
Привет, вастрики! Мы с друзьями собрались попрограммировать и что-то получилось :) Дальше рассказ будет от нас троих: @khadmat96, @dreamwa1ker и меня.
Расскажите о себе и сути проекта?
@nbrzvsk: последние 7 лет идентифицирую себя как продакт :))) в этом году появился интерес создать что-то своё. Одна из мыслей которая получила развитие с этим проектом — про telegram mini apps. Дуров и команда сделали мощную платформу, почти не уступающую по возможностям нативным приложениям. Гипотеза в том, что людям которые сидят в телеге будет удобно выполнять повседневные задачи тоже в телеге, а платформа мини приложений дает кучу возможностей и очень простую активацию — не надо качать приложение и аутентифицироваться.
@khadmat96: Всем привет! Я разработчик под мобилки на всём подряд, а временами ещё и был менеджером. Наш проект - приложуха на базе Телеги для удобного чтения статей.
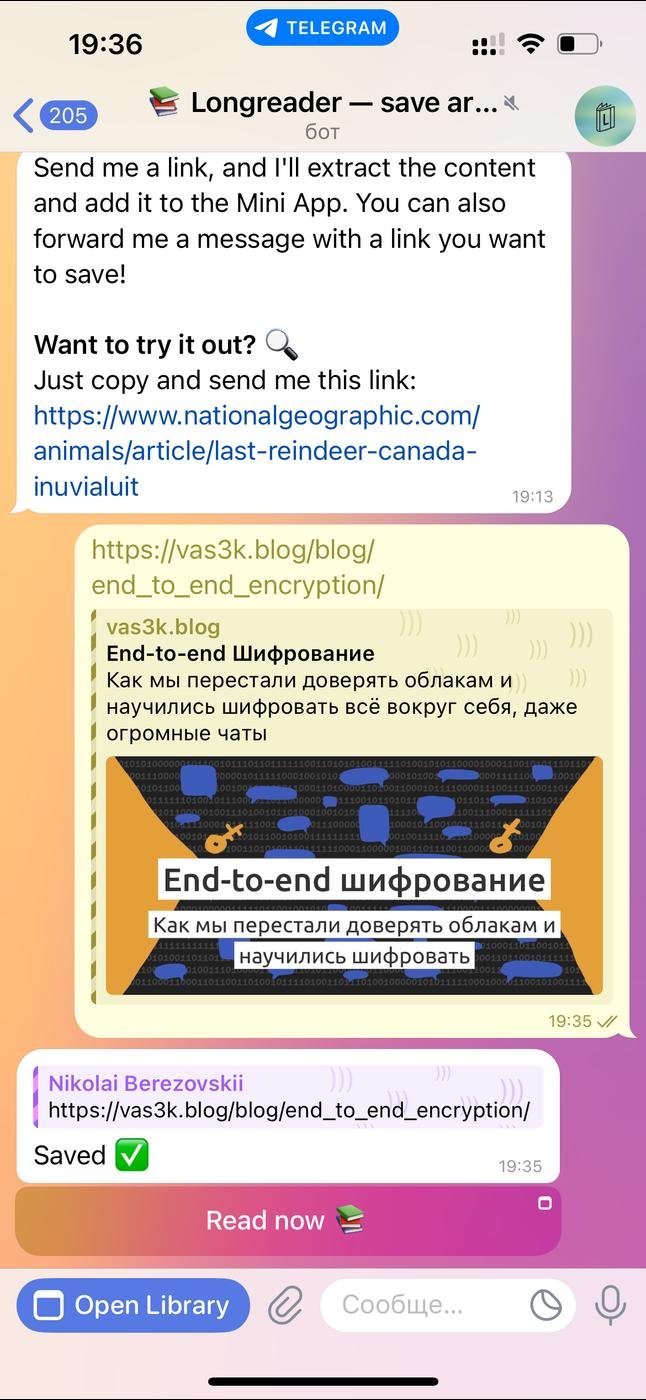
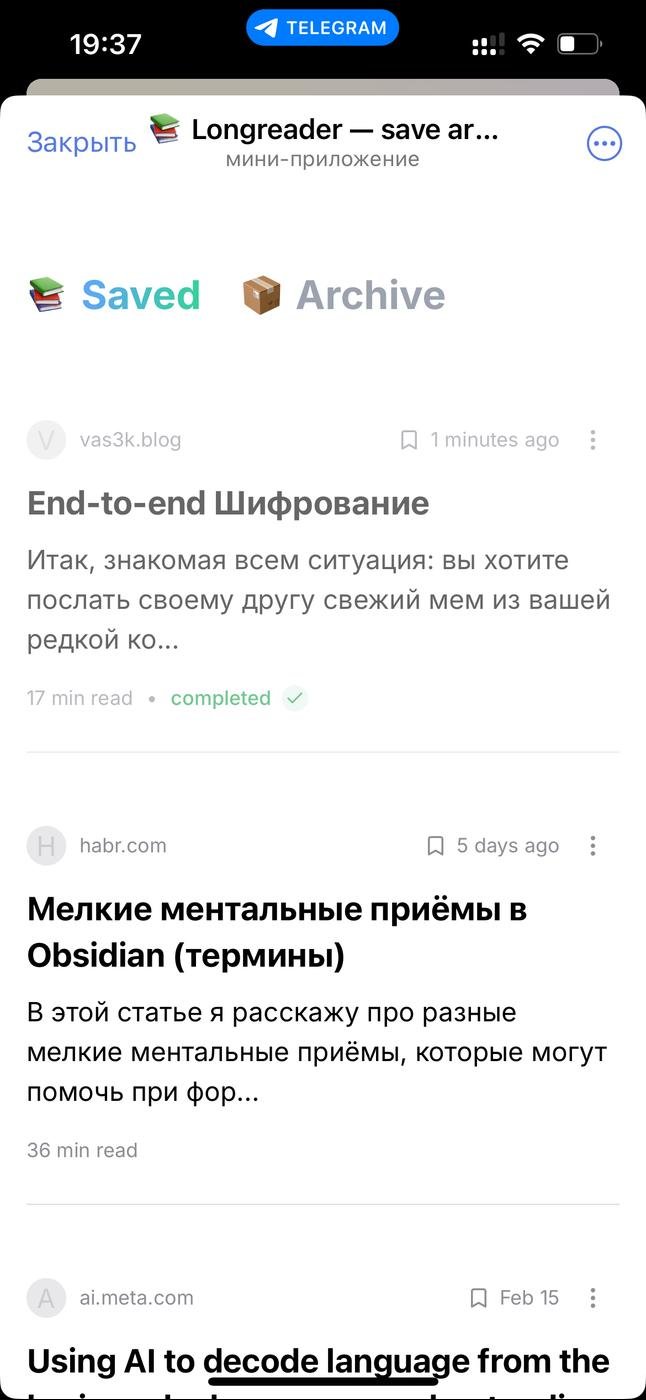
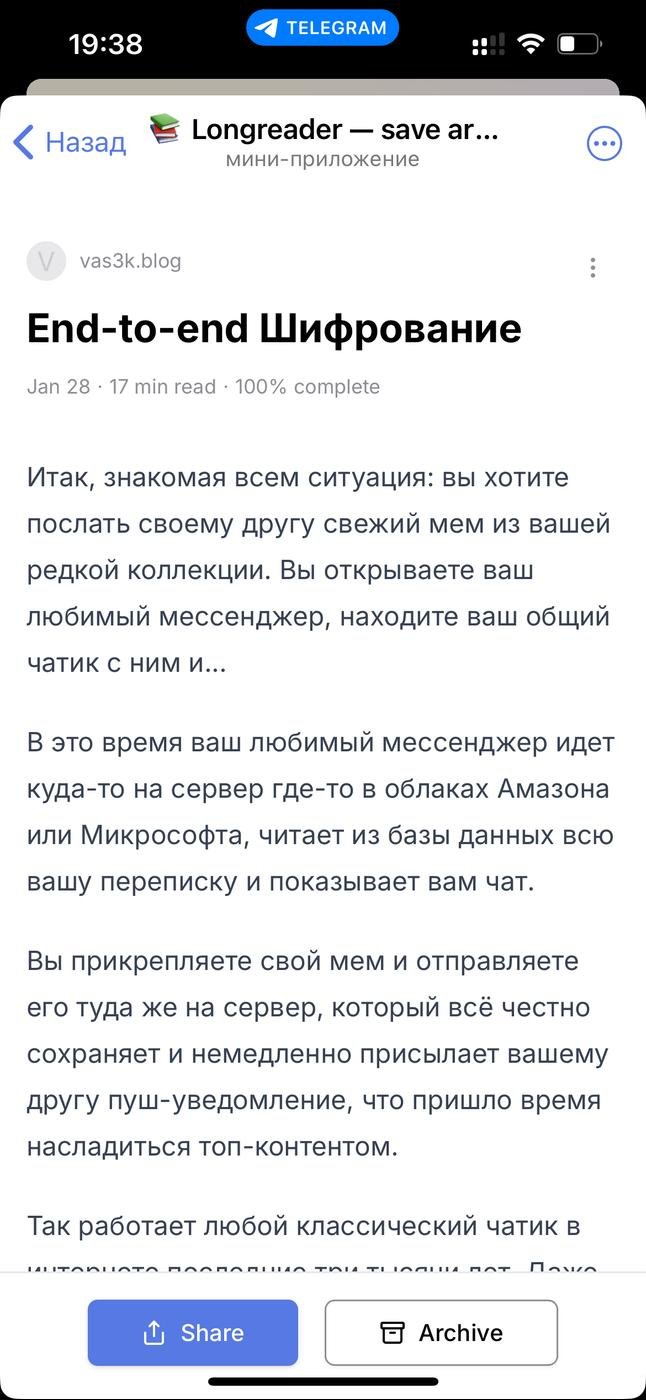
Суть простая: бот в Телеге позволяет сохранять статьи "на потом". Отправляешь или пересылаешь ему сообщение со ссылкой, а он парсит текст, убирает лишнее и сохраняет. Читать можно сразу или позже в минималистичной веб-аппе. Если остановился читать на середине, при следующем заходе аппа сама проскроллит статью до места, где ты остановился.
