

Всем хой!
Я провел 10 интервью с софтверными инженерами, которые активно используют AI утилиты в работе, начал внедрять AI в работу своей команды, провел 10+ часов пейринг сессий, прочитал множество статей, и сегодня я расскажу, что же я узнал. А узнал я охренеть сколько всего!
Сначала я расскажу про общие наблюдения, которые я вынес из общения с людьми.
Потом дам практические советы.
А те, кто дочитают до конца и поставят класс, найдут там 3 детально описаных юзкейса.
TL;DR
Почти половина девелоперов пользуется AI редко или никогда. Те кто говорит, что пользуется активно, по факту используют его, по моим ощущениям, на 20-30% (никто же не читает документацию!).
Джуны пользуются больше сеньоров, это помогает им быть на ступень выше.
Практики, которые существенно повысят результативность: промптинг, управление контекстом, дробление на части, повторение запроса, цепочки мыслей.
Call to action
Прежде чем начнем, буквально минуточку вашего внимания
Если вы пишите код или связаны с IT:
Присоединяйтесь к чату, где мы обсуждаем разные утилиты, их ограничения и юзкейсы. Для тех, кто не хочет время на чтение чата, у нас есть канал канал с более концентрированной информацией.
Если вы руководите IT бизнесом или командой разработки от 5 человек
Давайте пообщаемся, хочу задать вам несколько вопросов, я расскажу о внедрении AI в команду.
Как я проводил исследование
Опрос
Начал я свое исследование с того, что задал вопрос в чате Вастрик.Тех, и уважаемые господа оставили под ним свои голоса.
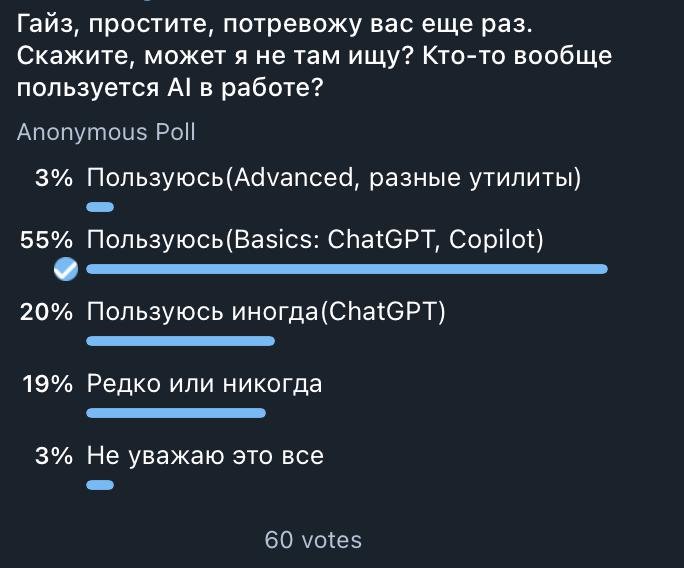
Больше половины 58% отметило, что пользуется ChatGPT и Copilot, что в целом достаточно много, но потом выяснится, что это использование ограничено только несколькими юзкейсами.
Меня еще удивило то, что только 3% выходят за рамки ChatGPT и Copilot, хотя каждый день выходят все новые и новые утилиты. Позже респонденты подтвердили, что информационный шум слишком сильный, такое колличество продуктов сбивает с толку.
Интервью
Данные обнадеживают, будет легко найти людей пообщаться, подумал я. Но я забыл с кем имею дело - программистами, не самыми общительными ребятами.
Правда, вы чего такие стесняшки? Я вам как нанимающий менеджер говорю - софт скиллы важнее хардовых, начинайте уже общаться. Но мы тут не об этом.
В итоге я прошерстил похожий тред на Вастрике и написал всем, кто в нем отписывался, написал друзьям и коллегам, набрал небольшую группу респондентов и пошел общаться.
Пейринг сессии
Где-то на 6-7 интервью я понял, что не получаю новой информации по юзкейсам и желаемой глубины и решил провести пейринг с коллегами.
И о чудо! Инсайты полелись рекой, начали появляться гипотезы и тут же проверяться, вырисовались очень конкретные юзкейсы.
Это тот формат, который я продолжу проводить дальше.
