
Доброго времени суток, Клубчане! Как и обещал, делюсь знанием по настройке мониторинга для своих пет-проектов. Сам пост отделен ::END секциями в зависимости от ваших потребностей. Вы можете остановиться в любой момент)
Сам я Android-разработчик, поэтому сурового хардкора не будет : D Правда быстро и в одну строчку тоже не будет, особенно если вы хотите что-то эдакое, хотя за вечер справитесь) Ну чтож... cнизил ожидания и... погнали : )
🤓 Что, в принципе, существует для того чтобы мониторить свои сервисы?
Популярных подходов два - когда мониторинг-сервис опрашивает сервисы (например, через HTTP API) или когда сервисы засовывают метрики в мониторинг (чаще всего, отправляя UDP).
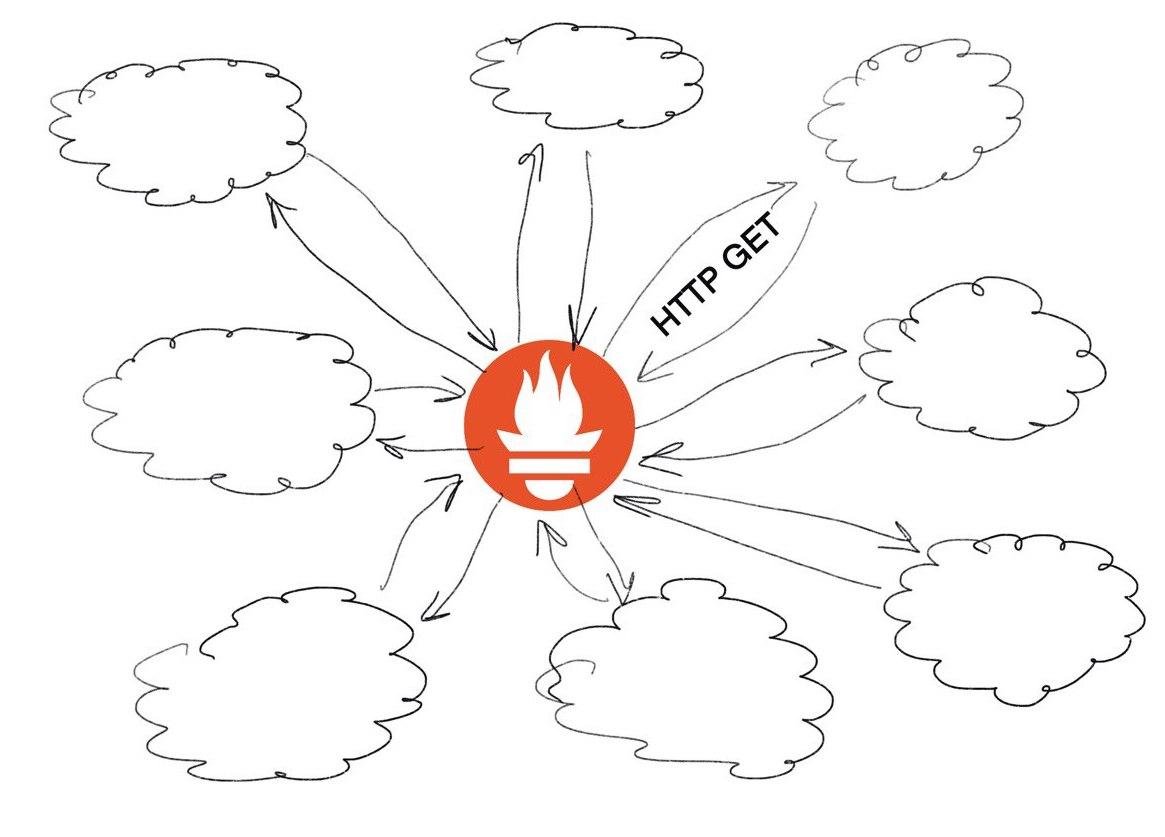
В нашем случае мы будем использовать Prometheus и подход с фетчингом метрик из сервисов. Во-первых, потому что в отличии от grafana prometheus feature-rich компонент, а значит все сразу из коробки, что нам на руку : D А, во-вторых, я его знаю и использую, поэтому речь пойдет о нем : ) Но вцелом все похоже, только названия тулзовин разные
📝 Какой у нас план?
Прометеус - это база данных, в первую очередь (time series тип), которая хранит и обрабатывает поступающие в неё данные. Значит нам нужно что-то что предоставляет эти данные и что-то что отображает.
Данные нам поставляют экспортеры, а красивые графики рисует Grafana. Вот как это выглядит сверху:
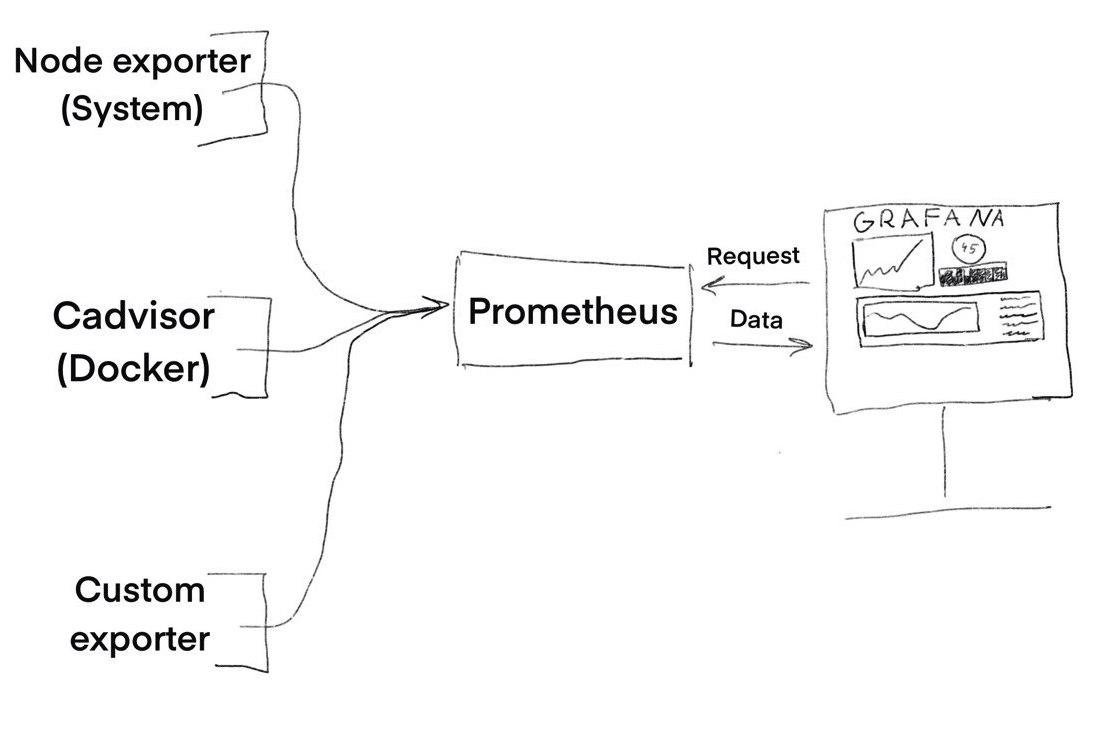
Изначально уже есть готовые экспортеры и готовые настройки для графаны, их мы и будем использовать.