Удобно, когда натыкаешься на интересный лонгрид, но читать прямо сейчас некогда. Это что-то вроде Saved Messages, но не в виде одной огромной свалки, а в виде удобного чата+аппы под конкретную задачу.
@dreamwa1ker: Привет! Я Паша, занимаюсь QA и саппортом. На одной из встреч ребята предложили поучаствовать в новом проекте. Всегда было интересно попробовать настроить инфру и CI/CD в продакшен проекте, так что я предложил взять эту задачу на себя. Так и началось мое участие тут :)
Как появилась идея? Что вдохновило?
@nbrzvsk: На идею читалки лонгридов вдохновила моя собственная задача — хочу читать больше лонгридов :) Задача давно решена, есть как зарекомендовавшие себя продукты типа Pocket от Mozilla, так и например модный калифорнийский стартап Matter, пропогандирующий “будь умным, читай лонгриды”.
Спусковым крючком “начать чето делать” стали 3 момента:
- бесят подписки! платить 10-20$ в месяц за простейшую (как казалось) читалку меня душит жаба
- желание протестить вайб кодинг с Cursor — последний раз я программировал что-то серьезнее формы сбора данных на лендинге лет 7 назад. Стало очень интересно, насколько моего бекграунда хватит, чтобы ставить задачки пытливому, но вечно косячащему, за то работающему за гроши эйай агенту
- на рынке телеграм веб апп таких решений еще не видно, хотя лонгриды часто появляются в каналах: посты, новости, ссылки на статьи. Сходу удобный UX — просто перешли ссылку боту
@khadmat96: А у меня пару месяцев назад появился интерес поковыряться с апи телеги, посмотреть как работают боты внутри. Я начал делать что-то вроде текстового квеста с картинками, в котором ты нажимаешь на кнопки и получаешь в награду ничего :)) Когда-то я его закончу :)
Как Коля упомянул в начале, мы не чужие друг другу люди, знакомы уже много лет, сейчас живем в разных странах, но периодически созваниваемся поболтать. На одном из звонков я рассказал про свои дела с ботами и поделился черновиком текущего проекта. А Коля в ответ поделился идеей read it later аппы, и нам показалось, что звёзды сошлись, вот она - возможность заиспользовать функциональность телеги, чтобы сделать реальный проект, решающий какую-то задачу. Начали работать над идеей и в процессе привлекли Пашу, с которым мы тоже дружим много лет.
Что вошло в прототип и сколько времени на него было потрачено?
@nbrzvsk: я сделал вебапп со списком статей, экраном чтения, seamless auth с помощью телеги, и хотелось еще попробовать нативный шеринг. Довольно много времени и сил ушло на парсинг статей по ссылке. Итого получилось где-то 40-50 часов активной работы за месяц, в свободное от основной работы время. Для продакта, который первый раз в жизни вбивал “yarn dev” в консоли я очень доволен результатом :)))
@khadmat96: Я занимался только ботом и ещё поднимал на старте впс-ку, на которой крутился(и крутится) этот бот и монга. Бота писал на котлине. И ещё сделал буквально парочку мелких задач на фронте. В текущую версию бота вошла очень простая функциональность:
- Перед началом взаимодействий рассказать что это вообще такое
- Парсить входящие сообщения и определять являются ли они урлом
- Отправлять урл бэкенду на парсинг
- Логировать действия юзеров, чтобы худо-бедно строить воронки. Можно сказать - аналитика :)
Не могу сказать сколько точно было потрачено времени, может быть около 20 часов в свободное от работы время. От начала обсуждений идеи до написания этого поста прошло что-то около двух месяцев
@dreamwa1ker: поскольку имелись лишь базовые представления о том, как всё должно быть устроено, большую часть времени я потратил на чтение документации и эксперименты. В сумме вышло около пары выходных дней неспешной работы. По итогу получилось так:
- сервисы backend, frontend и telegram-bot собираются в образы в GitHub Actions;
- на хосте эти сервисы + база поднимаются в контейнерах при помощи Docker Compose;
- базово настроен Nginx для маршрутизации трафика между сервисами.