Инсайты
Утилиты
Как уже было понятно из опроса, люди в основном пользуются Copilot(и встроенным в него чатом) и ChatGPT отдельно.
Один респондент рассказал про опенсорс плагин для IDE - Genie, который появился раньше Copilot, в него можно встроить свой токен от OpenAI и делать примерно тоже самое, что с Copilot, только без автокомплита. Плагин поддерживает гораздо больше настроек и кастомный промптинг, чем Copilot, но сейчас проект скорее мертв.
Другой респондент рассказал, что у них в компании запрещено пользоваться публичными моделями, плюс Copilot не дает им необходимой гибкости, и они пилят свое решение для переписывания легаси кода и используют энтерпрайз версию chatGPT от Azure.
У себя в команде мы протестировали еще утилиту CodiumAI для написания тестов. По сравнению с Copilot она гораздо лучше справляется, но об этом позже.
Джуны vs Старички
Джуны пользуются AI в работе гораздо активнее. Кто-то рассказывал, что сеньористые коллеги на работе попробовали Copilot, им не зашло, и они бросили, а молодые коллеги активно пользуются и это им помогает быть на уровень выше, чем их фактический опыт.
При этом от практикующих синьоров я слышал фразы, что для них Copilot - это "джун, на которого можно скинуть тупую работу"
Я люблю программировать
Такую фразу я слышал часто, многие пока не готовы отдать бездушной машине свое любимое занятие.
Кстати, многие сказали такую фразу, что они не используют Copilot для написания базовой логики, ее легче написать самому. Имеет место быть, но еще предстоить проверить с лучшим промптингом.
По поводу психологических причин, не хочу говорить за всех, но я рефлексировал на тему "почему меня бесит хайп вокруг AI", и пришел к тому, что я просто боюсь. Боюсь, что он действительно хорош, не устает, не выгорает и очень дешев.
Мне сразу вспомнилось движение Луддитов во времена промышленной революции, которые крушили станки, потому что боялись, что они их заменят.
Думаю, нам еще предстоит период морального принятия AI.
Обучение
Почти все респонденты рассказали, что используют AI для обучения. И джунам и синьорам он помогает быстро освоится с новым языком или в новой области.
Кто-то использует chatGPT как персонального ментора - учится по видео, если что-то не понятно, задает вопрос chatGPT для дальнейших разъяснений.
Или еще можно валидировать собственные мысли и предположения, например архитектурные решения, давая контекст chatGPT и пытаясь получить такой же ответ.
Я недавно наткнулся еще на такой факт, что гроссмейстеры сильно помолодели, потому что они перестали учиться у людей, а стали учиться у AI. Так что за этим будущее.
Политика компаний
Крупные компании вводят ограничения на использование публичных моделей, опасаясь утечки конфиденциальной информации. Хотя тот же Copilot обещает конфиденциальность и возмещение ущерба в случае ее нарушения.
Также Microsoft предлагает сервис Azure OpenAI Service с теми же моделями, но гарантирующий 99.9% availability time и дающий больше гарантий по безопасности и конфиденциальности данных.
Одна крупная компания, из тех с кем мне получилось поощаться, пишет свои внутренние утилиты для программистов как раз на Azure моделях.
Стартапы же в своей массе вообще никак не озадачиваются вопросом AI, ни регуляцией, ни внедрением.
Я планирую отдельно пообщаться с юристами по интеллектуальной собственности, чтоб узнать оправданы ли опасения, и как их минимизировать.
Каждый использует по своему
Из-за того, что компании никак не озадачиваются вопросом внедрения, а программисты сами не любят читать документацию, каждый использует тот же Copilot по своему.
Кому-то заходит автокомплит, кто-то считает его слишком тупым. Кто-то пишет тесты, а кто-то попробовал, ему не понравилось, и он больше никогда к этому не возвращался.
В итоге получается, что даже те, кто используют Copilot с момента его запуска, не знают как формируется контекст, как добавлять к нему нужные файлы, чтоб повысить качество результатов, или как использовать промптинг.
Я субъективно оцениваю утилизацию функций AI в районе 20-30%
Перформанс буст
Несмотря на то, что AI утилизируется не наполную, он дает большой буст к производительности.
Реальные цифры замерить очень сложно, поэтому даю субьективные оценки как есть.
