
Надо же с чего-то открывать рубрику «проекты» чтобы сразу задать тон всей комнате. Расскажу как и с чего вдруг появился infomate.club.
Как родилась идея?
Где-то в начале 2019 я активно залипал на всяких коммьюнити «мейкеров» и «инди-хакеров», в том числе крупнейнем indiehackers.com. Ничего не писал, конечно, только читал.
Где-то в комментариях я наткнулся на nuuz.io — страничку-агрегатор всех заголовков новостей по определенной теме, которую запилил один чувак из Бельгии как пет-проджект.
Ну и начал на нее время от времени заходить. А так как российские СМИ отстают от мировых примерно на сутки, а от первоисточников на три, я стал внезапно еще в понедельник узнавать оттуда всё, о чем мои друзья будут говорить лишь в среду.
Плюс, когда у тебя только заголовки и нет вот этих тупых кликбейтных новостей из твиттера, ты тратишь на это реально пятнадцать минут в день максимум.
Стало круто. Подсел. Отписался от VC и TJ, тем более у них как раз тогда сменились главреды и они стали не очень. Стал читать только этот агрегатор. Даже упомянул его в итогах года (после чего люди узнали о нем и начали мне говорить, что я его спиздил — вот это я называю ИНТЕРНЕТ) :D
Со временем появилось несколько проблем:
- nuuz работал пиздец медленно и часто от него отваливались фиды. Techcrunch, например, был пустым аж месяц. Не дело.
- Там начисто отсутствовали русскоязычное инфополе, из-за чего приходилось всё равно раз-два в неделю открывать VC
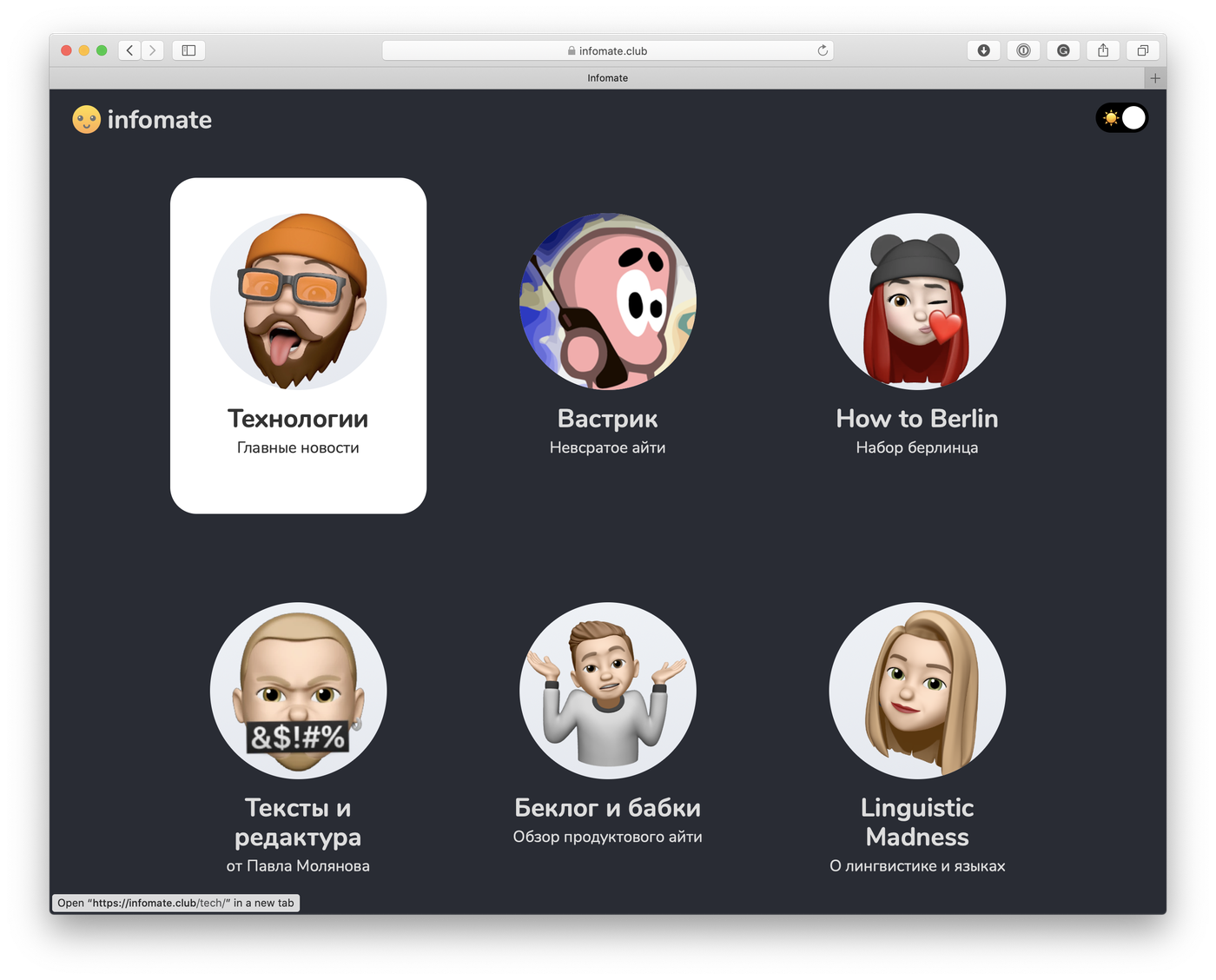
- Мне хотелось больше тематических подборок из разных областей. «Технологии», конечно, хорошо, но мне хотелось подборки типа «Компьютерная Лингвистика» или там «Сайты, которые читает редакция Завтракаста».
