Как мониторить сервера для себя?
Публичный пост Индихакеры
Индихакеры
У меня есть 3 небольших виртуалки в облаках, на которых крутятся пара пет-проджектов, один VPS для более серьезных штук и дома raspberry pi.
Хочу как-то централизованно мониторить всё это дело, чтобы вручную не ходить по SSH, не читать логи машин и контейнеров в less и смотреть метрики вручную.
Посоветуйте, как не очень всрато организовать мониторинг в одном месте, при условии, что я не настоящий девопс.
Смотрел в сторону ELK, в сторону Grafana/Loki/Prometheus, в сторону rsyslog, но так и не понял, что же мне подойдёт и не будет слишком enterprise.
Чуть более конкретно: 5 машин, десяток докер-контейнеров, ещё 2-3 веб-сайта на чистом nginx+php/flask (могу и докеризовать их).
Нужно смотреть все логи (системные и приложений) и метрики (cpu/mem/io/uptime) в одном месте.
И в идеале ещё и логи домашнего роутера (mikrotik, умеет в rsyslog слать).


если нужно собирать логи: papertrail
Я использую это, запускается одной командой:
https://github.com/stefanprodan/dockprom
Из коробки мониторит все Docker-контейнеры и хост
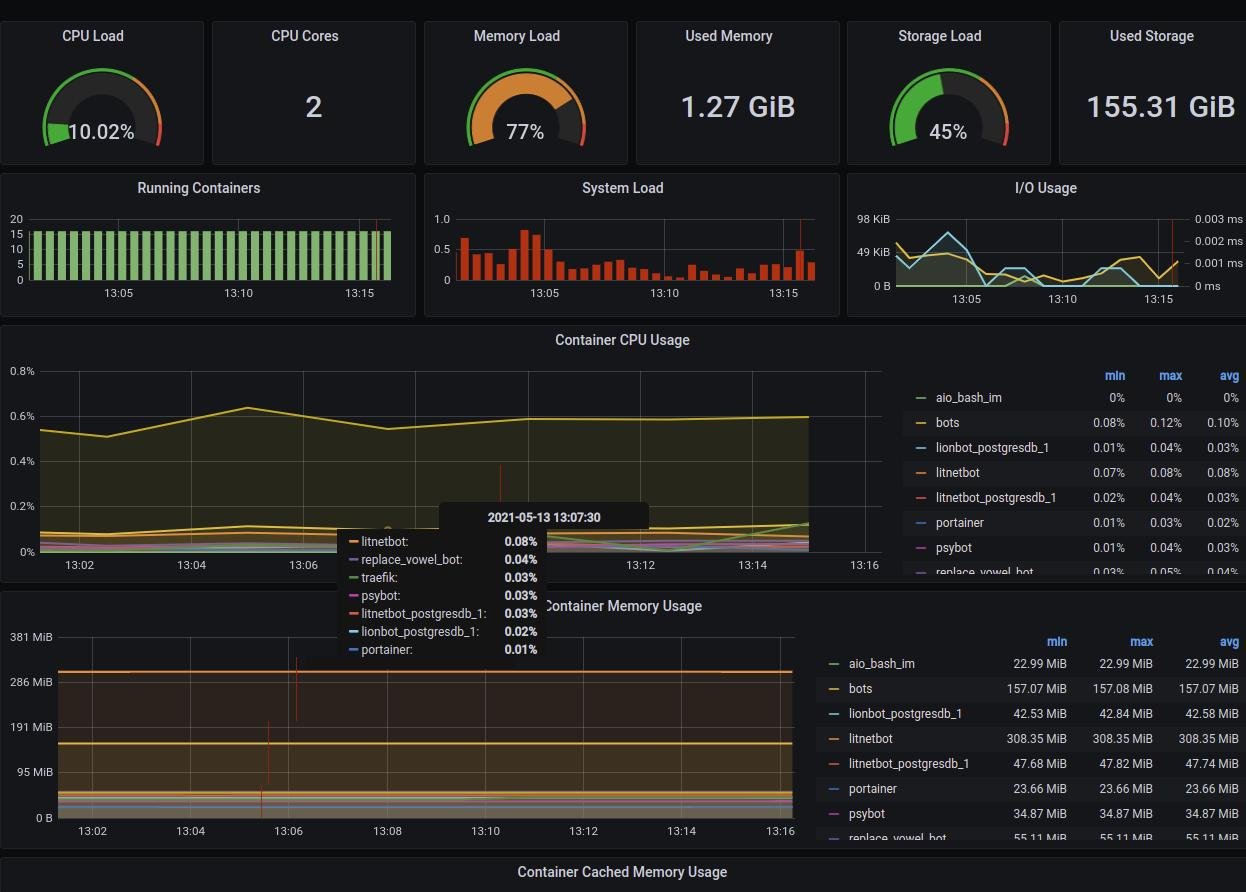
Выглядит как-то так, можно в одно место запихивать разные VPS и мониторить на одном дашборде
Логи из Docker-контейнеров можно отправлять в Google Cloud. Как раз недавно писал об этом пост
Для мониторинга доступных ресурсов можно использовать старый добрый Zabbix. К нему есть уйма плагинов для снятия необходимых метрик.
Для мониторинга доступности я использую сервис Monitorus. Стоит копейки, умеет слать смс или сообщения в телегу в случае недоступности хоста.
