
В ходе попыток прокачать навыки аудирования захотел попробовать собрать себе аналог WhysperSync.
Т.е. синхронизировать текст книги с её аудиоверсией, и добавить рядом еще литературный перевод. Но локально, без необходимости покупать книги в определенных сторах и отдавать задачи на чужие сервера с LLM.
ещё не совсем LLM/GenAI, но уже и не руками
Для теста выбрал "Властелина Колец" – он сложный с точки зрения грамматики, и известен фантазией переводчиков.
Для начала проверил, что chat-gpt справляется с задачей синхронизации двух переводов средне, с какого-то момента начинает галлюцинировать, и вдобавок быстро отказывается работать с защищенным авторскими правами текстом (хотя если владеешь двуми книгами и одной аудиокнигой – нет ничего криминального в том, чтобы просто читать и слушать их синхронно). Но где не справляется одна нейронка, справятся 3-4 других вместе.
Сначала задача не показалась сложной. Whisper от OpenAI запускается локально, и если скормить ему текст книги и аудио, выдаёт хорошие результаты.
SubPlz - неплохая обёртка для него от фанатов аниме. Немного программерской магии с версиями Python и Cuda (а также фиксов их core lib с кодировками и английским языком вместо японского) – и он отлично работает на локальной видеокарте. На выходе получаются субтитры на английском. Из приятных бонусов – Whisper работает с любыми языками.
Дальше оказалось сложнее. Сопоставить английскую фразу русской из перевода совсем нетривиально. В теории – с этим должны справляться мультиязыковые модели BERT. На практике почему-то не справлялись. Изначальная задумка была попробовать сопоставить английскую фразу всем вариантам различной длины на русском и выбрать лучшую.
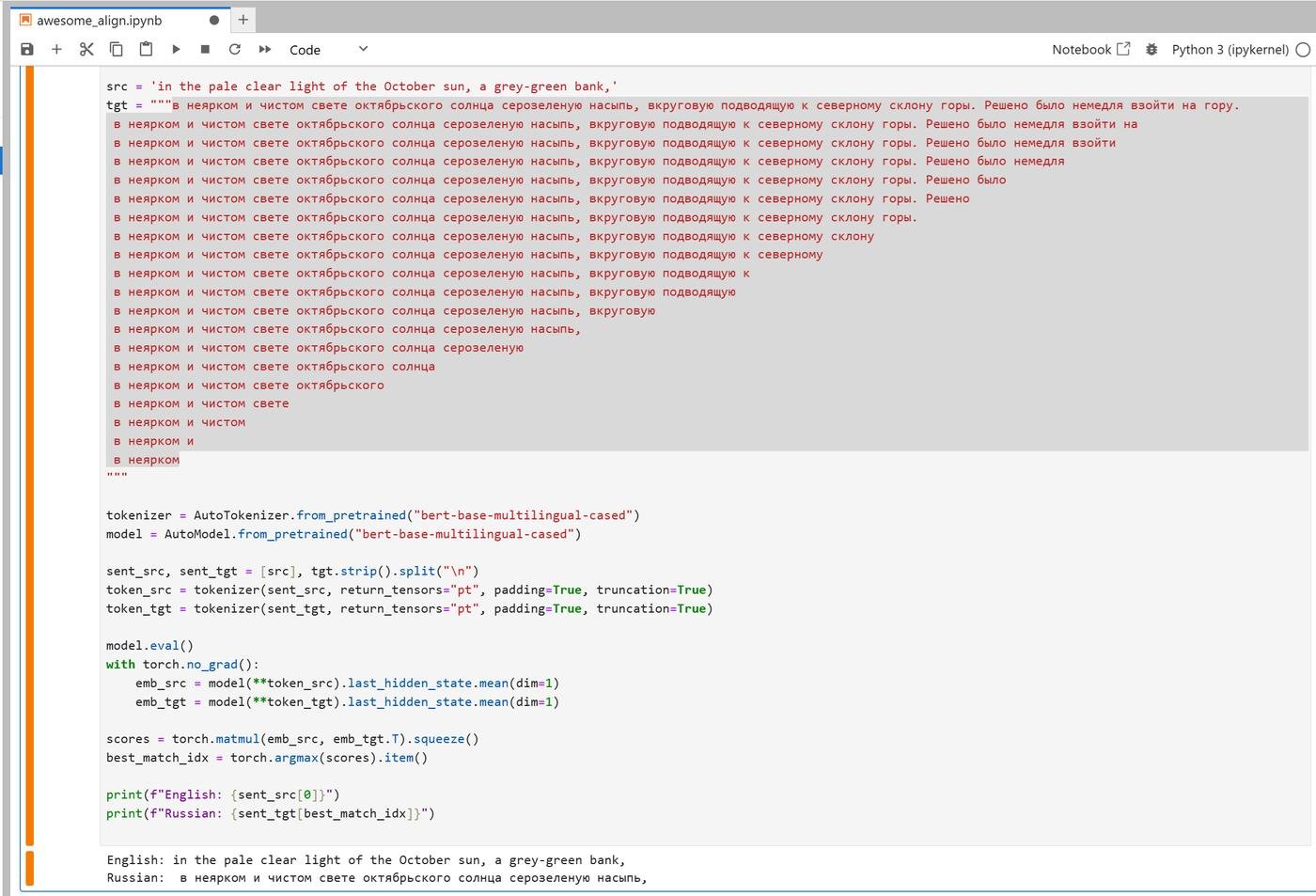
Стабильного результата таким образом добиться не удалось даже с разными метриками и вариациями алгоритма – очистка токенов, динамическое программирование с попыткой предсказать несколько следующих фраз, хитрое нормирование по длине фраз, и прочая магия-вуду не помогли. Вдобавок, работа с фразами из субтитров, а не целыми предложениями, сильно усложняет работу (модель на такое не тренирована, да и в принципе структура языков не всегда позволяет сопоставить части предложения). Хотя может я просто не научился их правильно готовить.
