
Каждой весной в МФТИ проходит масштабное празднование "Дней Физика" и одно из главных событий — большой Open Air. На нём традиционно выступают местные группы и несколько приглашенных гостей.

Вот, например, Noize MC в далёком 2017м
В январе 2020го мы начали выбирать хедлайнера для очередного концерта, но, к сожалению, денег на то, чтобы просто "позвать кого-нибудь популярного" особо не было. Мы понимали, что нужно действовать умнее, и как настоящие технари не могли не обмазаться ОБЪЕКТИВНЫМИ МЕТРИКАМИ и ЧЁТКИМИ ФАКТАМИ.
Логика простая — наш идеальный кандидат должен был быть не очень популярен среди широкой общественности, но хорошо известен среди физтехов. Такой исполнитель мог бы поместиться в наш бюджет, и при этом порадовать многих фанатов на нашем мини-фестивале.
Размышляя об этом и перебирая различные группы, мы пришли к простой идее — можно просто взять какой-нибудь физтеховский паблик вконтакте, страничку исполнителя и посчитать для них число общих подписчиков.
Через пару часов активного дата-майнинга мы получили первые пробные результаты для официального сообщества ВУЗа и главного мемного паблика.
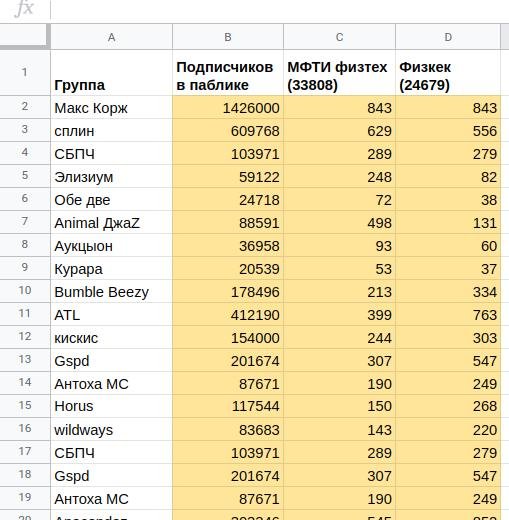
Если начать искать тайные смыслы в этих цифрах, можно даже заметить разницу между пабликом, в котором много сотрудников и выпускников постарше, и сообществом студентов-зумеров.
Как и ожидалось, у больших групп пересечение оказалось большим, а у маленьких — не очень. Но всегда можно просто нормировать размер пересечения на размер группы и получить долю физтехов среди подписчиков группы. После такой операции, студенческие группы и местные коллективы из Долгопрудного предсказуемо оказались наверху, а гиганты эстрады отошли на второй план.
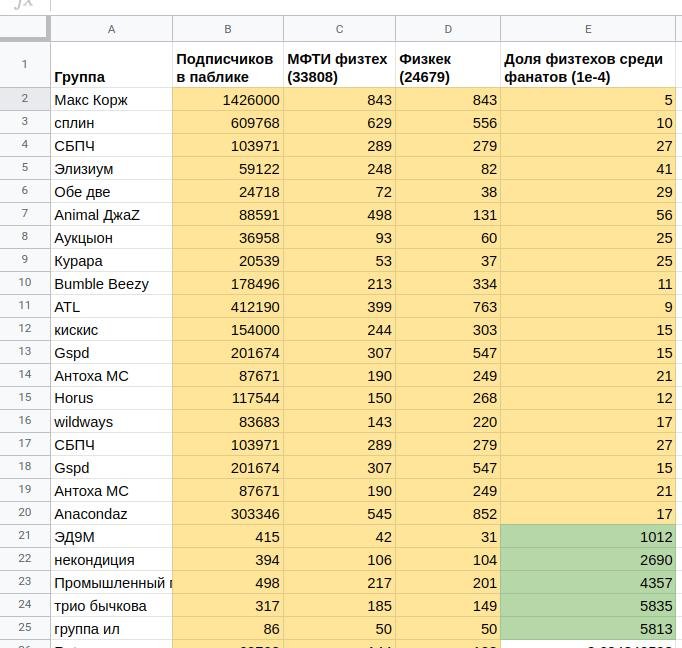
Не в силах совладать с таким количеством цифр, мы начали их визуализировать.
