

Поздравляю, вы уже AI разработчик.
Шутка. Вы только на 80% AI разработчик.
AI – теперь коммодити. Кто угодно может превратить свой древний saas в AI-driven за один HTTP запрос, а большая часть AI разработки с первого взгляда выглядит как перекладывание json'ов. Не нужно учить модельки, не нужно их хостить и можно не знать, как они работают.
Лучшая аналогия, которую я знаю – базы данных. Вы знаете, как с ними работать, как писать запросы, чтобы было хорошо. Иногда даже знаете детали реализации, благодаря которым делаете магию, которую коллеги не умеют. В 2% реальных задач. Но в большинстве случаев – это просто черная коробка, с которой нужно общаться по определенным правилам.
Только тут это еще и managed-db (OpenAI хостит все у себя, а вы дергаете их API).
Так что самая большая ошибка – идти изучать классический Machine Learning и обучение нейронок. Это профессия, которая будет вырождаться – большинству компаний больше не нужно обучать кастомные нейронки под свои задачи, когда с ними справляется GPT, ллама или deepseek.
Да, какое-то количество больших компаний будет делать свои фундаментальные модели. Но это уже AI Research, далекий от нашей бизнес-разработки. Считай, разработчики баз данных. Ну и там будут самые топовые пхдшники, и их нужно будет меньше, чем уже есть датасентистов на рынке. (См. предыдущий абзац, чем они занимались, и почему это будет не нужно)
Кусочек базы ML все-таки будет нужен, но про это позже.
Я это к чему – технический порог входа супер низкий. Самое сложное – найти, где этот AI применять.
- Можно делать петпроекты
- Пытаться устроиться в AI стартап (но кому вы нужны без опыта работы с "базами данных")
- Придумать, как AI бустанет что-то на вашей текущей работе.
Я пошел по 3 пути 2,5 года назад, предложив добавить фичу, которую клиенты давно просили, а сделать классическими способами никак не получалось.
Анализировать не только корректность кода кандидатов, которые проходят технический скрининг на нашей платформе, но и его качество.
Вот я придумал что-то полезное. Че дальше?
- Прототип (proof of concept)
- Получение одобрения от бизнеса
- (вот тут нужен кусочек ML) Сбор нормальных данных для итераций и валидации
- Куча итераций с построением разных пайплайнов и оттачиванием промптов (тут будут неожиданно полезен опыт менеджмента)
- Продакшн
Разберу шаги на примере моего первого AI проекта
1. Прототип
Тут даже кодить не всегда нужно. Просто берем нужные нам данные, засовываем в ChatGPT и пишем промпты, пока не получится что-то сносное
Не забываем отключить использование ваших данных для обучения моделей
Я просто выкачал несколько решений кандидатов, подставлял их по одному и вручную прописывал логику для оценки по нескольким критериям, на которые я бы смотрел вручную (типа именования переменных, модульности, читабельности функций, и т.д.)
2. Одобрение от бизнеса
Получаем норм результат на нескольких примерах, идем показывать начальству, выбиваем аппрув на проект + ресурсы на разметку данных. Особенно круто, если подготовить какие-то данные, что эта фича реально нужна.
Например, посчитанное в человекочасах время на процесс, который оптимизируете, или отзывы пользователей, где они жалуются на отсутствие фичи или чего-то смежного.
3. Сбор данных
Это вообще самый важный пункт, потому что shit in => shit out. Ну и глобально, оптимизируеся то, что измеряется.
Тут два важных шага
- сбор самих данных (что на вход идет)
- сбор разметки (ожидаемый ответ идеальной системы)
ВАЖНО: эти данные – не для обучения. Мы вообще тут ничего не обучаем в обычном смысле. Данные нужны для валидации. Чтобы численно сверять разные подходы и выбирать лучший. И показывать метрики бизнесу, конечно.
Данные (1) должны максимально захвытывать всю совокупность реальных инпутов. В моем случае, это были решения на разных языках и разные по успешности и длине.