Лучший результат таким способом – это AI-подсказки, каким может быть следующая фраза. Но даже так, с 80-90% точностью, оставшиеся 10-20% для всей книги – долгая работа, вдобавок иногда взрывающая мозг несоотвествием русского литературного перевода оригиналу. Вот пара примеров (на всю трилогию их тысячи):
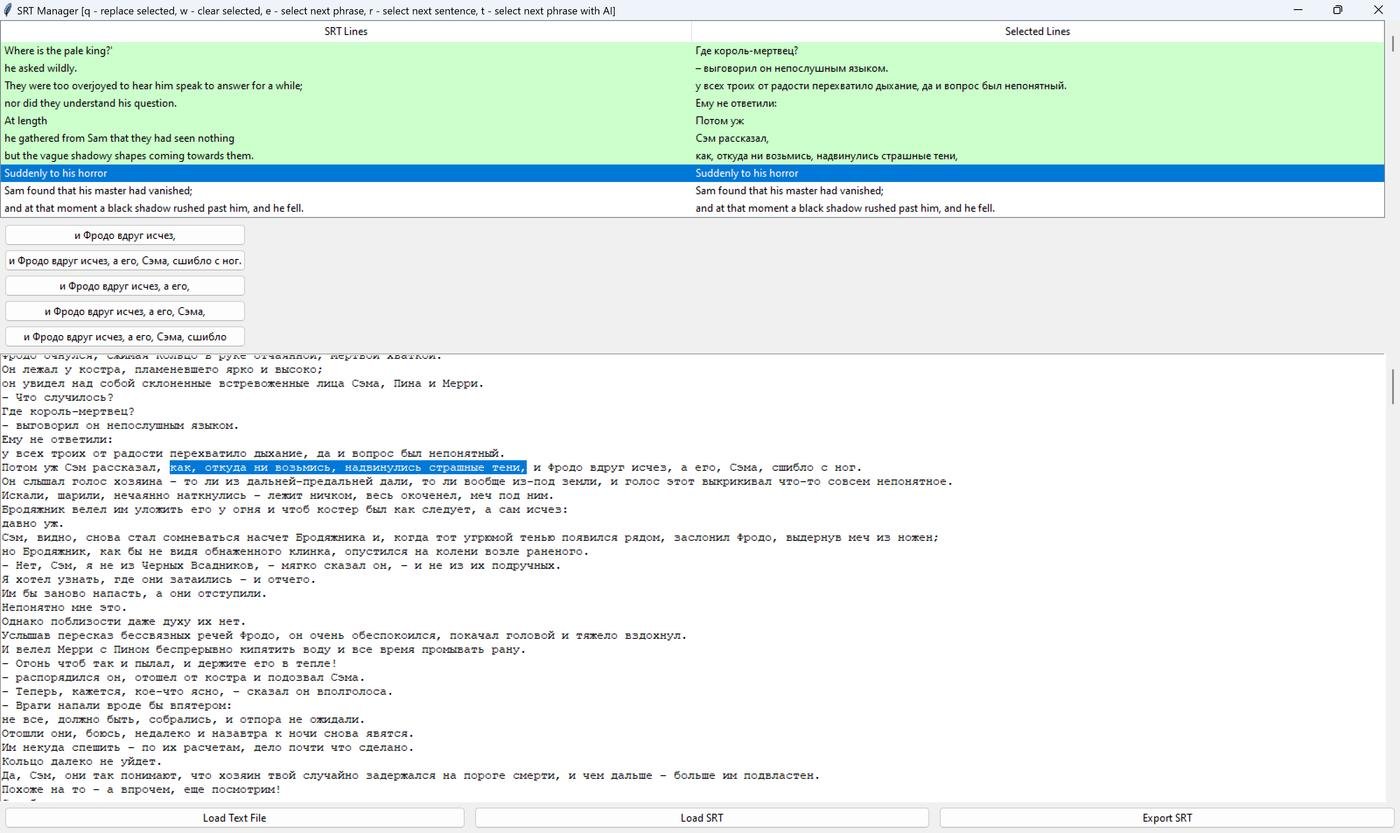
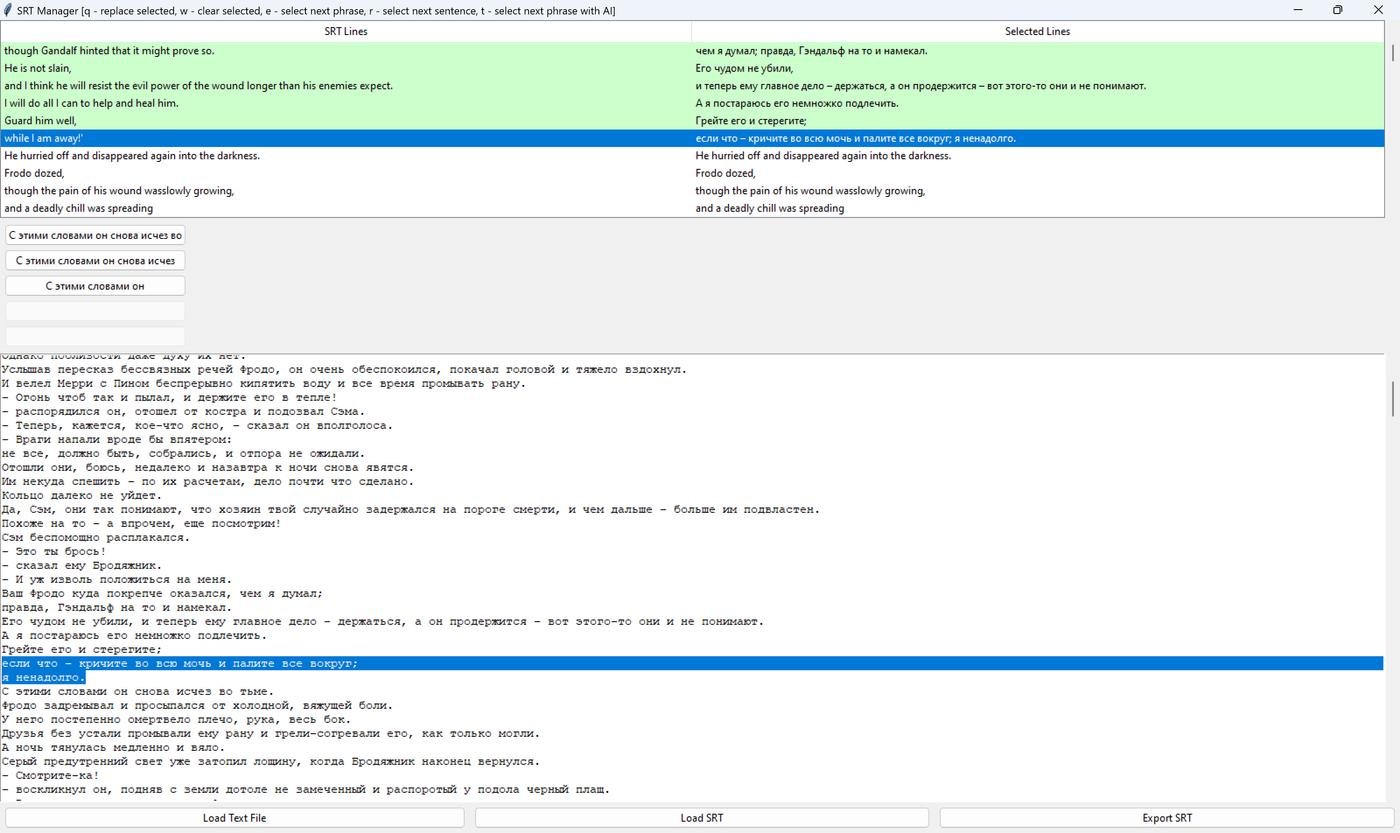
кричите во всю мочь и палите всё вокруг?
Поэтому тут я вернулся назад к работе с предложениями, чтобы попробовать сопоставить хотя бы их. Разбить текст на предложения – не такая элементарная задача, как может показаться программисту. Можно сильно удивиться, как много в языках нестандартных способов использовать знаки препинания, и как много всего интересного в юникоде. В общем, для токенизации текстов на предложения лучше не морочить себе голову и тоже воспользоваться натренированными моделями. Я брал spaCy – у них есть модели для 25 языках, натренированные на википедии и новостях, в принципе справляются хорошо. На выходе получаются отдельные предложения на русском и английском. Например, для 12-й главы – 503 и 588 предложений.
Лучшее, что нашлось для сопоставления предложений – hunalign. Один из плюсов, что программе можно скормить словарь из соотвествий отдельных слов, чтобы подсказать, что Strider это Бродяжник, а Glorfindel – Всеславур.
Это сильно проще, чем разбираться, как наложить патч с дообучением или кастомными весами слов, или еще какими-нибудь методами запихнуть эту информацию под несколько слоёв нейронов. Но даже из и без словаря, hunalign строит его для непонятных ей слов сама.
В принципе, дальше дело техники. Если есть английские сабы с фразами, и пары выровненных предложений, то можно написать скрипт, который заменит фразу этой парой предложений, причём подсветит саму фразу (как в караоке).
Это, собственно, то чего я и хотел добиться – видеть целое предложение и фразу внутри него, чтобы иметь возможность разобрать грамматику (иначе к концу уже забываешь начало).
В этом плане я считаю, что книги для активной работы с языком лучше фильмов, так как содержат больше новых слов и конструкций, а предложения – меньше сокращений, свойственных устной речи (если специально не занимаешься изучением сокращений в устной речи).

пример: первая же сцена из Snatch – кто кого keeps?
