
Attention
нужна помощь Клуба! Я сегодня запустился на ProductHunt:
https://www.producthunt.com/posts/scrapeninja и сейчас пока на 3 месте в product of the day. А хотелось бы значок, сами понимаете!
UPD: забрали бронзу дня, спасибо всем проголосовавшим!
Расскажите о себе и сути проекта?
Привет! Меня зовут Антон, мне 36, и я так и не научился программировать CTO в небольшой e-commerce компании, широко известной в узких кругах любителей международного шоппинга: qwintry.com, а еще я фанат маленьких SaaS бизнесов и подписочной модели.
В какой-то момент (примерно в 32 годика?) мои глаза потухли, а волосы на голове поредели, и я понял, что драйва в жизни не хватает. Сколько можно смотреть на эти круды и PHP и просить других программировать получше?
Я по жизни везунчик - просидел больше семи лет в мягком кресле CTO - и как только слегка ударился в индихакерство (а это произошло примерно в конце 19 года, кажется), почти сразу меня ждал успех. Где-то пятый проект "выстрелил", в итоге у меня получилось за пару лет создать и вывести два API-first SaaS продукта в $10K+ и $5K+ MRR (monthly recurring revenue) дохода, все это “в одно лицо”, без команды (проект с 10K+ закрылся в последствии, если что, так что я опять нищий). Когда я получил первую подписку на 5USD/mo - это был экстаз. Когда я получил первую подписку на 100USD/mo - я не мог поверить своим глазам. Люди платят мне за мой продукт! Сейчас эти ощущения от денег за подписки уже немного притупились, но что осталось - это новые скиллы, ведь я:
- неплохо прокачался в Node.js/Puppeteer,
- сетях и проксировании (натурально, пока мучился с биллингом - запилил еще один мега-проект, apiroad.net - для монетизации и аналитики API сервисов),
- веб парсинге,
- почувствовал себя увереннее в своих "продуктовых" способностях,
- а самое главное - ощутил уже позабытое счастье от самореализации в любимой сфере деятельности (в последний раз я такое испытывал, когда пилил в одно лицо qwintry.com, но об этом в другой раз) - это вылечивает выгорание надолго!
Собственно говоря, про один из этих продуктов - scrapeninja.net - и пойдет сегодня речь.
Я технарь. И вот мое мнение - индихакерство как явление - обалденная золотая середина между работой в большой компании, где зачастую ты являешься commodity, "винтиком", и техническими хобби проектами "в стол". Когда вам платят ваши кастомеры за собственноручно созданный вами продукт - это незабываемое ощущение. Индихакер - это машина, которая балансирует между разработкой, поддержкой пользователей и поиском своей ниши, не у всех это получается делать, но если получается - это уже тяжело променять на что-то другое)
Если вы запускаете свой продукт, и пытаетесь на нем зарабатывать - напишите мне в телегу: https://t.me/pixeljetter - буду рад знакомству.
Как появилась идея? Что вдохновило?
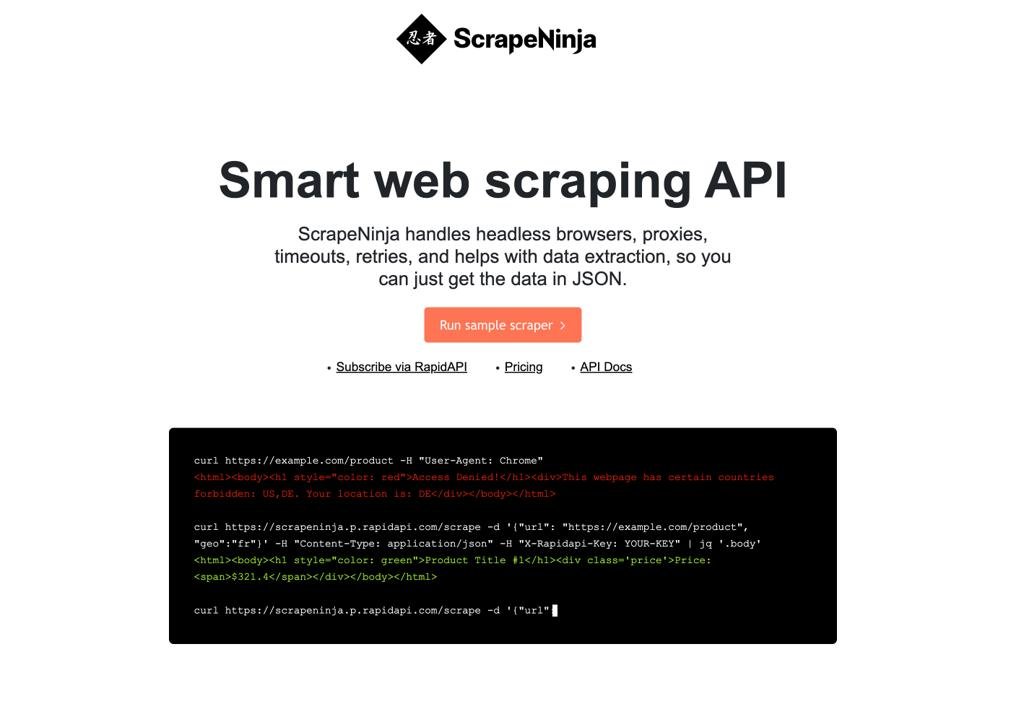
ScrapeNinja.net - это API для парсинга сайтов, и обвязка к этому API, в виде онлайн инструментов, которые можно прямо в браузере пощупать.
