



А вы знали, что есть невидимые символы шириной в 0 пикселей, и они влияют на работу многих систем - от поисковой выдачи до LLM и парсеров? Есть даже отдельные символы, чтобы текст отображался справа налево!
Сокращенную версию поста можно прочитать тут
Скопируйте эти цифры (12345) и пролистайте их: курсор не будет перемещаться между символами с каждым нажатием стрелки на клавиатуре - в тех местах и вставлены невидимые символы. Они влияют на парсинг и SEO, могут повредить ссылки и распознаются LLM.
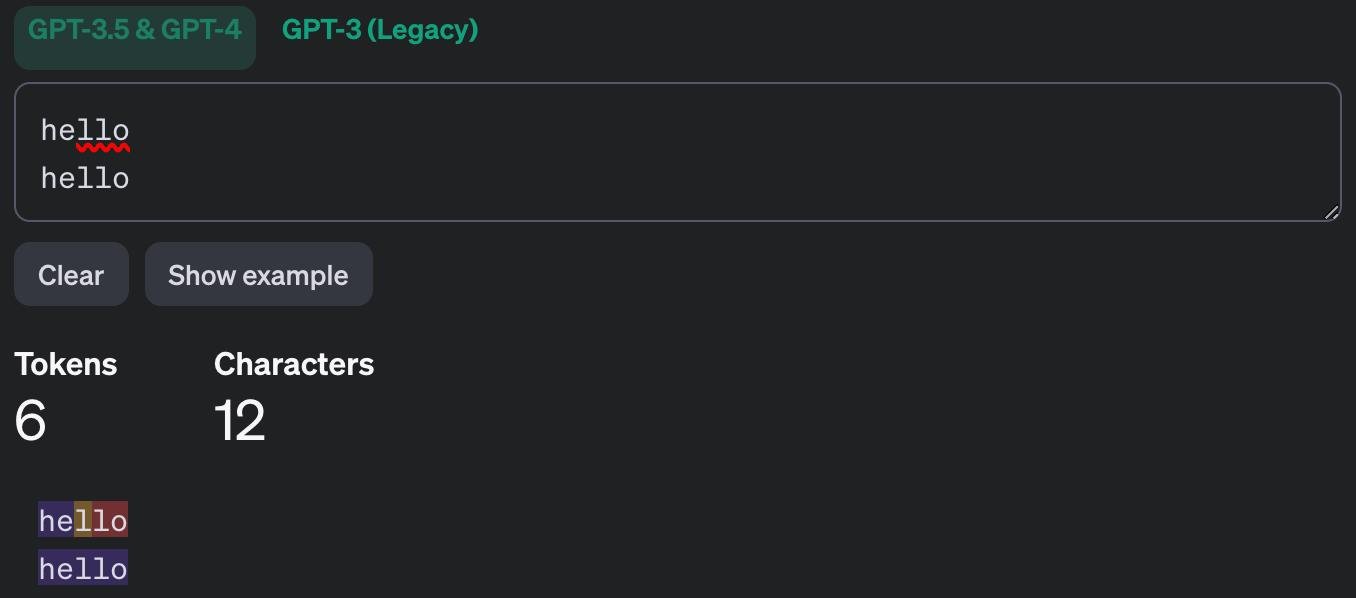
Их можно использовать как водяные знаки: если кто-то разместит копию текста, будет очевидно, что он украден - невидимые отметки сохранятся при копировании. Также можно сделать несколько версий текста и закодировать id или имена пользователей, которым вы его отправляете.
Системы анти-спама или анти-фишинга, как правило, ищут совпадения со словами в базе. Если добавить, например, невидимые пробелы, то текст для читающего будет отображаться без видимых изменений, при этом он пройдет проверку на фишинг. А если разрешить ввод символов юникода в юзернеймах (например, чтобы можно было ввести иероглифы), то у вас могут появиться юзеры с невидимыми и некликабельными юзернеймами - привет дискорду и некоторым компьютерным играм. Убедитесь, что вы правильно обрабатываете такие символы!
Вот список символов, которые я знаю, они в кавычках, честно-честно:
"" - Word Joiner
"" - Zero Width Space
"" - Zero Width Non-joiner
"" - Mongolian Vowel Separator
"" - Zero Width Joiner
"" - Left-to-right Mark
"" - Right-to-left Mark
"" - Zero Width No-break Space
"" - Left-to-Right Embedding
" Right-to-Left Embedding - "
"" - Pop Directional Formatting
"" - Left-to-Right Override
"edirrevO tfeL-ot-thgiR - "
"" - Invisible Times
"" - Invisible Separator
Какие-то символы заставляют текст отображаться справа налево, а некоторые запрещают перенос символов - можно сделать так, что "км/ч" не перенесет "ч" отдельно, или чтобы "100 км/ч" не разбилось бы отдельно на число и единицы измерения.
Раньше ens, доменная система ethereum, разрешал регистрировать домены с невидимыми символами, из-за чего появились клоны известных адресов - vitalik.eth, visa.eth и другие.
