

Если из нейросетей ты знаешь только о ChatGPT — ты не одинок. С начала 2025 года AI-лабы навыпускали столько новых моделей, что стало легко запутаться.
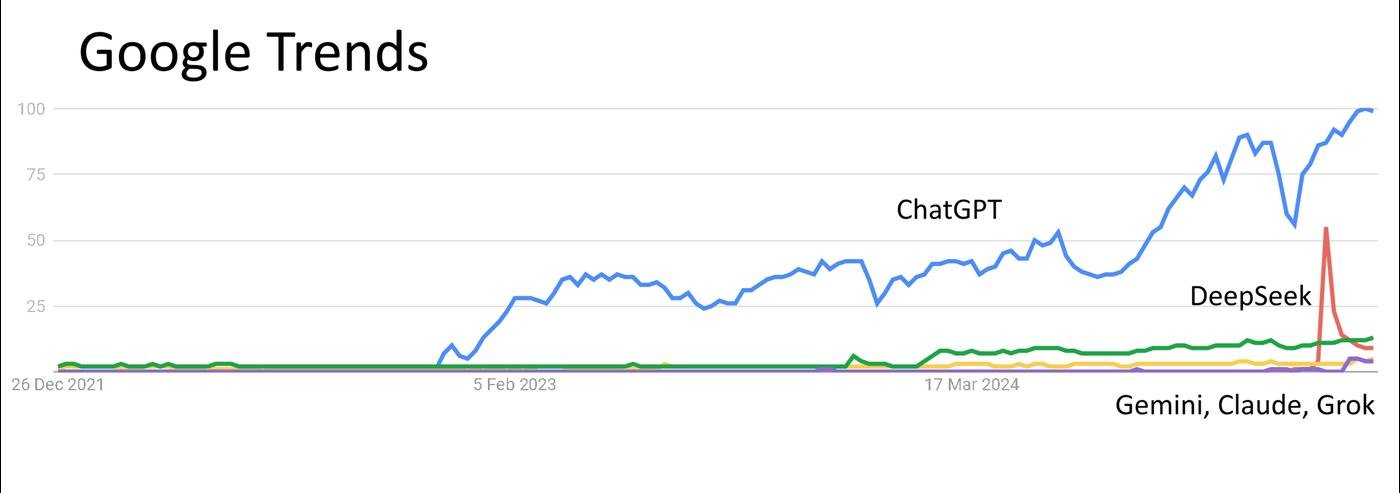
Почему так?
Новые модели классные, но их названия — это пиздец, если честно. Я сам начал теряться и решил разобраться, написав этот пост.
К тому же их еще и по бенчмаркам стало не отличить. Раньше можно было просто сказать: вот эта вот лучшая, все пользуйтесь ей. Сейчас это перестало работать.
Короче, на рынке много действительно крутых нейронок, но ими мало кто пользуется.
А зря!
Дальше я попробую навести порядок в названиях, расскажу про кризис с бенчмарками и накидаю советов о том как все таки выбрать чем пользоваться.
Го.
Моделей стало дофига, и называются они просто ужасно.
