


О сути проекта
Сделали поисковик для трансферов и визаранов в Черногории.
Эта статья описывает “как” (с большой долей технических подробностей и всяких списков).
Содержание:
- Как появилась идея?
- Решение проблемы курицы
- Простая архитектура
- Стек
- Планы на будущее
- Блиц
- Послесловие
Как появилась идея?
В начале января 2023 я приехал в Черногорию, ранее никогда там не бывал. Нужно было как-то добраться до забронированного жилья от аэропорта, а как заказать такси — было абсолютно непонятно. Тогда я воспользовался отдельным сервисом и заказал прям настоящий трансфер, как в командировке. Всё прошло нормально, но вопрос “как тут еще можно” в голове остался.
Через неделю мне нужно было ехать в другой аэропорт и трансфер заказывать не хотелось. Я начал ресёрчить и оказалось, что есть несколько чатов в Telegram, в которых люди ищут попутки или попутчиков в Черногории. В этих чатах несколько тысяч человек, запросы и предложения появляются десятками каждый день.
В моем случае нужно было запланировать простую поездку, причем без багажа. И было желание сэкономить. Я бы присоединился к кому-то, кто уже туда собирался ехать, но тогда нужно было бы мониторить чат практически 24/7. В результате я заказал отдельный трансфер через этот чат и забыл про это.
А через пару недель захотелось закодить что-нибудь простенькое. За выходные. Очередную “змейку” или что-то такое. Я предложил идею своему другу и по результатам обсуждения мы пришли к тому, что можно попробовать решить мою боль с поиском трансфера. Мы сразу оценили это как несколько недель неспешной разработки (вместо пары дней), но нас это не смутило.
Будущий образ продукта определили так: сервис, в котором можно быстро по фильтрам найти подходящую попутку.
В Черногории кроме обычных поездок-трансферов еще популярны визараны.
Визаран — это выезд за границу и обратно на короткое время , чтобы «обновить» срок разрешенного пребывания в стране. Может быть даже без заезда в другую страну, просто разворот на 180 в нейтральной зоне.
Долгий визаран — выезд на более продолжительное время, например на экскурсию в приграничный город.
Соответственно, визараны тоже хотелось добавить в фильтрацию.
И дополнительно учли, что если подходящей машины нет — попутчик может "оставить заявку" на поездку.

Через несколько месяцев были готовы основные функции:
Можно смотреть список доступных поездок и запросов от пассажиров с фильтрацией по:
‒ типу поездки (быстрый и долгий визаран, обычный трансфер)
‒ времени отправления
‒ точке отправки
‒ точке прибытияФильтрация по точкам работает даже когда у водителя более сложный маршрут и точки поиска совпадают частично. Например при поиске поездки B→D будет в том числе показываться поездка с маршрутом A→B→C→D→E→F.
Основной “Call to action” — кнопка “отправить сообщение” в объявлении, при нажатии пользователя перенаправляет в telegram в диалог с автором объявления.
Можно авторизоваться через telegram с помощью виджета и тогда будет доступно создание объявлений.
Водитель может в своей поездке указать до 20 точек, через которые он проезжает.
Мы понимали, что не хотим делать сложный проект (не получилось) и на этапе обсуждения нещадно резали все идеи, которые были дóроги в разработке. Мы сразу договорились, что делаем исключительно “информационный портал”, а не сервисную историю.
“Информационный” значит, что мы даем информацию и на этом умываем руки, перенаправляя пользователя в telegram, где он уже сам будет обсуждать детали поездки.
А в сервисной истории нужно было бы думать в сторону принятий оплат и тому подобного, но это уже полноценный бизнес, а не pet-project на “20 минут”.

Водители в своих поездках проезжают несколько точек и часто перечисляют их в объявлении. Мы хотели дать возможность попутчикам искать по сегментам таких маршрутов. Это дало проекту запрос на обработку графовых данных и частично определило стек, на котором проект реализован.
На этапе первоначального обсуждения было ясно, что в этом проекте есть проблема типичного классифайда (курицы и яйца): “чтобы была мотивация заходить на сайт и что-то искать — нужно чтобы УЖЕ было среди чего искать”.
Кажется, что такое решается либо агрессивным маркетингом, либо импортом уже существующего контента. Мы отложили эту проблему до этапа готового прототипа, но когда базовая функциональность была готова — вернулись к этому и сделали по красоте.
