
Раньше искусственные языки или конланги придумывали для международного общения или разговора с богами. Сейчас создание языков — это просто хобби. Сообщество таких энтузиастов настолько большое, что вы легко найдёте на ютубе с десяток туториалов про то, как придумать свой искусственный язык любой степени сложности. Поэтому я не буду погружаться супер-глубоко, но смогу написать ещё один пост про это, если попросите :–)
Искусственным языком обычно считают язык, который придумал один или несколько человек с определённой целью: общения (эсперанто, межславянский), философского упражнения (токи пона, ифкуиль) или использования в творчестве (квенья, валирийский). В отличие от новообразованных естественных языков, которые складываются сами по себе в сообществе — например, языки глухих, пиджины и креолы (ток писин, ндюка, нигерийский пиджин).
Как это работает
Чтобы придумать язык, надо понять, как языки работают в принципе. Я кандидат филологических наук, поэтому мне с этим было чуть проще. Но всё равно, чем дальше я пробовал расширить словарь, тем больше приходилось вспоминать вещей из курса «Введение в языкознание» и изучать дополнительные материалы.
Есть более-менее стандартный алгоритм создания искусственного языка:
- Поставить цель.
- Ограничить звуковой инвентарь.
- Придумать базовый набор слов.
- Выбрать способы выражения грамматических значений.
- Разработать письменность (необязательно).
- Создать диалекты.
- Тестировать.
С каждого последующего пункта часто придётся возвращаться на предыдущие, чтобы что-то подтюнить и поправить.
Для всех этапов как правило существуют программы, которые помогают любителям языков создавать слова, генерировать фонетические изменения в диалектах или составлять таблицы спряжения глаголов. Один из списков таких программ есть тут.
Мой язык
Сразу предупрежу, что я не пошёл по алгоритму, когда придумывал свой язык, поэтому пришлось многое переделывать и возвращаться к началу :–) Дальше начинается задротство.
Идея
Я фанат письменностей, поэтому свой язык я начал именно с букв. Как-то раз я сидел и придумывал знаки, вдохновлённые армянским письмом. У меня получился небольшой набор — и я решил попробовать собрать их в алфавит. Тогда у меня была идея о том, чтобы обозначать звуки в, ф и w одной буквой, но в процессе работы она не выжила :–(

В левом нижнем углу — буква с шапочкой, которая дала идею о том, чтобы обозначать гласные или надстрочными знаками или модификациями букв. В это же время я подумал, что было бы здорово включить странные аффрикатоподобные звуки (похожие на тш или дж) — «бж» и «пш». Тем более, что в целом такие звуки существуют, просто очень редки (0:28):
Дальше довольно быстро получилось назначить всем буквам по звуку, придумать значки для гласных, доизобрести недостающие буквы и создать упрощённый рукописный вариант написания каждой из них. Такую красивую картинку собрал уже значительно позже.

Обычно на предыдущем этапе я бросаю сделанную письменность и начинаю придумывать новую. Но в этот раз я решил пойти до конца и всё-таки сделать свой язык.
Начало работы
Я хотел сделать язык достаточно простым с точки зрения грамматики. Несколько идей взял из японского языка:
- Два времени — прошедшее и непрошедшее;
- Отсутствие категории числа — все существительные по умолчанию множественного или общего числа.

При этом, у глагола и местоимений есть стандартные три лица — мы (bzy), вы (faz) и они (daz). Чтобы сказать я или ты, нужно добавить «один», то есть «один-мы» (gy-bzy) или «один-вы» (gy-faz). Это подразумевает, что носители языка живут в обществе, где коллектив важнее отдельно взятого человека.
Раз я придумал слово «один», то надо придумать и числительные. Я выбрал двадцатеричную систему счисления (как в грузинском или французском), но добил её до конца — то есть для слова «сто» нет отдельного обозначения (это bzang-psyz — «20×5»), но зато есть для слова «двести» (mzang). Это же слово значит «много».