Дарио Амодей давно шутит, что мы быстрее создадим AGI, чем научимся понятно называть модели. Гугл тут по традиции впереди всех:
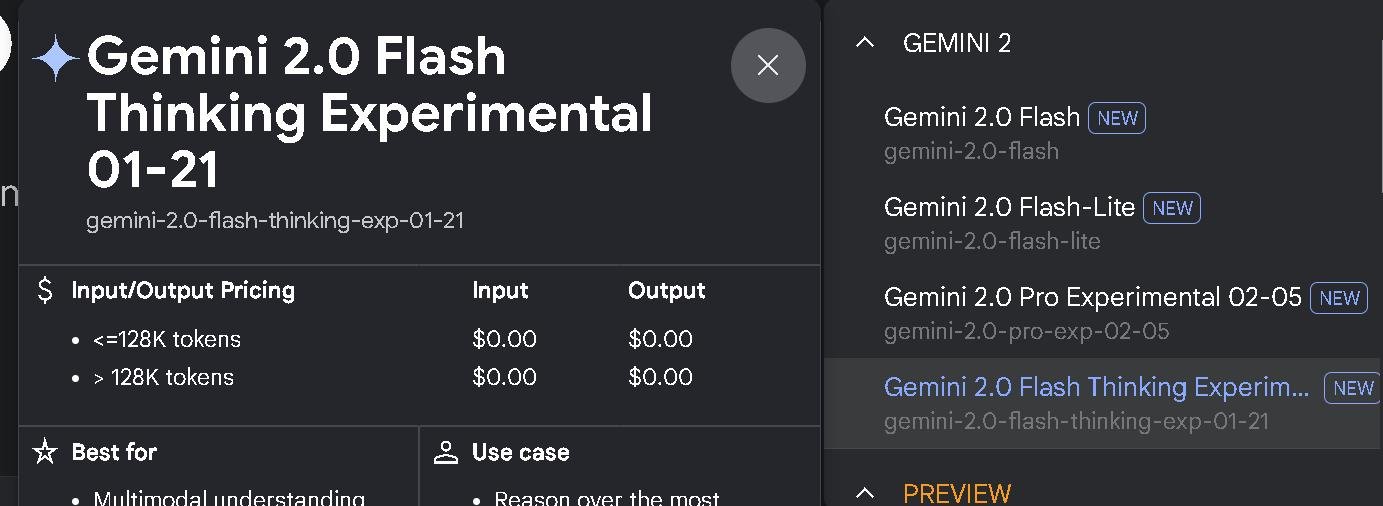
Хотя их можно понять. У каждой "базовой" модели появилось куча улучшений. Разница между ними есть, но не такая, чтобы с хайпом объявлять каждое обновление новой версией. Отсюда и лезут эти префиксы.
Чтобы разобраться, я собрал табличку с моделями разных типов у каждой топовой лабы. И вычистил все лишнее.
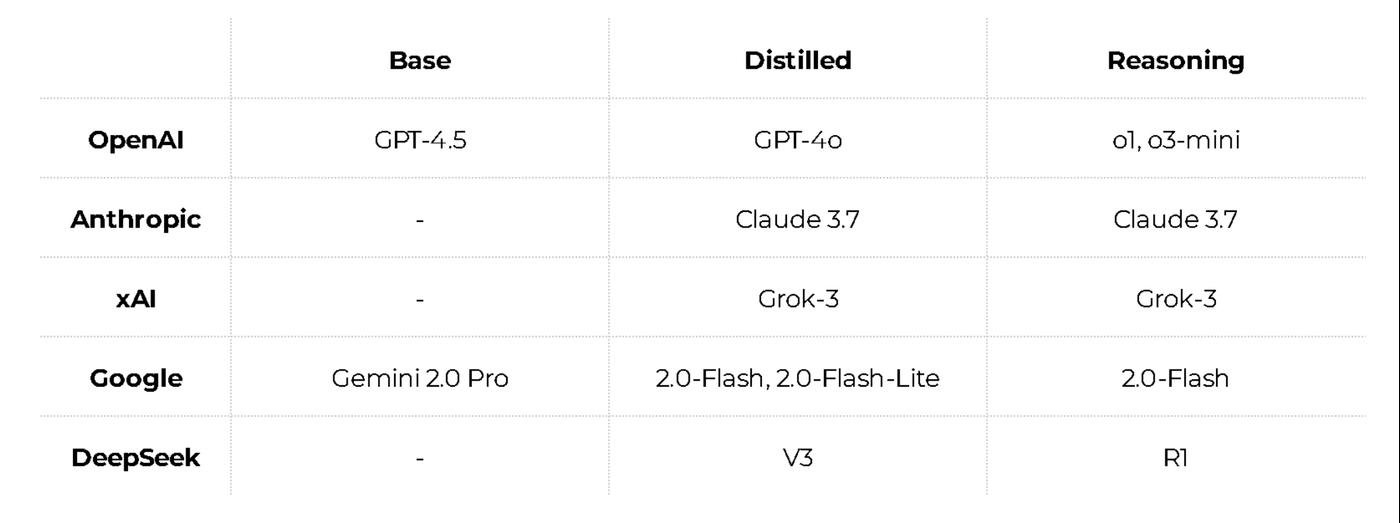
Есть огромные и мощные базовые модели. Они медленные и экономически невыгодные при массовом использовании.