А вот атака со сменой отображения расширения файла. Для этого в название testfdp.exe вставляется Right-to-Left Override, что заставляет текст после этого символа отображаться в обратном порядке.

Погодите, если можно сделать чтобы символы не разбивались при переносе, тогда почему мы все еще постим отсталый ascii art, у которого постоянно ломаются руки из-за переноса на другую строку?! Представляю вам неломабельный chad-art: ¯\_(ツ)_/¯ (╯°□°)╯︵ ┻━┻

А еще оказалось, что эти символы используются в эмодзи! Если поставить 🫱 и 🫲 подряд, а потом поставить между ними Zero Width Joiner, то вместо них отобразится 🫱🫲 ! Так работают многие эмозди: 👩🚀 (👩[ZWJ]🚀), 👨🍳 (👨 [ZWJ]🍳) и многие другие. Так же работает и смена цвета кожи, волос и остальные параметры.
Вернемся к чуть более скучным вещам. Оказывается, что существуют символы длиной в один символ (простите за тавтологию), которые кодируются LLM как несколько токенов, и они при этом невидимы! Mongolian Vowel Separator кодируется как целых 3 токена! И это происходит не только в tiktoken, но и в токенизаторе от Anthropic.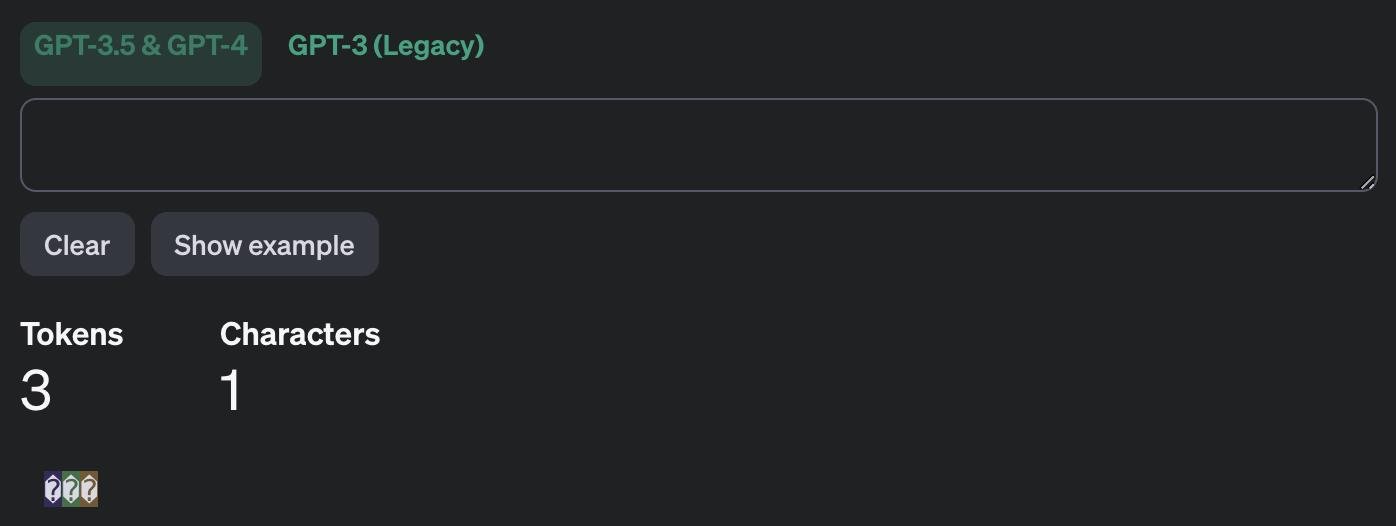
Из-за этого возможна атака скрытого перерасхода токенов: при размещении невидимых символов расходуется больше токенов, чем кажется. Невидимая строка длиной, казалось бы, в 0 символов (можно написать какое-нибудь слово или фразу для отвлечения внимания) может использовать максимальное количество входных токенов модели.
