

Привет.
Несколько лет назад я написал сервис vocabular.io. Ключевые фичи сервиса:
- строит частотный словарь текста
- хранит личный словарь пользователя
- считает статистику по словарям
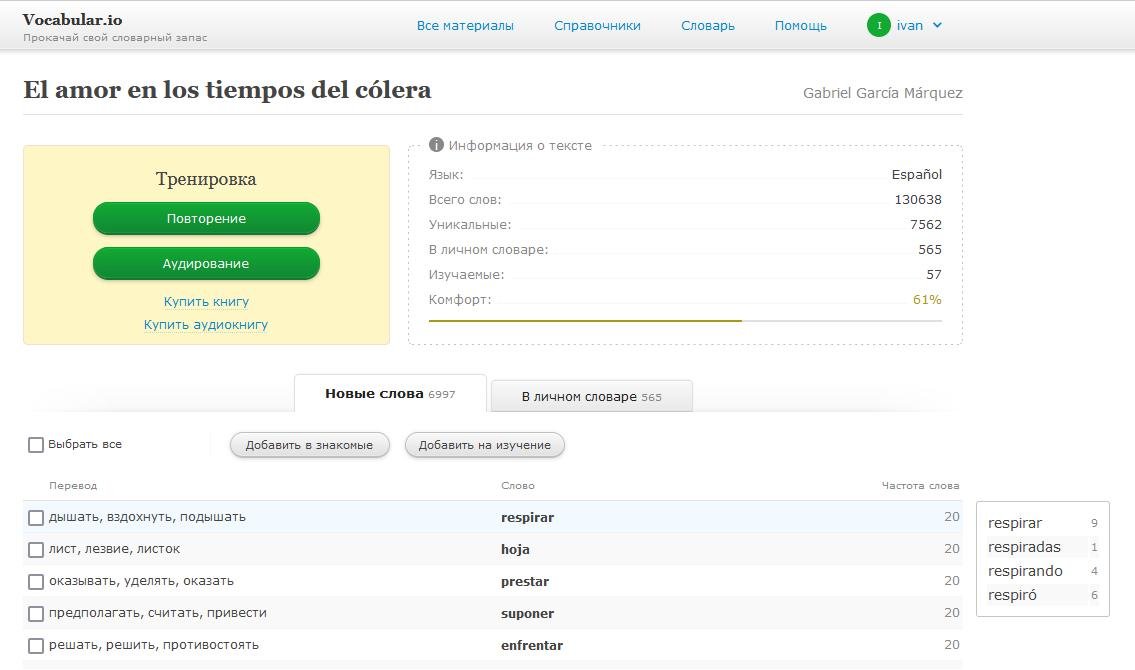
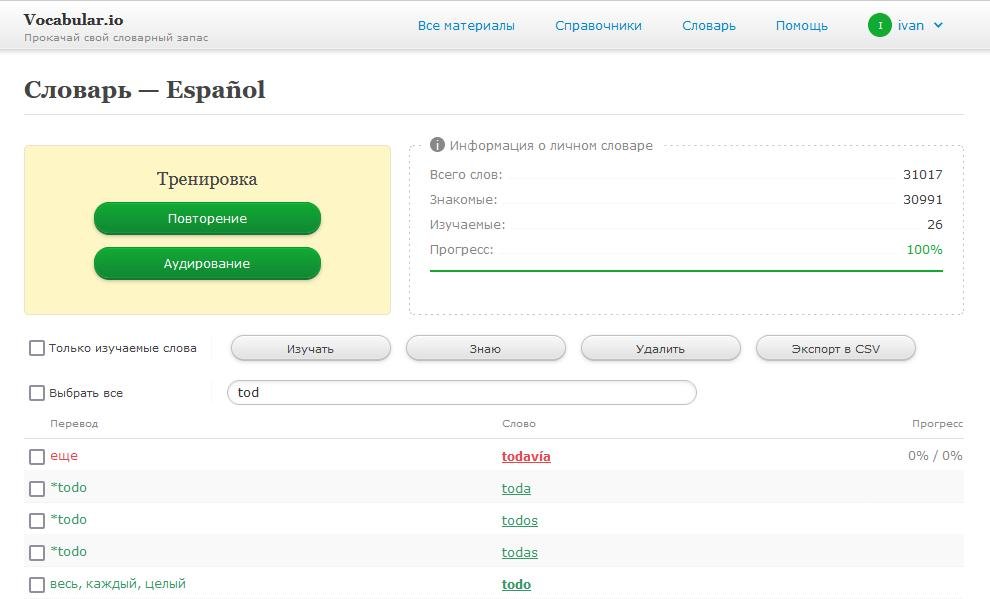
Сейчас есть возможность загрузить тексты на английском или испанском языках. Поддерживаемые форматы файлов: txt, srt, pdf, epub. Есть встроенный тренажер для запоминания слов. Для тех, кто хочет погонять слова, например, в anki, есть экспорт в csv.