В книге скорее было бы что-то из этого:
I give him a hard time to keep him in check
I give him a hard time. It keeps him in check
Последним штрихом – отобразить не только сабы, но и подсветить проговариваемый текст в PDF. Тут тоже немного заковыристо, встроенные в браузер просмотрщики отключили хуки для отображения текста (почему-то это посчитали несекьюрным и Firefox и в Chrome), сторонние читалки тоже не имеют API для динамической работы с текстом (подсветка по таймингам), а парсить PDF на лету – достаточно сомнительное занятие, так как это чисто output-формат. Проще всего предварительно сконвертировать ему в HTML и грузить/подсвечивать уже его.
Получилось примерно так:
(тут не последняя итерация, дальше вроде вышло и на более короткие фразы разбить)
С английским – работает с любой книгой. По идее и с другими парами языков, все используемые нейронки либо мультиязычные, либо имеют модели для двух-трёх десятков языков.
Если хотите помочь попробовать другие пары языков – пишите в tg (чтобы тут пиратчину на разводить). От вас – откопать книгу на исходном языке + её аудиоверсию + перевод, и потом отслушать результат, чтобы сказать, норм или нет получилось.



Интересный подход к решению задачи. Моё почтение. Одобряемс!
Сейчас есть какие-то вещи, которые хочется ещё улучшить? Могу наверное чем-то помочь ))
ответ на это
Скорее получается если с технической стороны смотреть, а не фронда, то литека это упрощенная версия того, что я сделал.
Озвучка роботом очень далека по качеству от профессиональной аудиоозвучки пока что. Если цель - научиться понимать носителей, надо и слушать носителей.
Для меня есть три уровня аудирования:
Между каждым из уровней пропасть.
По идее, еще 4-й уровень – когда понимаешь культуру и можешь переключаться на ментальность носителей, но я не знаю, можно ли так с английским, кажется, максимум для славянских языков возможно.
Неа, см. последний абзац про авторские права. Вдобавок я в образовательных целях делаю для себя, т.е. делаю и слушаю по одной главе до тех пор, пока не ощущаю, что можно к следующей переходить.
На выходе у меня на выходе у меня 2 srt-файла и один большой html (сконвертированный из pdf для удобства подсветки по нему джаваскриптом). Плейер, в который это можно загрузить – простая страничка, написанная на коленке (тут чья нибудь помощь не помешала бы может, сделать нормальный плейер). Её можно или открыть в браузере вообще без сервера, или запустить сервер, чтобы с телефона послушать.
Вот эти два srt-файла и html можно было б и "давать послушать друзьям в некоммерческих целях" или "временно использовать тем, у кого и так есть ВСЕ купленные версии" (и то, это право вечно ограничивать пытаются).
Ну, или выбирать произведения, которые в public domain, но если на известные продукты – то это надо ждать 70 лет с момента смерти автора/публикации (смотря что позже). Если с английским текстом ещё можно что-то интересное найти (в том смысле, что язык не устарел ещё), то для русского перевода сложнее, чаще всего их несколько и поздний -- лучший. Аудиокниг 70 лет назад вообще ещё не было, но тут собственно часть начитана изначально для public domain.
Но вообще, я делился инструкцией для того, чтобы и другие могли поиспользовать конечно (хотя бы нерды, которым не лень всё это локально повторить пока). Ну или есть интерес, какие-то книжки могу для теста поконвертировать, желательно не на английском, чтобы попробовать как это с другими языками работает.
Очень классный проект! Когда то так хотел делать для подкастов, что бы изучать язык. Но всё не дошли руки (может у тебя можно такое сделать ? там нужен автоперевод какой-нить хороший видимо). И не давно наткнулся на такую OS либу, может быть пригодиться для выравнивания, не пробовал?
https://github.com/averkij/lingtrain-aligner
Синхронизировал по запросу @bystritskiy Ведьмака на польском, даже получилось чё-то. Ожидается рецензия на качество :)