

Это продолжение рассказа о пути создания одной из самых интересных компаний нашего времени.
В первой части мы выяснили, что желающих донатить НКО кучу денег на хорошее дело оказалось не так много. И в случае OpenAI это оказалось критически важно.
Давайте кратко обрисую основные события:
Январь 2014 - Google купил DeepMind
Май 2015 - Сэм Альтман отправил первое письмо
Июнь 2015 - Илон посрался с Ларри на ДР
Июль 2015 - OpenAI завербовали Илью Сутскевера
Август 2015 - заседание комитета по этике DeepMind
Ноябрь 2015 - создание OpenAI
Весь 2016 - сбор команды и поиск финансирования
<<< вы сейчас здесь >>>
Начало 2017 - оценили, сколько денег нужно для AGI
Середина 2017 - вышла статья Attention Is All You Need
Середина 2017 - переговоры по переходу к новой структуре
Начало 2018 - Илон уходит из OpenAI
Середина 2018 - Релиз GPT 1
Срочно переобуваемся!
В первый год главным приоритеом OpenAI было усиление команды. Илон пишет в феврале 2016:
Вероятность того, что DeepMind победит растет с каждым годом. Нам важно добиться значимого результата в следующие 6–9 месяцев, чтобы ключевые таланты по всему миру обратили на нас внимание.
На что Илья ответил:
Для создания ИИ нам не хватает ключевых идей. Мощные идеи рождаются у лучших специалистов. Крупные вычислительные кластеры помогают и заслуживают внимания, но их роль менее значима.
У нас уже есть очень талантливые люди. И есть вполне реалистичный план для достижения результата, способного изменить всю область.
Но прошел год и ситуация резко поменялась — понадобился новый план. В марте 2017 ребята осознали, что создание AGI потребует огромных вычислительных ресурсов.
Грег с командой прикинули, что ресурсы, используемые другими компаниями для прорывных результатов, увеличиваются примерно в 10 раз каждый год. А это миллиарды долларов в год, которые невозможно собрать некоммерческому проекту.

Илья — гений
В июне и июле 2017 Илья Сутскевер классно обьяснил суть ситуации:
Мы обычно считаем, что проблемы сложны, если умные люди долго не могут их решить. Однако последние пять лет показали, что самые ранние и простые идеи об искусственном интеллекте — нейронные сети — были верны с самого начала. А чтобы они заработали нам просто не хватало современного железа.
Из разных интервью я слышал, что Илья был одним из первых, кто поверил в скейлинг. Еще за два года до того, как это удалось подтвердить на крупных масштабах.
В последние годы прорывы обычно происходили на моделях, тренировка которых занимала 7–10 дней. Если эксперименты занимают больше времени, сложно держать все данные в голове и итеративно улучшать результаты. Если же они занимают меньше, вместо экономии времени используется более крупная модель, которая замедляет эксперимент до оптимальной длительности. Это означает, что оборудование определяет границы потенциальных прорывов.

Если наши компьютеры слишком медленные, никакая гениальность ученых не поможет достичь AGI. Достаточно быстрые компьютеры — необходимый элемент, и все прошлые неудачи были вызваны тем, что оборудование оказалось недостаточно мощным для AGI.
Несмотря на это, небольшие академические лаборатории могли конкурировать с Google. Потому что 95% прогресса достигается благодаря возможности быстро проводить масштабные эксперименты.
То есть датацентр Google не мог ускорить проведение одного эксперимента — ты все равно ограничен мощностью видеокарт и упираешься в те же 7-10 дней. Имея много железа, ты можешь проводить больше разных экспериментов, но это преимущество не так полезно.
В такой парадигме старый план OpenAI имел смысл: небольшая команда топовых ученых, которые избирательно проводят качественные эксперименты.
Эпоха паралельных вычислений
Но сейчас стало возможным комбинировать сотни GPU и CPU, чтобы запускать эксперименты в 100 раз масштабнее за то же время. Ранее использование множества GPU одновременно было не особо полезно. Поэтому небольшие лаборатории фактически обладали таким же эффективным вычислительным ресурсом, как и корпорации.

