


Когда ноутбуки стали быстрее серверов пятилетней давности, а браузеры научились исполнять WebAssembly почти как родной код, странно, что для анализа одного CSV всё ещё нужно ставить Postgres, DBeaver или хотя бы Jupyter. Это все хоть и утрированно (как и заголовок поста), но речь конечно же про большие файлы.
Зачем гонять данные туда-сюда, если можно дать браузеру делать то, на что он уже давно способен - локальный анализ? Без серверов. Без учёток. Без отправки данных «в облако». Просто открыть вкладку и написать SELECT * FROM my_file.
Когда тебе в сотый раз скидывают CSV «посмотри быстренько», а ты каждый раз думаешь: ну ладно, открою Jupyter, pandas, импортну файл или, того хуже, пойду импортировать в БД - что-то в тебе ломается.
Я захотел инструмент, который не требует установки, ничего не сохраняет в облако, не трогает мои данные, а просто работает. Как блокнот, только для SQL. Так у меня и моих друзей родился PondPilot - open-source SQL-песочница, которая работает прямо в браузере, полностью локально, без серверов и учёток.
TL;DR
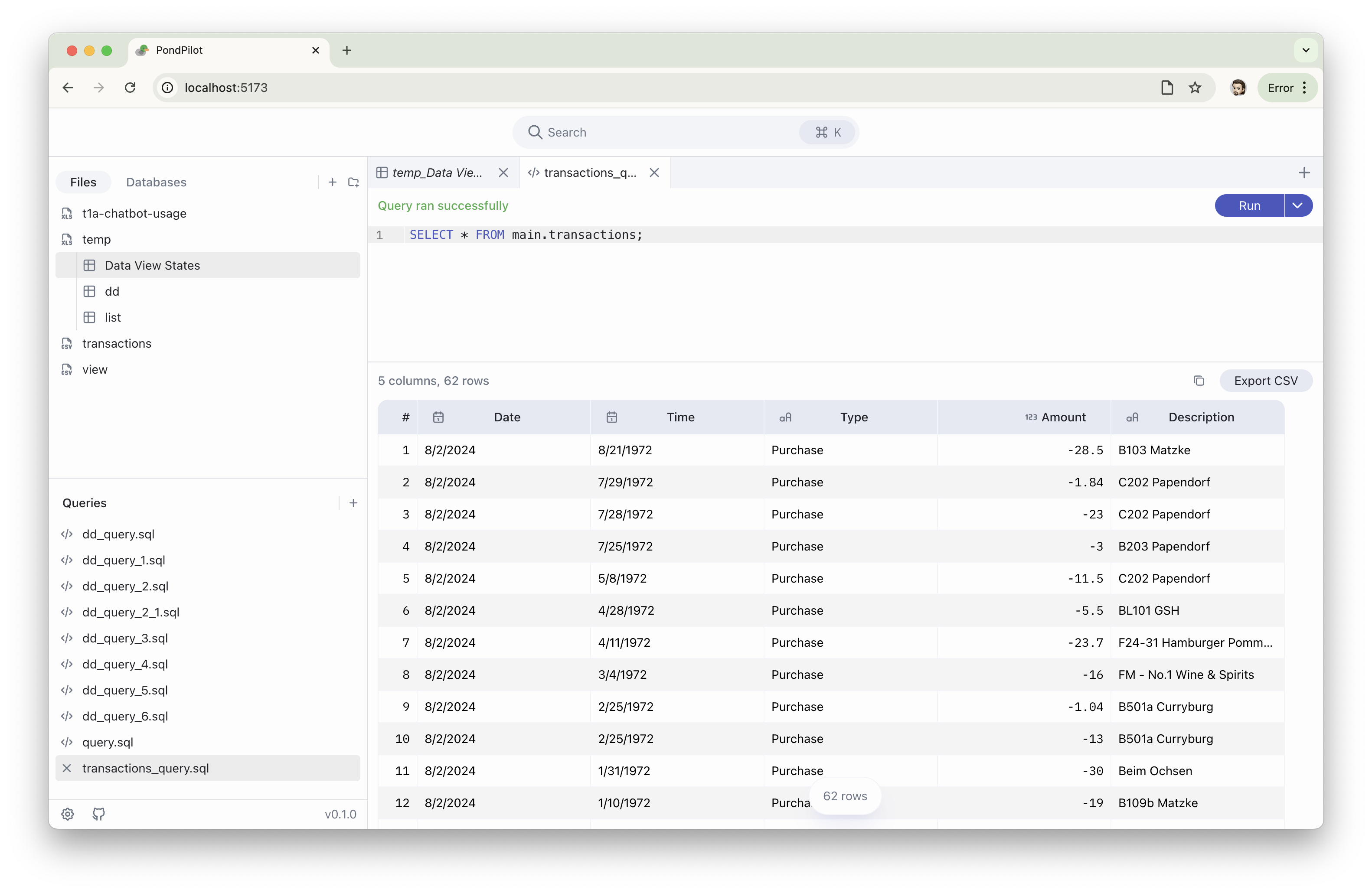
- PondPilot - SQL-редактор, работающий локально прямо в браузере
- Никакой регистрации, никакого бэкенда, всё остаётся у тебя
- Загружаешь CSV/XLSX/Parquet/JSON и сразу пишешь запросы
- Всё open-source: github
- Веб-апп: app.pondpilot.io
- БОНУС! Импортируешь лёгкую JavaScript библиотеку в свой блог и в одну строчку даешь интерактивный SQL-редактор пользователям, как здесь.
