
Думаю что многие видели знаменитый пост Никиты @tonsky и чувствуют схожее разочарование и сожаление.
Я не профессионал в области разработки приложений или компьютерных наук и не оспариваю тезисы изложенные в статье.
Однако мне бы хотелось рассказать о позитивном примере последовательного прогресса в целой софтверной отрасли.
Существует такая область математики как Operations Research (OR) - по степени хайпа как машинное обучение, но для эпохи 70ых. Задачи, которые там возникают имеют прямую связь с реальностью и экономической деятельностью - линейная оптимизация для оптимального портфолио акций, оптимальное размещение фабрик, роутинг и куча других приложений вики . Когда на собеседованиях вам предлагают вертеть деревья найти сколько кирпичей можно положить в рюкзак (knapsack problem) вы тоже решаете классическую проблему из OR - Mixed-Integer Programming.
В суровом энтерпрайзе (нефтяники, судоходство, банки) для решения таких задач на практике используют специальные пакеты, еще их называют солверы, чаще всего коммерческие (IBM Cplex, Gurobi). Речь в этом посте будет идти именно про этих ребят. Основная функция таких программ такова: Дана задача текстом или через API в определенной форме (что-то вроде SQL), программа как черный ящик считает наилучшее решение удовлетворяющее условиям и выводит значения параметров которые ему соответствуют. Надо учитывать что реальные задачи могут быть очень большими и считаются небыстро.