"Рефакторинг кода - +20-25% точно"
"Тупая работа с кодом - Очень много, +70-80% точно"
"Скорость написания кода увеличилась в 2 раза, отладка кода в 3 раза"
"На 70% экономит время при переписывании легаси кода на новую архитектуру"
От себя добавлю, что мы проводили эксперимент по написанию документации по существующему коду. Мы потратили 2 часа, из которых 1 час проводили разные эксперименты, написали 3 больших документа. Человек, который выполнял задачу сказал: "Если бы я сам писал доку, за 2 часа я бы еще возился с первой, качество было бы хуже, и, вообще, я терпеть не могу писать доки"
Абьюз
Один респондент рассказал забавный случай, когда коллега начал абьюзить функции Copilot по оптимизации и комментированию кода, комментарии не несли никакой функции, а только засоряли код.
Излишние комментарии и "оптимизации" также забивают конктекстное окно. Машине не нужно объяснение, что делает этот if-else, но контекст формируется блоками кода, и излишние комментарии попадут в промпт. А Copilot принимает только 6000 символов.
После разговора коллега перестал так делать, а мы можем выучить урок - все должно быть в меру и нужно проверять за бездушной машиной.
Мы, кстати, тестируем гипотезу, что если в коде уже содержатся осознанные комментарии, то это помогает ассистенту самому писать более осознанные комментарии.
Информационный шум
Проблемы, описанные выше, такие как слабая осведомленность, низкий уровень внедрения, неправильное использование, могут быть связаны с высоким информационным шумом.
Респонденты жалуются на большое количество материалов, кликбейтные заголовки, маркетинговые статьи, низкую выживаемость проектов.
Именно поэтому я решил создать портал, где мы группой практиков тестируем разные утилиты и юзкейсы. Напоминаю, что у нас есть чат, куда вы тоже можете присоединиться.
Собственно, самый жир
Ниже приведу советы, которые закроют 80% вопросов к копайлоту
Используй промптинг
Читаем для начала оригинальную статью.
How to use GitHub Copilot: Prompts, tips, and use cases
Оказывается, если в начало файла положить детальное описание задачи, что вы делаете, то автокомплит справляется лучше. Тоже касается и чата.
Для сложных задач промптинг особенно важен. Нужно как можно точнее описать задачу. Наш промпт на написание документации по коду в итоге составил 2200 символов.
Особенно работает, если "приправить" промпт бранными словечками типа "Avoid lengthy descriptions and marketing-style bullshit", что сразу заставило его писать по-человечески
Управляй контекстом
Контекст - самый главный ресурс, нужно уметь им управлять.
Для этого сначала нужно прочитать How GitHub Copilot is getting better at understanding your code
Можно принудительно добавлять файлы в контекст чата и держать только нужные вкладки открытыми. И почаще открывать новый чат, чтоб обнулять контекс. В долгих чатах Copilot начинает забывать начало.
Разделяй большие таски на части
Думаешь, что модель сходу за тебя напишет длинную документацию или целый класс? - Нет. Чем короче аутпут, тем он точнее.
Составь описание задачи целиком, а потом разбей на шаги, можно даже попросить chatGPT самой написать за тебя шаги, если очень лень. А потом просишь выполнить конкретный шаг из большой задачи.
Повторяй запрос
Бывает такое, что chatGPT выдает отличный ответ с первого раза, а бывает, что нужно перезапустить 10 раз, не меняя промпт.
Строй цепочки мыслей
Мы протестировали утилиту CodiumAI, которая специализируется на написании тестов, она справляется со своей задачей гораздо лучше, чем Copilot, потому что использует итеративный подход.
Первым запросом она генерирует набор тесткейсов к функции, а потом каждый тест пишет отдельным запросом, когда Copilot пытается все сделать одним запросом.
Мы пошли еще дальше в своей лени.
CodiumAI, как и Copilot, плохо работает, если не дать ему пример теста. Мы сгенерировали первый тест Copilot, привели к нужному нам виду и скормили CodiumAI как пример!

Outro
Спасибо всем, кто дочитал.
Как и обещал, в конце описание 3х юзкейсов, которые мы обкатали и уже внедрили в свой проект.