🖥️ Сетапим мониторинг для одной машинки
Добрые люди за нас уже подготовили базовый сетап из экспортеров и дашборды. Для запуска всего этого чуда нам потребуется Docker и docker-compose. Клоним себе проект и поднимаем несколькими командами (флаг -d означает что запускать мы будем в фоне, в демоне):
git clone https://github.com/stefanprodan/dockprom
cd dockprom
docker-compose up -d
По умолчанию логин и пароль будет admin и admin , но его можно поменять ручками внутри docker-compose.yml или подставить как переменные окружения. Заходим на :3000 порт и вводим туда дефолтные логин и пароль. Сразу после логина нам предложат поменять дефолтный пароль, советую это сделать) Далее можно посмотреть существующие дашборды в Dashboards→Manage:
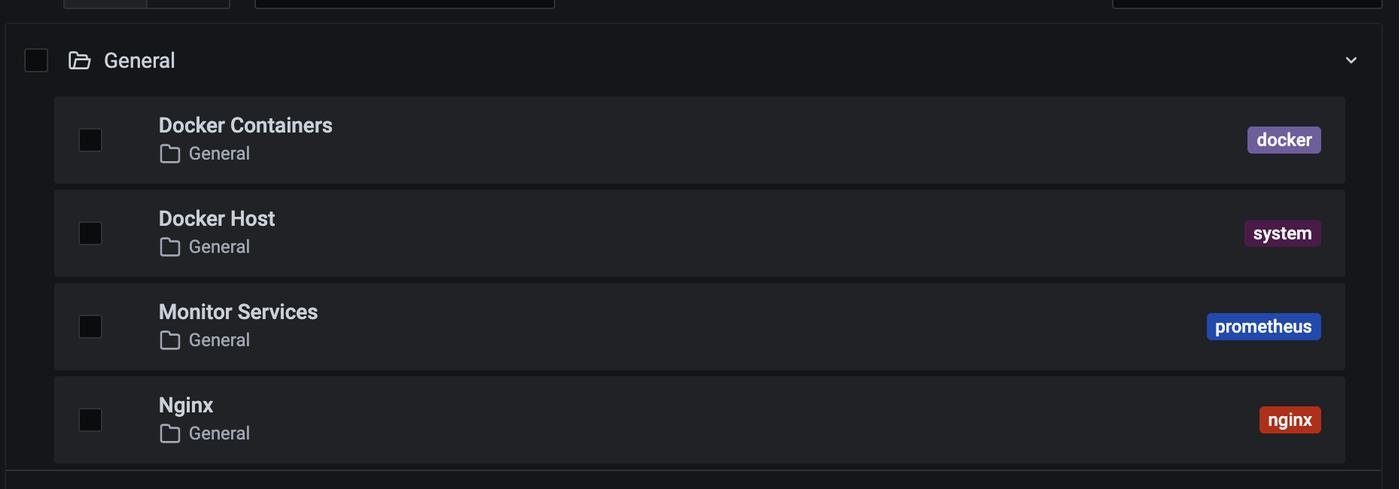
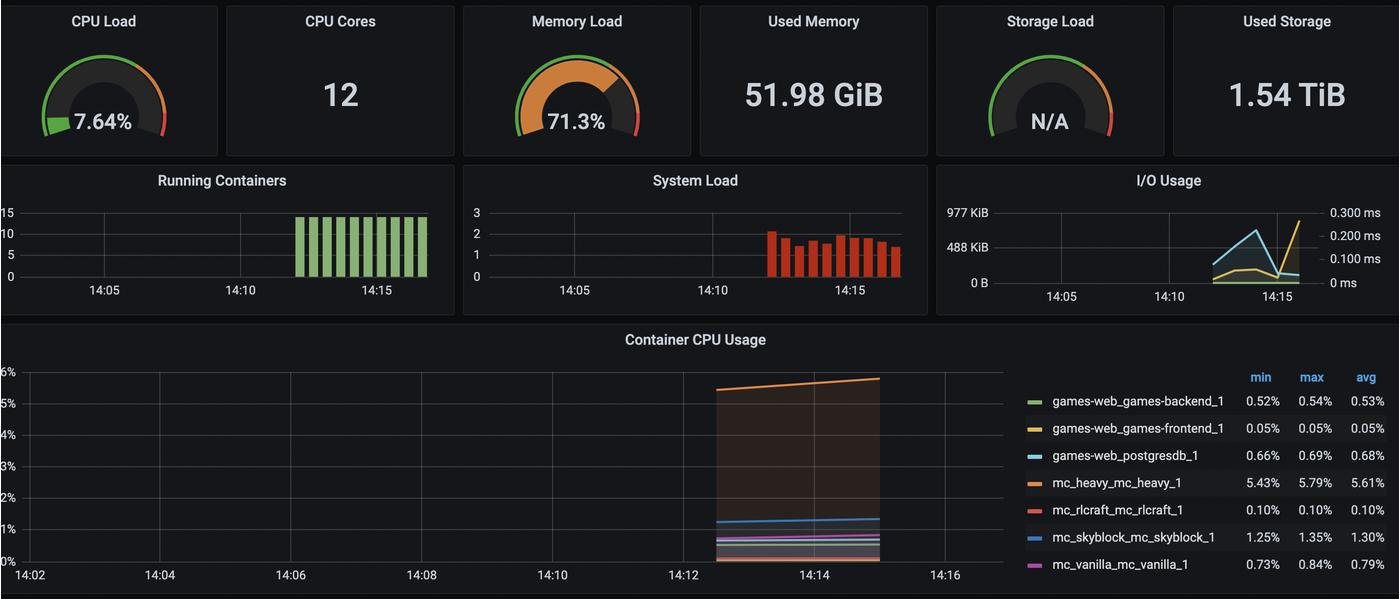
