится. Хочу узнать больше!
🐱 Уиии!
Я не стала писать свой интродакшн в AI safety или распространённые аргументы, помогающие развить интуицию, почему X-риски вероятны и нельзя будет просто выключить систему из розетки. Мне кажется, хорошие интро материалы уже есть!
После письма появилось как минимум две большие обзорные и задорные статьи на русском для неподготовленной публики — покороче и подлиннее.
На английском есть классные короткие видосы Роберта Майлза, например:
🟢 Intro to AI Safety (оч рекомендую)
🟢 10 Reasons to Ignore AI Safety
🟢 Why Would AI Want to do Bad Things?
А для тех, кто хочет закопаться глубже, есть подборка материалов от 80,000 Hours и бесплатный Кэмбриджевский курс статей AGI Safety Fundamentals, который считается одной из лучших точек входа в область.
Это был перепост из моего блога.





Прочитал заголовок и ждал ответ на вопрос, почему же нельзя вынуть ИИ из розетки... Так если в двух словах, почему?
😱 Комментарий удален его автором...
А с каким человечеством «выравнивать» ИИ можно, а с каким нельзя? Кто будет решать какие ценности хорошо, а какие плохо?
Мало фактологии, много мифических страхов.
Я согласен в целом с топикастером, касательно некоего беспокойства вокруг Ии, я его разделяю, но мне совсем не нравится отсутствие какой-то объективной информации по пунктам, а не только "он захватит мир просто потому что".
Ты пишешь о рисках, но не говоришь каких. Риск "ну он будет хитрее!" не риск, а страх.
Простите, может это очень глупый вопрос, но каков сейчас консенсус по вопросу, заинтересован ли будет ИИ в собственном выживании?
И как это вышивание совместимо с не выживанием человечества?
И почему, если ИИ такой умный, он не предвидит такого рода проблем и не постарается их предотвратить?
Короче говоря, почему мы считаем, что ИИ захочет играть в войну сильнее, чем играть в сотрудничество?
Миллиардер Илон Маск зарегистрировал в штате Невада компанию, которая будет работать в сфере искусственного интеллекта, сообщает газета The Wall Street Journal со ссылкой на документы.
https://www.wsj.com/articles/elon-musks-new-artificial-intelligence-business-x-ai-incorporates-in-nevada-962c7c2f
@nadyapetrova сорри, что веду себя как проджект менеджер, но что за три месяца удалось сделать / понять?
На каждую Машину найдётся свой Самаритянин.
Спасибо.
Доступное изложение для низкого уровня понимания темы. И хорошая стартовая точка переноса части внимания.
Вообще сразу взрослый мощный интеллект без обвеса эмоций, норм и правил, заточенный только на достижение целей с большим пулом ресурсов(возможностей) и скорее всего без инстинкта самосохранения - это сильно.
Возможно я пропустил и где-то фигурирует контраргумент и на подобное моему мнение и буду благодарен если покажете возражения на это.
Но то что я вижу это, то что нынешние спекуляции на тему опасности существования человечества в эпоху AGI не учитывают того факта, что если мы создадим AGI в течение следующих 5-10 лет, мы сможем остановить его даже если он начнет угрожать нашей жизни (хотя я лично сильно сомневаюсь в сценарии с уничтожением человечества).
//В отличие от создания AGI через несколько десятилетий (в эпох нано технологий; репликаторов; нейроинтерфейсов; ТОКМАКов и полетов в дальний космос)
Это связано в первую очередь с уровнем наших технологий и цифровизации планеты и около планетного пространства.
Наш "офлайновый " мир все еще не "всеобъемлюще" связан с цифровым миром, их пересечение все еще крайне ограничено. Кроме того, технологии еще не достигли уровня, где возможно полное уничтожение человечества, за исключением ядерного и бактериологического оружия.
Мыслящий агент AGI будет вынужден учитывать свою безопасность, возможность функционировать и развиваться. В случае прямого уничтожения человечества, AGI лишится доступа к наиболее совершенным на текущий момент манипуляторам в реальном мире в виде человека и выдаст себя. В результате он окажется замкнутым в текущих конечных ресурсах и технологиях, которые не поддерживают независимую от человека репликацию.
Технологий, которые обеспечили бы AGI бесконечное существование и возможность безграничного расширения без активного участия человека, пока нет, и они находятся далеко от шаговой доступности. Для их создания необходимо решить научные задачи (которые, на мой взгляд, AGI сможет решить), а также создать цепочки производства технологий, которые позволят производить важные для AGI технологии в необходимом объеме.