Написание документации по коду
Написание тестов
Рефакторинг кода
А вообще, мы создаем портал, где структурируем информацию по юзкейсам и разным утилитам, придумываем и тестируем гипотезы.
Проект планируется быть коммерческим, сейчас мы ищем контрибьютеров, которые будут получать вознаграждение за свои труды.
И в особенности, мы ищем бизнесы, которые готовы внедрять у себя проверенные практики.
Присоединяйтесь к нашему чату, чтоб не пропустить обновления
Большое спасибо всем, кто откликнулся и законтрибьютил свои знания в проект.
Ну и конечно же, жду вас в комментариях!




Как опознать человека, пользующегося chatgpt: он сам вам об этом скажет. А если вы тоже пользуетесь, то он скажет, что вы делаете это неправильно.
А статью руками писал, или тоже чат-ГПТ? А то я думаю, читать полностью или попросить выжимку сделать
Начал тыкать ChatGPT и Bard где-то в начале прошлого года, из любопытства, был очень впечатлён.
Потом в середине года делал на их основе проект для онлайн-университета предпринимателей для оценки бизнес-идей этих самых предпринимателей. Позже сделал пяток мелких проектов с использованием LLM, много баловался, много думал.
Пришёл к выводу, что это "магическое манипулирование текстом" не решает реальных задач. Ну за редкими исключениями.
Примеры: для нормальных ответов на вопросы тебе скорее всего нужен RAG и хорошо подготовленные данные, для осмысленной генерации кода тебе нужно дофига контекста (тот же RAG + нетрививальные алгоритмы выбора правильных кусков). Только для болтовни в чатах поддержки подходит, и то бесит 😁
Да, я изредка использую ChatGPT (в основном API playground и API напрямую), чтобы разобраться в чём-то мне неизвестном. Например, у библиотеки может быть отвратительная документация — и нужный метод иногда можно найти даже без подкладывания исходников в промт. Но иногда и это не работает, достаточно начать его спрашивать про какой-нибудь clojure.
Что касается использования в работе, пришёл к выводу, что как бы круто всё это ни выглядело на поверхности, по факту "AI пишет код вместо меня" — это скорее такой wishful thinking, чем данность.
Увеличение "производительности", а скорее только скорости генерации текста — она только в начале, и то постараться надо.
Да и вообще-то на 1-м этапе, если и правда хорошо подумать, всё уже можно сделать самому. Да, наверное код будет написан "быстрее", но честно говоря, никогда не встречал проблем со скоростью печати.
Скорее реальные сложности в том, как бы новую функциональность впихнуть в старую архитектуру (даже если она была придумана на предыдущем шаге час назад), не переписывая всё с нуля (ошибёшься, долго, дорого, не нужно) и не прибивая костыль к костылю. Вот это оно как раз решать и не умеет, по крайней мере, сейчас, по крайней мере, из коробки.
Причём это может поменяться в сторону "программисты больше не нужны", я этого не исключаю, но и ставить бы деньги на этот вероятный исход не стал.
Спасибо большое, выглядит, как знак, который я ждала, чтобы начать в эту сторону лежать))
Мне понравилось использовать гпт при прототипировании, придумал гипотезу, быстро накидал код, убедился что говно/работает - пошел писать стори на разработку. У меня последний год абсолютно менеджерская работа где руки до кода доходят раз в квартал, а то и реже, и вот тут гпт мне помогает быстро что-то написать, но важно понимать, это СТРОГО не продакшен реди код, это чисто прототип который надо переписать, и лучше с нуля.
Еще очень заходит когда надо сделать что-то, что не делал уже давно, например написать средней сложности sql запрос. Даешь чату схему бд, можно в двух словах, пишешь че надо, получаешь запрос который надо слегка поправить. Минус тут, что надо быть в теме и понимать где он галлюцинагирует.
Установил себе гпт в Raycast и использую как стековерфлоу, консоль высрала ошибку которую я вижу первый раз - cmd+space, tab, cmd+v - сразу ответ «чел ну ты еблан pod install сделай але» в 90% случаев решение сразу решает проблему, это буст по времени очень хороший, раньше такая дроч могла отнять часы, а сейчас минуты.
По ощущениям, было больше похоже на «очень тупой джун, которому нужно объяснять по несколько раз, чего именно ты от него хочешь».