"Вдохновило".. как-то раз я пытался спарсить один сайт, он в Хроме рендерился нормально, а если зайти в Chrome Dev Tools и сделать Copy as CURL на network запросе, и этот же запрос запустить в терминале макбука - выдавало 403 ошибку. Сначала я подумал, что что-то не то с заголовками, или с моим айпи адресом... но нет, все оказалось намного интереснее - это CloudFlare, крупнейший в мире DNS провайдер и прокси для большинства сайтов в Интернете, внедрил систему определения качества HTTP запроса на базе TLS фингерпринта.
Вот как работает защита CloudFlare
Работает оно по принципу реверс-прокси - CloudFlare "встает" перед веб-сервером самого сайта (по сути, CloudFlare - это сто тыщ пропатченных nginx-серверов), и анализирует каждый входящий запрос к сайту от браузеров (и ботов). Видит что запрашивается сайт "хорошим" софтом - пропускает запрос к сайту. Видит запрос от "плохого" софта - выкидывает 403.
Этот эффект можно наблюдать в моем видосике:
Подробнее про эту историю и про то, как CloudFlare анализирует траффик, можно почитать в моем блоге (англ):
https://pixeljets.com/blog/bypass-cloudflare/
Собственно, чтобы эту фигню обойти и спарсить сайт, пришлось придумать Ниндзю! под капотом у Ниндзи - очень похожая (по интерфейсу) на cURL консольная утилита, но на самом деле это кусок network стека Хромиума, специально подготовленный (это был челлендж для меня, скомпилировать этот кусок C++ кода, и правильно его подготовить, с моим-то PHP и Node.js бекграундом). Единственное его, куска, утилитарное отличие от cURL - в том, что TLS "отпечаток" HTTPS запроса получается не как у cURL, и не как у Node.js (или Python), а как у обычного Хрома! И это позволяет проходить базовый уровень защиты CloudFlare, не теряя при этом сильно в производительности парсинга (как просходит, если использовать headless браузеры через Puppeteer / Playwright).
К этой идее я добавил некоторых приятных фишечек, например умные ретраи на базе строки в HTML ответе, или статуса HTTP ответа, всякие там прокси в разных странах, и в конечном итоге - возможность браузеры запускать тоже (если очень хочется).
Потом понял, что на одном обходе CloudFlare далеко не уедешь (завтра защита поменяется, и все клиенты уйдут, да и вообще чернуха какая-то получается - обходить защиты) да и хотелось сделать просто удобный инструмент для парсинга, "на каждый день". Поэтому сделал онлайн-билдер веб парсеров:
https://scrapeninja.net/scraper-sandbox?slug=hackernews и инструмент для написания и тестирования "экстракторов" - кусочков кода, написанных на JS, исполняемых на моих серверах, и добывающих чистые данные из HTML кода: https://scrapeninja.net/cheerio-sandbox/basic
Потом, уже сильно позже, добавил headless chrome API. Как я его делал и зачем - в очередном блог посте:
https://pixeljets.com/blog/puppeteer-api-web-scraping/
Что вошло в прототип и сколько времени на него было потрачено?
Примерно две недели я ковырялся, чтобы запустить первую версию проекта. Потом еще пару недель чинил очевидные баги.
Какой технологический стек вы использовали? Почему?
Сразу использовал Node.js для APIшки, и C++ под капотом (скомпилированный кусок кода запускается как отдельный процесс, через https://www.npmjs.com/package/execa), чему несказанно рад до сих пор - на JS при всех его минусах можно говнокодить довольно быстро, при этом производительность - мое почтение. Идеальный баланс "легко пишется, быстро работает". Вот например и Python, и PHP7+, и Golang - языки сами по себе поинтереснее, но конкретно для быстрого тестирования и запуска API серверов подходят чуть хуже на мой взгляд. На гошке будешь страдать из-за статической типизации и мучиться с развесистыми JSON структурами - в итоге работать будет быстрее, и надежнее, но пострадает time-to-market, а на PHP/Python - асинхронные процессы все-таки пока не такие first-class citizen как в Ноде. Puppeteer / Playwright - это, опять же, нода.