Разметка (2) должна быть супер качественной. Я выбил по несколько часов срузу у 10 разных разработчиков в компании, чтобы они оценили код по 5 балльной шкале. При чем каждый пример оценивался 2 разработчиками, и минимизировалось число элементов, которые оценивала одна и та же пара.
Нафига так сложно?
Чтобы минимизировать bias (смещение?) особенностей восприятия конкретного разметчика (или конкретной пары). Пишите в лс, если нужен сприпт распределения данных по разметчикам.
Грабли:
Я слишком поздно догадался отфильтровать все элементы, где у разметчиков сильно расходилось мнение. Глупо измерять качество оценки LLM, сравнивая его с оценкой, в которой мы сами договориться не можем.
Абсолютные оценки дают очень низкую разрешающую способность. У меня было много кода на 4 из 5, но это были очень разные 4 из 5. Просить оценить код по 100 бальной шкале было бессмыссленно, потому что люди в целом не очень хорошо дают абсолютные оценки и флуктуации бывают на 10-20 баллов. Правильнее было бы сделать систему относительной оценки, когда разметчикам давалось бы два примера кода, и нужно было бы выбрать из них лучший. И рейтинг ЭЛО, как в шахматах или в llmarena.ru.
Нужно рандомно отложить часть данных (процентов 20) и вообще их не трогать до самого последнего этапа.
Тут как раз душный момент из ML (гуглить train test data leakage). Да, мы не обучаем модель в прямом смысле, а строим систему через перебор промптов и комбинирование запросов. Чтобы понимать, что работает, а что нет, мы прогоняем систему на данных и смотрим где лучше результат. И в этом смысле, получается, что мы типа "обучаем" нашу систему типа "на данных".
Поэтому нам нужна отложенная выборка, которую мы не видим в процессе итераций, чтобы на ней оценить качество итоговой системы "в чистую".
4. Итерации
Большую часть времени после сбора данных мы проводим вот в этом цикле посередине
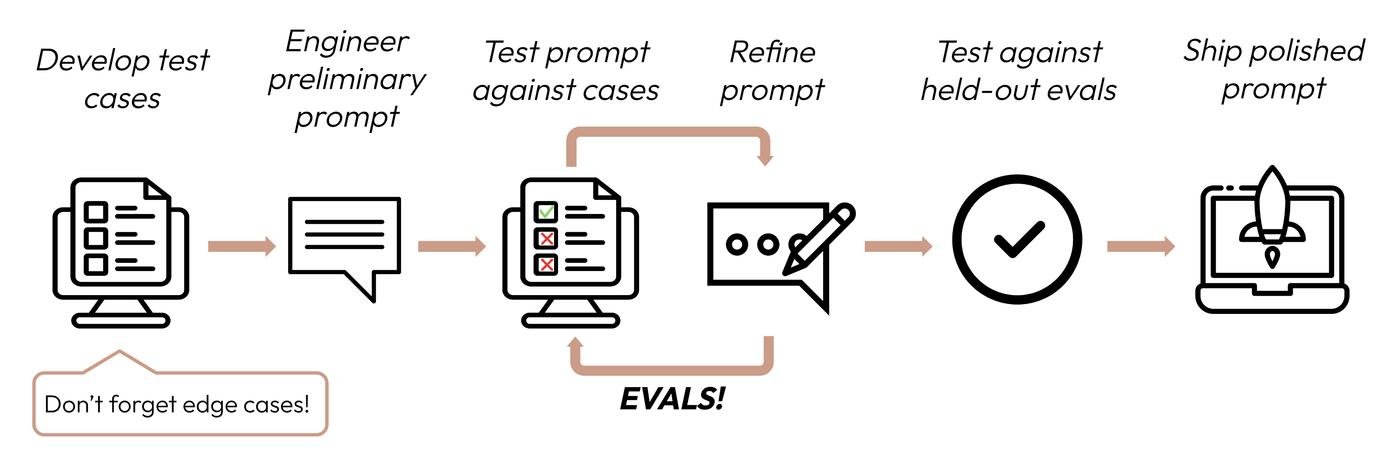
Хорошо, когда наши аутпуты легко проверить на корректность. Например, оценка кода, или id релеватного блока документации для AI техподдержки. Тогда мы просто сравниваем 1 в 1 (для id) или считаем ошибку (для оценки).