Первая версия Cplex была выпущена в 1988 году, самая новая версия 12.10 выпущена в декабре 2019 года. Gurobi 1.0 был создан в 2008 году лидерами проекта Cplex, последняя версия на текущий момент - 9.0 вышедшая в марте 2020 года. Как вы видите оба пакета активно разрабатываются и дополняются. Можно было бы подумать, что неизбежно превращение в Nero Burning Rome или редизайн в стиле реддита, но нет!
Дальше по тексту будут кусочки слайдов из лекции основателя Gurobi Роберта Биксби
Линейное программирование. Одна из самых частых задачек, "рабочая лошадка" оптимизации. Биксби решил проверить как на одинаковом компьютере будет работать самая первая версия CPLEX 1988 года и версия от 2003 года. Скромные 43.5 тысячи раз ускорения, вместо 1 месяца ожидания - 1 минута. Стоит учитывать что самая первая версия не была написана сортировкой "пузырьком" школьниками.

Линейное программирование в каком-то смысле считалось "решенной", "неинтересной" задачей. Понятно как считать, понятно, что можно справиться, вопрос только во времени и постановке самой задаче. С задачами комбинаторной оптимизации такой уверенности не было и нет по сей день. Но и тут нашлось место для скорости.
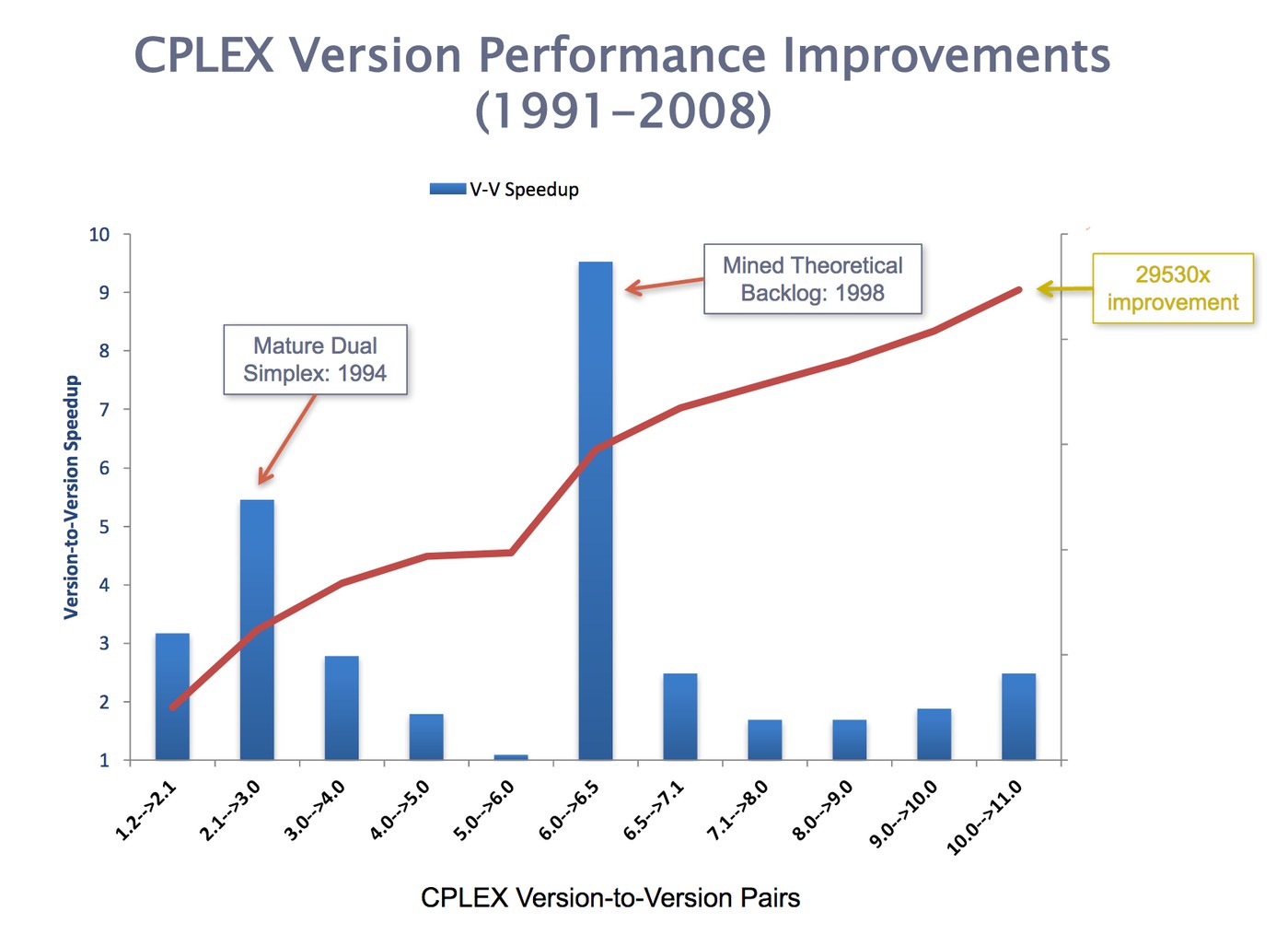
С 1991 года по 2008 кумулятивный прирост в скорости не связанный с железом составляет 29.5 тысяч раз. Версия 2008 года более или менее эквивалентна версии Gurobi 1.0
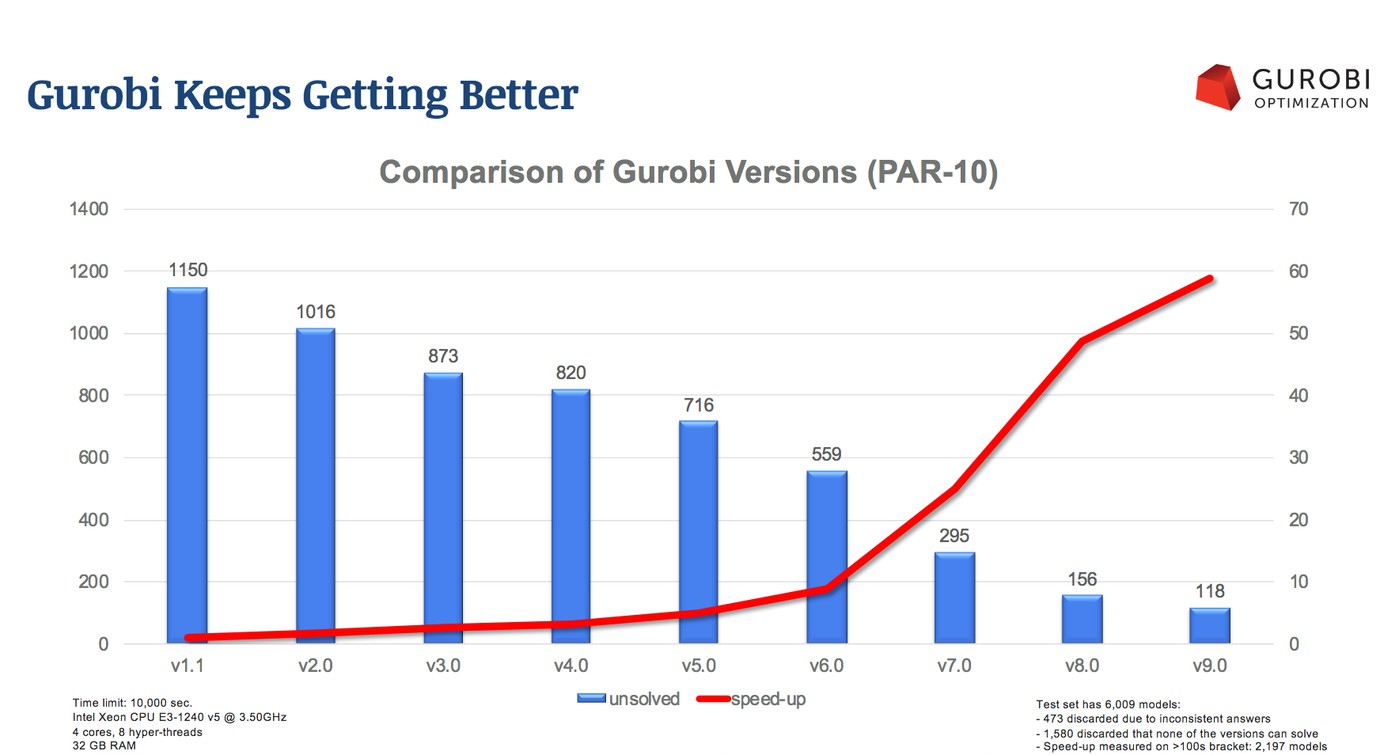
С версии Gurobi 1.0 немало воды утекло, для версии 7.0 вышедшей в 2016 году посчитали дополнительное ускорение.
По сравнению с 2008 годом добавили еще всяких плюшек и получили 43 кратное ускорение. Если посчитаем кумулятивный эффект получим что-то в районе миллиона раз быстрее. Задумайтесь, какие еще программы стали работать в миллион раз быстрее?