Как вы запускались и искали первых пользователей?
Почти все первые, и не только первые, но и вторые пользователи - это заслуга SEO и моего технического блога pixeljets.com - его очень любит гугл, ведь я пишу туда умные (и не очень) вещи уже больше десяти лет.
Сколько потратили и заработали? Есть идеи как это можно монетизировать?
Сейчас ScrapeNinja приносит в районе 5K USD в месяц, но не скажу что активно растет - пора подключать новые маркетинговые каналы (или пилить новый продукт??!).
Каждый месяц деньги уходят на сервера на Хетцнере и на прокси в разных странах, в районе 300 баксов.
Какие неожиданные трудности испытывали?
ScrapeNinja стал так популярен... что Турция, которая банит все сайты связанные с проксями, недавно забанила сайт проекта (так что если вы в Турции - то зайти на Ниндзю получится только через прокси).
Какие планы на будущее?
Сделать ScrapeNinja де-факто стандартом парсинга сайтов для no-code разрабов, например, для людей которые пользуются Make.com:
Нужны ли какие-то советы или помощь Клуба?
нужна помощь Клуба! Я запустился на ProductHunt:
https://www.producthunt.com/posts/scrapeninja и сейчас пока на 3 месте в product of the day.
UPD: забрали бронзу дня, спасибо всем проголосовавшим!
Буду благодарен за вашу посильную помощь и еще сильнее благодарен - за пару строк в отзыв там (потому что, кажется, просто апвоут мало влияет на рейтинг, а очень хочется взять Product of the Day)
Какой совет вы бы сами могли дать идущим по вашим стопам?
- Прежде чем начинать пилить MVP, подумай, как и кому будешь продавать продукт.
- Пили продукт на тех технологиях, которые умеешь.
- Если уже запланировал какой-то MVP запилить, помни что мозг - однозадачный, не распыляйся, сосредоточься на core value, и не сомневайся в успехе мероприятия.
У меня - работает!








У меня есть документ, где собраны сообщества, где можно запросить поддержку на PH, думаю будет полезно.
https://docs.google.com/spreadsheets/d/13DoDv1LZqCbticDWZJUtlnB1IuzHog__xupmzeHIP98/edit?usp=sharing
Красивое 🤩 А с каждой новой версией Хромиума ты билдишь новый релиз, или не обновлять подкапотный Хромиум ок?
Спасибо, вдохновил попробовать некоторые свои идеи :)
привет! классный рассказ, апвоут на ПХ поставлю тоже
вот кстати тема на вастрике где можно тоже взывать к апвоутам - https://vas3k.club/post/2603/
И если не секрет, а по каким причинам убил другой СааС и тяжело ли далось такое решение?
Может наивный вопрос, но мне правда интересно.
А в какой момент ты понял, что экспортированный cURL запрос из браузера не отрабатывает именно из-за того, что CloudFlare ввел фичу с TLS? И как пришла мысль о том, чтобы использовать стек хрома для этого?
Я просто ставлю себя на твое место, и вообще не понимаю как до этого можно додуматься. Вряд ли ведь сам CloudFlare заанонсил новый тип защиты. А даже если так - как пришла мысль о использовании стека хрома?
Супер рассказ!
Антона всегда интересно читать) толковые мысли, остроумные шутки с ноткой иронии над нашей стандартностью)
А тем более зная его лично, отличный нестандартно мыслящий человек, продукт не один его талант)
Поставлю upvote и попрошу друзей бро!🙏
Классный продукт, а какие есть идеи по масштабированию? Подобный сервис вполне можно до 1 млн $ в год вывести, в теории можно даже привлечение инвестиций рассмотреть.
хм... у меня есть пару дестяков сайтов которые надо парсить )))
Выглядит супер! Мне такой сервис точно может пригодиться, взял на заметку
Есть ли в планах добавление инструментов для более сложных сценариев парсинга? Например, вытащить список ссылок, пройтись по каждой, из ответов сформировать единый JSON. ParseHub умеет в такие штуки, но качество их десктопного приложения расстраивает
@pixeljetter а поисковую выдачу Google или yandex выдаёт "раз через раз" ? На тесте гугла получил только первые результаты, без дозагрузки остального (2 ,3, 4 старницы как у яндекс), это как то решается средствами ниндзя ?