- Хотелось чтобы в попапе отображалось не первое предложение (оно часто бесполезно), а хоть какой-то полезный саммари
Создатель nuuz не отвечал ни на какие имейлы. Он вообще заметил нас только по трафу на сайте, после чего написал пост Nuuz.io has fans in Russia. После чего всё равно не ответил :D
Я решил писать своё.
Техническая реализация
Сайтик
Я свободно говорю на Python, потому мой выбор для пет-проджектов вебсайтиков чаще всего один — Django.
Знаю, многие её ненавидят. Я и сам через это прошел, когда был маленьким. Да, сегодня я бы не выбрал ее в проект на работе и не потащил бы в суровый продакшен.
Джанга по сути конструктор LEGO — куча деталей, но собирать можно только игрушки и от других конструкторов ничего не подходит. Что идеально для сайтиков пет-проджектов.
Чаще всего я стараюсь оторвать от джанги всё, кроме основы — вьюх, шаблонизатора и ORM. Они простые и это всё, что мне обычно надо. Миддлварей я и сам нафигачить могу.
Джанговскую авторизацию, например, я пытался раза три осились и каждый раз тупо писал свою. Так проще.
По сути я превращаю Django в микрофреймворк типа Flask, только при этом у меня всегда есть возможность «рисовать крупными мазками», взяв какую-нить готовую django-либу из тысяч имеющихся на гитхабе (тот же django-q).
Со фласком же всегда получается в разы больше лишних движений руками. Гибче, да, но не всегда оно надо.
В целом я больше не максималист-фанатик и ничего плохого в джанге не вижу. Она задаёт главное — структуру, которая понятна как другим, так и тебе, когда откроешь код через 5 лет. Она проста как LEGO и в этом ее прелесть. Мой блог живет на ней уже лет 8.
Просто джанга не везде подходит.