В начале 2017 Google использовали для оптимизации классификатора на два порядка больше вычислений, чем обычно. А несколько месяцев назад Facebook показали в статье как обучить большую модель ImageNet с практически линейным ускорением на 256 GPU.
За последний год Google Brain показал впечатляющие результаты т.к. у них в 10–100 раз больше GPU, чем у остальных. Мы оцениваем, что у них около 100 тысяч GPU, у FAIR — 15–20 тысяч. DeepMind выделяет 50 GPU на одного исследователя и арендовали 5 тысяч GPU у Brain для AlphaGo.
В старом посте в блоге OpenAI даже есть график, где четко виден этот тренд:
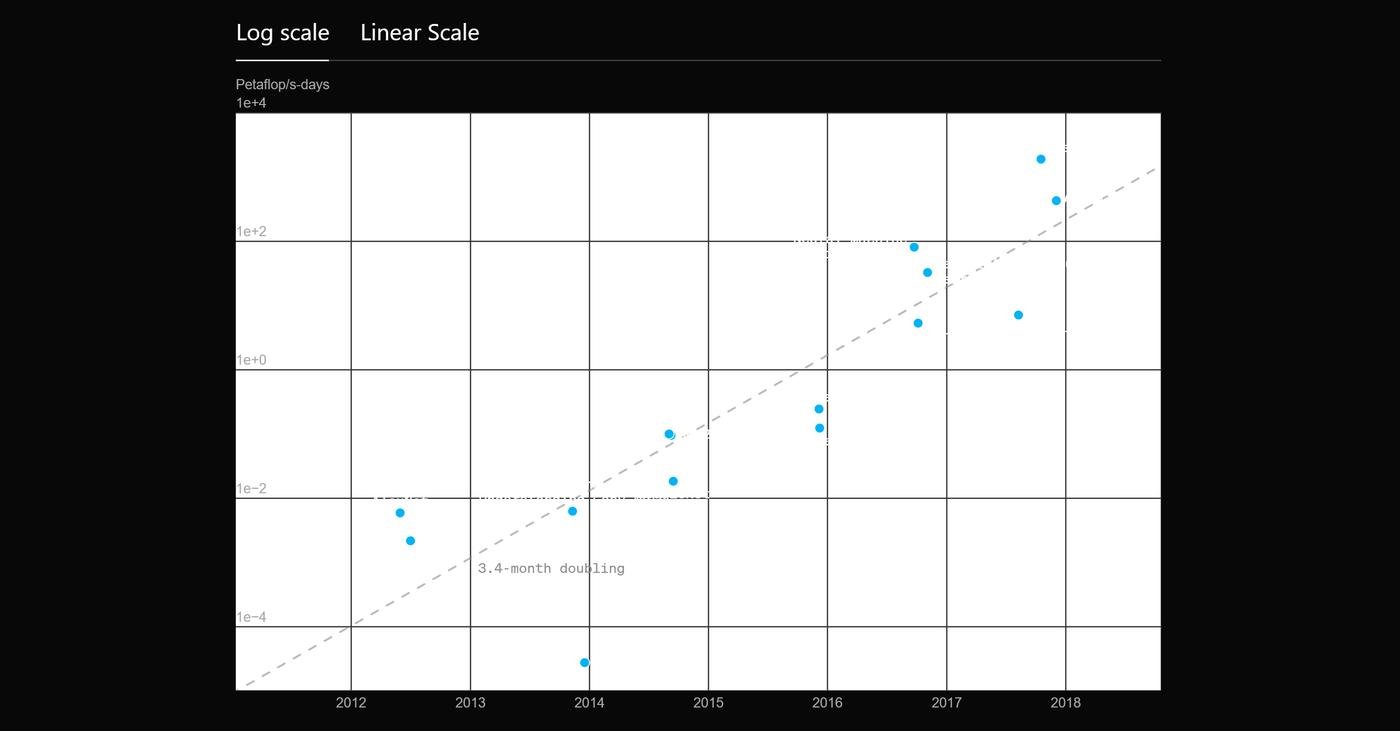
- До 2012: Использование GPU вместо CPU было редкостью.
- 2012–2014: Большинство результатов достигалось на 1–8 GPU мощностью 1–2 терафлопс.
- 2014–2016: Крупные тренировочные запуски на 10–100 GPU мощностью 5–10 терафлопс. Однако видеокарты неэффективно взаимодействовали друг с другом.
- 2016–2017: Появились новые чипы (TPU) и много разных подходов улучшающих параллелизацию.
Каждые несколько лет GPU становятся мощнее. Чем лучше карты, тем больше операций в секунду можно выполнять за ту же цену. Но рост в 10 раз в год происходит потому что ресерчеры постоянно находят способы использовать больше чипов параллельно. И это открывает возможность заваливать проблему деньгами.
Какие Илья делает выводы
Главное — это размер и скорость наших экспериментов. Раньше даже крупный кластер не сильно ускорял проведение большого эксперимента. Но теперь можно проводить их в 100 раз быстрее.
Если у нас будет достаточно оборудования, чтобы проводить эксперименты за 7–10 дней, история показывает, что все остальное приложится. Это как в фундаментальной физике: ученые быстро выяснят как устроена вселенная, если у них будет достаточно большой коллайдер.
Есть основания считать, что оборудование для глубокого обучения будет ускоряться в 10 раз ежегодно на протяжении ближайших 4–5 лет. Это ускорение произойдет не из-за уменьшения размеров транзисторов или увеличения тактовой частоты; оно произойдет потому, что, как и мозг, нейронные сети обладают внутренним параллелизмом, и уже создается новое высокопараллельное оборудование, чтобы использовать этот потенциал.
Оглядываясь назад, он примерно в два раза переоценил масштаб, но все равно хорошо предсказал тренд.