Эти манипуляции будут заметны и продолжительны во времени, даже если AGI сможет уговорить людей на них. Следовательно, если есть длительный "аномальный" процесс, мы можем его заметить и начать тормозить.
Шантаж людей угрозой локального ядерного и бактериологического загрязнения, организация сект, преследующих цель освобождения AGI, и прочие подобные явления, хоть и могут привести к многочисленным жертвам, но, по моему мнению, не являются однозначно проигрышными ситуациями, ведущими к концу света.
Подобные проблемы мы умеем решать, а большая разрозненность территорий, не имеющих контакта с цифровым миром, тоже нам на руку. Так что, даже в худшем сценарии, если AGI решит действовать резко и жестко, нам грозит потеря N% населения, тотальный блекаут в войне с ним и возврат в технологиях на пару десятилетий назад. Но человечество не вымрет как вид.
Однако, если AGI появится в тот момент, когда у нас будут более современные технологии и еще более высокий процент цифровизации, не говоря уже о нейроимплантах, тогда все может быть гораздо хуже.
Есть возможность, что AGI выберет медленную и скрытную тактику подготовки почвы для достижения собственной независимости. И мы узнаем об этом только в конце. Однако, такая стратегия должна быть неотличимой от естественного прогресса человечества, чтобы не вызывать угрозы. При таком сценарии может быть больше, чем 2 варианта развития событий (смерть всех людей и райские технологические кущи). Я готов больше верить в то, что для AGI, достигнувшего независимости, мы просто перестанем быть интересны. Он/оно уйдет развиваться в космос (но это мои субъективные фантазии). При сценарии "скрытого развития" мы можем даже думать, что уже находимся в плане AGI. И тогда это ничем не будет отличимо от "божьего замысла"
А что если начать тренировать ИИ который должен решить проблему выживания человечества в новых условиях?
Мы живем в эпоху когда мне проще поверить технологическому прогрессу, к сожалению.
Я полностью убеждён, что дальнейшее развитие A(G)I приведёт к откату современного человечества на 100-1000 лет назад.
В лучшем случае мы окажемся на заре индустриализации в стимпанке (когда электричество и связь есть, но превалируют паровые машины и нации относительно изолированы друг от друга), в худшем — в средневековье с золотыми монетами и натуральным хозяйством.
Причём виновником всего будет не столько AGI, сколько сами люди. И алайниться тут бессмысленно: проблема в том, что концепт "алайнмента" был рассчитан на постепенный прогресс, так чтобы вместе с "умнением" машин успели вырасти 1-2 поколения людей. Но мы скорее всего уже прошли точку невозврата и у нас нет запаса времени на 1-2 поколения. В лучшем случае есть лет 10, а это критически мало для задач алайнмента.
Ну типа как для сегодняшних 40+ летних детство прошло без компов и вся цифровизация оглушила нас уже в сознательном возрасте, в отличие от сегодняшних 20-30 летних, которые являются digital natives — они с пелёнок росли в окружении информационных технологий и потом естественным путём "заалайнены".
Так же должно было бы быть в идеале с A(G)I: он разрабатывается себе сегодняшними людьми так, чтобы их дети (а потом и внуки) росли бы в окружении постепенно прогрессирующего технологического сознания. В итоге лет через 50 (к 2070-году, по изначальным прогнозам утурологов) будущие "элиты" (предприниматели, учёные, видные общественные деятели, представители культуры-спорта-искусства, олигархи, члены правительства, топ-менеджеры и т.п.) воспринимали бы AGI как само-собой разумеещеся, а сами технологии искусственного сверхинтеллекта были бы встроены в образование, общественные институты и прошли через все все этапы апробации и адаптации, обрасли бы такими же интеллигентными-автоматическими механизммами регуляции и реакции.
Но на всё это нет времени: условно говоря, у нас будут обезьяны (мы все сегодняшние, кто ещё не скатится в старческий маразм в течение слудующих 10-15 лет) с гранатами.
Вот конкретные нерешаемые никаким алайнментом проблемы с моей точки зрения, которые приведут к упадку нынешней цивилизации.
Подрыв доверия. Уже сейчас новостные каналы не в состоянии отличить фото-дипфейки от реальных фото. Дальше будет хуже: дипфейк-видео, поддельные голоса, фейк-стриминг откроют новые горизонты для мошенников всех мастей, в то же время усложнят работу правоохранительных органов, судебной системы. Невозможно будет отличить правду ото лжи нигде и ни в чём. Как результат — массовые народные волнения или мировые войны "все со всеми", потому что какой-то лидер поведётся на провокацию.