Также ваш хостинг провайдер может предоставлять панель с метриками виртуальной машины. Возможно вам будет достаточно и этих данных)
Если не хочется конфигурировать, что-то тяжелое и централизованное (для пет-проджектов это всегда оверкилл) есть netdata: https://github.com/netdata/netdata
Легковесная, zero-configuration, не требуется центральный сервер из коробки есть много чего. Единственное на счет просмотра логов не уверен (раньше точно не было, но может плагин завезли какой), но метрик (+алертинг по ним) там из коробки сильно больше чем даже нужно.
ИМХО это неплохой выбор. Докину ещё InfluxDB. Все три стека, в принципе, одной степени энтерпрайзности, и довольно высокой. Самому, конечно, настраивать и поддерживать это всё я бы не рекомендовал.
Но!
Grafana Cloud предлагает абсолютно бесплатно:
И это здорово! Это абсолютно managed решение и оно не требует никаких телодвижений. Зарегался, получил токены, можно слать данные. Я рекомендую, сам использую для хобби в похожих условиях, только у меня JVM-стек.
Из удобств: туда можно абсолютно легально завести метрики вообще со всего, что у тебя есть. Все проекты, сколько бы у них ни было ресурсов, можно держать в одном месте и коррелировать. Grafana создана для этого. В отличие от той же netdata, которая хороша, но больше как-то предназначена для мониторинга на местах, на конкретных серверах (там есть ре-стриминг, но его ещё настраивать надо всюду).
Из недостатков: если твои проекты крутятся за NAT и у них нет внешнего IP, Prometheus, использующий pull-подход, не сможет забрать метрики. Решается либо выбором стека с push-подходом (Influx, но тут я не знаю бесплатных managed решний для хобби) либо использованием специального push gateway.
Grafana, Influx, Kibana - это уровень дешбордов и алертов. Данные в них можно закидывать из кучи источников. Grafana Cloud Agent, Telegraf, node / process / docker -exporter - это агенты которые будут собирать и экспортировать разные метрики. Их десятки, выбор зависит от стека, pull / push, форматов, задач, требований. Нужно выбирать конкретно, но выбирать всегда есть из чего.
В добавок ещё сами приложения могут экспортировать специфичные для языка (типа количество сборок мусора) или бизнеса (завершённые транзакции) метрики. Например для Flask нагуглилось https://pypi.org/project/prometheus-flask-exporter - это экспортер метрик из Python / Flask в формате прома.
Селхостед альтернатива Datadog и NewRelic - https://github.com/SigNoz/signoz
Неплохой вариант - Check_MK. Прост в установке и добовлении хостов в мониторинг, интеграция с Opsgenie для получения уведомлений, умеет в логвотч и инциденты по ошибкам в логах.
Selfhosted:
https://www.librenms.org/
Умеет собирать логи в кучу
Вот такое ещё есть - https://www.nginx.com/products/nginx-amplify/
Здесь уже говорили про бесплатную Grafana Cloud — тоже ее использую, топ решение для небольших пет проектов.
Еще бы посоветовал посмотреть на их плагин для синтетического мониторинга, позволяет спать еще спокойнее, когда знаешь, что сервер не валяется не только по своим метрикам, но и нормально доступен из внешнего интернета — https://grafana.com/grafana/plugins/grafana-synthetic-monitoring-app/
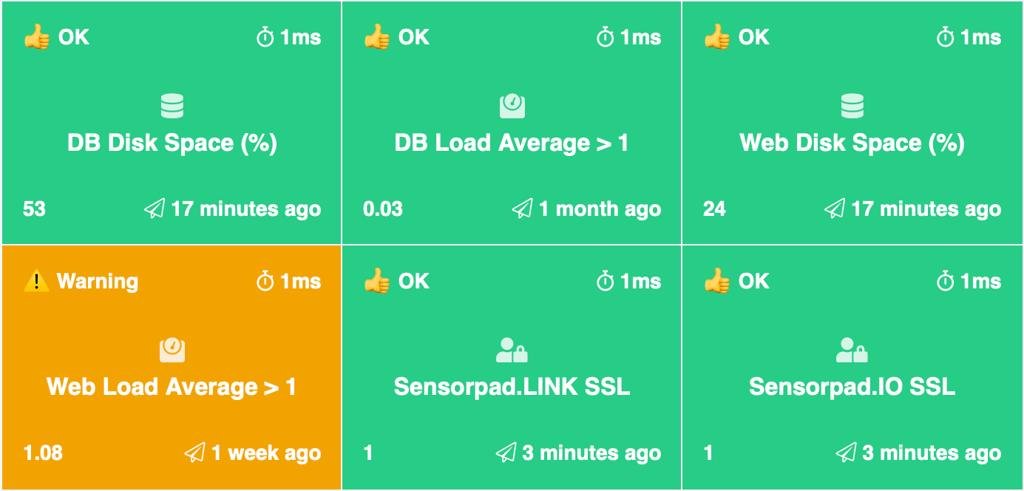
Пишу по выходным систему для мониторинга https://sensorpad.io
Надеюсь, соберусь мыслями и напишу большой пост в клуб про это, но пока можете поиграться, если не лень.
Кстати, вот как Sensorpad мониторит сам себя:
Я тут пару дней назад написал пост о том, как я делал сервис для мониторинга:
https://vas3k.club/project/10256/
Если пойдешь в сторону прометея, я всем кидаю вот этот сахар https://awesome-prometheus-alerts.grep.to
Все свои наработки туда залил
😱 Комментарий удален его автором...