Также для создания объявлений нужен был список городов/деревень, “из”, “через” и “в” которые совершаются поездки. Мы собрали порядка 3000 точек и сделали отдельный сервис для поиска и автозаполнения.
Поддерживаем поиск на черногорском, русском и корявом английском (транслитерация с черногорского).
Точки включают города и крупные поселения в Черногории, Сербии, Боснии, Хорватии и Албании.
К сентябрю 2023 была готова текущая версия, которая крутится на сайте.
Решение проблемы курицы
В телеграме есть куча чатов с объявлениями, у нас есть веб-сервис с фильтром для такого вида объявлений ⇒ нужно как-то перенести данные из одного источника в другой (ну и формат изменить, да).
Наконец-то появился pet-проект, где можно применить ML!
ChatGPT использовать не хотелось — денег жалко. Из-за характера данных еще можно было разобрать это регулярками на основе правил, но это не так интересно (можно же сделать ХуЖе и ДоРоЖе!©).
Поэтому пошли по пути обучения своих моделек. В итоге, как мне кажется, получилось достаточно хорошо.
Визуализация точности распознавания:
План такой: берем сообщения из телеги, совершаем над ними магию, получаем заполненный контент в своей системе.

Звучало просто, но вопрос был в том, как использовать магию вне Хогвартса.
Сначала было вообще не понятно, какую именно задачу из мира машинного обучения надо решать. Но после некоторого ресёрча мы очертили подход — используем две нейронки: классифицирующую и NER (распознавание именованных сущностей).
За фразой “очертили подход после ресёрча” скрывается в том числе пройденный курс от ODS по Natural Language Processing. Он дал базовое понимание, где и какие гайки крутить. Кстати, нашел я его через клуб :)
Пришлось расчехлить свое знание питона.
Пайплайн обработки данных
Telegram-бот отслеживает новые сообщения в чате
При получении нового сообщения — оно попадает в пайплайн:
a. модель классификации (тип объявления, отсечение шума)
b. модель для выделения сущностей (дата, время, точки)
c. постобработка (получение итоговых параметров объявления из результатов NER, работа со словарями и мета-информацией)Если все параметры поездки определены — сервис дергает бэк, чтобы создать новое объявление
Бэк проверяет, что у данного пользователя ещё не создано такое же объявление, чтобы отсечь дубли. Если такого объявления нет — оно создаётся.
Разметка датасета и обучение нейронных сетей
Сейчас я бы прикрутил GhatGPT размечать всё это и получилось бы неплохо (и думаю не так дорого). Но год назад хотелось “пощупать данные”, поэтому за пару (недель) томных вечеров я разметил несколько тысяч сообщений, выделяя классы и сущности.
Инструментом для разметки сначала был обычный Excel, но его неудобно использовать для сущностей внутри текста. Поэтому нужен был другой инструмент, более профильный.
Я попробовал несколько плагинов в jupyter notebook для разметки NER (например этот), но они оказались либо нестабильны, либо очень ограничены.
В конечном итоге я нашел label studio, который идеально решал задачу.