От боли к идее
Я занимаюсь аналитикой и продуктами, и мне постоянно приходится работать с локальными данными: экспорт из админки, выгрузка по запросу, какой-нибудь .parquet, который никто не может открыть.
Обычно workflow такой:
- файл скачал
- Jupyter запустил
pandas read_csv()- потом
query()илиdf[df.column == x] - потом забыл, закрыл, потерял
Мне надоело. Я хочу просто писать SQL. Без окружений и библиотек. Просто загрузил файл и сразу SELECT * FROM file LIMIT 10.
WASM + DuckDB = магия
В какой-то момент мы наткнулись на duckdb-wasm. Это была любовь с первого SELECT. DuckDB в браузере, локально.
Решено! Надо обернуть это во что-то.
PondPilot: как работает
- Загружаешь файлы drag-n-drop
- Видишь их схему в сайдбаре
- Пишешь SQL - получаешь результат
- Всё в вкладках, всё сохраняется в localStorage
- Можно открыть сессию и продолжить с того же места
Бонус: можно вставлять интерактивные SQL-блоки в HTML. Пример:
<pre class="pondpilot-snippet">
SELECT * FROM your_data;
</pre>
И он станет редактируемым SQL-виджетом. Можно прям в статьях или туториалах давать живой код, а не скриншоты. Вот тут видно, как это работает.
Note: сначала надо импортировать легкую библиотечку через <script src="https://unpkg.com/pondpilot-widget"></script>
Возможности PondPilot
- SQL-песочница с полноценной поддержкой SELECT/CTE/JOIN/AGG и т.д. - пишите и запускайте SQL-запросы к вашим файлам прямо в браузере — с подсветкой синтаксиса и базовой автодополнением.
- Загрузка файлов с локального диска и экспорт результатов в локальные файлы.
- Состояние рабочей среды сохраняется между сессиями браузера - продолжайте работу с того места, где остановились.
- Поддержка нескольких вкладок. Вкладки помнят своё состояние даже при перезагрузке страницы или переключении - как в полноценной IDE.
- Шаринг скриптов по ссылке. Делитесь SQL-скриптами с коллегами и сообществом через простую ссылку в один клик
- Автоматическое обновление данных. Если локальный файл изменился вне PondPilot, приложение обнаружит это и обновит данные, как полноценное десктоп-приложение.
- Работа с папками. Можно добавлять целые папки с файлами — они автоматически подгружаются в проект, ускоряя работу с множеством источников данных.
Мы не строим из этого SaaS. Это просто удобный инструмент для себя и таких же людей, которым лень настраивать всё ради пары запросов. Захотелось удобства, которое «просто работает». Делюсь:)
Что дальше?
- Генерация SQL через AI-хелпер (уже готово, тестируем)
- Автоматический расчет разных метрик/распределений/графиков, чтобы облегчить анализ данных
- Классный интерфейс для просмотра схемы БД
Всё это в бэклоге и скоро будет. Если есть еще идеи - welcome.
Все ссылки в одном месте
Наш лендинг: pondpilot.io
Веб-апп вот тут, а информация про виджет тут.