Парсинг RSS
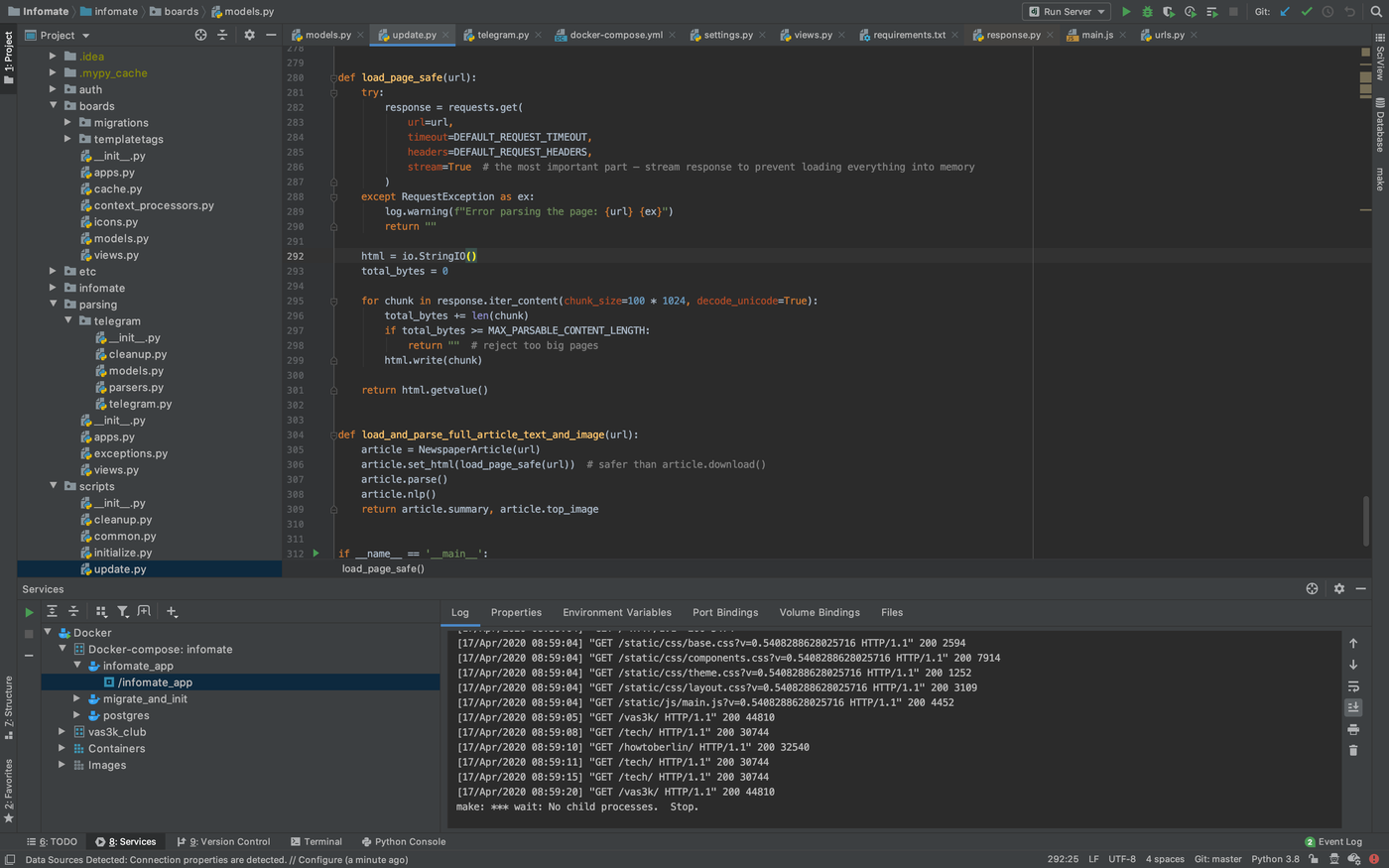
Дальше нужен был парсер RSS'ок.
Очередь задач я решил не пилить, обойтись лишь скриптиками в кроне. Нет необходимости тащить ебучую Celery, которая потом будет крешиться по ночам из-за незакрытого бага, когда тебе надо всего-лишь раз в час дергать скриптик.