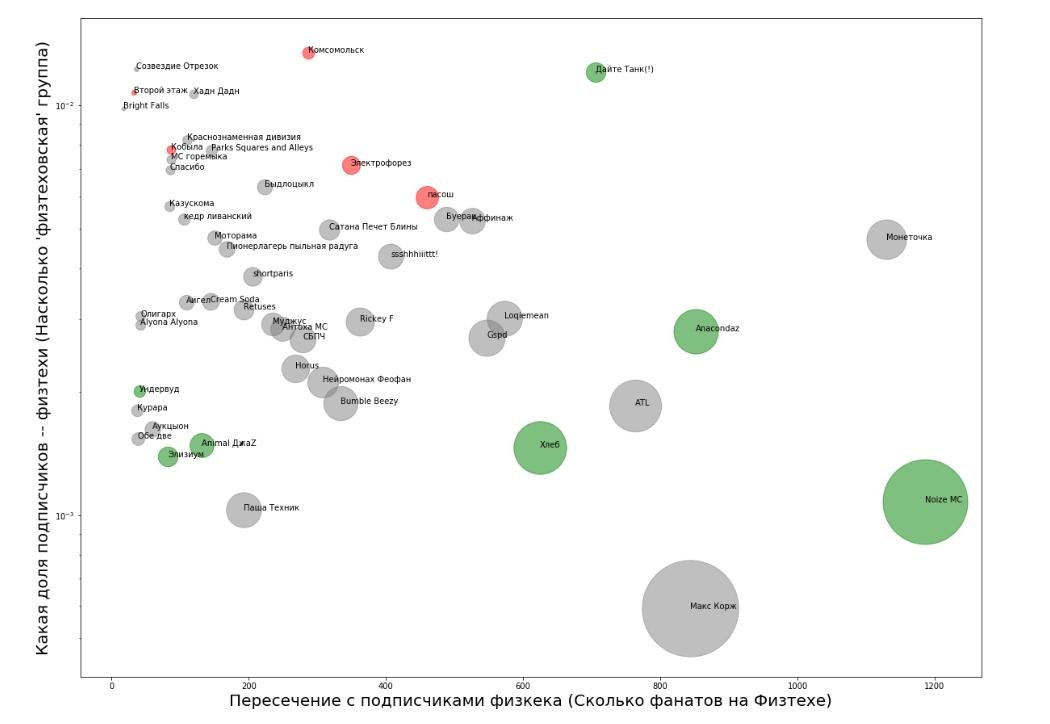
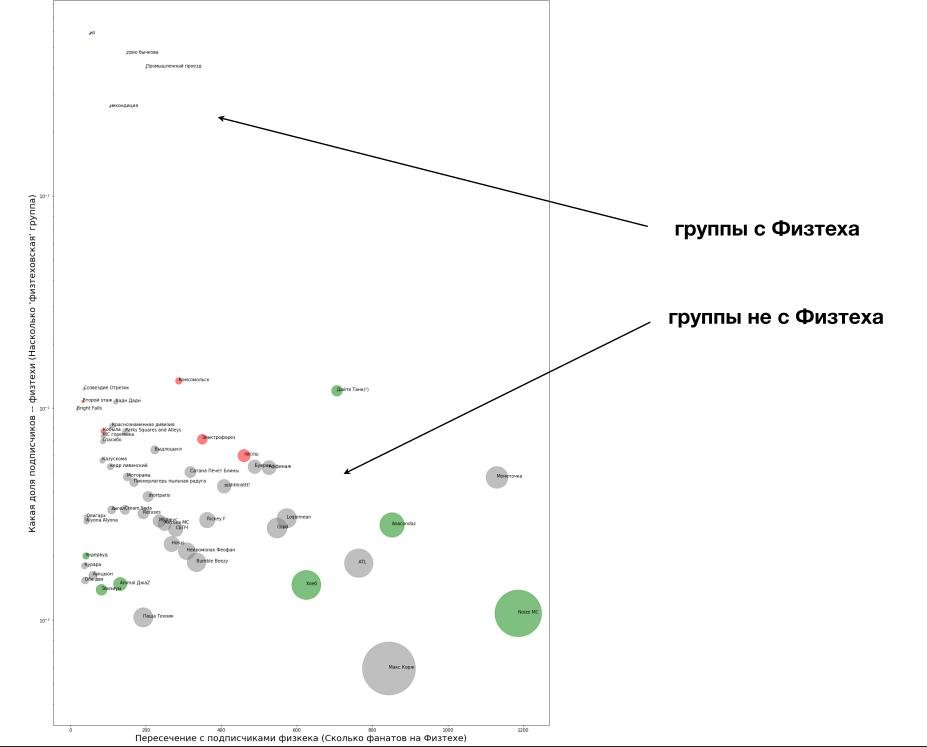
Каждому кругу соответствует одна группа. Размер круга — общее число подписчиков. Положение по горизонтали показывает много ли у группы фанатов в МФТИ, по вертикали — популярность, нормированную на размер группы. Зелёным помечены группы, уже выступавшие в прошлые года. Красным — группы, которые планировали позвать в этом.