В целом, наша метрика готова : ) У нас есть отдельно разбитая метрика по Docker-контейнерам и отдельная метрика метрика по состоянию host-машины. CPU/RAM загрузка и статистика по хранилищ. Многим достаточно этого : )
:: END тут если вас устраивает текущая борда для одной машины
🐛 Фиксим мелкий баг в борде
Единственное, storage load выдает N/A, можем его пофиксить. Выбираем плашку и нажимаем редактировать:
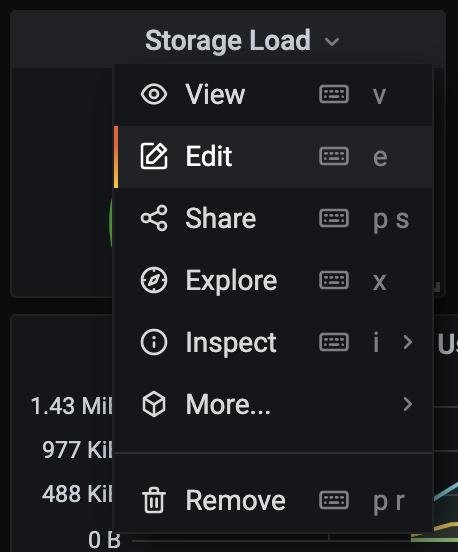
Смотрим какой запрос ответственен за это и находим виновника:
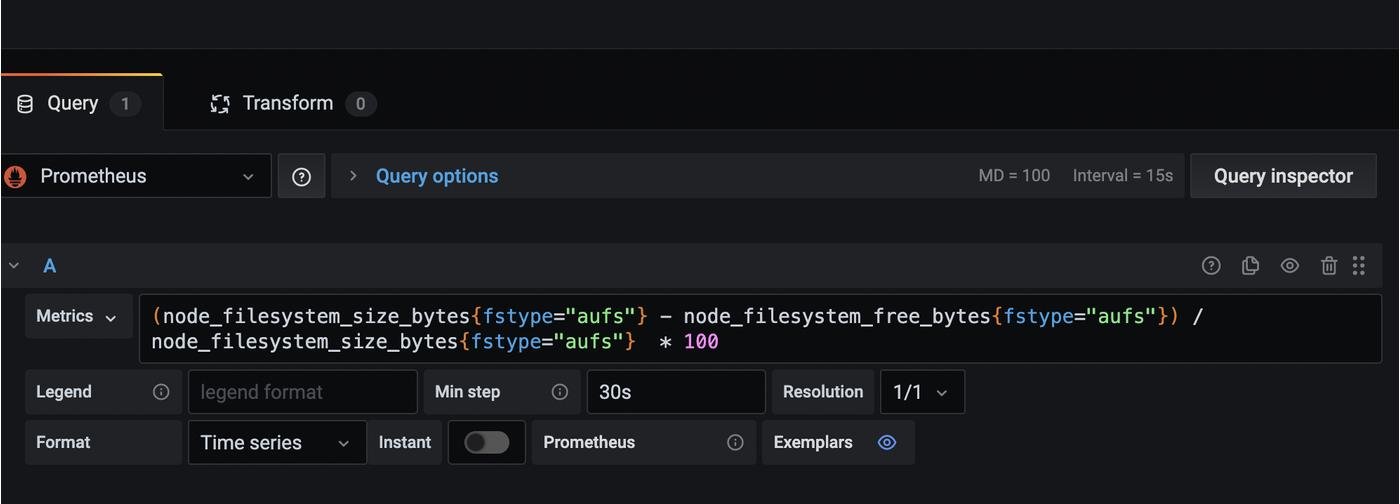
Ага, виновник найден - по умолчанию мы смотрим на ищем сторадж с файловой системой aufs , которого, естественно, нет. А какие есть? Можем попробовать выполнить запрос node_filesystem_size_bytes прометеусу напрямую (Меню справа → Explore) и глянуть какие варианты есть:
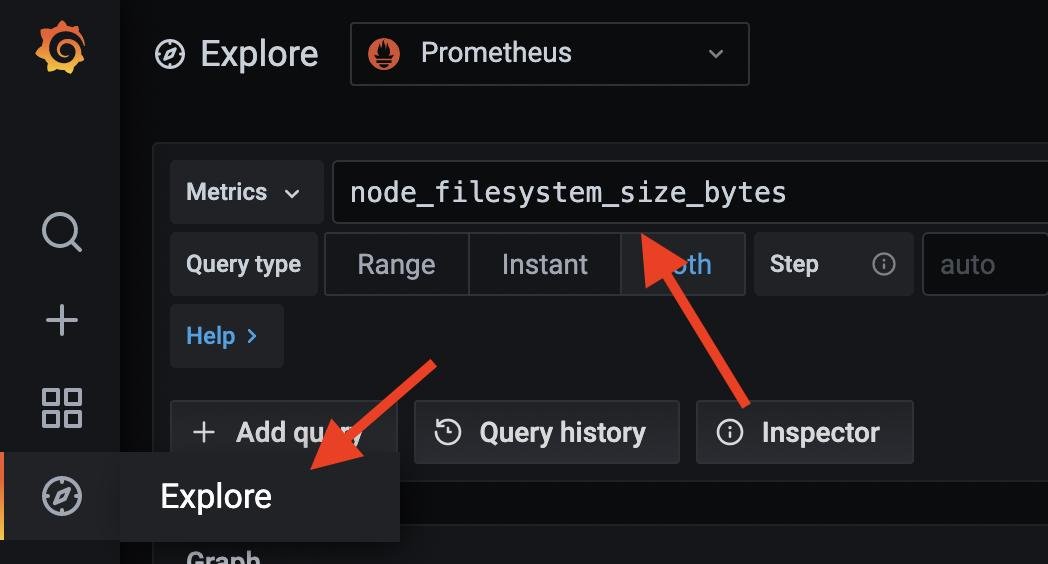
Видим что интересующий нас сторадж имеет fstype=ext4. Бинго!