В label studio можно создать свой интерфейс для разметки под конкретную задачу (результат справа):
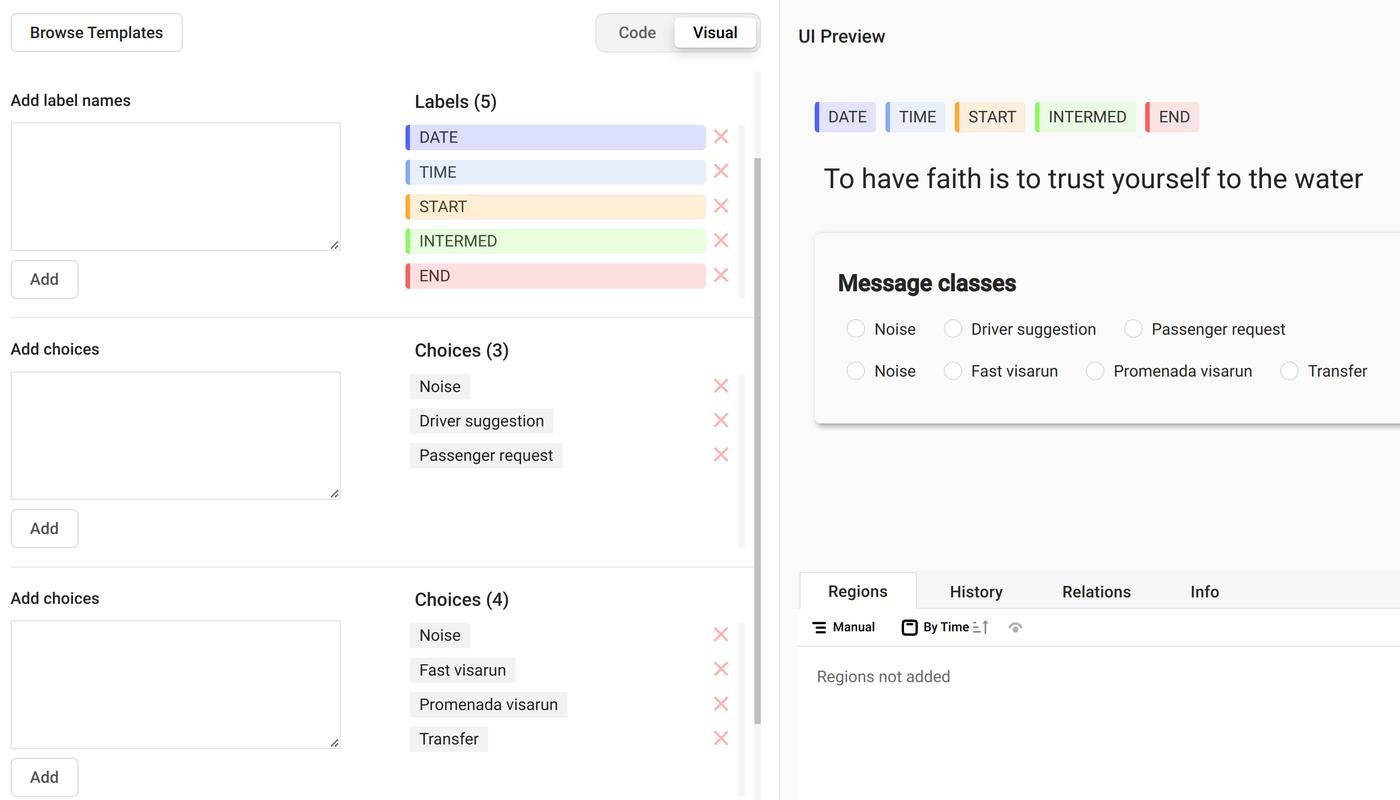
Еще можно импортировать значения, которые твоя нейронка выдала в качестве предсказаний. Это позволяет ускорить разметку, так как задача смещается с “создать аннотацию полностью с нуля” на “скорректировать уже существующую”.
Размеченное сообщение выглядит так:
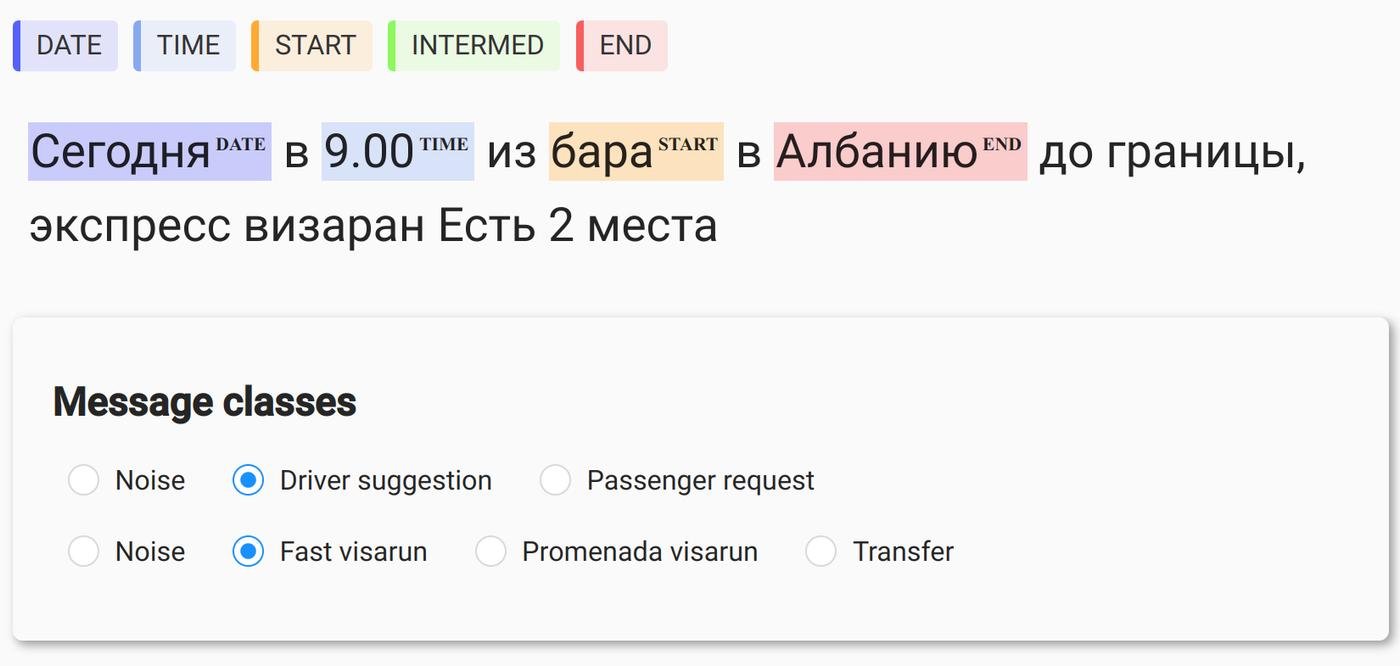
После разметки данные экспортировались в json, который загружался в jupyter notebook для обучения.
Для распознавания текста используем HuggingFace, взяли предобученную на диалогах нейронку.
Классификация
Первая нейронка отвечает за классификацию. Решаем задачу “является ли это сообщение объявлением и если является, то каким”. Цель была в том, чтобы с большей точностью передавать второй нейронке данные для последующего разбора.
На этом этапе определяем:
- В сообщении “шум” или объявление
- Пишет водитель или пассажир
- Какой тип поездки подразумевается: трансфер, визаран или визаран с прогулкой.
Если сообщение распознано как шум — его обработка останавливается.
NER
NER (Named Entity Recognition, wiki) нужен, чтобы доставать данные из сообщений. Нас интересуют следующие сущности:
- Точка отправления
- Точка прибытия
- Промежуточные точки для описания пути следования водителя