Быстро взглянув на диаграмму, можно сразу найти ИНСАЙТЫ
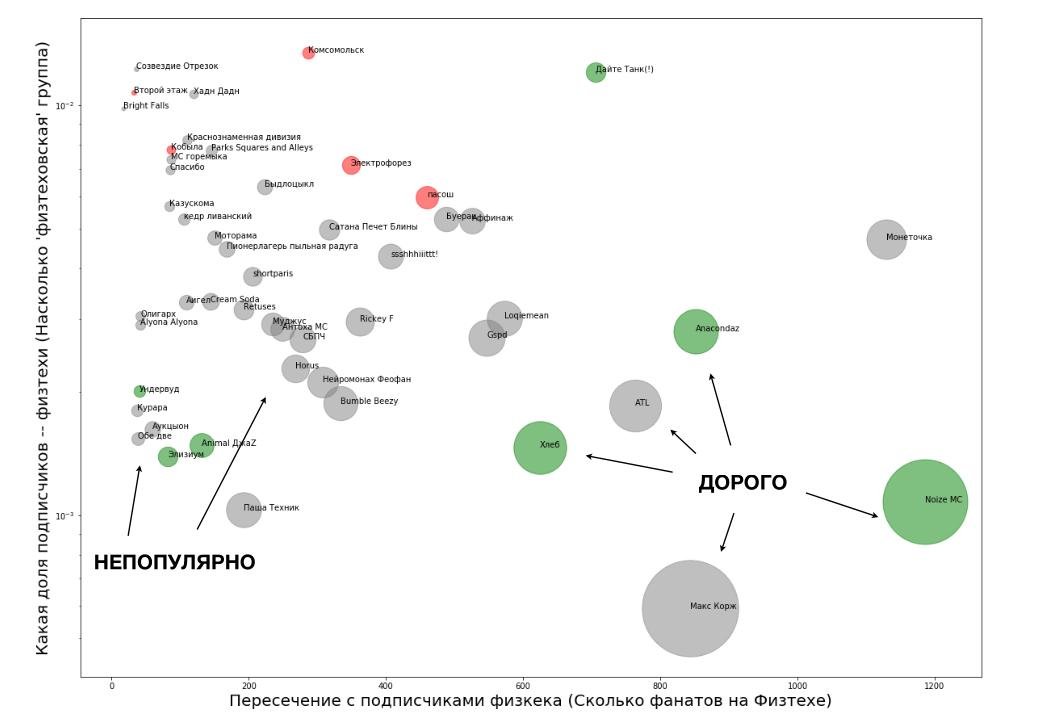
Сразу понятно, что чем правее группа на графике, тем лучше. Однако, при движении вправо быстро растёт общая популярность групп, а значит, скорее всего, и их гонорар. Но в верхней чаcти графика можно найти небольшие группы, которые, в целом, нравятся студентам. (Звать маленькие группы, которые никому не нравятся, было бы совсем странно))).
Если добавить на график местные группы, принцип становится ещё более ясным.
Конечно, полностью полагаться на такие расчёты нельзя, и на наш финальный выбор повлияла ещё целая куча факторов. А потом стало понятно, что большого концерта уже точно не будет, и всё поменялось ещё несколько раз. Но подобные исследования помогли понять общую картину и отсеять очевидно плохие варианты. К тому же, графики и таблицы прекрасно действовали на спонсоров и всевозможное начальство, которому мы должны были пояснять свои решения. Сразу видно что тут серьезные дела, не что попало.
В итоге большая часть музыкантов сыграла в импровизированной домашней студии, а кто-то у себя из дома. Получилось вполне хорошо и лампово. (Мне особенно понравилось джазовое Трио Алексея Бычкова и электронный сет от группы ил, но там все было довольно круто, можно посмотреть в группе)
Наверное, похожими методами можно сравнить музыкальные вкусы студентов разных московских вузов или вообще кластеризовать и визуализировать всю российскую музыкальную сцену. Но, оказывается, даже небольшими усилиями можно получить полезные и неочевидные закономерности из данных, валяющихся под ногами и просто интересно провести вечер, залипая в цифры.


Визуализация - круть.
Если ещё и сразу обрезать по параметрам "денег не хватит, слишком круты" и "этих не имеет смысла, т.к. не выгодно, людей не соберём". Останется вообще узкая выборка, класс.
А вот парсинг и вычисления - не проще было парсером(ТаргетХантер, например) это всё собрать и пересечения собрать? Или довольно быстро скрипты написал?
Я о соотношении "трудозатраты на эксперимент" к "результату".
Или это больше по фану, когда время на код не жалко?