Дальше я понял, что надо как-то обосновать появление сочетания bz в языке — и вот тут я свернул на скользкую дорожку. Я начал придумывать праязык.
Праязык
Поскольку языки меняются и эволюционируют, лингвисты дополнительно выделяют праязыки — формы языка, на которых сейчас не говорят, но которые когда-то были полноценными разговорными языками. Например, для русского — это древнерусский, праславянский. Для английского — англосаксонский и прагерманский. Для испанского — латынь. Для них всех — праиндоевропейский.
Зная слова праязыка и принципы звуковых изменений в конкретном языке, можно логически вывести современные слова. Только обычно лингвисты это делают в обратную сторону — восстанавливают праязыки.
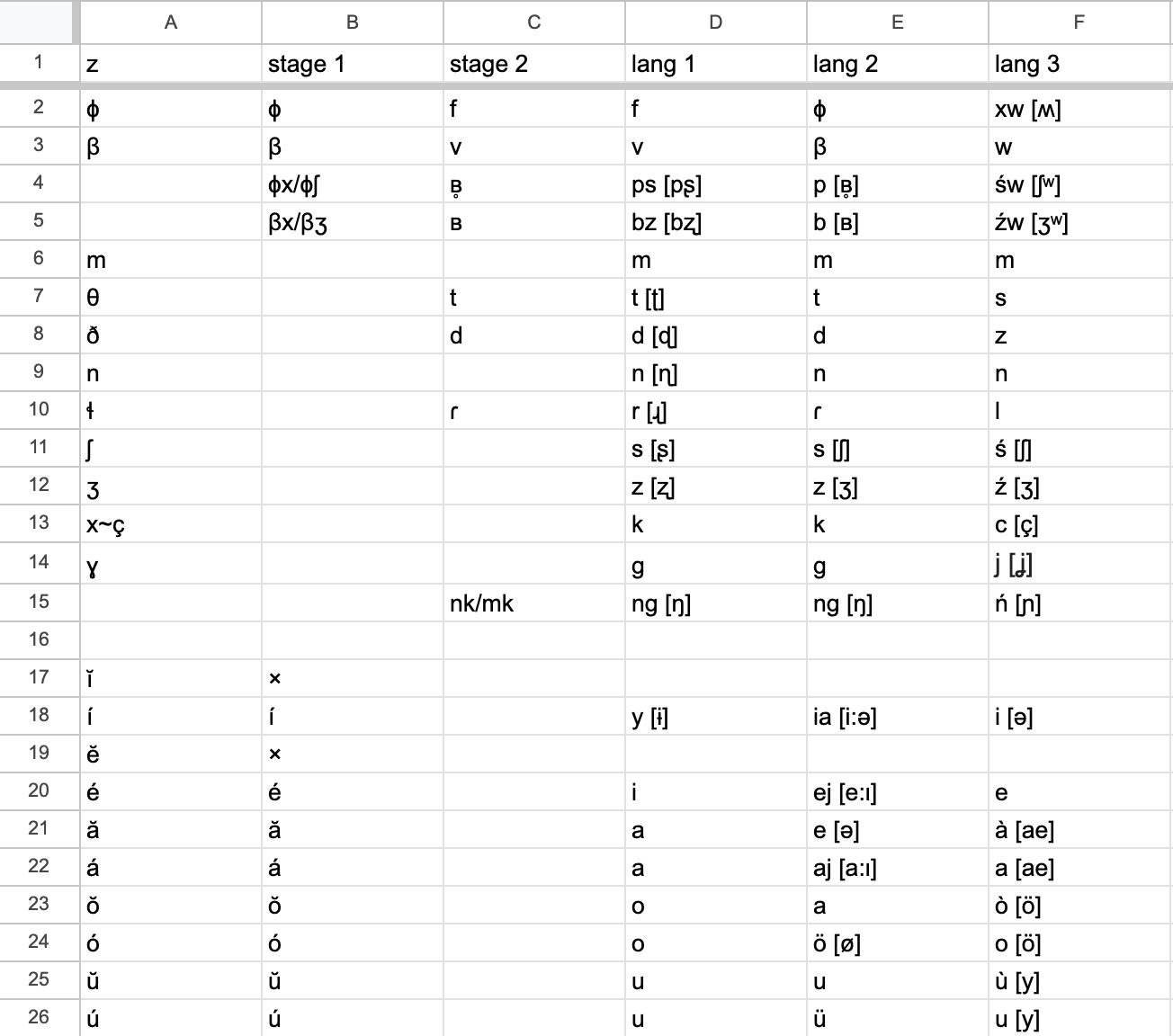
Я придумал, что в моём праязыке будут краткие и долгие гласные, а краткие потом выпадут (как в русском). И из сочетаний, где они выпали между v-x, f-x, v-z, v-s, f-z и f-s, образуются bz и ps. И таких случаев должно быть много, чтобы язык приобрёл то звучание, которое мне нужно.
В результате пришлось добавить гораздо больше фонетических изменений и получилась вот такая cхема:

Но, как вы знаете, из латыни, например, появился не только испанский, но и французский, итальянский, румынский и другие языки. Ну и я тоже решил сделать пару диалектов с другими фонетическими процессами. В языке 2 гласные превратились в дифтонги, а в языке 3 приобрели тоны. Кроме того, в языке три очень сильно изменилось произношение всех изначальных звуков праязыка.
Письменность
Если вы помните, всё это изначально затевалось из-за письменности. Её я тоже расширил и модифицировал.
Появилось несколько почерков для языка 1 — руны, устав/маюскул, скоропись/минускул и рукописные буквы, максимально упрощённые. Также появился отдельный вид печатных и рукописных букв для языка 2, и небольшие видоизменения рукописных знаков в языке 3.

Результат
До конца ещё далеко, но у меня уже есть несколько десятков слов, некоторая часть грамматики, три диалекта + праязык, куча разных письменных знаков. Ну и создание языка это всегда скорее процесс, чем результат — всегда есть что добавить, поправить и доработать.
Закончу примером текста на праязыке и языке 1 (zabzy):
Proto-zabzy: mazánex-mazánex xéfulánelúgi ma gi dázi: gexél nu xut nu závizí lafínelúgi xo xut nu lafisó ma vaxímex nu závizí xuvun latúnelú ta sávizínelú líxetú ma dázi.
Modern Zabzy: mazmazang kifuranrug ma daz: kir-kutnu zabzy rafynrug ko kutnu rapso ma vakynu zabzy kuvun ratunta sabzynru ryktu ma daz.

Перевод: The wise elder, respected by all in the community, has shared stories of the past and will continue to guide the young.
Задавайте вопросы в комментариях — не хотел делать пост слишком объёмным, но готов рассказать о всех деталях :–)
Класс, большая работа проделана! Я тоже в юношестве увлекся конлангами, в результате этого появился мой никнейм) Правда, это единственное что выжило - записи куда-то безвозвратно сгинули. Для интересуюшихся рекомендую "The language construction kit" by Mark Rosenfelder , для введения в тему
Просто классно, что играешься во всё это
Очень интересно, что LLM, сутью которых является работа со смыслами (как и любых языков), способны придумывать коланги (genlangs в этом случае), а также подхватывать другие коланги, на которых не обучались. Чем больше корпус текста с переводом, тем лучше подхватывают.
В качестве шутки, основываясь на маленьком розетском камне из поста, варианты перевода фразы "Космические киты поют мелодии звёзд":
Судя по всему, попадание абсолютно мимо, но очень интересно потом скормить актуальным LLM корпус текста побольше (200к токенов) и посмотреть, что получится.
Можно ли изобрести визуально более лёгкую и оптимальную письменность, чем латиница? С точки зрения дизайна. Если кто-то уже пытался измерить «лёгкость», где об этом почитать?