- Время и дата отправления
Тип поездки у нас уже есть, он определился на предыдущем этапе классификации.
Обработка
Для AI-сервиса я сделал допущение, что одно сообщение = одна поездка. Бывает так, что водители утром едут в одну сторону, а вечером в другую и пишут об этом в одном сообщении. Или выкладывают целое расписание. В таких случаях мы берем только первые сущности из их объявления. Тут теряется какое-то количество контента, но мы решили этим пренебречь.
После нейронок в пайплайне идет преобразование полученных данных в понятный бэку формат. Ищутся точки, человеческое время конвертируется в машино-читаемое. Разумеется тут всё обложено костылями.

Но вроде работает неплохо.
Результаты распознавания
В процессе анализа созданных объявлений вскрылась проблема: оказывается, у некоторых пользователей telegram нет юзернейма. Возможно они зарегистрировались через номер телефона без логина или он скрыт какими-то настройками приватности. Но для нас это было проблемой — нельзя с сайта перенаправить пользователя в чат с создателем объявления, если нам неизвестен логин. Пришлось отфильтровывать даже полностью распознанные объявления на этом этапе:

Несколько примеров успешного распознавания:


Кстати в нижнем примере слева "ХН" должно было определиться как промежуточная точка (Херцег-Нови), но NER ее пропустил.