Такие оптимизации открывают путь к новому осмыслению ряда классических задач. Например многим известен метод Decision Trees. Считается что нельзя взять и посчитать оптимальные разбиения данных в лоб, нужны какие-то эвристики, всякое такое C4.5 кхекхе. Ну вот оказывается если ваш MIP солвер становится намного быстрее, то можно взять и посчитать глобально наилучшие ветки решающего дерева и не париться - Optimal Classification Trees
Что интересно микросервисы, кубернетесы и прочий AI пока не вмешивается в естественный ход вещей и пакеты продолжают ускоряться. Несмотря ни на что, несмотря ни на кого.
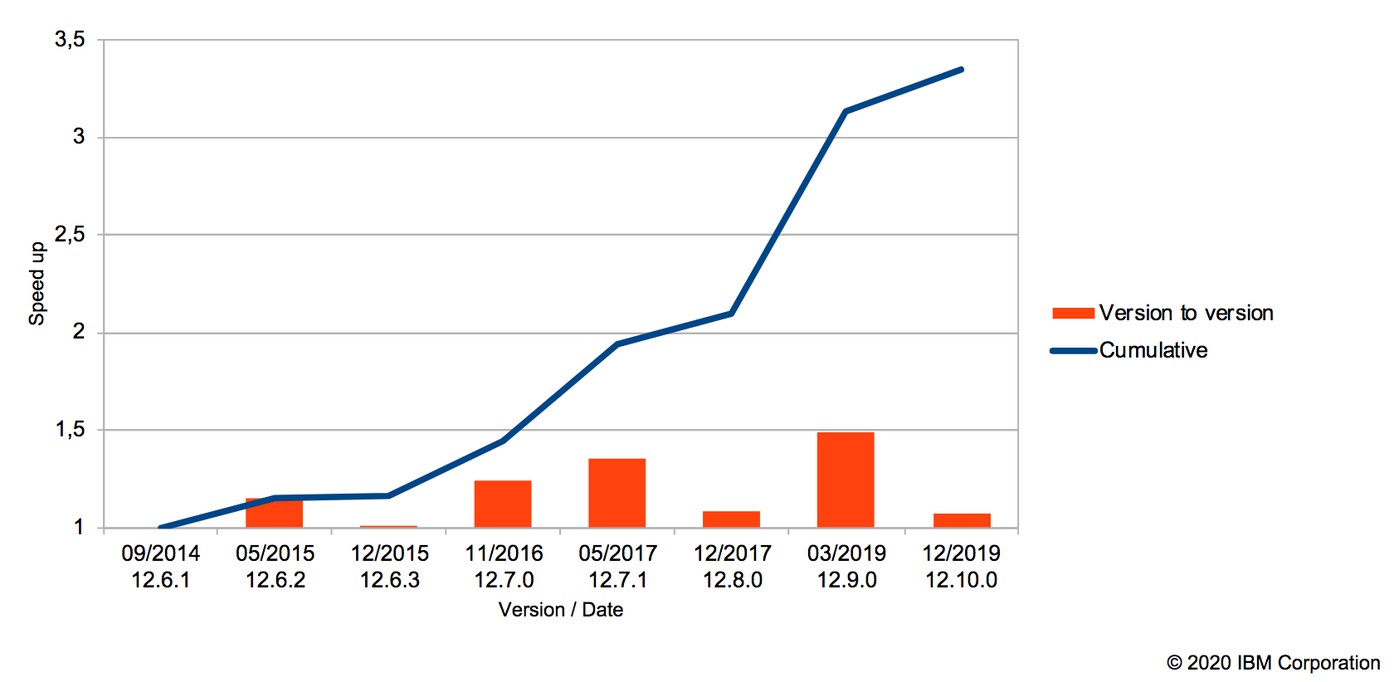
Вообще Operations Research удивительно интересная дисциплина с богатой историей советской школы математики. Надеюсь этот пример окажется интересным для вас и вы получите заряд оптимизма. Пишите в комментариях про другие примеры ускорений и софтверного прогресса.
Мы у себя тоже такое используем с недавнего времени, правда, опенсурсное: https://www.minizinc.org/ + https://github.com/Gecode/gecode.
Одна модель на 70 строк заменила ±700 строк самописного MIP-алгоритма. Скоро, может быть, напишем про это в блог.
Самое интересное и сложное это перестроить мозги с императивной модели на декларативную. Плюсом ты получаешь лучшее понимание проблемы и ограничений и описанная таким образом задача читается понятнее (по модулю странного синтаксиса MiniZinc), чем ±700 строк ad-hoc Go кода.
Если кому интересно, на Coursera есть очень хороший курс, судя по отзывам коллег (у самого в списке "когда-нибудь пройти"): https://www.coursera.org/learn/basic-modeling
Насколько я понимаю, солверы становятся быстре во многом за счет эвристик, разве нет? (статью не читал)