Исходники: github
Локально поднимается в пару строк:
docker run -d -p 4173:80 --name
pondpilot
ghcr.io/pondpilot/pondpilot:latest
и потом пользоваться приложением по адресу http://localhost:4173
Пробуйте, бейте, шерьте. Надеюсь, наша уточка сэкономит вам пару часов жизни:)
PS: если у вас есть идеи, с кем можно сделать коллаб по встраиванию нашего виджета - дайте знать, кажется, что учиться SQL должно стать приятнее.

З А Е Б И С Ь
А
Е
Б
И
С
Ь
Я время от времени работаю с CSV, всякие штуки типа "найти количество дубликатов", "посчитать сумму в такой-то колонке", "найти все значения в которых встречается такой-то паттерн" - не настолько часто, чтобы заморачиваться с обработкой их через python, но достаточно часто, чтобы заебаться импортировать это говно в эксель, возиться с кривым распознаванием дробной части в числах и ссаным "1.0001E+15".
Дай тебе бог здоровья!
Охуенная идея, однозначно лайк!
Было бы круто, если б была волшебная кнопка экспорта в гуглщиты. Я, да и думаю много кто еще, все равно без них не обойдусь, так как там удобно делать сводные таблички/нарисовать простые графики/пошарить результаты.
Выглядит очень круто!
Единственное, не очень понимаю, почему бы не использовать условный sqlite, если юзкейс "хочу кинуть файл и написать селект". sqlite создает табличку из цсв в два клика и уже можно фигачить селекты.
Пива за счет заведения этому пупсику!
интересно, что numbers установлен на каждом маке и отлично открывает csv
Выглядит интересно. Было бы классно иметь auto complete для имён столбцов, когда пишешь скрипт. Ну или я его не нашёл.
Вау! то, что всегда хотел сделать и мучался. Когда эксели и гугл доки не под рукой, а статистику по логам хочется посмотреть.
После 10 минут использования мои фич реквесты:
Правда очень круто сделано! прямо приятно курсором тыкать
Какая офигенная штука!
Фича реквест тоже)))
вот есть скажем json файл в котором объект с одной или несколькими таблицами, ну например
{
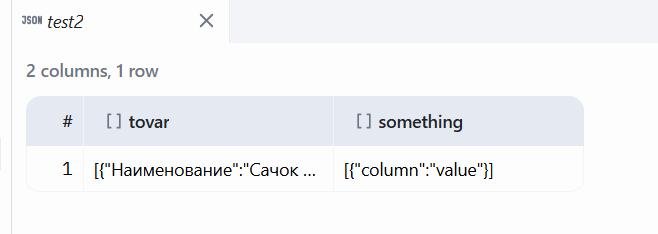
"tovar": [
{
"Наименование": "Сачок с плоской сеткой Bestway 40х34 под ручку30мм",
"НоменклатураКод": "80609",
"Артикул": "58659 BW",
"ЕдиницаИзмерения": "шт",
"Производитель": "",
"Количество": "15",
"Цена": "2 100",
"ЗначениеСкидкиНаценки": "5",
"ЦенаСУчетомСкидкиНаценки": "1 995",
"Склад": "Склад Огородная",
"ВидЦен": "Розничная цена",
"ГруппаНоменклатуры": "INTEX (БАССЕЙНЫ И КОМПЛЕКТУЮЩИЕ)"
},
... и тд
]
}
его импортирует как то так
можно добавить опцию ну скажем реимпортировать таблицу из ячейки, чтобы каждый список внутри можно было открыть?
Классная идея! А не тестировал на каком объеме строк браузер умирает?
Пишу ещё не опробовав, на эмоциях.
Ох ты, какая мякотка!
Долгое время сидел на clickhouse-local (habr ). Потом на csvtool + grep/awk. Но консоль не даёт наглядности (визуальной обратной связи), многие простые действия приходится делать в несколько приёмов.
Ух ты, звучит классно! Надо попробовать в работе, а то иногда прям неимоверно лень ковыряться из-за одного-двух-трех запросов.
Огонь! Не хватает только возможности отредактировать схему/конфигурацию парсинга полей из CSV.
К примеру, у меня в некоторых CSV-шках значение записано вместе с значком валюты, и по идее его бы проигнорировать и воспринимать как число, но оно отображается как varchar, в итоге операции сложения не проделаешь. :(
Очень круто, спасибо большое!
Фича-реквест:
Было бы здорово экспортировать результат не только в csv, но и в новую таблицу. Либо сделать возможность использования результата из другой вкладки.
у меня одного из РФ не стало открываться без ВПН? это баг или фича?