Да, скриптик должен уметь быть немного параллельным, иначе он будет парсить сайты целый час. Но для этого отлично подойдет простейший ThreadPool на питоне. Мне не надо синкать треды, потому вообще похуй.
Так что раз в час у меня запускается скрипт, который пробегает по всем RSS из базы и смотрит что там нового.
Один из челленжей был — сделать это всё говноустойчивым.
Например, по ссылке из RSS условного HackerNews может придти 500-мегабайтный PDF. Или подкаст. А либы для парсинга ведь тупые, они скачивают в память всё, что ты им даёшь!
Content-Lenght верить нельзя, некоторые его не проставляют. Content-Type тоже у многих сломан. Короче, начинаются долгие вечера допиливания, использования стриминг-скачки и вставки if'ов в код. Ну, оно там видно.
Саммари
Одна из фишечек проекта — генерация автоматического саммари текстов на 20+ языках. Сейчас есть два подхода к этому:
Олдскульный. Он же статистический. Программа считает по алгоритму TextRank какие предложения наиболее «значимы» в рамках данного текста и ранжирует их как поисковик результаты. Показываешь топ-5 и готово.
Готовые либы делают это в прямом смысле за 2 строчки кода, одна из которых — импорт. Я взял newspaper3k. И нет, не потому что у меня ник тоже на 3k заканчивается.
Модный нейросетковый. Щас модно обучать нейросетки писать саммари. Тот же BERT с этим хорошо справляется. Саммари получаются прям как будто ваш друг пересказал статью.
Проблема такого подхода одна — под каждый язык придется искать свой датасет и, опять же, много работать руками.
Этим я планировал заняться потом, если проект попрет или будут желающие помогать. Пока времени поиграть с этим не было.