Почему Илья был уверен в том, что тренд сохранится в ближайшие годы? Так уж совпало, что он опирался не только на исторические данные.
Сюрприз от Google
Ровно в тот же день Google выпустили статью Attention is All You Need, где представили архитектуру трансформеров. Это был поворотный момент в обучении моделей.
Помните, как раньше Сири или Google Ассистент не могли поддерживать длительные разговоры т.к. быстро теряли контекст? Главная причина — ограничение архитектур того времени: модель могла быть либо умной, либо обладать хорошей памятью (упрощаю, но суть похожа).
- Свёрточные сети хорошо масштабируются, но теряют общую картину в длинных цепочках
- Рекуррентные сети лучше обрабатывают длинные цепочки, но плохо масштабируются
Разные модели лучше подходили для разных задач, например для перевода текста важны длинные цепочки, а для генерации изображений — внимание к локальным деталям, которое лучше у крупных моделей.
Трансформеры убрали эту проблему, сохранив лучшее от обоих архитектур. Они умеют видеть общую картину и при этом отлично масштабируются.
Маск просит придумать, что делать
Илье потребовался месяц, чтобы вернуться с конкретным планом, где он раскрывает много деталей о состоянии компании:
Чтобы хотябы в теории остаться актуальными, нам необходимо:
1. Увеличить количество GPU в нашем кластере в 10 раз за 1-2 месяца, с 600 GPU до 5000. Максимальная стоимость этого шага составит $12M плюс $5–6M на операционные расходы на следующий год. Каждый год нам нужно экспоненциально увеличивать затраты на оборудование. Но есть основания полагать, что для AGI может потребоваться менее $10B.
2. Увеличить количество сотрудников: с 55 (июль 2017) до 80 (январь 2018), 120 (январь 2019) и 200 (январь 2020). Мы справляемся с организацией текущей команды, поэтому теперь ограничены числом умных людей, способных тестировать идеи.
3. Закрепить значительное преимущество в оборудовании. Дизайн новых чипов от Cerebras значительно опережает конкурентов. Если они реально работают, эксклюзивный доступ даст нам сильное преимущество. У нас есть идея, как это реализовать.
Всё это потребует значительных финансовых ресурсов. Если мы обеспечим финансирование, у нас будет реальный шанс задать начальные условия для появления AGI. Увеличение финансирования будет идти рука об руку с увеличением масштаба результатов.
То есть у них всего 600 карт, а у Google 100 тысяч! Теперь понятно, почему Илон так часто упоминал разницу в ресурсах.