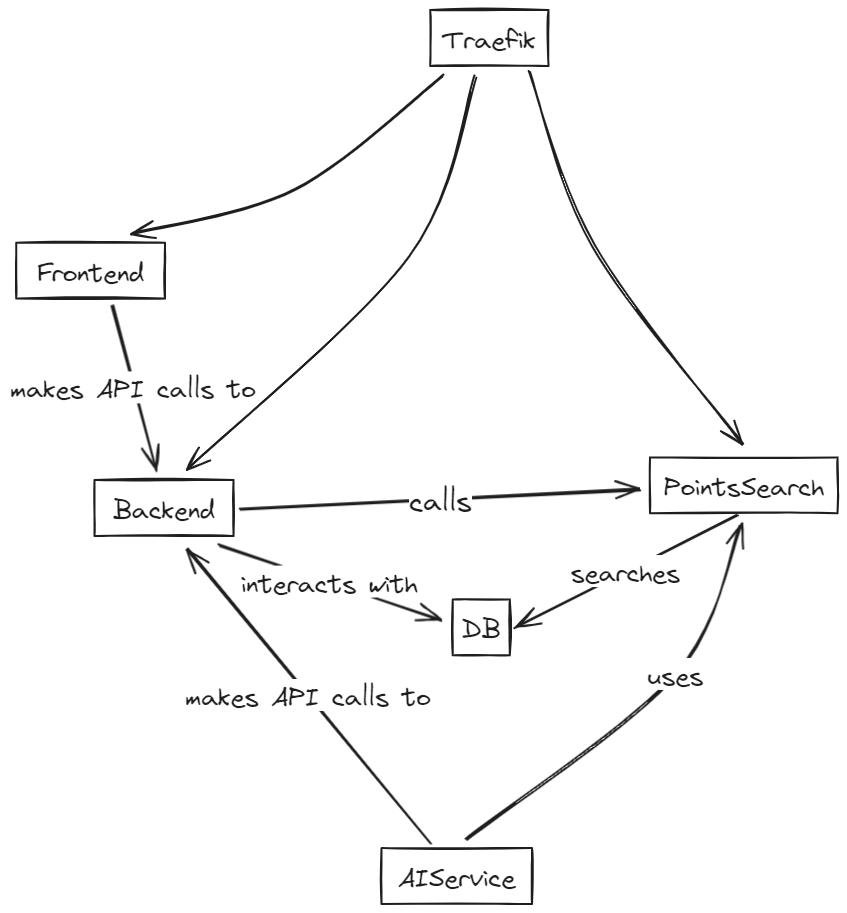
Простая архитектура™
Микросервисная получилась:
- telegram-бот с ML-обработкой для отслеживания новых объявлений
- бэк для обработки запросов на CRUD
- фронт
- сервис поиска точек
- база данных
Подобно клубу, хостится это за traefik’ом:
Стек
- Vue для фронта
- NestJs для бэка
- FuseJs для текстового поиска по точкам
- Neo4j в качестве графовой базы данных
- Python + HuggingFace/transformers + telethon для обработки сообщений на естественном языке
- Sentry для получения ошибок с фронта
Neo4j
Neo4j тут заслуживает отдельного упоминания. Это достаточная популярная китайская бд, которая часто выдается в поиске по запросу “графовая база данных”.
Нам она была нужна из-за поиска сегментов в маршрутах. Но практика показала, что ее неудобно использовать для проектов, где не хочется покупать Enterprise лицензию.
Банально, нельзя снять дамп для бэкапа пока база функционирует. Официальная инструкция: опустить основной контейнер, поднять рядом еще один с другими параметрами, снять дамп, а потом обратно поднять основной контейнер. Из-за этого у нас каждый день в 4 часа утра 2 минуты даунтайма =)
Репликации/кластеров в бесплатной версии нет. Второго пользователя с не-рутовыми правами на всю базу не создать. Даже имя пользователя сменить нельзя.
В общем — разочарование. Надо было пробовать с PostgreSQL, кажется там или из коробки или с плагином можно графы вертеть.
Планы на будущее
Есть короткий бэклог:
- Индивидуальные уведомления о подходящих объявлениях через бота в telegram
- Чуть допилить NER и ее правила разбора сущностей, там неприятные баги бывают
- Натянуть новый дизайн на сайт
- Дать возможность оставлять фидбек по объявлению на случай ошибок
- Статус объявления должен обновляться в зависимости от сообщения в telegram. Например если исходное сообщение удалено — то хотелось бы на сайте отобразить что-то вроде “устарело”
- Добавить кэш для поиска, сейчас БД выжирает все ресурсы и сервер страдает
Но не знаю, дойдут ли руки до этого. Из-за размера входящего трафика (которого нет) мотивации продолжать разработку — не много.
В целом цель свою этот проект выполнил. Мы интересно покодили, я изучил много новых штук, выкатил новый проект в прод. Даже умудрился рассказать про свою архитектуру на техническом интервью в компании, где сейчас работаю (лайфхак для прохождения секции по системному дизайну, я на собесе рисовал примерно ту же диаграмму архитектуры из поста).