В общем-то вроде всё.

Какие были проблемы?
Первая — телеграм.
Все сразу захотели добавлять в подборки телеграм-каналы. Некоторые вообще состояли только из них (такие я забривал).
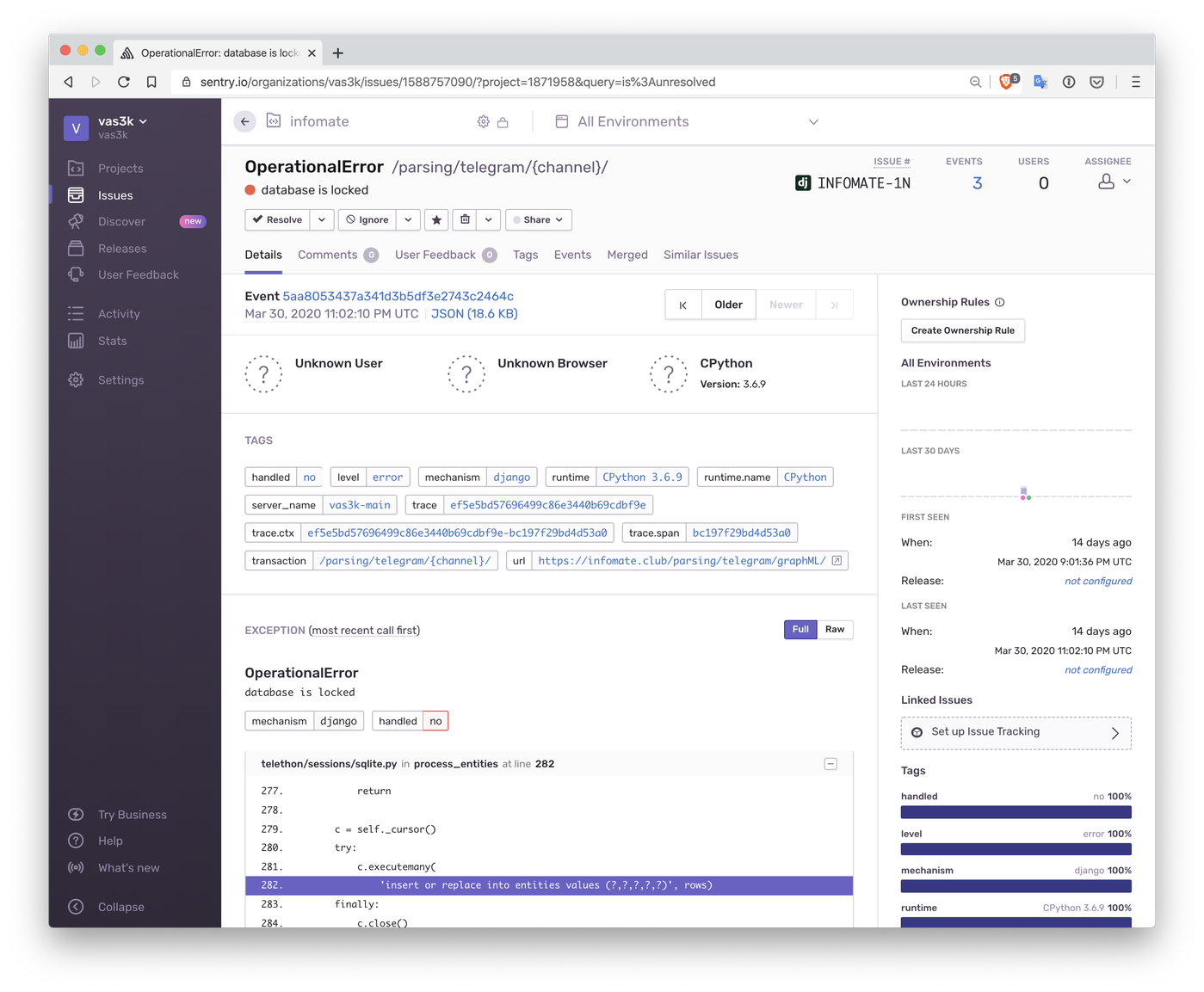
Проблема телеграма в том, что он ненавидит, когда его парсишь. Нельзя читать каналы ботом, нельзя делать больше 500 запросов в сутки, нельзя подписываться более чем на сколько-то там каналов. Короче, постоянные палки в колеса.
Дополнительной проблемой стали либы. Оказывается, либо для телеграм-ботов, которая прекрасная и охуенная, это не та же либа, которую ты будешь использовать для Telegram API. Для этого нужна отдельная — telethon.
Так вот я не знаю, кто его написал, наверняка очередные ОЛИМПИАДНИКИ, но они наговнокодили там прямо мама не горюй. Хотя бы то, что они использовали SQLite базу чтобы хранить ТОКЕН блять (ведь просто в текстовый файл положить было нельзя!). Они еще и написали всё на модном asyncio с тредпул-экзекутерами, забыв, что SQLite, сука, очень не любит, когда в него сразу параллельно все ходят.
Либа отваливается по ночам и кидается эксепшенами.
Уух, бомбит.
В итоге мы хотели переписать парсинг телеги на парсинг их веб-сайта, который доступен если добавить /s/ в URL: https://t.me/s/vas3k_channel
Вторая проблема — сайты без RSS
Долго думал и в итоге решил просто заплатить за сервис парсинга FetchRSS. Там можно загрузить любой сайт и прямо мышкой накликать из каких блоков брать заголовок, описание, картинку. Он сам сгенерит RSS.
Таких сайтов еще много, но я остановился на этом как самом простом.