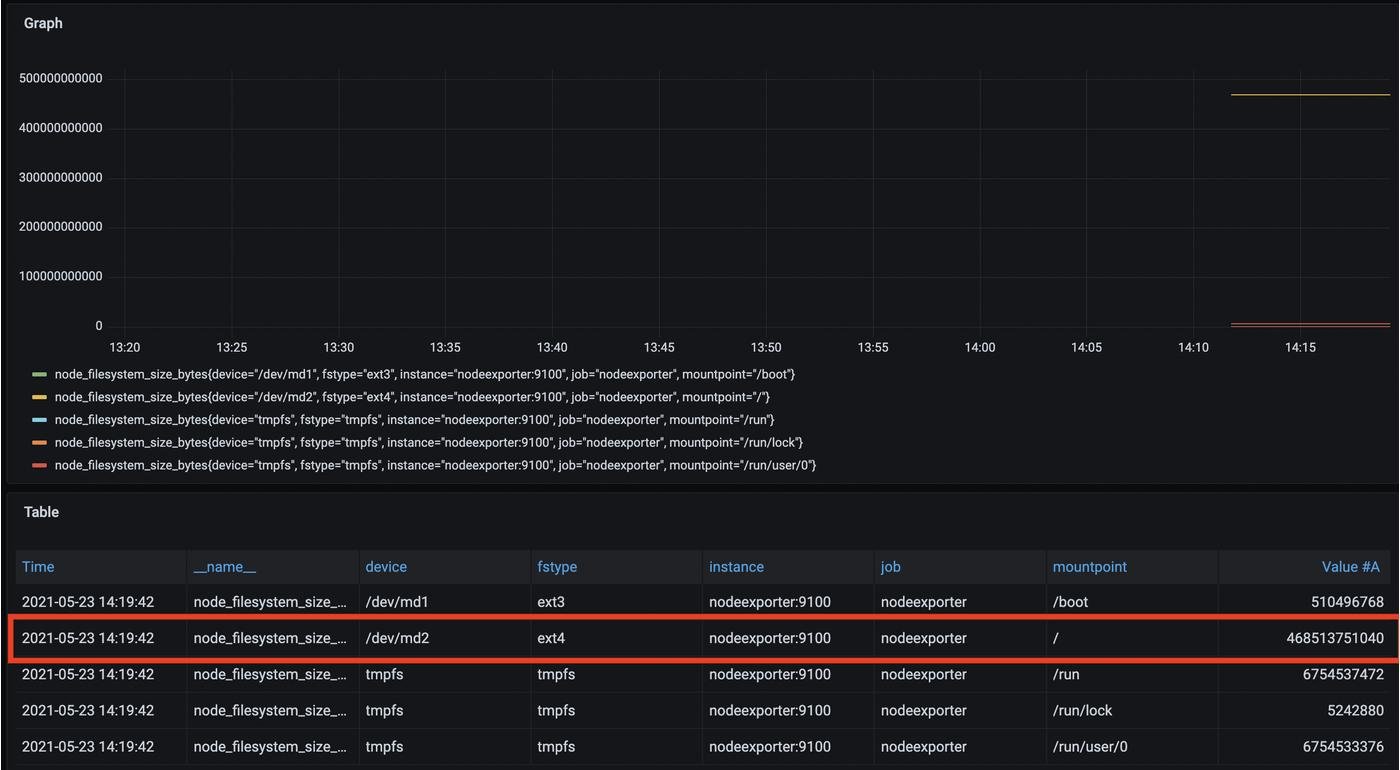
Возвращаемся в дашборду, редактируем запрос и видим успех : )
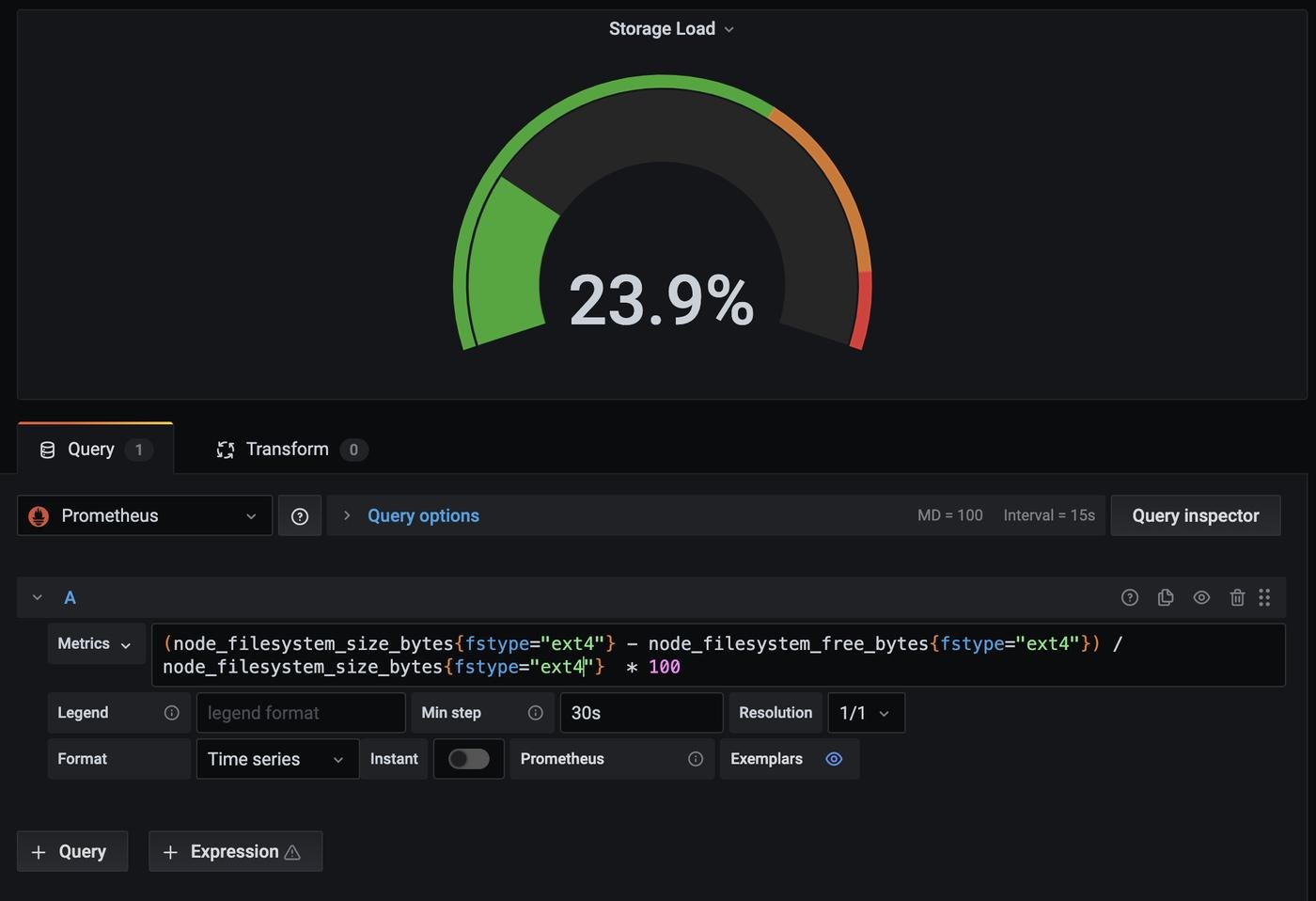
Вот примерно так можно редактировать или создавать новые плашки в дашборде. Помимо уже существующих и готовых)
Еще из интересного - можно настроить алерты на критические показания каких-то метрик. Отличная инструкция для этого есть в readme проекта, лучше этот процесс я навряд ли опишу.
:: END тут если вас одна машина для мониторинга
👩👩👧👧 Сетапим мониторинг для нескольких машин
А что если у вашего пет-проекта больше одной машины? Хотелось бы на одной машине смотреть все, не так ли? Окей, это можно сделать. Вначале на хост-машине поднимайте все что выше, а потом поднимайте на вашем сервере экспортеры. Создатели репозитория dockprom заботливо сделали специальный файлик docker-compose.exporters.yml для этого. Инструкция для поднятия этого такая же легкая как и на хост-машине:
git clone https://github.com/stefanprodan/dockprom
cd dockprom
docker-compose -f docker-compose.exporters.yml up -d
Все! Теперь надо настроить хост-машину и добавить туда наши экспортеры. Открываем и редактируем наш prometheus/prometheus.yml , добавляя туда новые экспортеры и ip внутри секции scrape_configs
- job_name: 'nodeexporter_minecraft'
scrape_interval: 5s
static_configs:
- targets: ['168.119.89.86:9100']
- job_name: 'cadvisor_minecraft'
scrape_interval: 5s
static_configs:
- targets: ['168.119.89.86:8080']
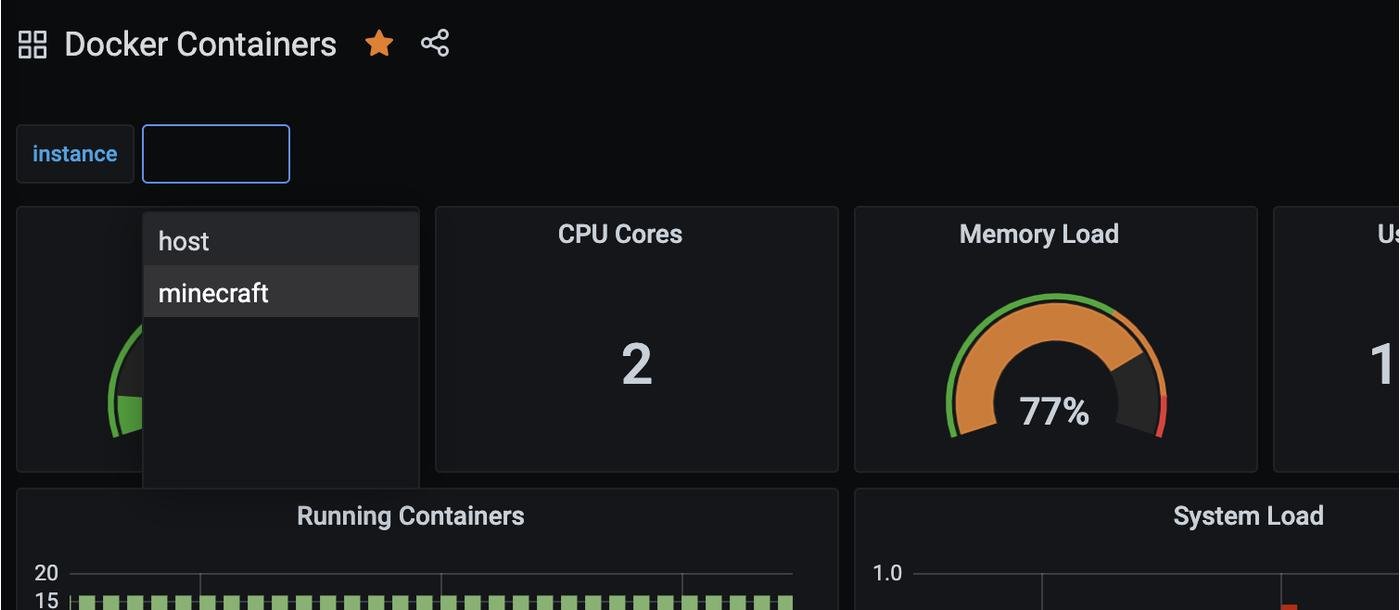
Так как мы хотим красивые названия у машин, нужно добавить фильтр к экспортеру, который перезаписывает имена (сделайте это для каждого экспортера):
- job_name: 'cadvisor_minecraft'
scrape_interval: 5s
static_configs:
- targets: ['168.119.89.86:8080']