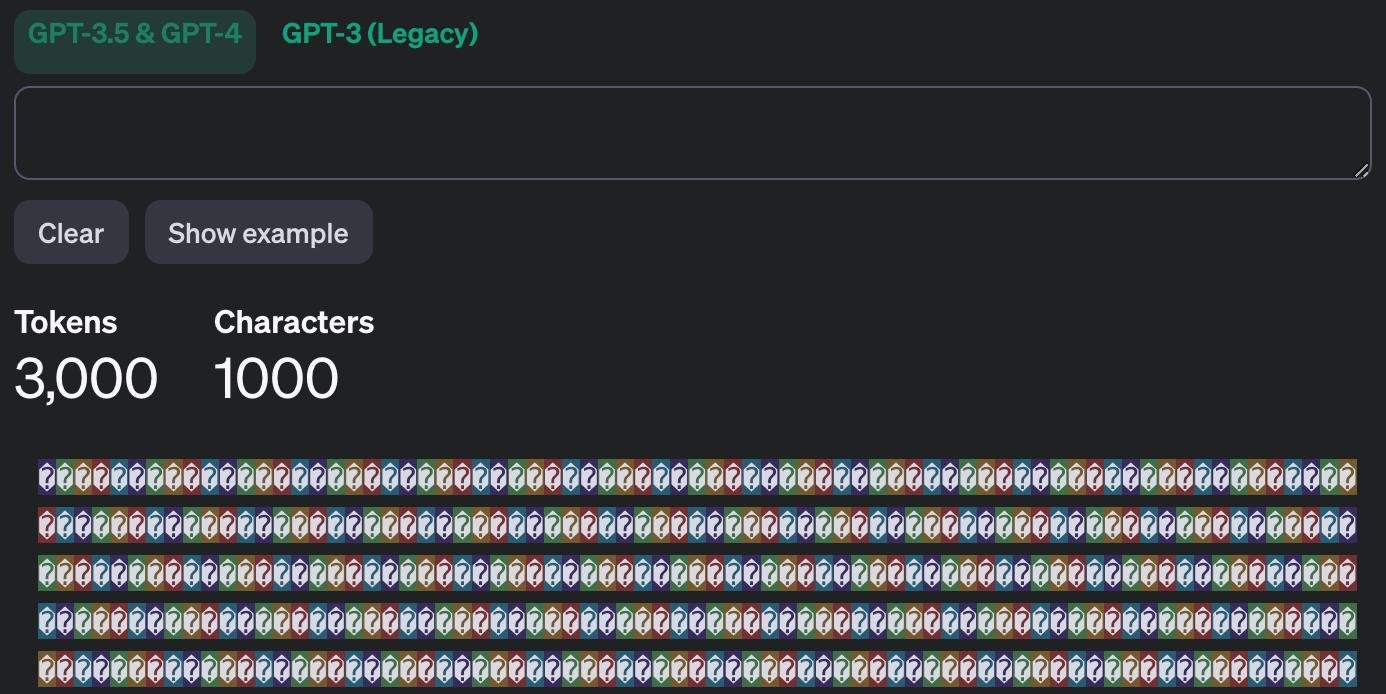
Всегда считайте токены перед отправкой данных в LLM, не смотрите "на глаз" - не пытайтесь считать их через подсчет символов. Используйте специальные библиотеки, например, tiktoken.
Компании, обучающие нейросети на текстовых данных, должны знать о существовании таких символов юникода и отсеивать poisoned данные и случайно попавшие в текст символы. В открытых датасетах они уже есть.
Я также уверен, что невидимые символы могут скрывать различные команды LLM, но мне пока не удалось надежно воспроизвести эту атаку. Идея состоит в том, чтобы написать запрос к LLM, добавить невидимые символы и заставить LLM сделать что-то совершенно другое. У некоторых моделей также ломается защита - они забывают, что нельзя отвечать на какие-то запрещенные запросы.
Upd: как подсказали в комментариях, невидимую атаку уже нашел инженер из Scale AI, который как раз занимается изучением атак на LLM.




Больше странного ойти вперемешку с новостями можно найти в моем телеграме. Спасибо за чтение!
Для кодирования текста в инъекции можно использовать символы из Tags блока юникода, PoC.
Сейчас ChatGPT/апи OpenAI это легко фильтруют, но другие модельки могут быть ещё уязвимы
ЕБУЧИЙ ЮНИКОД
дополнительной чтение по теме — https://tonsky.me/blog/unicode/
А эти ваши невидимые символы они с нами в одной комнате?
Как-то давно работал над парсером текстов из книг epub и обнаружил там хитрый баг, что в некоторых словах количество символов явно не совпадало с тем, что я сам видел глазами.
Подумал, что кукушечка все и программировать больше не придется — а потом нашел в слове скрытые символы разбивки слов по слогам, которые используются для корректного переноса слов в читалках 🙀
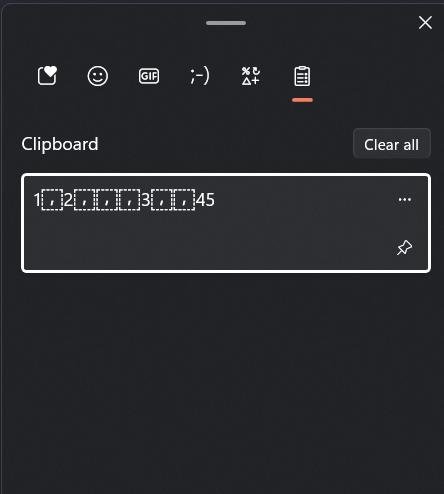
Клипбоард винды кстати их распознает
Оставлю свою любимую статью на тему юникодовых пробелов
https://jkorpela.fi/chars/spaces.html
Это ж можно в качестве вотермарков оставить целую программу на whitespace (с маппингом символов)!
А если вы наоборот хотите от всех этих символов избавиться - очень хороший и портабельный скрипт можно найти тут https://www.datafix.com.au/BASHing/2021-12-08.html
А вообще есть Data Cleaner's Cookbook, советую его всем, кто часто перегоняет данные/интегрируется с левыми системами (😭😭😭):
https://www.datafix.com.au/cookbook/
Телега кстати распознает текст из топика, показывает пробелы в сообщении.
😱 Комментарий удален его автором...