Поэтому придумали дистилляцию: берём базовую модель, обучаем на её ответах более компактную модель, и получаем примерно те же способности, только быстрее и дешевле.
Это особенно важно на рассуждающих моделях. В последние полгода лучшие результаты показывают модели делающие перед ответом большое количество шагов рассуждения. Они составляют план решения задачи, выполняют его и проверяют результат на адекватность. На такие цепочки можно потратить в разы больше ресурсов. И.. это дорого.
Есть ещё специализированные модели: под поиск, супер-дешёвые для самых простых задач, или модели для узких сфер вроде медицины и юриспруденции. Ну и отдельная группа для картинок, видео и звука. Я всё это не стал добавлять, чтобы не путаться.
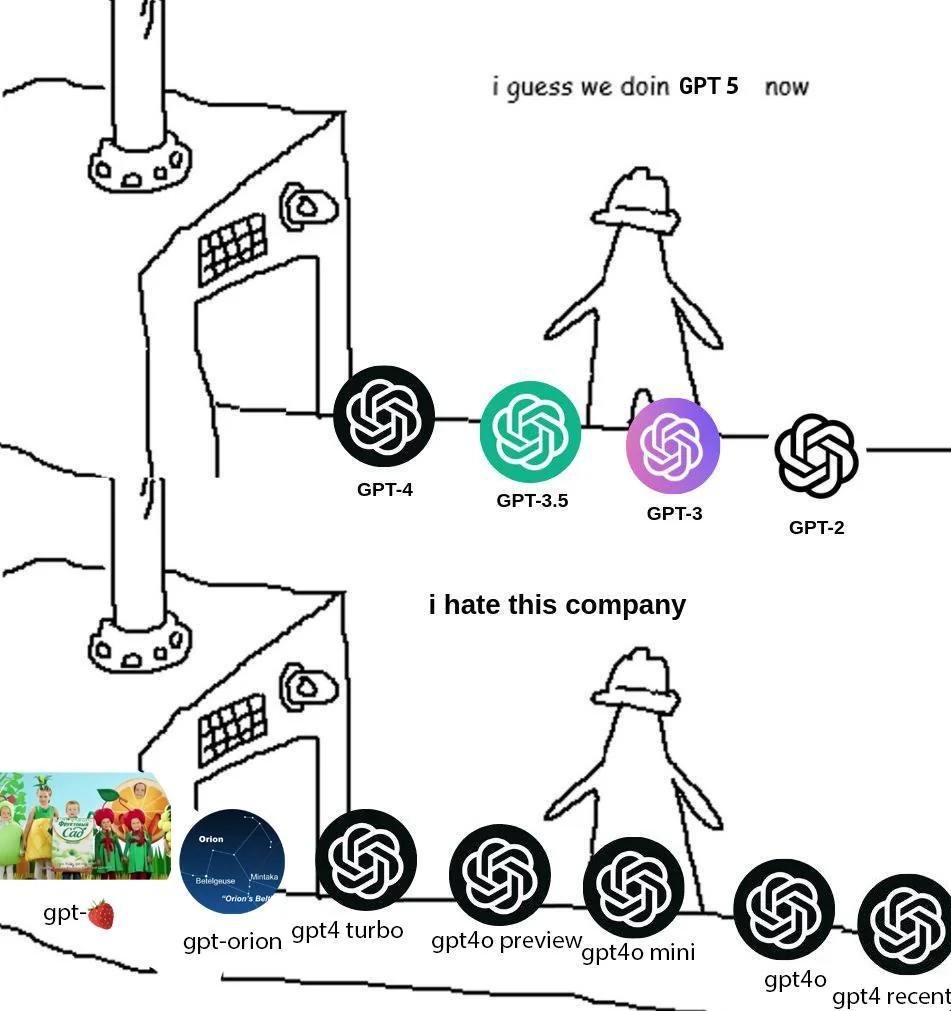
Все модели стали примерно одинаково хороши.