relabel_configs:
- source_labels: [__address__]
regex: '.*'
target_label: instance
replacement: 'minecraft'
Перезапустим хост контейнер с помощью docker-compose restart и проверяем результат : ) Можем как раз на команде, которую мы фиксили в предыдущем пункте (node_filesystem_size_bytes):
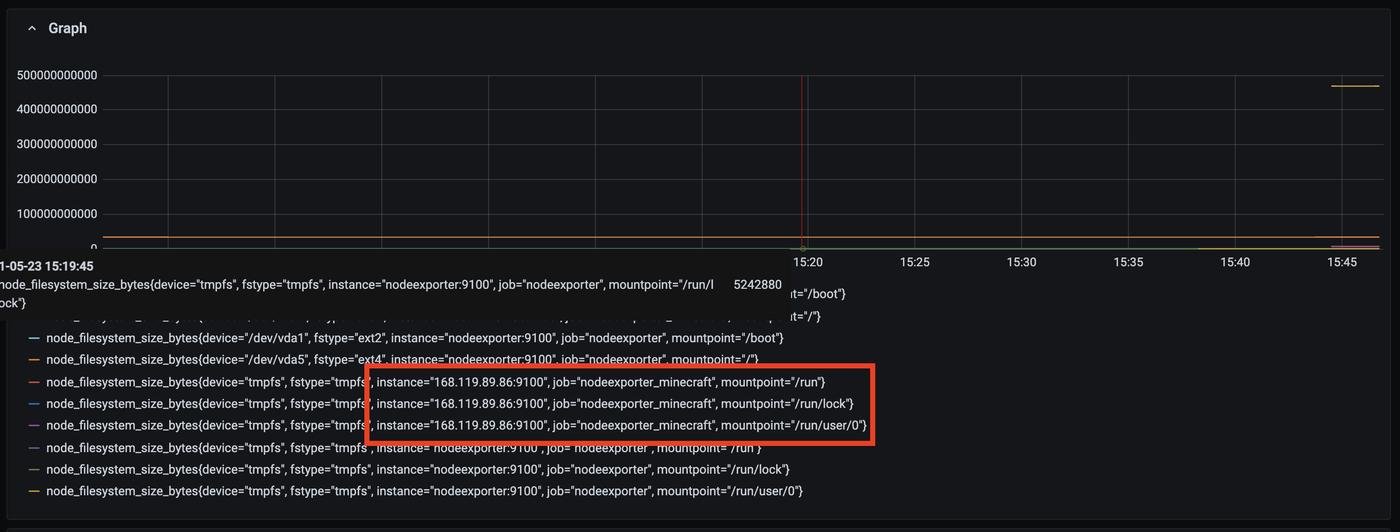
Бинго! Вот наши метрики! Теперь давайте посмотрим как выглядит наш dashboard теперь

Мда... Ну ожидаемо хотя бы, как им еще себя вести. Нам необходимо добавить variable и составить все запросы в графиках так, чтобы они фильтровали результат еще и по машине. Это довольно нудная работа, поэтому я её сделал за вас. Вам остается лишь сделать import этих двух dashboard. Зайдите в Create→Import и загрузите dashboard с id 14479 и 14480
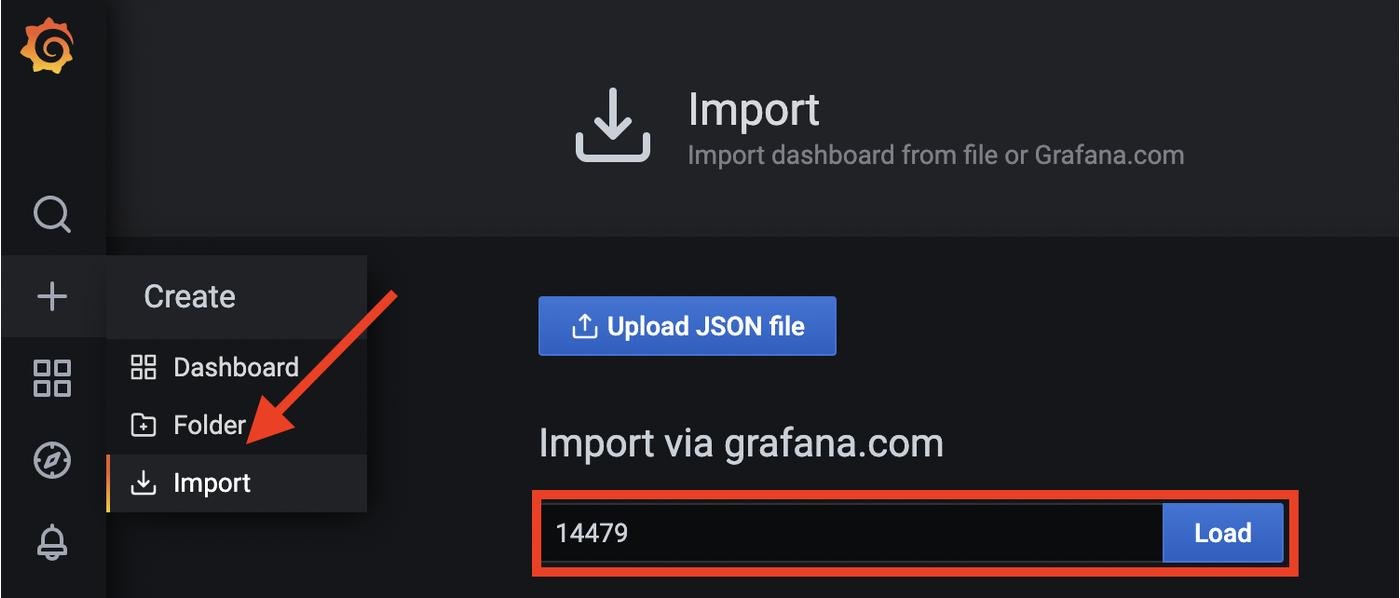
Класс. Теперь все работает:
:: END тут если вы don't worry about security
🛡️Security
А вас ничего не смутило в предыдущем этапе? Таки да, мы просто берем, указываем IP сервера и получаем к нему доступ. Т.е, любой человек в интернете сможет прочитать наши метрики? Фигня какая-то. Давайте добавим авторизацию. На стороне гостевой машины меняем caddy конфиг на:
:9100 {
basicauth /* {
{$ADMIN_USER} {$ADMIN_PASSWORD_HASH}
}
reverse_proxy nodeexporter:9100
}
:8080 {
basicauth /* {
{$ADMIN_USER} {$ADMIN_PASSWORD_HASH}
}
reverse_proxy cadvisor:8080
}
И docker-compose.exporters.yml (добавим caddy и объединим все контейнеры в одну сеть) на:
version: '2.1'
networks:
monitor-net:
driver: bridge
services:
nodeexporter:
image: prom/node-exporter:v1.1.2
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
cadvisor:
image: gcr.io/cadvisor/cadvisor:v0.39.0
container_name: cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /cgroup:/cgroup:ro