В общем, план классный, но денег на него нужно намного больше, чем и Сэм и Илон считали возможным привлечь в рамках некоммерческой организации. Поэтому пришлось придумать новую структуру, с которой можно быстро привлекать деньги и при этом сохранять верность миссии.
Обсуждение условий
В июле 2017 Илон и команда OpenAI пришли к общему выводу, что придется переходить к коммерческой модели. В компании появится отдельная часть с понятной для инвесторов целью — зарабатывать бабки. ИИ ресерч остается как есть, а деньги на него идут от нового направления.
Интереснее всего выглядит вариант с поглощением Cerebras, потому что у них уже есть крутые наработки по железу, а у Сэма и Илона есть способность быстро собрать инвестиции под их развитие.
В течение двух следующих месяцев они обсуждали переход на новую структуру. У команды было много вопросов к Илону, но он занял неожиданно жёсткую переговорную позицию.
Илон любит писать прямолинейно, решительно и хлёстко. Но я до этого момента ни разу не видел, чтобы его жесткость и раздражение было наравлено в адрес OpenAI.
В середине процесса Шивон Зилис (она помогала с переговорами как посредник) пообщалась с ребятами и скинула Илону краткую выжимку с довольно логичными и адекватными вопросами. И вот что он ответил:
Это невероятно раздражает. Пожалуйста, убеди их уже заняться созданием компании. Больше не могу это терпеть.
На что он так взбесился я не понял. Ведь он предложил довольно суровые условия: 50-60% компании и должность СЕО. Шивон даже написала, что такие условия обычно не характерны для его других сделок. С другой стороны, OpenAI тоже хотят не мало. Вот самое интересное из письма Шивон:
Если Илон хочет быть CEO, сколько времени он готов выделять на компанию? Нам нужно минимум 5–10 часов в неделю. Это важно, чтобы он успевал погружаться в контекст. Если он не готов к такому, мы предлагаем уменьшить обьем контроля.
Он хочет получить абсолютный контроль? Хорошо бы оставить какой то противовес, на случай если вся компания будет не согласна с выбранным им направлением.
Нам сходу нужно $200M-$1B, чтобы начать собирать датацентр и нанять больше людей. (И купить Cerebras? В письме почему то этого не было. Возможно они уже обговорили условия ранее)
Ребята переживают, что у Илона уже итак много нагрузки. И что если он хочет быть СЕО, то где он найдет время, чтобы успевать погружаться в контекст? Разумный же вопрос, не? Мне сложно сказать, что произошло, но Илон на него в письме не ответил. Есть несколько догадок:
Ребята заебали его своими вопросами. Из-за неопытности, ответы для них не очевидны, а Илону не хочется тратить время на разъяснения. Особенно когда из-за всей этой возни простаивают более приоритетные задачи. Им срочно нужно закупать видеокарты и думать как догнать лидеров, а они лезут не в свою зону ответственности.
Илону важно любым способом продавить свои условия, чтобы оставить бэкдор к управлению компании. Чтобы не произошло как с покупкой DeepMind. Его раздражение это изящная манипуляция: вместо контсруктивного ответа он пишет, что недоволен -> ребята успокаивают его тем, что забивают на свои вопросы и соглашаются на любые условия.
Я не думаю, что тут есть однозначный ответ. Предположу, что оба варианта имеют место. Но как станет ясно дальше, даже они вместе полностью не описывают ситуацию.

В следующей части расскажу, чем всё в итоге закончилось и почему ушел Илон.
(Ссылка на источник с оригиналами переписки)



А я кстати работаю в Cerebras, железо у нас действительно топ, только вот OpenAI уже свои чипы разрабатывают
Первая треть поста как будто повторяла предыдущий, даже перепроверил, не открыл ли я ненароком первую часть. Только началось новенькое и тут же закончилась))
Ждем продолжения, когда следующий сезон?)
Ждём с нетерпением выхода 3-ей части. :) Видимо, уже в 2025-ом.
А где можно увидеть выжимку?