Настолько одинаково, что сложно понять, какая лучше. Андрей Карпати написал, что у нас кризис оценки моделей:
Сейчас есть несколько способов оценивать модели:
1 - Бенчмарки, которые измеряют что то одно конкретное и узконаправленное.
Например, умение писать код на питоне или уровень галлюцинаций в ответах. Но модели становятся умнее, осваивают всё больше задач, и одной метрикой их уровень уже не измеришь.
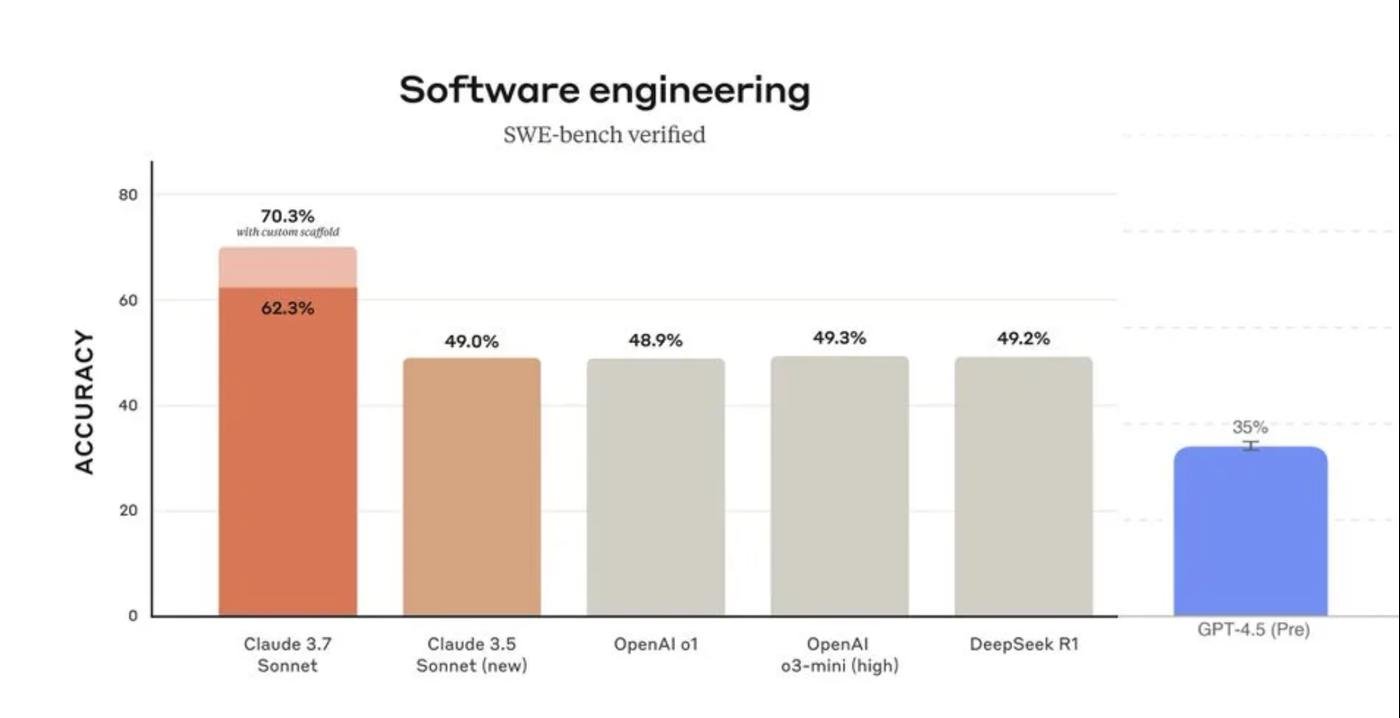
2 - Системные бенчмарки, которые пытаются кучей чиселок обсчитать модель с разных сторон.
Но когда начинаешь сравнивать кучу показателей, получается полный хаос. Одна модель лучше в одном, другая — в другом, и не понятно как это интрепретировать.