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
caddy:
image: caddy:2.3.0
container_name: caddy
ports:
- "8080:8080"
- "9100:9100"
volumes:
- ./caddy:/etc/caddy
environment:
- ADMIN_USER=${ADMIN_USER:-admin}
- ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin}
- ADMIN_PASSWORD_HASH=${ADMIN_PASSWORD_HASH:-JDJhJDE0JE91S1FrN0Z0VEsyWmhrQVpON1VzdHVLSDkyWHdsN0xNbEZYdnNIZm1pb2d1blg4Y09mL0ZP}
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
Далее на хост-машине нужно указать что мы не просто делаем GET запросы, мы еще и логин+пароль прокладываем. В prometheus/prometheus.yml нужно добавить блок с basic_auth (только замените на свой логин/пароль):
basic_auth:
username: 'admin'
password: 'admin'
Done! Теперь вы защищены!
🏁 Заключение
Ну вот мы настроили свой сервер. Есть варианты быстрее (netdata, godmod by vas3k), менее ресурсоемкие (Grafana Cloud), платные (очень быстро в платный тариф упираешься), но одним кликом (datadog). И прочее. Подробнее про альтернативы можно почитать тут: <a href="https://vas3k.club/question/10033/">https://vas3k.club/question/10033/</a>
Но что мне нравится в текущей связке:
- Полностью self-hosted: ты не зависишь от изменения правил сервиса/расценки, все у тебя на серверах
- Бесконечно расширяемый: при желании можно навесить мониторинг абсолютно любой сложности
- Простой в написании экспортеров: эту секцию я решил не описывать, потому что статья уже не маленькая, но поверьте - экспортеры реально легко писать. На любом языке и в любой экосистеме. Если хотите отдельную статью про написание экспортеров, напишите мне, запилим. Но вообще там самому легко разобраться
❓Что не было покрыто тут?