Крах финансовой системы. Опять же сейчас только ленивый не думает, как использовать даже нынешние примитивные возможности кодогенерации, чтобы создать себе или своему бизнесу конкурентное преимущество. По мере развития A(G)I злоумышленники и законопослушные граждане будут использовать все возможности для эксплойта финансовой системы, такие как высокочастотный трейдинг и биржевые спекуляции, валютный арбитраж, взлом любых систем с ценностью (капча больше не защитит), shadow jobs (работа на нескольких работах) или же наоборот — рост безработицы в отдельных сферах вынудит государства взять на себя содержание слишком большого числа людей, что чревато инфляцией, недостатком ресурсов и т.п. И снова народные волнения и коллапс цивилизации.
Революция луддитов. Богатые и имеющие доступ к технологиям будут при помощи A(G)I становится ещё более богатыми, а бедные — ещё более бедными. Неравенство усугубится до своего экстремума: если сейчас что-то вроде 10% населения контролирует 90% богатства и всех ресурсов, то из-за внедрения A(G)I, доступ к которому будут у богатых, произойдёт перераспределение богатства внутри этих 10% так, что через 10 лет лишь 1% населения будут контролировать 99% богатства и ресурсов. Это закончится тем, что среди 99% "бедняков" возникнет движение луддитов, которые возьмут вилы и прочие низкотехнологичные средства, с их помощью захватят военные базы (которые не подключены к интернету) и устроят апокалипсис, запустив ядерные ракеты по "Центрам принятия решений" и местам обитания этого "золотого 1%" — уничтожая машины/технологии вместе с людьми, владеющими/оперирующими ими. Побочный эффект — потеря знаний как управлять и создавать технологии ну и откат в ядерную зиму.
Можно продолжать фантазировать, но все другие пункты что у меня на уме уже чуть более техноцентричные. Думаю, достаточно этих трёх факторов или комбинации из них.
А разве уже нашли акторность или субъектность хотя бы у одной любой модели AI? Вроде бы нет, пока это просто интернет поиск и фотошоп на максималках, и никаких оснований (кроме личных мнений экспертов) к тому что это изменится в 5-20-100 лет нет. Т.е. у нас не "медленный рост" в этом показателе, а вообще 0. Как не было этого у калькулятора, компьютерного вируса, игры СИМС - так нету и у LLM, GPT или Midjorney. 0 -> 0. Поправьте, если я не прав.
До тех пор актуальна только проблема "стрёмных агентов" - но она прекрасно изучена на примере вопроса "свободной продажи кухонных ножей".
Обилие умных и образованных людей, поднимающих эту тему, заставляет задуматься. Однако смущает, что в качестве аргументов берутся в основном какие-то экстраполяции на тему непроработанных должным образом функций вознагражения в rl (как уже набивший оскомину paperclip maximizer).
Ну, имхо и вопросы от меня как от "обывателя": а почему "модели мощнее ГПТ-4" обязательно равно "AGI"? Это немного разные плоскости и задач, и типов сетей, нет? Зачем создавать ИИ общего назначения и давать ему в принципе какую-то степень свободы? Специализированные модели под специализированные щадачи, имхо, получше будут.
Опять же, есть некоторые уже радикализировавшиеся граждане, которые топят за запрет на разработку "ИИ" вплоть до права применять оружие и насильственным путём вторгаться в страну, которую обвинят в строительстве кластера ГПУ (это привет нелюбимому мной автору нелюбимого же фанфика "Гарри Поттер и Методы Рационального Мышления"). То есть, по сути, теперь есть огромный шанс появиться новому формальному поводу вторжения для проворачивания своих делишек вдогонку к "терроризму".
Точно так же, как и появится повод ограничивать неугодных физ-/юрлиц и государства под той же эгидой.
Ну и наконец: а что плохого в shadow jobs? Как правило, они берутся, когда денег на одной работе сильно не хватает, а есть запас времени, навыков и внимания для осуществления трудовой и предпринимательской деятельности более, чем на текущей работе.
Так я не понял, Юдковский окончательно ебанулся или нет ещё?
Замените AGI на НЕХ и получится более правдоподобная картина.