Ниже немного из истории проекта.
Идея
Я люблю читать книги. Беда в том, что нередко книги не переводятся на русский язык, а если переводятся, то с задержкой в год+ после релиза в оригинале. В определенный момент у меня накопилось несколько таких книг и появилось сильное желание их прочитать. Но читать книгу, заглядывая в словарь для почти каждого слова,- такое себе занятие. Так в 2015 году возникла идея сервиса.
Началось все с того, что я решил набросать скрипт, который разобьет текст по пробелам и построит частотный словарь. Сделал, попробовал, и тут началось)
Сразу обнаружил ряд неудобств:
- Большую часть top слов я уже знаю, но среди них иногда проскакивают незнакомые, поэтому просто отсекать top 1000/2000/3000+ для каждой книги - не совсем корректно. Нужна возможность хранения уже отсмотренных слов, чтобы для нового текста не было необходимости обрабатывать их заново.
- Одно и то же слово может повторяться в списке в разных формах (например, begin и begins). Во-первых, нет желания обрабатывать одно и то же слово несколько раз, во-вторых, не совсем честно считать для них частоту по отдельности, т.к. слово, по сути дела, одно.
- В языках есть устойчивые выражения и фразы. В английском, например, очень распространены фразовые глаголы, поэтому в случае give up правильней считать частоту для всего глагола, а не для give и up по отдельности.
Сперва я хотел сделать небольшие утилитки, которые решали бы указанные проблемы, но затем подумал, что такой инструмент мог бы быть интересным для кого-то еще, и имеет смысл сделать online версию.
Реализация
Первым делом я продумал как пользователь будет взаимодействовать с сервисом (тут главной задачей было поставить себя на место другого человека и сделать сервис удобным для большего числа людей, а не только для себя). После этого отдал макеты другу, и он сделал дизайн в webflow. Затем начался долгий этап разработки. Долгий, потому что в какой-то момент проект был заброшен почти на год из-за нехватки свободного времени.
В 2015 году у меня был опыт в основном в Java мире и хотелось использовать уже имеющиеся знания. В то время Grails выглядел как хороший инструмент для быстрой разработки на Java стэке. На нем, собственно, и была реализована первая версия сервиса, но некоторые время назад у меня выкроилось немного свободного времени и я переписал все на Kotlin + Spring Boot + Postgres + React.
Инфраструктура:
- собирается и запускается руками в Docker на DigitalOcean
- CloudFlare
- AWS CloudFront в качестве CDN для отдачи озвучки слов
Весь основной код лежит в открытом доступе:
https://github.com/vanzay/wiktionary-utils
https://github.com/vanzay/text-analyser
https://github.com/vanzay/vocabulario-utils
https://github.com/vanzay/vocabulario-api
https://github.com/vanzay/vocabulario-frontend
Трудности
Одной из основных задач, которые я поставил перед началом реализации: не использовать NLP-библиотеки, заточенные на какой-то конкретный язык, даже если эти библиотеки дают хорошие результаты. Я хотел сделать решение, которое можно было бы использовать для любых (или большинства) языков, чтобы при добавлении нового языка не было необходимости делать новые исследования и сильно дорабатывать ядро системы. В результате решил строить индекс слов для языка и с помощью этого индекса обрабатывать тексты. Возник вопрос: где взять хороший словарь для разных языков (желательно бесплатный или не очень дорогой)? После ресерча самым оптимальным решением оказалось использовать wiktionary.org, для парсинга которого было написано несколько утилит.
