
TL;DR
Я связал Logseq и MacOS Dictionary через еще три программы и пару сотен строк кода, чтобы делать карточки как в anki, но в формате logseq. Я это сделал, потому что я учу сербский, а для него и приложений с карточками мало, и я хотел добавлять свои из того, что я читаю и слушаю.
Результат у меня прижился, вдруг вам повезло пользоваться теми же программами, что и я, и вам тоже зайдет. github -- там есть видос.
Интро
Я учу языки. Прямо сейчас сербский. Это не очень популярный язык, а конкретно его нет в memrise, которым я пользовался до этого. Но интервальное повторение -- лучший способ запоминать слова, поэтому что-то делать надо.
Я веду заметки в logseq. Это, очевидно, лучшая программа такого рода, но в данном случае оказалось, что в ней есть система карточек. Еще у меня (и у всех людей, которые пользуются макосью) есть программа Dictionary, которая вообще-то хорошая, и быстро работает, и не требует интернета.
Давайте их подружим.
Достаем определения
Не давайте, говорит нам эпл. Программа Dictionary прекрасно работает словарем, но не дает никакой возможности посмотреть на определения, кроме как глазами. Ни апи, ни Shortcut-ов, ничего.
Ну ладно, но раз она работает без интернета, файлы должны лежать где-то на компьютере, правильно? Правильно, а еще я не первый, кто об этом подумал. И не второй. Кто-то за меня эти файлы нашел, распарсил, сложил в питоний пакет и на гитхаб, а потом еще приложил ссылку на тред на hackernews, который одно удовольствие читать.
На выходе из каждого словаря получается xml-файл, каждая строчка из которого соответствует слову. Само слово лежит в атрибуте d:title. Я ищу его с помощью ripgrep:
-> rg 'd:title="odškrinuti"' ../apple-peeler-output/Croatian.xml --max-count=1 --no-line-number
<d:entry xmlns:d="http://www.apple.com/DTDs/DictionaryService-1.0.rng" id="59304" d:title="odškrinuti" class="entry" lang="hr">...</d:entry>
Внимательный читатель мог заметить, что я ищу по хорватскому словарю, а не по сербскому. Это потому что сербского у эпла нет, а хорватский достаточно на него похож.
Расшифровываем XML
Почти весь код занимается этим, но также про него особенно нечего сказать. Ну xml, ну там классы, они обычно что-то значат. Но иногда это бесполезные обертки, а иногда одинаковые сущности помечены разными классами.
Короче методом проб и ошибок я знаю, где транскрипции, где определения, где фразы, где само слово. Как раз хватает для того, чтобы собрать карточку.
Как узнать, что какое-то определение не распарсилось из-за очередного особенного формата? Например, можно пройтись по всем словам, применить парсер, взять текст на входе и выходе и если он как-то сильно различается, хотя бы по размеру, значит в парсере чего-то не хватает. Я однажды это сделаю, ну или шлите пулл-реквесты.
Собираем карточку
Формат карточек в Logseq прекрасен. Карточка -- это блок, помеченный хештегом #card. Части, обернутые в {{cloze ...}}, скрыты и показываются, когда нажимаешь Show Clozes. Все остальное форматирование работает более-менее как в маркдауне.
Оно работает неидеально, например если расставить много (больше трех?) закрытых частей, он ломается. Но мы здесь не парсер тестируем, а дело делаем, так что и фиг с ним.
Короче, карточка:
- ### {{cloze #{heading.text}}}
{{cloze #{GENDERS[gender] || gender}#{inflections}}}
Definitions
#{definitions}#{definitions2}
#{phrases.empty? ? "" : "Phrases\n\n " + phrases}
#card
Как мне показывается карточка:

На скриншоте видно подозрительный пункт номер ноль и английское слово в нем. Это потому что я добавил его туда руками. Карточка -- это блок, и его можно редактировать в любом месте, где ты его видишь. Например, при проверке. Пригождается минимум на каждом втором слове.
Когда карточка собрана, нужно показать ее логсеку. Логсек оперирует файлами, поэтому можно завести файл с карточками и каждый раз туда дописывать, он поймет.
Оборачиваем программу в Alfred Workflow
Я пользуюсь Alfred, чтобы запускать все на свете. Он мне нравится, никогда меня не подводил, но возможно вам больше нравится какой-то его конкурент, чье название я забыл. В таком случае, шлите патчи.
В альфреде можно делать свои workflow, которые активируются ключевым словом. Я и сделал. Берем слово, достаем определение, складываем в логсек, а заодно открываем это слово в словаре.
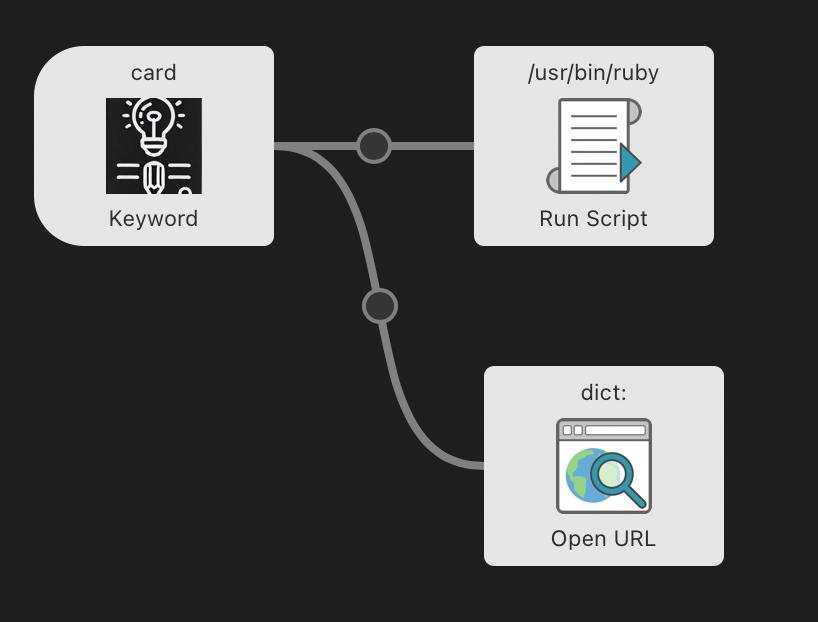
Localfirst
Я ничего для этого не сделал, но логсек, вообще-то, синхронизируется через айклауд с телефоном, а это значит, что он может работать без интернета, то есть 1) мгновенно и 2) если вы читаете книжку в самолете, слова все еще можно добавлять. А еще можно добавлять слова на компьютере, а проверять на телефоне.
Готово
Программа прижилась, я набил 300 карточек и продолжаю. Слова берутся из книжек, подкастов и уроков. Когда мне что-то не нравится в программе, я ее дописываю.
repo, пользуйтесь, шлите патчи. Спасибо.







В чём в итоге отличие от Анки?