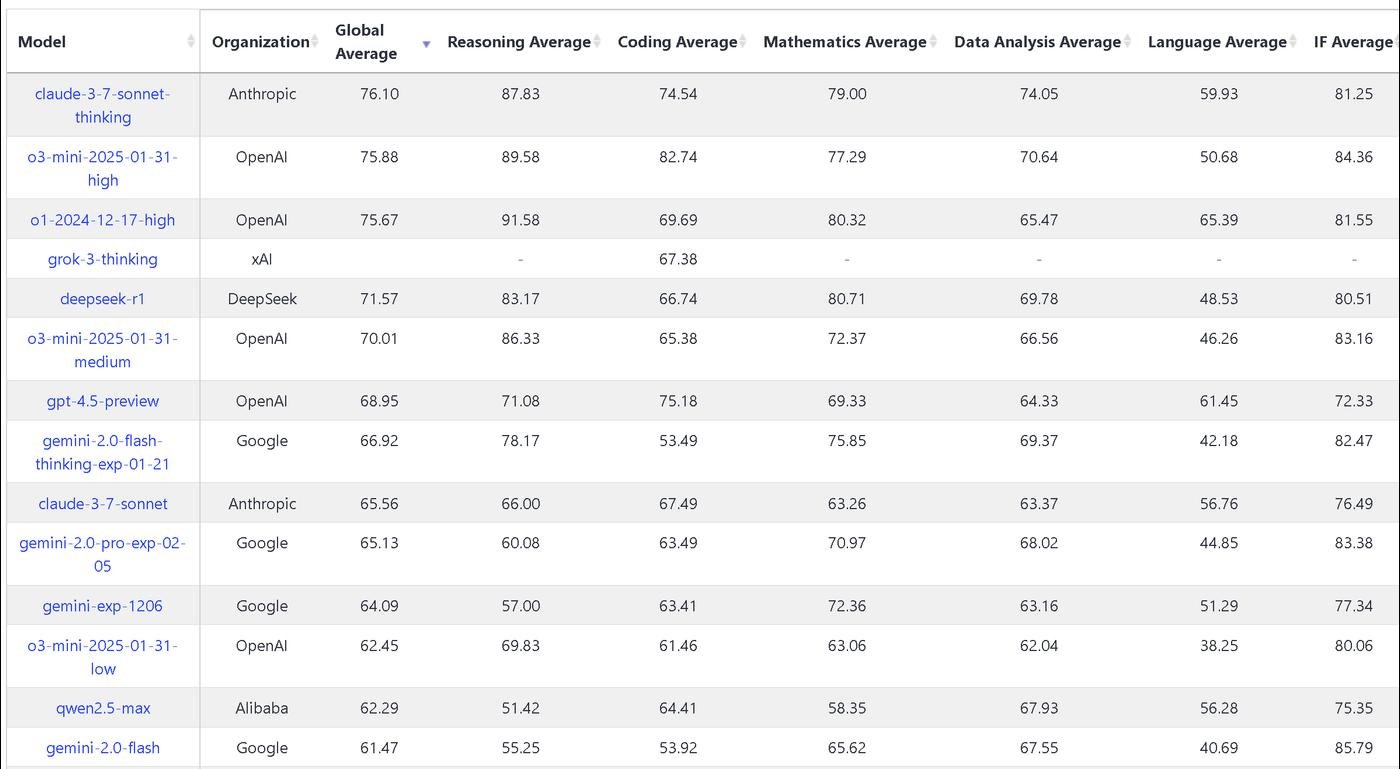
3 - Арена, где люди вслепую сравнивают ответы моделей по своим субьективным критериям.
И вместо непонятной кучи оценок, каждая модель получает ELO-рейтинг, как в шахматах. Чаще выигрываешь — выше эло. Но это было круто и удобно, пока модели не подобрались слишком близко друг к другу.
Разница в 35 ELO значит что у одной модели шанс дать ответ лучше 55%, а у другой 45%. Как и в шахматах, у игрока с меньшим ELO всегда есть шансы выиграть. Даже при разнице в 100 ELO треть ответов "худшей" модели будет лучше.
Ну то есть опять — одни задачи лучше решает одна модель, другие другая. Выбирай модель выше в списке и один из 10 твоих запросов будет получше. Какой и насколько лучше — хз.
А чё делать то?
Карпати предлагает за неимением лучшего полагаться на вайб-чек. Пробуешь на своих задачах и смотришь, норм или нет. Тут легко себя обмануть из-за предвзятости и всяких искажений. Но что поделать.