Блиц
Ответы на оставшиеся вопросы о проекте по формату клубного поста:
- Как вы запускались и искали первых пользователей?
Запустились обычно, docker compose up. Но анонсов никуда не делали. Пользователей на данный момент нет.
- С какими самыми неожиданными трудностями пришлось столкнуться?
Хотелось всего лишь покодить на выходных, а вышло вот так…
- Сколько потратили и заработали?
Потратили кучу времени и $6 на сервер в месяц. Денег не заработали, только бесценный опыт.
- Есть идеи как это можно монетизировать?
С монетизацией тут сложно. Если бы мы делали сервисную историю — можно было бы брать какую-то комиссию за поездки. Но тут чисто информационный инструмент. Максимум что я могу придумать — это повесить рекламу, но для этого недостаточно трафика. Непонятно в общем.
- Нужны ли какие-то советы или помощь Клуба?
Любые комментарии — welcome! Лёгкая монетизация, например, очень интересует.
Послесловие
Пока мы занимались рефакторингом и игрой со шрифтами — в Черногории кто-то зарегистрировал местное ООО с нашим названием. Если не ошибаюсь, то сначала в данных о компании была деятельность "ремонт обуви" судя местному аналогу “ОКВЭД”. Но сейчас поменяли на аренду авто 😄.
Иногда некоторые сообщения делали очень больно:
Немного статистики за полгода работы сервиса (21.08.23 - 30.01.24):
- Водителей: 655
- Предложений поездок: 4610
- Попутчиков (кто искал машину): 1392
- Запросов на поездки: 2699
- Неполных объявлений: 9733 (сообщения включая дубликаты, которые были распознаны как объявления, но не все данные получилось распознать)
- Дубликатов: 3797 (полностью распознанные объявления минус созданные). Значит пользователи публикуют свое объявление в чатах в среднем 1.5 раза.
Еще раз ссылка на сервис, чтобы не скроллить наверх: montedriver.me
Спасибо за внимание.

Насчет монетизы - в информационных продуктах у тебя какой главный продукт? Праааавильно, информация.
Вот ее и надо продавать, но, конечно же, не топорно (как, например, оплати долор и получишь доступ к закрытой площадке).
В голову приходят 2 варианта, которые не ухудшают жизнь юзеров:
Привет!
Офигенный проект, пуст выгорит :-) Накину несколько штук, вдруг окажутся полезными.
Про привлечение пользователей - я не смог найти вас в гугл даже по прямому запросу с адресом сайта. Прочекал и у вас нет базовых штук для seo, типа robots.txt / sitemap. Кажется, если добавить их, залинковать сайт в гугл серч консоль, то хоть что-то может получиться.
Я уверен, что поисковый трафик в теме есть, по крайней мере по запросу "трансфер будва подгорица" показывается в том числе контекстная реклама в гугле, а значит это хоть сколько-то частотный запрос.
Как получить этот трафик - выводить ваши объявления на сайте не только после поиска, но и в целом пусть лежат на какой-то нормальной странице категорий, типа Трансферы из Будвы / Трансферы в Подгорицу, просто список всех объявлений + ключевые слова основные добавлять автоматом к ним. Сейчас объявления просто находится только по сложным ссылкам вида https://montedriver.me/drivers?tripType=2&from=5000&to=5005&date=1706738400000 и такое не будет нормально индексироваться.
Ну и если в целом показать контент на сайте, то будет ощущение, что проект живой, им можно пользоваться. Сейчас одинокая поисковая форма выглядит грустно(
И еще вам бы обработать пустые поиски, например, я ищу поездку на сегодня, ничего не нахожу. Покажите мне в этот момент, что завтра по этому маршруту есть объявления, вдруг я поменяю дату выезда.
А про монетизацию, что если брать долор за доступ к контактам в объявлении? :-)
Круто, спасибо за подробный рассказ, трансфер в Черногории сейчас конечно полностью на ручнике.
Напоминает кстати историю Indrive – там тоже была группа с объявлениями от водителей. Группу потом купили, сделали приложение, которое сейчас довольно хорошо отмасштабировалось по миру :)
Скажи пожалуйста, на какой спеке это всё добро крутится? Если там ещё и ваши локальные нейросети, то выглядит довольно всё довольно ресурсо-требовательно!
Недвига! Срочно нужен аналогичный сервис по аренде недвиги в Чг ))