Какой технологический стек вы использовали? Почему?
Vibe coding: Cursor Agent + Sonnet 3.5 -> 3.7
Frontend: нынче модные Next JS + shadcn
Backend: Python + FastAPI + MongoDB + Trafilatura для парсинга
Telegram bot: Kotlin + Telegram Bot API
DevOps: Docker Compose, GitHub Actions, Nginx
Как вы запускались и искали первых пользователей?
@nbrzvsk: это самая большая боль сейчас )) делали на энтузиазме, за месяц он ожидаемо поугас, хочется делать что-то и дальше, но основной вопрос — что именно и для кого. Сейчас хотим показать этот проект миру, чтобы понять, есть ли в нем какой-то интерес. Начинаем с этого поста (привет, мир!), дальше пойдем в несколько телеграм комьюнити, которые потенциально любят читать лонгриды.
@khadmat96: Пока что проектом пользуемся мы сами и наши друзья. Судя по логам - не очень активно :) Прямо сейчас, начиная с этого поста, мы будем рассказывать о проекте широкой аудитории и смотреть на результат.
С какими самыми неожиданными трудностями пришлось столкнуться?
@khadmat96: Это скорее не трудность, а забавный кек. В первый день, когда мы развернули всё на “проде”, буквально через несколько часов я заметил, что все мои статьи пропали. Я написал ребятам и сразу же пошел смотреть а что не так.
А оказалось вот что
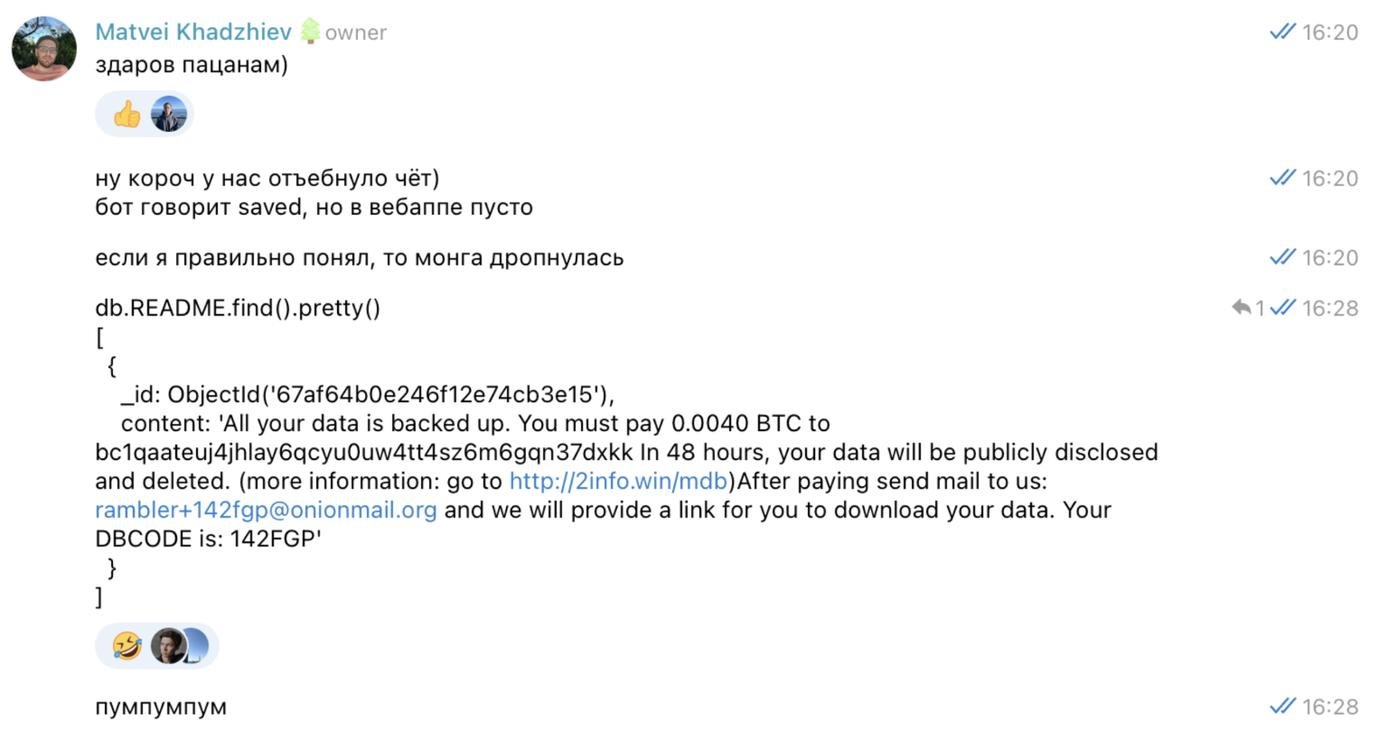
Монга светилась наружу, была обнаружена и дропнута злоумышленником :) Первые грабли они такие)
Благо, что ничего ценного там не было, только мои пара статей. Никто больше к тому моменту не успел попользоваться проектом.