Следующей проблемой было достать где-то переводы слов. В качестве решения был написан скрипт, выгружающий переводы из Google translate (пришлось поразбираться с обходом защиты, т.к. прямые запросы блокировались гуглом). Для связки английский-русский гугл работает сносно, но для языков, отличных от английского, качество сильно падает. Поэтому для испанского я сделал выгрузку уже из reverso.net.
Еще одной проблемой было взять где-то озвучку слов. В итоге, часть слов была выгружена с forvo.com, а то, что там отсутствовало, было синтезировано штатным TTS в Windows, который был выбран из-за простоты и доступности, хотя качество сгенерированного аудио оставляет желать лучшего.
Outro
Сейчас зарегистрированных пользователей меньше сотни за все время, т.к. я особо сервис никак не продвигал. Из финансовых расходов только оплата DigitalOcean. Монетизации нет.
Есть ряд известных багов, список улучшений, но пока сервис никак особо не развиваю, хотя продолжаю держать его в рабочем состоянии.

Очень крутая идея! Я учу испанский (с английского) и мне пару месяцев назад как раз очень хотелось что-то похожее найти, но еще запаренное на правильные интервалы для повторения слов. Пока нашла lingvist.com и уже пару месяцев плачу им по 10 баксов (FYI про монетизацию :).
Несколько рандомных мыслей:
В vocabular интерфейс мне было очень тяжело и не понятно, долго тыкала кнопки, поковыряла даже код немного (когда кнопка не работала). В общем я оч мотивированный юзер, книжку загрузила, слова выгрузила. Пока не тестила насколько легче читать, если это слова заранее учить (в лингвисте я учу 5000 самых частых слов, хоть он тоже умеет custom decks из текстов).
Посмотрела еще в интерфейс про учить карточки - у меня не подгрузились переводы. И мне было бы неудобно что в словах мне заранее говорят сколько букв (лишняя подсказка). И вообще приложений про учить слова много хороших, мне кажется лучше сфокусироваться на процессинге текстов и выгрузке в другие приложения.
В общем надеюсь что-то полезное :)
Крутая фича была бы: выгрузить слова для изучения в Anki карточки (или в csv файл). Они специализируются на spaced repetition, там внутри много логики для долгосрочного запоминания
Блин, шикарная идея. Мне очень актуально. Мне кажется, стоит развивать, прикрутить монетизацию и дело пойдёт. Ну и на Product Hunt попробовать запулить.
выглядит очень отлично, надо будет протестить на чешском
Чувствую себя глупым — зарегался, попробовал, но ничего не понял :(
Большой труд был проделан, но, как мне кажется, только ради создания словаря частот. Не понимаю способа использовать этот продукт в учебных целях :(
Это офигенно! Мне прямо очень не хватало такого инстурмента.
Правда, я бы больше не для книг бы использовала, а для профессиональной лит-ры типа отчётов, стандартов или пейперов.
У меня есть два предложения в беклог:
Сорри, если очень очевидные идеи. У меня есть опыт с NLP (правда на питончике), так что буду рада ещё побрейнштормить на тему улучшения сервиса, если вдруг будет такое желание.
Есть похожий проект, которым давно пользуюсь - https://wordsfromtext.com Его киллер-фича в том, что он не просто строит словарь, а позволяет загрузить текст и читать его, размечая незнакомые слова и показывая перевод in-place.
Энивей, автору - респект, особенно за опенсурс.
Буквально пару недель назад пришла в голову точно такая же идея. Даже жене о ней рассказал. Офигенно, когда придумываешь что-то, оцениваешь, насколько оно будет полезно, а потом обнаруживаешь, что кто-то уже сделал и твои оценки, похоже, оправдались.
Заранее предупреждаю, что я возможно буду делать конкурирующий продукт :) Но это не точно :)
ахуенно, надо мобилку делать
😱 Комментарий удален его автором...
😱 Комментарий удален его автором...
Нет ли в планах добавить польский?