Я не затрагивал сбор логов и сбор крешей. Варианты с которыми это можно сделать описаны тут: <a href="https://vas3k.club/question/10033/">https://vas3k.club/question/10033/</a>
Лично я сам использую Sentry для крешей, для логов подумываю воспользоваться Google Cloud.
Так же я опустил нюансы настройки метрики вне docker'а. Там все очень похоже (конфиги то одни и те же), просто надо будет еще ручками ставить prometheus, grafana и прочее.
Пишите комментарии! Нет ничего светлее чувства когда спустя 5 лет находишь статью и в комментариях кто-то предлагает идеально подходящее тебе решение. Ну и вопросы задавайте, да)



Извините за душнину, но у вас стрелочки не в том направлении на диаграмме про то, как все устроено - не сервисы ходят в Прометей, а Прометей в сервисы. Это довольно важная часть в логике его работы, ИМХО.
На самом деле можно чтоб сервисы сами все в него слали, но там чуть другая история и ее не очень рекомендуют.
К А Е Ф
А А
Е Е
Ф Ф
Кроме смены пароля в Grafana нужно ещё поменять пароль в Caddy. Иначе на Prometheus http://host-ip:9090 , Prometheus-Pushgateway http://host-ip:9091 и AlertManager http://host-ip:9093 логин:пароль так и останутся admin:admin
Делается это так:
docker run --rm caddy caddy hash-password --plaintext 'ADMIN_PASSWORD'Вместо ADMIN_PASSWORD вставляем свой пароль
Команда выдаст хеш пароля. Этот хеш нужно прописать в docker-compose.yml:
nano docker-compose.ymlв самом низу файла: caddy-> environment -> ADMIN_PASSWORD_HASH=${ADMIN_PASSWORD_HASH:-/сюда вставляем хеш/}
После этого перезапускаем docker-compose
docker-compose up --build -dВзято отсюда:
https://github.com/stefanprodan/dockprom#Updating-Caddy-to-v2
Ещё там же в docker-compose.yml можно задать дефолтный пароль Grafana в настройках соответствующего контейнера.