А что если мы делаем саммари статей? Как понять, что сгенерированное саммари достаточно хорошее в сравнении с "идеальным" в нашем тестовом датасете? Посимвольное сравнение точно не сработает – текст может отличаться кардинально, при этом по смыслу очень хорошо попадать.
Тут можно много костылей нагородить, но я сразу скажу про OpenAI Evals – новый встроенный инструмент. Есть не только вездесущее семантическое сравнение на ембеддингах, но и фактологическое, что гораздо полезнее. И вообще позволяет задать любые (!) кастомные критерии.

На практике, часто вижу, что многие не греют себе голову с тесткейсами – просто смотрят на результат генераций на нескольких примерах, и интуитивно итерируют промпты. Такой вайбчек. Вполне имеет место быть, так что начинать можно вообще без заморочек с разметкой (но я делал не так 🤷♂️)
Хорошие LLM пайплайны часто напоминают хорошо выстроенные процессы в компаниях. А хорошие промпты – хорошие инструкции или документацию. Попытайтесь думать про LLM систему не как про обычный код, а как про набор умных студентов 3-4 курса, у которых почти нет контекста про ваш бизнес, но которых вам нужно организовать. Реально работает!
5. Продакшн
Тут возникают проблемы, которых не было во время локальных итераций. Выбираем на свой вкус, где стелить соломку:
- Fallback на других провайдеров, если OpenAI не отвечает
- Добавляем жесткие таймауты (частый кейс, что при большом количестве одновременных запросов, небольшая часть из них выполняется сильно дольше)
- Делаем retry + exponential backoff на случай пробития лимитов по токенам или запросам в секунду. Особенно критично, когда у вас низкий уровень аккаунта.
из документации не очевидно, но уровень определяется суммой трат, а не пополнений, так что просто закинуть денег – не увеличит лимиты.
- Логгирование и мониторинги. Сохранять все пары вход-выход – супер полезно. Плюс знать, сколько токенов и когда потрачено. Можно слать руками в какую-нибудь графану, можно использовать специализированные тулзы вроде lunary, а можно использовать новое встроенное логгирование от OpenAI (store=True).
P.s. Справа вверху две крутые волшебные кнопки
Можно еще мониторить data drift, аномалии и т.д., но это даже не следующий уровень, так что забейте пока.
- Если в запросах есть инпуты конкретного пользователя, добавляем его id в запрос через параметр user. Если какие-то запросы будут нарушать политику OpenAI, это поможет и найти нарушителя, и с OpenAI разобраться (вот мол, конкретный юзер косячит, мы сами белые пушистые, а пользователя уже заблочили).
Что дальше?
- Прочитать методичку про промптингу (https://www.promptingguide.ai/)
- Восхититься идеей ембеддингов
- Разочароваться в ней
- Научиться работать со structured_outputs, чтобы структура ответа модели была детерминированной
- Начать использовать LangChain, чтобы понять, что вы это зря.
- Потратить кучу времени итерируясь над промптами в реальных задачах, чтобы обучить свою нейросетку в голове.
- Научиться делать мониторинг (и самих ответов, и метрик, и костов, и ошибок, и дрифта входных данных)
Если вам нравится такой контент, скоро будет разбор structured_output в моем канале, где пишу про LLM, предпринимательство и грабли, на которые наступаю.
Как человек который работает с генеративными модельками каждый день я искренне надеюсь что AI инфоцыган которые пишут обертки над апи и называют это AI продуктом в какой то момент станет настолько много, что они все дружно станут никому не нужны. Как это случилось с инфоцыганами дропшипперами, инфоцыганами с курсами по программированию и другими инфоцыганами.
Так что спасибо за пост, надеюсь таких AI продуктов от предпринимателей которые не разбираются в мл станет больше и моя мечта наконец сбудется.