А OS реально сильно проигрывают?
Мне дико нравится с SMT солверами. Насколько я понимаю, современный алгоритм CDCL появился только в 90-х. И сейчас, там явно идет развитие скорости солверов, судя по тому, что я видел совсем свежие статьи на эту тему. Хотя казалось бы совершенно обычные алгоритмы, никакого машин лернинга.
И у них есть новые приложения. Насколько я понимаю, их всю дорогу использовали для верификации программ, но сейчас это начинает становиться доступным обычным людям.
Например refinement types, позволяют создавать типы с инвариантами, которые солвер проверит. По сути подмножество зависимых типов, где руками доказывать не нужно. Примеры: Liquid Haskell и F*.
Аналогично, можно не динамически, а статически проверять контракты. В Solidity это уже встроенно в компилятор в качестве эксперементальной опции. И я реально использовал это для написания продакшн контракта, и оно сходу работало и находило ошибки. Правда в итоге перешел на фаззер по соображением юзабилити.
Говоря о фаззерах, я так понимаю, что с ними тоже прогресс, судя по тому, что те их применения что я встречал, достаточно недавние. Но тут я меньше изучал вопрос, может сейчас просто модно стало.
Не совсем в статью, тут всё-таки про целую область вычислений)
Но пару лет назад наткнулся на игру Mekorama (Android).
Это полноценная и интересная 3D-головоломка, которая «весит» всего 5 МБ!
После разных коротеньких 0платформеров, весящих по 150 МБ, обновления Youtube на 300 МБ, это было прям приятное удивление.
Было приятно узнать, что автор напрягся и написал игру без Unity и вот-этого-всего и хорошо её оптимизировал =)