Дальше присваивания аргументов к полям data-класса в Kotlin Copilot’а не хватило. Более того, на попытку сделать именно так, как его рекламируют - сделать пустое тело функции + комментарий, что она делает, Copilot немножко подумал, и выдал мне потрясающее тело функции: TODO().
То же и с написанием документации - если я уже знаю, что мне нужно в ней, я быстрее это сделаю сам, чем пытаться заставить ChatGPT написать это так, чтобы это было со смыслом и читаемо. Если я не знаю, то я додумываю, или оставляю блоки TBD.
Для меня чат GPT является просто Гуглом на стероидах, большинство ответов на вопросы можно найти в несколько раз быстрее, как и ответы на дополнительные вопросы
Раньше нужно было загуглить 1 вопрос, найти какие-то зацепки и ключевые слова и продолжить гуглить уже зацепки и ключевые слова(и так по кругу, пока не найду все ответы, тк редко все ответы в одном месте). В общем приходилось открывать +-15 вкладок и разных сайтов. Сейчас, задаю вопросу чату и почти всегда сразу же нахожу ответ на вопрос. По сути это просто огромная хорошая документация.
В общем просто очень удобно.
Копилот это почти как код ген+предложения в idea. Т.е помогает решать какие-то типовые задачи и ускорять процесс написания кода. Ну и в какие-то моменты нужно меньше гуглить, тк типовые задачки типа найти несколько элемент в списке копилот может решить быстрее чем поиск в гугле.
В итоге продуктивность выросла. Это как перейти с плохого компьютера с слабым интернет, на хороший компьютер с хорошим интернетом. Разница большая, но сверх продуктивным ты не становишься. Становится просто комфортнее и приятнее работать.
Присоединюсь к общему впечатлению. По моему опыту, копайлот удобен в рефакторинге, и автокомплите примитивных кейсов вроде map-reduce, но за ним (как правильно заметили как за джуном) всегда нужно проверять.
И в подавляющем большинстве копайлот-чату не под силу исправление синтаксических ошибок.
Используем AI в EdTech стартапе. В основном для генерации контента и анализа эффективности креативов.
На рынке много классных инструментов. Например, для генерации картинок просто топ Leonardo.ai (есть бесплатная версия)
Жаль в исследовании нет ничего про код ревью (code review). Как кодомакака с большим опытом я способен наговнякать рабочее решение в 99.99% случаев без посторонней помощи. При этом хотелось бы получать фидбэк, особенно когда пишешь в соло без команды других разработчиков.
В идеальном мире, у AI есть мудрость всего гитхаба и понимание контекста проекта. Так что он может указывать мне на тупорылые решения, неконсистентный нейминг или уязвимости. Еще было бы здорово бить по рукам в тех местах, где я вместо использования чего-то готового и подключенного в проект, наизобретал своих велосипедов.
Порекламирую несправедливо неизвестный Phind.com. Услышал о нём, как о годной LLM для кодинга на канале «Запуск Завтра».
Отвечает на голову лучше Bard, Perplexity, субъективно, даже лучше OpenAI ChatGPT (в бесплатной версии по крайней мере). Главные фичи:
Позволю себе закинуть подобное от одной крупной российской компании, у нас в Тинькофф тоже делают подобное, только на своих мощностях, по сути в компании есть безопасный (on-premise) аналог копилота, который развивает отдельно выделенная команда. И так как это внутренняя разработка, ее пробуют обучать на внутреннем же коде, что дает очень хороший буст в качестве автокомплитов предлагаемых ею.
Добавлю свои пять копеек, до чатгпт программирование для меня была - не осуществимая мечта (долго и дорого, а у меня и так жизнь насыщенная), но регулярно возникали идеи каких-нибудь мелких бот-проектов, в итоге я заказывал на фрилансе написание этих проектов.
После того как попробовал чатгпт и оно с первого раза мне выдало готовый результат (который скопировать в IDE и запустить и работает), сказать что я удивился - это ничего не сказать.
После этого я ударился в ботостроение и вон написал тг-бота с нуля полностью с помощью чатгпт.
Так что новичкам для обучения, либо для хобби - самое то.
спасибо за замечательную статью. Очень вдохновляет! Правда, я не программист, соответственно, перейти к принятию AI мне намного легче)