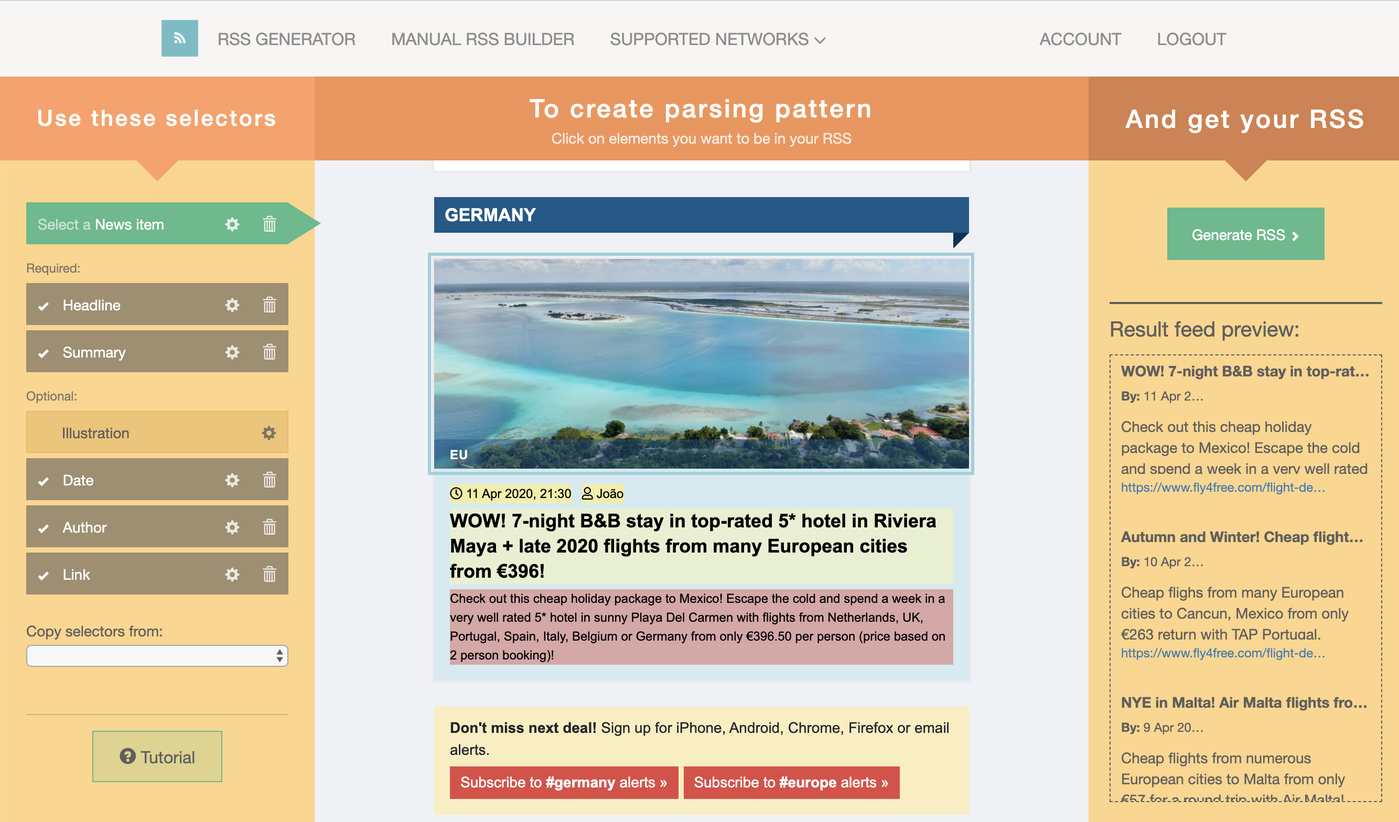
Так и плачу за него около $5 в месяц. По сути это самый большой мой расход на Infomate :D
Вычту его из налогов.
Что было самым сложным после запуска?
Оказалось, что объяснить людям такой новый формат было весьма тяжело. Только для меня это «вау, как круто, я теперь узнаю в два раза больше и трачу на это в десять раз меньше времени», а для других это не так очевидно :D
Я пытался объяснять, но никого так и не убедил. В итоге забил.
Просто принял как должное, что получился нишевый проект, на который либо подсаживаются надолго и на каждой сходке говорят «спасибо», либо не понимают вообще.