Опытным путём выяснил, что пароль Grafana в docker-compose.yml имеет приоритет над тем, который указывается в config файле. Но на всякий случай меняю в обоих файлах :)
Спасибо за статью! Хотел ещё дополнить, что по умолчанию есть алертинг и докрутить его, чтобы он слал в телегу - не очень сложно.
Для этого можно воспользоваться сервисом telepush:
dockprom/alertmanager/config.yml)dockprom/prometheus/alert.rulesСтатья, которой руководствовался.
Спасибо, я себе поставил еще в тот момент когда статья была комментарием. Прямо 100% в мои нужды )
Огонь!
А если я хочу мониторить и докер, и хост, на котором он бежит, я что-то делаю не так?
То, что надо! Thanks!
Прочитал во второй раз и понял что там про алертинг ничего нету. Его как-то можно прикрутить?
Для логов у той же Графаны есть встроенные механизмы.
Это позволит иметь всё в одном месте и, допустим, настроить alerting по метрикам и логам сразу.
Немного про DataDog, он на самом деле в бесплатном режиме дает очень много. Если не привязывать свою карточку и не давать свой номер телефона, можно весьма успешно пользоваться без ограничения по времени, но с небольшим ограничением функционала (например не будет логов).
Из того что я видел даже платный вариант это очень крутая штука, особенно если надо что бы пыш пыш и работало.
При пулле из докера лезет такое:
dockerpycreds.errors.InitializationError: docker-credential-gcloud not installed or not available in PATH
Беглый гуглинг показал, что оно требует какую-то либу (или даже скорее целое sdk) от Google Cloud, которое ещё и ставить надо, скачивая не из репы, а откуда-то с их сайта.
Не-не, корпорации добра я не настолько доверяю.
Хм, я в общем хз, может у меня руки кривые, но насколько я понял, некоторые метрики нужно тянуть с IP:9001, а некоторые - с IP:8080 и половина метрик не отображается, на дашборде из инстансов только ip:9001
А что по памяти? Prometheus так то её очень любит и для своего сервера на каком нибудь DO за 5 долоров или AWS FreeTier будет жирновато.
Автору спасибо за труды - всегда интересно читать за автоматизацию)
При этом есть пару моментов куда хотел бы обратить внимание:
Пользуясь случаем попиарю свой пост о том, как я писал сервис, с помощью которого можно настроить вполне себе полноценный мониторинг сервера меньше чем за час:
https://vas3k.club/project/10256/
Круто, давно хотел себе какие-то метрики и алёрты, а тут всё из коробки работает.
Правда, у меня не получилось завести nginx дэшборд, у кого-то получилось?
Добавил экспортер, настроил путь на nginx, как в этом комменте — https://github.com/stefanprodan/dockprom/issues/187#issuecomment-653273427
Но графики все равно пустые, а где логи глядеть или куда копать чуток непонятно.
За пару вечеров накидал у себя такой деш на основе Python+TimescaleDB+Grafana:
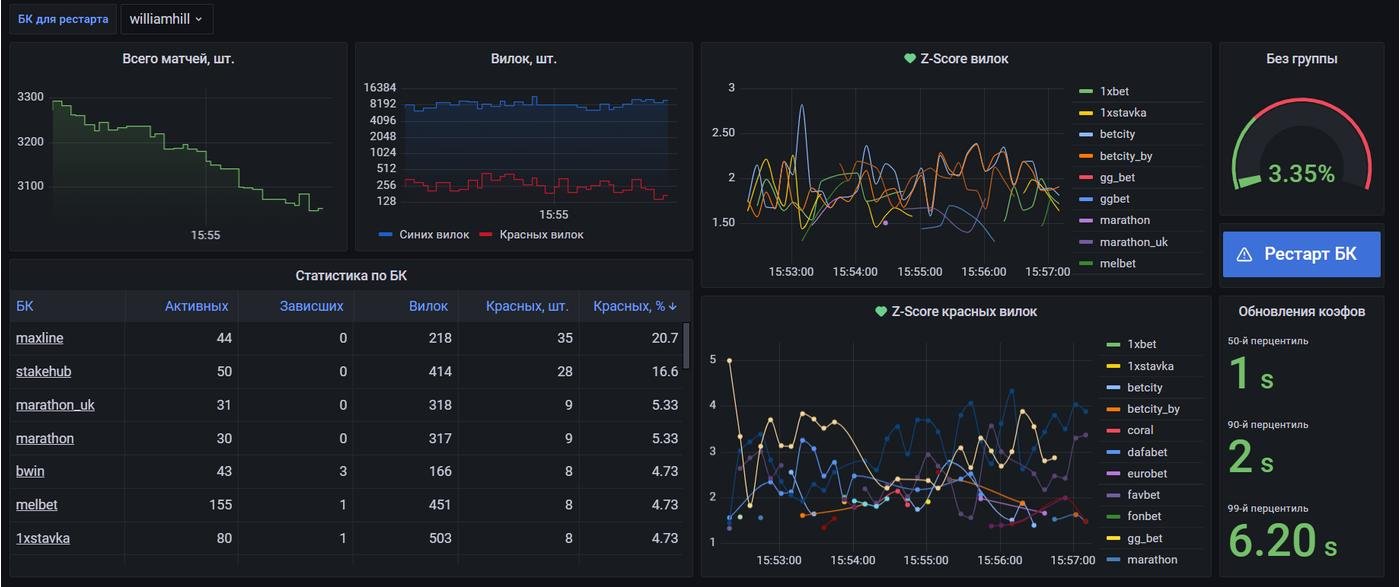
А тут не должно быть написано graphite, а не graphana?