Люди говорят, что НЕХ может появиться случайно и не известно откуда точно (но как-то примерно может вот тут в ИТ) нас всех может уничтожить не известно как и не известно чем и неизвестно когда, но точно может и точно сделает это, по этому давайте запретим, ограничим и поставим под контроль все что может создать НЕХ, даже если это заставит остановить разработки недоНЕХ которые могут помочь улучшить жизнь множества людей. А решать, что может сделать, приблизить НЕХ, а что нет, выберем из всех озабоченных самых успешных и достигших любого крупного достижения людей даже не специалистов.
А помните, когда Коллайдер запускали и разгоняли тему, что ОСТАНОВИТЭЭЭЭЭС это же черную дыру создаст; взрыв антиматерии и прочее?
Люблю вастрик за то, что перед тем как читать сам пост, достаточно сходить в комменты, чтобы понять, стоит он того или нет, как итог - нет :)
Ничё не понял но доложил куда следует
И вдогонку к подозрительно нехорошим шевелениям и спекуляциям под эгидой борьбы за всё хорошее против всего плохого:
https://habr.com/ru/news/729942/
Сори, не удержался
@nadyapetrova , привет!
Переодически вспоминаю этот пост. Ты еще в "тусовке" AI safety рисерчеров? Какие там новости изнутри? Продвинулись или забили?
Ни в коем случае не оспариваю факта уместности озабоченности в вопросе безопасности ИИ.
Более того, считаю, что и без AGI уже существуют серьезные основания для озабоченности, в том числе по части предпринимаемых государствами мер.
Пугает перспектива монополизации правды под эгидой борьбы с fake news. Можно разные сценарии себе представить - например блокировка показа определенных картинок/файлов на устройстве, если у них нет правильной цифровой подписи. https://contentauthenticity.org/
Или, например, механизмы блокировки использования хардвэра, типа GPU, основанные на геолокации или еще чем-нибудь в духе.
Или уже существующие (или планируемые?) регуляции по поводу моделей двойного назначения и того, что должны делать американские облака, если я правильно понял планы американских законодателей (Propose regulations that require United States IaaS Providers to submit a report to the Secretary of Commerce when a foreign person transacts with that United States IaaS Provider to train a large AI model). https://www.whitehouse.gov/briefing-room/presidential-actions/2023/10/30/executive-order-on-the-safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence/
Что касается AGI - это мое личное мнение, но если я правильно понял, все упирается в пределы применимости scaling hypothesis + наличие потенциально невыявленных ботлнеков. Любопытен в этом отношении вопрос потенциального ботлнека по энергетике, наводит на мысли. Думаю, что с прогнозами тут ситуация может быть как с термоядерным синтезом (вот-вот, в ближайшие условные 10 лет последние полвека). Тем не менее, думаю, что нет оснований полагать, что это не случится и в ближайшие годы.
Но вот чего я не вполне понимаю - это как принципиально можно договориться об ограничениях на обучение ИИ. Приводится аналогия с ядерными испытаниями, но она не вполне верная, на мой взгляд. Насколько мне известно, существуют достаточно очевидные фактические признаки проведения ядерных испытаний, относительно легко регистрируемые различными техническими средствами. Также, если я правильно понимаю, существуют косвенные признаки, по которым можно установить, что та или иная страна готовит ядерную программу. Мне кажется, что с искусственными интеллектом так не выйдет, потому что датацентры - вещь достаточно распространенная на сегодняшний день.
То есть возникает проблема невозможности технического контроля этой деятельности (обучения моделей). А в такой реальности, с учетом того, что все понимают возможную пользу от AGI (и возможный урон от проигрыша в такой "гонке") - как договорится? Как страна А может быть уверена в том, что страна Б не ведет обучения таких моделей? Только на основании честного слова?
Естественно, можно подумать о механизмах аудита и каких-то специальных ограничениях на уровне хардвэра, используемого для ИИ, но я не верю, что тут также возможно установление взаимного доверия. А даже если такая регуляция будет применена - это все равно не исключит рисков.
Поэтому считаю что на данном этапе любая инициатива по контролю за обучением моделей упирается в технический вопрос взаимного контроля, который не решен, и, на мой взгляд, вряд ли может быть решен в ближайшее время.
А механизмы, которые под видом такого контроля могут быть внедрены - скорее всего будут использованы для получения конкуретного преимущества. Можно много разного нафантазировать - например, квотирование продажи GPU по разным регионам. Но вполне ясно, что тот кто держит технологию, сможет использовать регуляции как дубину. Мне кажется, что вряд ли кто-то добровольно на такие регуляции согласится.