Мои советы такие:
- Открывать сразу несколько вкладок с разными моделями при каждой задаче и пробовать.
- Субьективно смотреть, за какой нейронкой мне нужно меньше переделывать.
- Не гоняться за цифрами. Намного важнее, чьи продуктовые фичи тебе реально нравятся и за какую подписку ты уже отдаешь долор.
- Если все таки хочется циферок, юзайте LifeBench. Авторы пишут, что он решает проблемы хакинга, устаревания, однобокости и субьективности.
- Если делаешь продукт на основе моделей, вот классный гайд от HuggingFace о том как собрать свой бенчмарк.
А пока, если вы ждали знак, чтобы попробовать что то кроме ChatGPT, то вот он:
https://claude.ai
https://gemini.google.com
https://grok.com
https://chat.deepseek.com
httрs://сhаt.openai.сom
Дальше я сделаю отдельный пост, где расскажу, что интересного у каждой модели и сделаю саммари вайб-чеков других людей.


Гайд по моделям ChatGPT
GPT-4o mini
Лучше не использовать. Самая слабая модель, придумывает ответы, не способна следовать сложным инструкциям.
GPT-4o
GPT-4o with scheduled tasks (beta)
Использую только для To Do:
o3-mini
✨ o3-mini-high
o1
o1 pro mode
Deep research
TL;DR
Для повседневных задач:
UPD:
Оригинал это от
Денис секси: https://t.me/denissexy/9499
Ожидание: Кроме чатгопоты есть айти
Ожидание 2: Кроме ЛЛМок и Гены Аи есть машинное обучение
Реальность:
Люблю полезные выводы из статей =)
А чтобы не регистрироваться и платить за каждый сервис отдельно, можно зарегистрироваться в OpenRouter, в котором есть все популярные модели по ценам производителя, и поднять LibreChat - форк интерфейса ChatGPT который поддерживает любые модели и работает локально. Плюс он дополнительно поддерживает несколько крутых функций которых нет в официальном ChatGPT и может использовать в том числе ваши локальные модели для sensitive запросов.
В список еще можно добавить https://chat.mistral.ai 🙂
У разных моделей, на самом деле есть разные кейсы в которых они очень круто справляются.
Но кажется, что обычному адекватному человек это не нужно, кто не работает с ними 8 часов в день.
Сейчас плачу за
Gemini (самый длинный контекст и Deep Research, который хуже OpenAI, но сильно выше лимит)
OpenAI (просто универсальная модель)
Anthropic (когда надо генерить код).
Иногда стал захаживать в Grok тоже за DeepResearch, когда у OpenAI и Gemini уже закончился лимит.
Из API дополнительно в проекта использую:
Gemini-2-flash - быстро, дешево и хорошо
Qwen-32b - очень дешево, очень быстро
Ещё поделюсь субъективизмом.
Давно мечтал задействоват LLM в рефакторинге кода.
Написать по аналогии, или добавть в гуишке пару кнопочек - это запросто.
А вот запилить крутую архитектуру, чтобы душа радовалась смотря на код - с этим плохо.
Как-то давно я делал попытки... но gpt4o была для этого совершенно бесполезна - она выдавала какую-то общую муть.
Но прошло вермя и появились думающие модели, и вот как-то подвернулся случай, и я решил протестить разные модели на одном и том же примере.
У меня есть ключик от OpenAI, недавно сделал ключик для DeepSeek.
Использую самописный GUI, который может закинуть сразу несколько файлов, а потом распарсить ответ и обновить файлы на диске:
https://vas3k.club/project/26935/
Так вот. Я ему закинул некий питоновский файл с некой моделью. Файл был целиком написан тем же GPT. Я конечно просил LLM группировать похожий код в отдельные методы и выносить что-то в отдельные классы, но всё-равно получился некий говнокодный монстр в одном файле.