Сколько заработал?
Нисколько. Сначала была идея делать Infomate закрытым проектом «только для Клуба». Приглашать знаменитостей делать закрытые подборки, а потом анонсировать это на участников Клуба. Чтобы все типа думали какие они илитарные.
Но что-то не вышло. Ажиотажа вокруг формата не получилось, ну и ладно, зато мне (и еще паре людям) это полезно.
Как говорит «Почта России» — охуительных идей много, а я одна. Приходится фокусировать усилия на том, что работает, и нахуй выбрасывать остальное.
Планы на будущее
Проект живет на одном сервере со всеми остальными и кушать особо не просит. Так что пусть живет. Он мне нравится. Я захожу туда минимум раз в день и продолжаю читать новости только так.
Сейчас я понял, что нет смысла делать из него закрытый проект, потому я выложил все данные (включая подборки) на гитхабе.
Нужна ли сейчас помощь?
Ну, если вы знаете каких-нибудь известных в интернете чуваков, которые бы согласились выложить подборку сайтов, которые они читают, у нас — мне было бы это весьма интересно.
Я бы очень хотел сделать отдельные разделы типа «тематические подборки» и «подборки от крутых людей», но совсем не знаю где этих самых людей находить, как с ними общаться и что им предлагать за потраченное время.
Ну и парсер телеграма у нас всё еще ужасный, да. Хотелось бы перейти на какой-нибудь RSSHub в докере и парсить им все сайты и телеграм-каналы.



У меня почему-то просто бланковая страница и пару строк: Проект Вастрик.Клуба. Код открыт.
Все подборки исключительно субъективны и собраны коммьюнити.
Идеи и предложения новых источников присылайте на гитхаб.
смотрю с сафари - ipad
Всем привет! у меня в последнее время сайт https://infomate.club/ перестал открываться, почините пожалуйста)
UPD: точнее он открывается, но больше нет тематичеких подборок, сайт пустой
Какой потрясающий проект! Спасибо огромное, что делишься им!
А откуда картинки персон на главной? Очень красиво сделано.
Я частенько пытаюсь выдумать свой агрегатор, потом мне напоминают, что я переизобретаю инфомейт. На самом деле хочется накрутить как минимум дедупликацию - чтобы очень похожие тексты схлопывались в один со счётчиком. А ещё лучше какую-то более умную агрегацию, чтобы было просто одной строкой написано "100500 источников написали про
чатгптсверхпроводники". Пусть пока эта идея витает в воздухе, и может быть у меня когда-то и появится время впилить её.Для телеги есть https://github.com/bellingcat/snscrape -- он почти не документирован, но там в принципе не сложно разобраться. Он как раз поверх веб-просмотра каналов в телеге. Из минусов (по крайней мере на момент когда я тыкал) канал можно тащить только целиком, а не просто новые посты. Некоторые каналы не дают себя смотреть таким образом. Под капотом у него какие-то адские заклинания на beautifulsoup. Из плюсов -- потенциально без ограничений на скачивание.
Ещё есть переходники из телеги в rss. Я вот таким пользуюсь https://tg.i-c-a.su/ -- там просто надо в конце название канала в url впихнуть и всё.
Выглядит здорово, но по формату больше нравится что-то вроде https://tldrmarketing.com
Попробуй pyrogram, охуенная либа поверх mtproto телеграмовского. И не надо бэкенд городить для бота
Я погонял fetchRSS - попробовал через него всякие социалочки, чтобы РСС выдавал. Но он постоянно показывает ошибки. Даже ССЛ у сайта отвалился.
Проект еще живой? Работает? Либо ты его уже заменил чем-то?
Я для своего проекта гоняю self-hosted RSShub -- если тебе интересно, могу поделиться деталями и можешь тоже его использовать. Он у меня все равно без дела большинство времени сидит :)
Ребята привет! Предлагаю добавить в ленту ресурс Cybermedia (https://securitymedia.org)