"Так что самая большая ошибка – идти изучать классический Machine Learning и обучение нейронок. Это профессия, которая будет вырождаться – компаниям больше не нужно обучать кастомные нейронки под свои задачи, когда со всем справляется GPT, ллама или deepseek."
Ога, а потом:
С остальным содержанием поста я не спорю, сейчас рынок не смотря на хайп всё ещё сырой и такое работает, только мне кажется что с годами вырождаться будет скорее такой авантюристский подход, чем фундаментальные навыки
Я достаточно давно работаю в области и сейчас занимаюсь тем, что делаю внутреннюю production-ready платформу для AI-агентов со всеми сложностями вроде scalability и подсчетом бюджета.
Не очень согласна с дихтомией, что либо вы сами обучаете foundation models, либо делаете запросы к провайдерам, а все, что посередине - нишевые знания для R&D отделов в тех-гигантах.
В предыдущих сериях, если что, тоже мало кто на работе обучал Берта с нуля, чтобы сделать чат-бота техподдержки :)
Действительно, с появлением model as a service порог входа снизился, так как не надо собирать данные, потом обучать модель под свою задачу, а потом ее где-то хостить, чтобы показать прототип и узнать, что проект не одобряют. Прототип можно сделать по инструкции выше.
На мой взгляд, сейчас просто по-другому устроен порядок процесса разработки: вы быстро делаете прототип, собираете фидбек, а потом начинаете обучать свои модели поменьше там, где это возможно, чтобы использовать как fallback, router'ы или просто снизить косты.
Если начать считать затраты vs. прибыль, многие задачи гораздо адекватнее решать классическими классификаторами предыдущего поколения или применить что-то из классического Information Retrieval'а.
Проблема в том, что если человек научился только писать промты и запускать langchain, он это не применит. Но не надо стрелять из пушки по воробьям каждый раз, когда вам надо проверить, например, похож ли input на связный текст :)
И чем больше такого вы отсеиваете классическими методами, тем ниже ваши косты на AI as a Judge.
Опять же, многие библиотеки для AI Evalation под капотом представляют собой ребрендинг какого-нибудь давно известного подсчета расстояния между строками.
Как с помощью LLM детектить фрод и поддельные документы? (Серьезный вопрос, нужен совет)
Барев дзес, ахпер джан!
Спасибо за пост. Помог структурировать мысли в голове вокруг того как и куда прикрутить LLM. Пошел курить методичку по промптингу.
Очень согласен про то, что 95% запросов в 95% бизнесов проще будет решать инференсом, и для этого нужны люди уровня "бизнес-аналитик с опытом, описанным в статье", а не ML специалист.
Может быть потом, если все работает, если все отскейлилось и быстро растет, возникнет задача снижения костов, где опять же, вначале можно покрутить готовые модельки подешевле, а уж потом, если не помогло, что-то самим пилить. Не разрабатываем мы для бизнеса же операционку для десктопов или драйвера для принтера. И CRM разрабатываем, только если бизнес с относительно уникальной бизнес-моделью, а для "обычных бизнесов" коробка будет куда лучше.
Наблюдаю все это из достаточно технологичного бизнеса, где есть и отдел, который 10 лет учил свои ML'ки (специфические, но и их, кажется, сейчас смогли бы сделать в разы быстрее-проще-дешевле), и сейчас вижу в бизнесе прямо тысячи чел/дней потенциальной экономии с помощью простых пайплайнов на базе готовых LLM.
Вы таки определитесь. Вы хотите сделать бэкендера для openai-api, либо вы говорите про то, что стало модно называть Applied Scientist?
Промптинг, склейка API и менеджмент данных - это первое.
Но если вам хоть на секунду потребуется своё - тут по цитате Майка Тайсона, все эти ходы в статье хороши до первого удара в лицо. Удара в лицо в виде дебага модели. Как только хоть на наносекунду появится требование "обоснуй" - весь этот api-driven development заканчивается и внезапно нужно разбираться а каким хером это работает, проверено на опыте.
Брр. "Куки-монстр" Винджа вспомнился чет