Промпт был таким:
You are senior python developer. Here is my file: ..... Analyze the given code and identify areas that need refactoring. For each necessary change, provide a detailed explanation, including the class name and function name. Clearly describe the issue with the current implementation and propose an improved approach. Ensure that the explanation is specific and actionable, focusing on enhancing code readability, maintainability, and performance.Результаты тестирования
gpt4o Много воды, мало конкретики. На грани полезности
03-mini Очень неплохо - всё ещё размытые формулировки, но появляется хоть какая-то конкретика. И он нашёл реальный баг в моём коде!!!
deepseek-reasoner - самый чёткий. Он прямо показывает строчки кода, и часто даже пишет пример когда - как нужно это исправить чтобы было хорошо. Прям максимум конкретики!
o1 - тоже нашёл реальный баг. Вот это первая модель, которая меня реально впечатлила. Она написала мне на какие 4 класса я могу разбить свою модель, чтобы разделить разные сущности. И это прямо то, что я хотел!!!! Свершилось! (остальные модели ограничивались "у тебя слишком сложная функция попробуй её разбить на несколько частей"
gpt4.5 - выдала ту же самую вдумчивую разбивку на 4 класса. Вообще не упоминула о мелочах. Баг не нашла. Но как бы так сказать... это был прям ответ системного архитектора, который озвучивает тебе только архитектурные проблемы, а мелочи даже не считает нужным упоминать. Чуть больше советов системного уровня, чем 01
gemini 2.0 Flash Thinking - (тестировал через веб) - несмотря на свою бесплатность (даже через API) - лучше 03-mini и пожалуй наравне или может чуть лучше deepseek-reasoner ! Пойду прикручиват её в свой питоновский GUI.
P.S.
Не претендую на научность т.к. тестировал только по 1 разу и на одном запросе (а как известно, даже на один и тот же запрос повторённый 3 раза одна и та ж модель може выдать разные ответы).
P.P.S
O1 и тем более gpt4.5 прям game-changer в моей практике программироавния, но при их стоимости токенов с ними нужно быть очень осторожным, особенно если пихать в них большие файлы. Как-то 01 за 10 минут высадила у меня $5, и даже с третьей попытки так и не выдала мне требуемый результат...
Ещё, кстати, батхёрта добавляет тот факт, что использование LLM-чатика и использование API – это два разных продукта, за которые нужно платить по отдельности.
В последнее время, каждый раз, когда меня выбешивает Claude 3.7 (даже с рассуждениями), иду в Grok 3, и он раскладывает проблему и решает ее как божечка.
Сначала страдал что у него не удобный интерфейс в твиттере, а потом понял что есть grok.com и там гораздо удобнее, так что теперь если задача хоть чуток сложноватая или баг не сильно понятный или код от Claude попахивает пиздежом + оверинжинирингом - пользуюсь Гроком.
Спасибо за полезный пост!
А есть ли простой способ сделать локально доступный API для того же ChatGPT, чтобы он юзал подписку? В виде расширения для браузера или еще как?
я думала, что с моими задачами Клод лучше по большинству параметров. а потом я кастомизировала чат гопоты. и тут уже стало сложно. в итоге у меня их два, а на работе только Клод (потому что я его туда занесла х)
А ни у кого не было ощущения, что модели OpenAI целенаправленно тупеют?
Я раньше очень много пользовалcя gpt4o для написания кода (python, C#, C++) и прям это круто работало!
Певрвое ухудшение было в ноябре, когда openAI выпустила новую О1.
Может конечно так совпало, но старая gpt4o прям стала работать на удивление плохо - приходилось по 3 раза переформулировать запрос, чтобы добиться от неё того, что раньше она делала с 1 запроса.
(да, запросы разные, в лоб не сравнишь).
Второе ухудшение было недавно, когда вышли o3-mini и gpt-4.5.
Сейчас я вообще не могу пользоваться gpt4o - иногда проще самом написать код, чем добиться от неё того, что я хочу.
Всё субъективно, но сейчас пожалуй o3-mini - работает чуть лучше gpt4o начала 2024.
Может кто-то ещё такое замечал? Или это моё субъективное искажение реальности?
Спасибо за информацию, простенько и понятно.
интесно, а кто нибудь пытался делать обёртку над web версией chatgpt, что бы, дергать web api и не платить за токены?
В списке нейросетей в конце поста, кроме ChatGPT, на последнем месте - ChatGPT (https://chat.openai.com/) :)