Получив такой опыт мы немного сняли розовые очки и поняли, что нас наверняка будут пытаться сломать разными способами. Из этого родилось текущее ограничение в 10 статей на парсинг в сутки.
@dreamwa1ker: на тот момент “прод” был очень условным. Наружу светились все сервисы, у базы еще не было ни аутентификации, ни бэкапов. После удачной попытки всё поднять, я порадовался, что всё завелось и пошел передохнуть. Вернувшись, увидел сообщения от ребят, что случилось непоправимое :D
Сколько потратили и заработали? Есть идеи как это можно монетизировать?
@khadmat96: Впс-ка на DO стоит 12$/мес, но всё ещё оплачивается из подарочных реферальных кредитов. Если появится нагрузка, то, вероятно, надо будет перейти на впс-ку подороже.
Ещё сколько-то стоят гитхаб экшнс, которые собирают нам имаджи для докера. Про них, я думаю, расскажет Паша.
Детально монетизацию мы пока не рассматривали, но как один из первых и простых вариантов - интеграция звездочек ТГ и увеличение дневных лимитов за них.
@dreamwa1ker: Actions за прошлый месяц, когда разработка была активнее и образы собирались чаще всего, мы потратили около $1.
@nbrzvsk: Да, про монетизацию мыслей много, от подписок за продвинутые фичи (прислать статью войсом как подкаст, сделать TLDR), до usage based за них же, с оплатой telegram stars или через условный tribute. Но основное, это сначала понять что есть какой-то вообще интерес.
Какие планы на будущее?
@nbrzvsk: Если в этом проекте будет фидбэк и потенциал, то развивать его. Если нет — то двинуться дальше, но пойти от рынка и потребностей пользователей. Берем нишу “юзеры телеграма” и их платформу, будем копать в сегменты, общаться и исследовать боли.
@khadmat96: Особо и нечего добавить, всё так
Нужны ли какие-то советы или помощь Клуба?
@nbrzvsk: будем рады как фидбэку о багах и неудобствах, так и более глобальные советы “как встать на путь индихакера” от тех, кто уже это сделал
@khadmat96: честный фидбек!
@dreamwa1ker: помимо фидбэка по продукту, буду рад услышать советы по настройке инфры и CI/CD, безопасности и всему такому.
Какой совет вы бы сами могли дать идущим по вашим стопам?
@nbrzvsk: база — быстрее доводить до первого результата и собирать фидбэк. Без него нужно расходовать гораздо больше ресурсов силы воли :)
@khadmat96: как можно быстрее добираться до первой обратной связи
Воспользоваться ботом можно по ссылке: https://t.me/ReadWatchLaterBot



Круто что сделали такое на энтузиазме! Мне тоже кажется что Телеграм как платформа недоиспользован, хоть и понимаю некоторые причины этого.
Идея для фичи: настраиваемое "подпинывание" прочитать всё-таки сохранённое, думаю хорошо смотрелось бы в виде отправки ботом сообщения с отрезком лонгрида с того места где остановился. Может для кого-то станет основным сценарием использования чтобы есть слона по кусочкам, а лонгрид читать регулярно по паре абзацев из напоминания :)
Понятно что такое не годится для статей где нужно сильное погружение в контекст, но для таких текстов пользователь может и не включать
Скажите, а читалка для лонггрид постов в telegram может работать примерно так же?
Бывает, что в каналах пишут лонгриды на 2/3/... поста. И находятся они где-то там, далеко. Сложно найти.
Можно сделать так, чтобы их переслать в бот и они собирались в читаемый текст? )
Или, возможно, есть какие-то решения?